

Последние записи
- Изменить цвет шрифта TextBox на форме
- Ресайз PNG без потери прозрачности
- Вывод на печать графического файла
- Взаимодействие через командную строку
- Перенести программу из Delphi в Lazarus
- Определить текущую ОС
- Автоматическая смена языка (раскладки клавиатуры)
- Сравнение языков на массивах. Часть 2
- wprintf как напечатать кириллицу
- Взаимодействие через командную строку

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
27th
Фев
 Компилятор домашнего приготовления. Часть 3
Компилятор домашнего приготовления. Часть 3
Posted by Chas under Журнал, Статьи
Всем доброго. В прошлой статье я описал как охладить в холодильнике квас, пока пишется ядро компилятора. Помните? Нет?! Странно… Впрочем, это не проблема. Наши журналы хранятся по адресу [1], так что освежить память – не проблема. Поскольку ядро, генерирующее PE файл готово (по минимуму, но готово) и его можно использовать для генерации исполняемого файла, то теперь вполне можно подумать более глобально (в общем, углубиться дальше в лес). Вообще, некоторым может понравиться писать прямо в опкодах, да еще в собственном компиляторе – это интересно и познавательно. Придется перелопатить кучу литературы, которая направит на путь над пропастью по тонкой нити, потому как опкоды не позволяют сосредоточиться на стратегических задачах, постоянно отвлекая на тактические мелочи: то учесть адрес переменной, то работа со стеком. Уже сама операция 2+2 подразумевает, как минимум: положить в переменную число, прибавить к ней второе число. Это две операции, плюс ко всему нужно еще знать адрес переменной. Конечно не абсолютный, а относительный, но при наличии, скажем сотни, переменных хранить в голове все их адреса – достаточно круто. К этому нужно привыкнуть. Или переменная локальная – она лежит в стеке, а потом же не забыть этот стек очистить от мусора – еще одна операция. Не получиться в опкодах записать выражение (2+2)*18/(32+sin(pi/3.4)) в одну строку вот так просто. Придеться думать о том, какой приоритет, какому оператору задать. Каждый оператор имеет свою команду, а если брать «синус», тут еще серьезнее – придеться работать с FPU командами: поместить в стек сопроцессора число, получить из него синус, и выдернуть из стека в переменную – это уже три операции как минимум. В общем, люди, которые по натуре своей ленивы, естественно желают разгрузить себя, переложив рутинные операции на машину. Поэтому высокоуровневые языки программирования всегда снабжаются модулями разбора и анализа написанного кода на более понятном и близком к человеку языке. Машине-то все равно: разбор текста – тоже вычисления, а уж она это умеет делать гораздо быстрее человека, да еще и надежнее. Следующая важная задача – разработка механизма трансляции исходного кода в операционный код. Именно этим и займемся в этой части. Так что, устраивайтесь поудобнее и включайте свой разум на прием информации о том, как можно упростить себе жизнь…
Виталий Белик
by Stilet http://www.programmersforum.ru
Good morning, Joаn
Итак, давайте еще раз посмотрим, что мы имеем, и что нам нужно для того, чтобы писать свои программы на своем языке было проще. Мы имеем открытый поток байт – строку, представляющую собой операционные коды и данные, с которыми эти коды будут работать. Нам нужно написать программу (класс, процедуру, функцию… что удобнее), которая будет переводить выражения, вроде описанного выше, в операционные коды, учитывая при этом все зарезервированные слова в выражении.
Что такое зарезервированное слово? Зададим этот вопрос Википедии:
Это часть языка, которая должна говорить компилятору о том, что в операции участвует некий объект. Функция, представляющая собой вызов некого блока кода, и возвращающая результат, интерпретируемый вместо ее имени, и участвующий в дальнейших операциях. Переменная, представляющая собой область памяти, которой человек дал имя. Как, скажем, названия улиц в городе. Представьте себе, если бы их не было, а вместо этого был бы просто номер – удобно ли это было бы?
И, конечно же, нужно не забыть о константах. Вообще, константа в программировании – это способ адресации к данным, изменение которых запрещено, но в целом это определение предполагает нахождение константного значения в памяти в том же месте, где располагаются и обычные переменные. Однако константой с таким же успехом можно считать часть операции, одним из операндов команды. Например, ассемблерная команда сложения значения в регистре-аккумуляторе: ADD EAX, 6. Здесь 6 – это константа, но расположена она не в секции данных, а непосредственно в команде. Это тоже нужно учесть. Никто не мешает хранить это число в секции данных вместе с другими, и это не будет ошибкой. Программа так же сложит и получится такой же результат, но это не оптимально. Зачем напрягать компьютер лезть в память за каким-то числом, если это число можно прямо командой загрузить в процессор, уже не говоря о том, что размер такой команды будет меньше. Вот взгляните на рисунок 1:
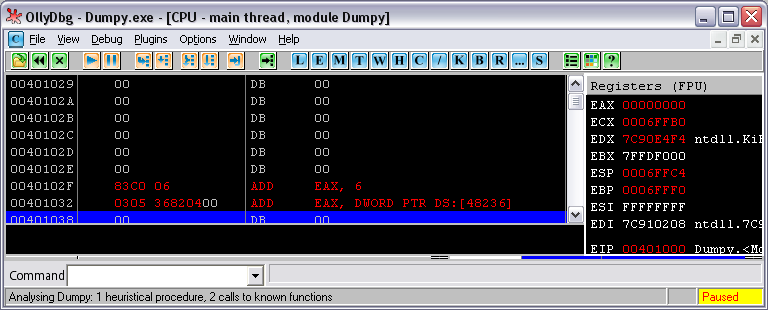
Рис. 1. Разница в командах
Видите, что Оля показывает (Оля – это Olly Debuger, которая будет нам помогать анализировать сгенерированный код)? Команда работы с ячейкой памяти занимает 6 байт, в то время как команда с константой всего лишь 3. Это не только выглядит более логичным, но и занимает меньше места в памяти. Причем в данный момент я говорю о байтовых операциях.
Хорошо, договорились: зарезервированное слово – это имя переменной, имя функции, имя оператора, операции. Теперь нужно подумать о самом языке. Из каких слов и конструкций он будет состоять? Какие ключевые слова нужно заранее прописать в компиляторе?
Вот и я опишу семантику, так как я представляю ее на самом простом уровне. Имеется в виду правила, похожие на язык ЛИСП. Почему именно ЛИСП? Его операции атомарны. Каждая операция предполагает не смесь операторов внутри выражения, а набор огражденных блоками операций с параметрами, при чем эти операции могут быть сколь угодно вложены друг в друга, и совершенно не помешают написать достаточно сложное выражение. Таким образом, каждая операция будет окружена символами-ограничителями операции, внутри которых будут между разделителями операнды. Первый операнд – сама команда. В качестве ограничителей предлагаю взять круглые скобки, а в качестве разделителей операндов символы пробела и разделитель строки.
Так выражение описанное выше приобретет следующий вид:
(/ (* (+ 2 2) 18) (+ 32 (sin (/ pi 3.4))) )
Запутанно и непривычно немного. Правда? Да, те кто работал только с Си, Паскалем, Бейсиком скажут: «Фу-у-у… Ну и где здесь удобства?». Отвечу. Во-первых, армада специалистов, пишущих на ЛИСП наберет достаточно много аргументов «За» и поймут меня. Во-вторых, не так уж и сложно понять такую структуру, если запомнить и разобрать такую структуру, поскольку каждое ключевое слово находится строго на своем месте. Операция на первом, операнды через пробел на остальных, и одна операция окружена круглыми скобками. Это правило не сложно объяснить компилятору. Всего лишь, пройтись по строке от первой «(» до последней «)», учитывая вложенные скобочки. А потом в цикле перебрать разделенное со второго по последний операнд. И применить к каждой итерации операцию по ключевому слову в первой позиции.
Так. С семантикой выражений более-менее понятно. Ну что, попробуем описать парсер, разбирающий такое выражение? Тогда предлагаю выделить этот механизм в особый класс. Ему будет передаваться текст, а тот будет разбирать его по блокам:
// Класс, отвечающий за разбор выражений
TAlisaScaner=class
private
// Массив операндов. Нулевой операнд — это операция
Param:TStringList;
FText: string;
function GetItem(i: integer): string;
procedure SetText(const Value: string);
public
// Свойство, которому будет идти присвоение строки, рассматриваемой как
// исходный код
Property Text:string read FText write SetText;
// Свойство, позволяющее получать из массива операнд по номеру
// Соответственно нулевой операнд — это операция
// Свойство это я предлагаю сделать по умолчанию, так будет удобнее
// обращаться к параметрам объекта сканера
Property Item[i:integer]:string read GetItem; default;
// Функция возвращающая последний индекс в массиве операндов
// Предназначена для циклов типа FOR. Я лично не люблю писать Count-1
// Хотя никому не мешает не использовать эту функцию
Function High:Integer;
Constructor Create;
Destructor Free;
end;
TAlisaScaner=class
private
// Массив операндов. Нулевой операнд — это операция
Param:TStringList;
FText: string;
function GetItem(i: integer): string;
procedure SetText(const Value: string);
public
// Свойство, которому будет идти присвоение строки, рассматриваемой как
// исходный код
Property Text:string read FText write SetText;
// Свойство, позволяющее получать из массива операнд по номеру
// Соответственно нулевой операнд — это операция
// Свойство это я предлагаю сделать по умолчанию, так будет удобнее
// обращаться к параметрам объекта сканера
Property Item[i:integer]:string read GetItem; default;
// Функция возвращающая последний индекс в массиве операндов
// Предназначена для циклов типа FOR. Я лично не люблю писать Count-1
// Хотя никому не мешает не использовать эту функцию
Function High:Integer;
Constructor Create;
Destructor Free;
end;
Немного свойств. Ну, нам-то и нужно разорвать код на операнды. Причем, в случае с вложенными выражениями, соответствующий операнд будет представлять такой же текст кода, который тоже нужно будет парсить. Таким образом, рекурсивно вызывая функцию, запускающую парсинг, передавая ей операнд, содержащий операцию можно пробежаться по дереву вложенных операций.
Теперь дело за реализацией. Сразу хочу оговорить один момент. Поскольку символом разделителя операндов считается пробел (по крайней мере, у нас), нам придется что-то придумать для операндов-строк. Ведь в них могут быть пробелы. Как строки устроены в популярных ЯВУ? Строка – это набор символов, ограниченных специальным образом. В Си символы ограничители*** – двойные кавычки: “Это строка в Си”. В Паскале кавычки одинарные, а например, в MySQL особый вид кавычек:`. Честно даже не знаю, как этот символ называется. Поэтому нам придется пропускать пробелы или, поясню точнее, приписывать их операнду, не считаясь с разделителями, если встретится символ ограничитель строк, при условии, что его еще не было. И включить учет пробелов непосредственно после встречи второго такого же символа, отделив полученное между символами в операнд. Интересно кстати-то, что обычно открытая строка в параметрах функций или выражениях может называться константой. Ее тело, конечно, не может быть частью операционного кода процессора, оно слишком длинно (может быть 2 Гигабайта, например), поэтому ей, в любом случае, отводится участок памяти (как правило, это местечко в секции данных или ресурсов), а уж в самом опкоде участвует адрес на первый символ (байт) строки. В случае с юникодом, символ придется трактовать как два байта, хотя процессору «это до лампочки».
Си тоже не далеко ушел. Там перед символом ставится «\», дабы компилятор не учитывал его как разделитель. Это все не сильно мешает, но все же не смотрится красиво. По-другому дела обстоят в Обероне, ПХП, Перле. Здесь я могу запросто использовать несколько видов ограничителей строк. При этом, остальные ограничители, входящие в строку, но не похожие на первый ограничитель, будут считаться как символы строки.
Например “Это строка ‘в одинарных’ кавычках”. Здесь ограничителем выступает первый из трех возможных символов – “. С таким же успехом я напишу: ‘Это строка “в двойных” кавычках’ и ограничителем будет считаться одинарная кавычка. Достаточно редко используются строки со смешанными кавычками, а тем более для нашего простенького языка, не претендующего (пока еще) на широкий спектр решения задач.
Не утомил я с теорией? В любом случае пора переходить к телу парсера. Перейдем к листингу 2, где опишем тело этого парсера:
procedure TAlisaScaner.SetText(const Value: string);
var
i // Перемнная для цикла. Будем с ее помошью посимвольно прходить
,BracketsCount // Переменная считающая кол-во вложенных скобочек
// Если появляется открывающая скобка переменная увеличивается
// если скобка закрывающая — уменьшается
// Когда переменная достигнет 0 — парсить больше нечего, ибо
// дистигнута последняя закрывающая скобка
:integer;
// Вспомагательные переменные, принимающие входной код
// и распарсенные операнды
// после того как очередной операнд получен
// он поступает в список
v,s:string;
// Эти переменные необходимы для того чтоб парсер попав на начало строки
// не растерялся, а получив первый символ ограничитель строки
// из указанных нами начал считать все символы до следующего
// такого же как контент строки
bs:char;
BracketsOfString:boolean;
begin
// Итак. Получаем код, не забыв заменить все переносы
// каретки на пробелы а так же отрезаем граничные пробелы чтоб не мешали
v:=trim(StringReplace(value,#13#10,‘ ‘,[rfreplaceall]));
// Учтем что в начале кода есть первая открывающая скобка
BracketsCount:=0;
// Чтоб она не мешала циклу удаляем ее
if v[1]=‘(‘ then delete(v,1,1);
// И закрывающую тоже, ибо текст
// поступающий на парсинг все равно будет
// считаться атомарным кодом
if v[length(v)]=‘)’ then delete(v,length(v),1);
// Приведем в готовность список операндов
Param.Clear; s:=»;
// Если парсить нечего то выйдем
if v=» then exit;
// Уберем лишние граничащие пробелы
v:=trim(v);
i:=1; bs:=#0; BracketsOfString:=false;
// И в цикле до конца текста
while (i<=length(v)) do begin
// Поскольку мы сочли пробел(ы) символом разделения операндов
// пройдемся циклом до следующего пробела
// или же до следующего символа ограничителя строки
while (i<=length(v))and(v[i]<>‘ ‘)or(BracketsCount>0)or BracketsOfString do begin
// Если появилась открывающая скобочка
// учтем ее, увеличив количество.
// Таким образом показывая что операнд может быть выражением,
// и нужно захватить
// весь его текст
if v[i]=‘(‘ then inc(BracketsCount);
// вплоть до его закрывающей скобки
if v[i]=‘)’ then dec(BracketsCount);
// Если появился символ ограничитель строки
// Перейдем в режим сканирования строки
if v[i] in [»»,‘"’,‘`’] then begin
if bs=#0 then begin bs:=v[i];BracketsOfString:=true;end else
if bs=v[i] then begin bs:=#0;BracketsOfString:=false;end;
end;
// Пересадим по символу в переменную, отделив очередной операнд
s:=s+v[i];inc(i);
end;
// После отделения поместим его в список
Param.Add(s);
s:=»;
// После того как получили очередной операнд отбросим
// копыта пробелам, что могут быть после него
while (i<=length(v))and(v[i]=‘ ‘) do begin inc(i);end;
end;
end;
var
i // Перемнная для цикла. Будем с ее помошью посимвольно прходить
,BracketsCount // Переменная считающая кол-во вложенных скобочек
// Если появляется открывающая скобка переменная увеличивается
// если скобка закрывающая — уменьшается
// Когда переменная достигнет 0 — парсить больше нечего, ибо
// дистигнута последняя закрывающая скобка
:integer;
// Вспомагательные переменные, принимающие входной код
// и распарсенные операнды
// после того как очередной операнд получен
// он поступает в список
v,s:string;
// Эти переменные необходимы для того чтоб парсер попав на начало строки
// не растерялся, а получив первый символ ограничитель строки
// из указанных нами начал считать все символы до следующего
// такого же как контент строки
bs:char;
BracketsOfString:boolean;
begin
// Итак. Получаем код, не забыв заменить все переносы
// каретки на пробелы а так же отрезаем граничные пробелы чтоб не мешали
v:=trim(StringReplace(value,#13#10,‘ ‘,[rfreplaceall]));
// Учтем что в начале кода есть первая открывающая скобка
BracketsCount:=0;
// Чтоб она не мешала циклу удаляем ее
if v[1]=‘(‘ then delete(v,1,1);
// И закрывающую тоже, ибо текст
// поступающий на парсинг все равно будет
// считаться атомарным кодом
if v[length(v)]=‘)’ then delete(v,length(v),1);
// Приведем в готовность список операндов
Param.Clear; s:=»;
// Если парсить нечего то выйдем
if v=» then exit;
// Уберем лишние граничащие пробелы
v:=trim(v);
i:=1; bs:=#0; BracketsOfString:=false;
// И в цикле до конца текста
while (i<=length(v)) do begin
// Поскольку мы сочли пробел(ы) символом разделения операндов
// пройдемся циклом до следующего пробела
// или же до следующего символа ограничителя строки
while (i<=length(v))and(v[i]<>‘ ‘)or(BracketsCount>0)or BracketsOfString do begin
// Если появилась открывающая скобочка
// учтем ее, увеличив количество.
// Таким образом показывая что операнд может быть выражением,
// и нужно захватить
// весь его текст
if v[i]=‘(‘ then inc(BracketsCount);
// вплоть до его закрывающей скобки
if v[i]=‘)’ then dec(BracketsCount);
// Если появился символ ограничитель строки
// Перейдем в режим сканирования строки
if v[i] in [»»,‘"’,‘`’] then begin
if bs=#0 then begin bs:=v[i];BracketsOfString:=true;end else
if bs=v[i] then begin bs:=#0;BracketsOfString:=false;end;
end;
// Пересадим по символу в переменную, отделив очередной операнд
s:=s+v[i];inc(i);
end;
// После отделения поместим его в список
Param.Add(s);
s:=»;
// После того как получили очередной операнд отбросим
// копыта пробелам, что могут быть после него
while (i<=length(v))and(v[i]=‘ ‘) do begin inc(i);end;
end;
end;
Что? Кода много? Да нет, просто я комментариями его обильно полил. На самом деле тут все просто. И простота эта сказалась благодаря семантике языка (привет ЛИСПу). Остается дополнить класс сервисными функциями:
constructor TAlisaScaner.Create;
begin
// Создадим экземпляр списка для операндов
Param:=TStringList.Create;
end;
destructor TAlisaScaner.Free;
begin
// Освободим его
Param.Free;Param:=nil;
end;
function TAlisaScaner.GetItem(i: integer): string;
begin
// Свойство получения конкретного
// операнда по списку. Если индекс не указывает на
// элемент списка, возвращается просто пустая строка
if (i>=0)and(i<Param.Count) then
Result:=Param[i] else Result:=»;
end;
function TAlisaScaner.High: Integer;
begin
// Этот метод не обязателен
// как я и говорил можно обойтись без него
// Но мне влом писать в циклах с -1’ой
Result:=Param.Count-1;
end;
begin
// Создадим экземпляр списка для операндов
Param:=TStringList.Create;
end;
destructor TAlisaScaner.Free;
begin
// Освободим его
Param.Free;Param:=nil;
end;
function TAlisaScaner.GetItem(i: integer): string;
begin
// Свойство получения конкретного
// операнда по списку. Если индекс не указывает на
// элемент списка, возвращается просто пустая строка
if (i>=0)and(i<Param.Count) then
Result:=Param[i] else Result:=»;
end;
function TAlisaScaner.High: Integer;
begin
// Этот метод не обязателен
// как я и говорил можно обойтись без него
// Но мне влом писать в циклах с -1’ой
Result:=Param.Count-1;
end;
Так-с… класс описан. В принципе его можно опробовать. В предыдущих статьях были примеры кода, предполагалось, что все они будут находиться в одном модуле, соответственно и эти листинги нужно кинуть туда же (в приложениях к статье я прикреплю действующий пример). Кстати, если любопытный читатель уже успел скопипастить код и попытался его откомпилировать, не мог не заметить, что компилятор ругается. И прежде всего на отсутствие в разделе uses модулей classes, sysutils.
Какой вывод? Не спешить! А если не терпится попробовать, привыкайте к тому, что у авторов статей, книг… что вы там читаете… могу быть другие условия работы. Например, частенько описанные в книгах приемы просто-напросто заточены под конкретную версию компилятора, и на других не то что не сработают, а просто требуют мелких поправок «там-сям».
Ладно, оставим лирику. Для проверки предлагаю сделать форму (нам же понадобится редактор для кода), на которой будет красоваться. Для начала компонент TMemo. Для начала, потому что в дальнейшем, возможно, захочется разными цветами подсвечивать ключевые слова, а в Мемо это не столь удобно. Но пока хватит и Мемо.
Кстати, для красоты Мемо можно выровнять на всю форму, задав свойству Aling значение alClient. Далее кинем на форму TActionManager. Кликнув по нему правой клавишей мышки, создадим новую акцию. Для ее свойства ShortCut поставим клавишу F9 – эта акция будет срабатывать по нажатию на F9, дабы запускать компилятор. Рядом же кинем ListBox, задав ему Align как alBottom. Пусть лежит внизу. Туда мы будем выводить то, что нам парсер выделит из выражения. Это для проверки, чтобы убедится, что парсер работает как надо.
Не забудем «привинтить» поле этого класса (или переменную, кому как больше нравится). Например, как в следующем листинге:
TForm1 = class(TForm)
Memo1: TMemo;
ActionManager1: TActionManager;
Action1: TAction;
ListBox1: TListBox;
procedure Action1Execute(Sender: TObject);
private
sc:TAlisaScaner;
{ Private declarations }
public
{ Public declarations }
end;
Memo1: TMemo;
ActionManager1: TActionManager;
Action1: TAction;
ListBox1: TListBox;
procedure Action1Execute(Sender: TObject);
private
sc:TAlisaScaner;
{ Private declarations }
public
{ Public declarations }
end;
Это стандартный набор для приложения, я не буду его описывать. Исключение составляет поле класса парсера. В событии OnExecute() этой акции напишем следующий код:
procedure TForm1.Action1Execute(Sender: TObject);
procedure parse(Atext:String);
var i:integer; sc:TAlisaScaner;
begin sc:=TAlisaScaner.Create;
ss:=ss+‘ ‘;
// Заряжаем текст на парсинг
sc.Text:=aText;
// Оператор помести сразу пометив его как команду
ListBox1.Items.Add(ss+‘Начало оператора ‘+sc[0]);
// Отработав это свойство сформирует список, который поэлементно
// пройдем, обратившись к предусмотрительно
// оформленному полю сканера по умолчанию в цикле
for i:=1 to sc.High do begin
// Если попался оператор рекурсивно вызовем процедуру
// передав ей операнд-оператор. Пусть распарсит
if sc[i][1]=‘(‘ then parse(sc[i])
else ListBox1.Items.Add(ss+sc[i]);
end;
ListBox1.Items.Add(ss+‘Конец оператора ‘+sc[0]);
delete(ss,1,1);
sc.Free;
end;
begin
ss:=‘ ‘;
parse(Memo1.Lines.Text);
end;
procedure parse(Atext:String);
var i:integer; sc:TAlisaScaner;
begin sc:=TAlisaScaner.Create;
ss:=ss+‘ ‘;
// Заряжаем текст на парсинг
sc.Text:=aText;
// Оператор помести сразу пометив его как команду
ListBox1.Items.Add(ss+‘Начало оператора ‘+sc[0]);
// Отработав это свойство сформирует список, который поэлементно
// пройдем, обратившись к предусмотрительно
// оформленному полю сканера по умолчанию в цикле
for i:=1 to sc.High do begin
// Если попался оператор рекурсивно вызовем процедуру
// передав ей операнд-оператор. Пусть распарсит
if sc[i][1]=‘(‘ then parse(sc[i])
else ListBox1.Items.Add(ss+sc[i]);
end;
ListBox1.Items.Add(ss+‘Конец оператора ‘+sc[0]);
delete(ss,1,1);
sc.Free;
end;
begin
ss:=‘ ‘;
parse(Memo1.Lines.Text);
end;
Здесь для каждого выражения создается отдельный сканнер, выражение парсится на операнды, и, если очередной операнд представляет собой вложенное выражение, идет рекурсивный вызов этой процедуры, передавая ей операнд. И так на любое количество вложений (ну, почти на любое, насколько компилятору стека хватит).
Пока что не будем вводить в игру сам компилятор. До него еще рано. Запустим программу и впишем в Мемо наше выражение (для удобства можно прямо в дизайне вписать его в свойство Lines, чтоб не вписывать каждый раз. Нажмем F9 – сработает наш парсер, разобрав выражения на части (см. рисунок 2):

Рис. 2. Парсинг выражения
Как видно, парсер справился с задачей. Выражение разобрано, разобрано правильно, все операнды на своих местах по вложенности. И ведь так можно разобрать достаточно сложное выражение. А нам, на все про все, хватило всего лишь строк около 50-ти (сам механизм парсера и обработчик нажатия F9). Следует отметить, что ЛИСПовские операторы достаточно просто запрограммировать, несмотря на кажущуюся сложность. Это потому что приоритеты операторов выделяет сам программист при написании выражения. Интересно, а чего будет стоить написать парсер для выражения, где операции находятся между операндами? Как в Си или в паскале.
Вполне возможно, что придется сначала рассчитывать операторы высшего приоритета, для этого еще их и их операнды нужно вычленить из выражения, это притом, что стоять они могут где угодно… Мы обошлись одним проходом – от начала строки в ее конец. Это радует простотой и скоростью разбора. А что будет при разборе выражения вроде нашего (2+2)+18/(32+sin(pi/3.4))? Обратите внимание, я специально заменил знак умножения в формуле на «+», дабы усложнить ситуацию, ведь в этом случае рассчитав 2+2, нельзя сразу к результату прибавлять 18. Значит, придется либо запоминать в некий стек эту 18, либо сначала пройтись по оператору деления и вычислять не с начала, а с конца. Ладно, допустим. А как такое выражение****: 5+2*(4-1/3)^2*36^3+28.
Что тут вычислять сначала? Явно не с конца. Сначала придется вычислить (4-1/3)^2, потом 36^3. Запомнить результаты вычисления где-то, а уж потом умножение и сложения. Уверен, что строк кода такого парсера будет поболее, чем в нашем случае.
Pull the trigger to start
Теперь можно попробовать скомпилировать это выражение в опкоды, и запихнуть в РЕ файл. Сразу предлагаю для простоты убрать вычисление синуса. Оперировать будем с целыми числами, размера DWord, Этого вполне хватит пока что.
Заменим наше выражение на (2*2)+16/(10-(20/4)). Тут четыре основных операции, не так будет много кода для них. Это выражение будет выглядеть по-нашему вот так:
(/ (+ 16 (* 2 2)) (- 10 (/ 20 4)) )
Это выражение будет равно четырем. Учтем, что деление будет производиться стандартными опкодами процессора, и операнды целочисленные, а значит, результат операции деления будет целое без остатка. Остаток пока что не будем учитывать. То есть, это будет аналог 20 div 4 в паскале. Самое главное, что это выражение достаточно простое. Здесь, во-первых, задействованы все четыре оператора, а во-вторых, деления получаются без остатка – сейчас это нам важно.
Теперь самая главная задача – выяснить на собственных ошибках (ибо ничего так не вправляет мозги как хождение по своим же граблям), чего будет стоить механизм, использующий эти простейшие операторы. Именно отсюда можно будет развить стратегию работы с другими операторами, увидев какую методику проще будет использовать. Далее, парсер, разбирая выражение, дает возможность оперировать отдельными операндами. Кроме того, у нас несколько операций. Попробуем описать примерно следующую схему:
- после разбора выражения в цикле пройтись по выражению, передав некой процедуре (назовем ее kernel) очередной операнд;
- эта процедура должна будет определить, какова операция должна быть проведена над данным операндом, и вызвать соответствующий код, который можно для удобства выделить в отдельную процедурку;
- эта отдельная процедурка будет заниматься конкретным операндом и конкретным действием.
Получается, что нам нужно пять процедур – четыре действия и их менеджер. Прекрасненько. Начнем с того, что опишем kernel – процедуру посредник между циклом, который проходится по разпарсенным операндам и процедурой непосредственного транслирования в опкоды. Она может выглядеть так:
procedure kernel(
NumOfOperand:integer; // Номер операнда по счету
fromStack:boolean // Указание, что работать нужно с
// результатом вложенного выражения
);
var o:integer;
begin
// получение значения по номеру операнда из выражения
// Если идет работа с вложенным выражением его значение
// предполагается либо в стеке либо в регистре-аккумуляторе
if not fromStack then o:=StrToInt(sc[NumOfOperand]) else o:=0;
// вызов процедур-трансляторов согласно операции
// и передача им информации
if sc[0]=‘+’ then plus(o,NumOfOperand,fromStack);
if sc[0]=‘-‘ then minus(o,NumOfOperand,fromStack);
if sc[0]=‘*’ then mul(o,NumOfOperand,fromStack);
if sc[0]=‘/’ then div_(o,NumOfOperand,fromStack);
end;
NumOfOperand:integer; // Номер операнда по счету
fromStack:boolean // Указание, что работать нужно с
// результатом вложенного выражения
);
var o:integer;
begin
// получение значения по номеру операнда из выражения
// Если идет работа с вложенным выражением его значение
// предполагается либо в стеке либо в регистре-аккумуляторе
if not fromStack then o:=StrToInt(sc[NumOfOperand]) else o:=0;
// вызов процедур-трансляторов согласно операции
// и передача им информации
if sc[0]=‘+’ then plus(o,NumOfOperand,fromStack);
if sc[0]=‘-‘ then minus(o,NumOfOperand,fromStack);
if sc[0]=‘*’ then mul(o,NumOfOperand,fromStack);
if sc[0]=‘/’ then div_(o,NumOfOperand,fromStack);
end;
Думаю здесь понятно – эта процедура распределяет по операциям операнды. Вызов ее нужно «прикрутить» непосредственно в цикл, пробегающий по элементам выражения в предыдущем листинге следующим образом:
begin
sc:=TAlisaScaner.Create;
ss:=ss+‘ ‘;
// Заряжаем текст на парсинг
sc.Text:=aText;
// Оператор помести сразу пометив его как команду
ListBox1.Items.Add(ss+‘Начало оператора ‘+sc[0]);
// Отработав это свойство сформирует список, который поэлементно
// пройдем, обратившись к предусмотрительно
// оформленному полю сканера по умолчанию в цикле
for i:=1 to sc.High do begin
// Если попался оператор рекурсивно вызовем процедуру
// передав ей операнд-оператор. Пусть распарсит
if sc[i][1]=‘(‘ then begin
//**********************************************************************
// Если обнаружено вложенное выражение
// запомнить предидущий результат в стеке
cdata:=cdata+#$50;// PUSH EAX
// Разобрать подвыражение
parse(sc[i]);
// и передать управление процедуре-распределителю
// указав что работать нужно не с константой а с результатом
// разобранного (и поскольку тут рекурсия скомпилированного)
// выражения
kernel(i,true);
// Незабыть убрать в стеке после себя мусор.
// Все что посчитанно должно хранится в аккумуляторе EAX
cdata:=cdata+#$83#$C4#$04;// ADD ESP, 4
end else begin
// Если же этот операнд — константа
// то передать указания работать с ней
kernel(i,false);
//**********************************************************************
ListBox1.Items.Add(ss+sc[i]);
end;
end;
ListBox1.Items.Add(ss+‘Конец оператора ‘+sc[0]);
delete(ss,1,1);
sc.Free;
end;
sc:=TAlisaScaner.Create;
ss:=ss+‘ ‘;
// Заряжаем текст на парсинг
sc.Text:=aText;
// Оператор помести сразу пометив его как команду
ListBox1.Items.Add(ss+‘Начало оператора ‘+sc[0]);
// Отработав это свойство сформирует список, который поэлементно
// пройдем, обратившись к предусмотрительно
// оформленному полю сканера по умолчанию в цикле
for i:=1 to sc.High do begin
// Если попался оператор рекурсивно вызовем процедуру
// передав ей операнд-оператор. Пусть распарсит
if sc[i][1]=‘(‘ then begin
//**********************************************************************
// Если обнаружено вложенное выражение
// запомнить предидущий результат в стеке
cdata:=cdata+#$50;// PUSH EAX
// Разобрать подвыражение
parse(sc[i]);
// и передать управление процедуре-распределителю
// указав что работать нужно не с константой а с результатом
// разобранного (и поскольку тут рекурсия скомпилированного)
// выражения
kernel(i,true);
// Незабыть убрать в стеке после себя мусор.
// Все что посчитанно должно хранится в аккумуляторе EAX
cdata:=cdata+#$83#$C4#$04;// ADD ESP, 4
end else begin
// Если же этот операнд — константа
// то передать указания работать с ней
kernel(i,false);
//**********************************************************************
ListBox1.Items.Add(ss+sc[i]);
end;
end;
ListBox1.Items.Add(ss+‘Конец оператора ‘+sc[0]);
delete(ss,1,1);
sc.Free;
end;
Я отделил изменения специально, чтобы показать, где они могут стоять в нашем случае. Теперь остается описать сами процедуры-трансляторы:
//***** Сложение *********************************
procedure plus(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
// Если работа идет с операндом-константой
// Если это первый операнд, то подготовим регистр, кинув в него
// первый операнд
if num=1 then cdata:=cdata+#$B8+DWordToStr(Operand)
else
// Иначе прибавим к регистру очередной операнд
cdata:=cdata+#$05+DWordToStr(Operand);
end else
// Если же работа должна идти с уже посчитанным результатом
// то нужно прибавить его значение из стека
cdata:=cdata+#$03#$04#$24; //ADD EAX, DWORD PTR SS:[ESP]
end;
//**************************************
procedure plus(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
// Если работа идет с операндом-константой
// Если это первый операнд, то подготовим регистр, кинув в него
// первый операнд
if num=1 then cdata:=cdata+#$B8+DWordToStr(Operand)
else
// Иначе прибавим к регистру очередной операнд
cdata:=cdata+#$05+DWordToStr(Operand);
end else
// Если же работа должна идти с уже посчитанным результатом
// то нужно прибавить его значение из стека
cdata:=cdata+#$03#$04#$24; //ADD EAX, DWORD PTR SS:[ESP]
end;
//**************************************
Тут все просто и понятно. Вообще процедура сложения достаточно удобна для транслирования. Ее двояко трактовать не приходится, потому, как от перестановки слагаемых сумма-то не меняется. Теперь процедура вычитания:
//***** Вычитание *********************************
procedure minus(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
if num=1 then
// Если это первый операнд положим его в регистр-аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
else
// иначе отнимем константу от значения в регистре
cdata:=cdata+#$2D+DWordToStr(Operand);
end else begin
// Если же это работа с результатом выражения
// Придется вычитать значение от результата в стеке
// А уж потом вложить полученное в аккумулятор
cdata:=cdata+#$29#$04#$24;//SUB DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$8B#$04#$24;//MOV EAX, DWORD PTR SS:[ESP]
end;
end;
//**************************************
procedure minus(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
if num=1 then
// Если это первый операнд положим его в регистр-аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
else
// иначе отнимем константу от значения в регистре
cdata:=cdata+#$2D+DWordToStr(Operand);
end else begin
// Если же это работа с результатом выражения
// Придется вычитать значение от результата в стеке
// А уж потом вложить полученное в аккумулятор
cdata:=cdata+#$29#$04#$24;//SUB DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$8B#$04#$24;//MOV EAX, DWORD PTR SS:[ESP]
end;
end;
//**************************************
Здесь уже четко просматриваются отличия. Результат операции вычитания зависит от того, как расположены его операнды – это важно. Значит можно сделать вывод – на самом деле трансляцию каждой операции стоит оформлять отдельно, не смешивая в кучу. Можно, безусловно, написать одну процедуру, которая в зависимости от операции будет проводить нужный опкод в результирующую последовательность для экзешника, но это будет нормально при четырех, десяти простейших операциях, а если захочется дальше развить компилятор? Такая универсальная процедура, скорее всего, разрастется в «мегазапутанный» код, который потом на самого автора будет навевать ужас. Тут не то что обфускация может получиться, а даже как любят выражаться программисты «гххх-код», то есть запутанный, неоптимальный, зачастую наполненный бессмысленными операциями, код. Любого хакера будет рвать вдоль и поперек при виде такого монстра.
Поэтому, несмотря на кажущуюся выгодную позицию – упихнуть все в одну процедуру, предлагаю этого не делать. Пусть каждая процедура, а еще лучше каждый класс, занимается своим и только своим делом.
Далее следуют процедуры умножения и деления:
//***** умножение *********************************
procedure mul(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
if num=1 then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
else begin
// иначе умножим. При этом нам придется задействовать
// дополнительный регистр потому как операция умножения
// и кстати деления не допускает указания в качестве
// операнда константу.
// Ну выберем регистр DX.
cdata:=cdata+#$BA+DWordToStr(Operand);//MOV EDX, …
cdata:=cdata+#$F7#$E2; //MUL ЕDХ
end;
end else begin
// Если же работать нужно с результатом подвыражения
// умножим результат из стека на значение в аккумуляторе
cdata:=cdata+#$F7#$24#$24; //MUL WORD PTR SS:[ESP]
end;
end;
//**************************************
//***** деление *********************************
procedure div_(Operand,num:integer;fromStack:boolean);
begin
if num=1 then begin
if not fromStack then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
end else begin
if not fromStack then begin
// иначе задействовав дополнительный регистр
// перемножим константу на значение в аккумуляторе
cdata:=cdata+#$BB+DWordToStr(Operand);//MOV EВX, …
cdata:=cdata+#$F7#$F3; //DIV EВX
end else begin
// Если же работа предстоит с уже посчитанным значением
// подвыражения придется делить на значение из стека.
// предварительно не забыв поменять местами
// поскольку операция деления как и вычитания тоже строга
// к положениям операндов
cdata:=cdata+#$87#$04#$24; //XCHG DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$F7#$34#$24; //DIV DWORD PTR SS:[ESP]
end;
end;
end;
//**************************************
procedure mul(Operand,num:integer;fromStack:boolean);
begin
if not fromStack then begin
if num=1 then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
else begin
// иначе умножим. При этом нам придется задействовать
// дополнительный регистр потому как операция умножения
// и кстати деления не допускает указания в качестве
// операнда константу.
// Ну выберем регистр DX.
cdata:=cdata+#$BA+DWordToStr(Operand);//MOV EDX, …
cdata:=cdata+#$F7#$E2; //MUL ЕDХ
end;
end else begin
// Если же работать нужно с результатом подвыражения
// умножим результат из стека на значение в аккумуляторе
cdata:=cdata+#$F7#$24#$24; //MUL WORD PTR SS:[ESP]
end;
end;
//**************************************
//***** деление *********************************
procedure div_(Operand,num:integer;fromStack:boolean);
begin
if num=1 then begin
if not fromStack then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
end else begin
if not fromStack then begin
// иначе задействовав дополнительный регистр
// перемножим константу на значение в аккумуляторе
cdata:=cdata+#$BB+DWordToStr(Operand);//MOV EВX, …
cdata:=cdata+#$F7#$F3; //DIV EВX
end else begin
// Если же работа предстоит с уже посчитанным значением
// подвыражения придется делить на значение из стека.
// предварительно не забыв поменять местами
// поскольку операция деления как и вычитания тоже строга
// к положениям операндов
cdata:=cdata+#$87#$04#$24; //XCHG DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$F7#$34#$24; //DIV DWORD PTR SS:[ESP]
end;
end;
end;
//**************************************
Здесь тоже наметились грабли. С умножением еще кое-как нормально, а вот с делением сложности на горизонте. Во-первых, физиология деления достаточно непроста, если заглянуть в мануалы. В них сказано, что для деления разного, м-м-м, размера чисел, задействуются разные механизмы. При делении на двойное слово, как раз наш случай, задействуются регистры EDX (остаток от деления) и EAX (целая часть от деления), так что, если EDX предполагается задействовать для чего-либо, его предварительно стоит сохранить в стек. Пока не будем на этом останавливаться, потому как при делении на результат из стека его придется либо выбирать в регистр, скажем, тот же EBX, либо делить на SS:[ESP+4]. Но все равно, на будущее, стоит это учесть.
А так, в целом, для работы с константами и вложенными выражениями этого должно вполне хватить. Предлагаю попробовать в действии. Для этого «прикрутим» к проекту переменную типа TAlisaCompiler3. В прошлой статье я описал этот класс для генерации РЕ файла. В его поле открытым тестом, для чего в листингах служит переменная cdata, описанная как String, будем передавать отранслированный операционный код, и записывать скомпилированный с этим кодом контент в файл. Вот как это будет выглядеть:
var comp:TAlisaCompiler3;f:file of byte;
begin
// На всякий случай сохраним наш исходный код
Memo1.Lines.SaveToFile(ExtractFilePath(ParamStr(0))+‘file.source’);
ss:=‘ ‘; cdata:=»;
// Переведем исходний код в операционный
parse(Memo1.Lines.Text);
// который будет передан обьекту-компилятору
comp:=TAlisaCompiler3.Create;
comp._Code._Data:=cdata;
// и скомпилирован
cdata:=comp.Compile;
// после чего контент РЕ пойдет в пункт назначения
AssignFile(f,‘file.exe’);rewrite(f);
BlockWrite(f,cdata[1],length(cdata));
CloseFile(f);
comp.Free;
end;
begin
// На всякий случай сохраним наш исходный код
Memo1.Lines.SaveToFile(ExtractFilePath(ParamStr(0))+‘file.source’);
ss:=‘ ‘; cdata:=»;
// Переведем исходний код в операционный
parse(Memo1.Lines.Text);
// который будет передан обьекту-компилятору
comp:=TAlisaCompiler3.Create;
comp._Code._Data:=cdata;
// и скомпилирован
cdata:=comp.Compile;
// после чего контент РЕ пойдет в пункт назначения
AssignFile(f,‘file.exe’);rewrite(f);
BlockWrite(f,cdata[1],length(cdata));
CloseFile(f);
comp.Free;
end;
Хорошо, что у нас уже наготове РЕ генератор: как просто передать ему контент, не заморачиваясь о том, как устроен РЕ, и какие пертурбации в нем будут происходить. Кстати, этот код можно подкинуть в обработчик клика по кнопке, элемента меню… Да куда угодно, в целом. Я предлагаю разместить его в обработчике нажатия клавиши F9, для чего и использовал TActionManager. Вот выше в процедуру TForm1.Action1Execute(), его и стоит вставить. Если все сделано правильно, то запустим программу, введем выражение и нажмем на F9 (см. рисунок 3):
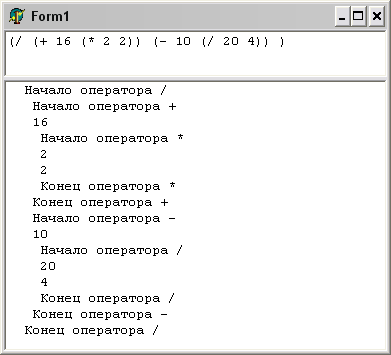
Рис. 3. Редактор исходного кода
Как все было, так и осталось. Единственное, что в папке с программой появится исполняемый файл с скомпилированным выражением. Давайте посмотрим на него сквозь микроскоп отладчика (см. рисунок 4):
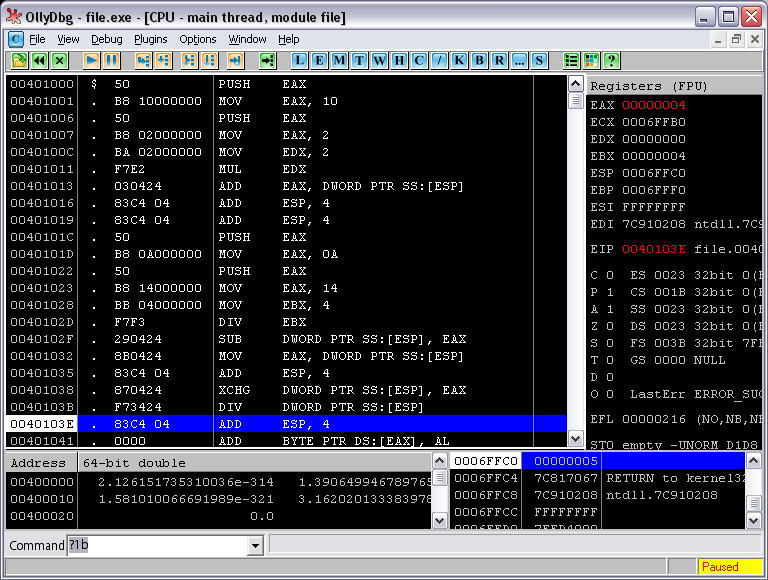
Рис. 4. Скомпилированное выражение
Что-то записало… Если пройтись пошагово (F8 в Оле), то можно увидеть как выражение, оживая, дает плоды в виде результирующего числа, для каждого вложенного выражения, и для всего целиком. В аккумуляторе в результате появляется заветная 4, что говорит о том, что выражение правильно посчитано. Это радует. А давайте попробуем теперь проверить на другом выражении. Скажем, на вот таком:
1+3+5+(8-10)+(10/2)+(3*(8+2))
Вводим в редактор выражение «по-ЛИСПовски»: (+ 1 3 5 (- 8 10) (/ 10 2) (* 3 (+ 8 2)))
Жмем F9, открываем отладчик, проходимся по шагам и… жестоко ****** «обламываемся» (см. рисунок 5):
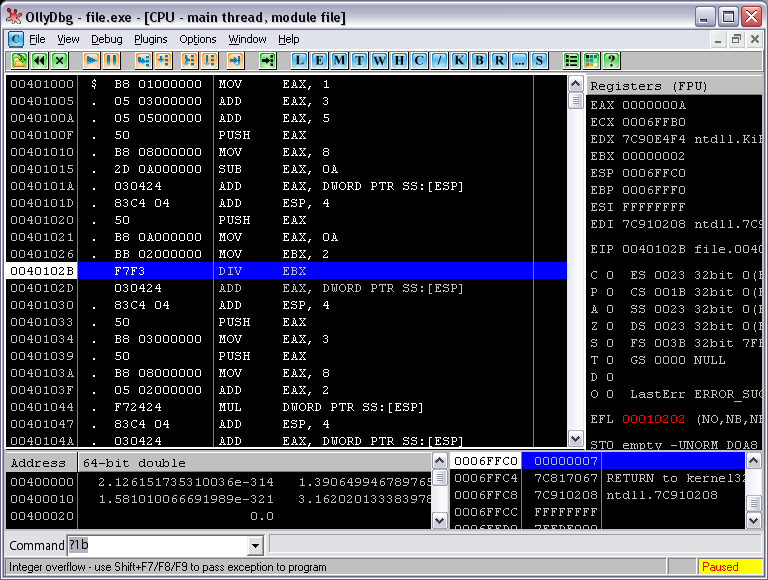
Рис. 5. Грабли
Видите внизу посказку Оли?: «Integer overflow».
Так, теперь будем думать (предположим, что ассемблер мы знаем… ну на троечку как максимум) почему это произошло. Проанализируем ситуацию – Деление. Задействовано три регистра: EAX – туда будет помещено частное, EDX – для остатка, EBX – сам операнд. Логика подсказывает, что копать нужно в сторону особенностей работы деления не с исходными, а с получаемыми значениями. Как происходит сам механизм деления? Div делит число из EBX (это 2 – посмотрите на рисунок 5) на число из пары регистров EAX:EDX. В ЕАХ записано «А», что равно 10-ти в десятичной системе, а в EDX записан какой-то адрес. Механизм деления, если делится двойное слово, затрагивает оба этих регистров и оба они должны быть предварительно проинициализированы делимым, но делимое наше не велико, и вполне умещается в АХ (или даже в AL), MOV EAX, A0 занимает под двадцатку весь регистр, все 32 бита. А что же происходит с EDX? А ничего. Мы забыли о нем, в нем остался мусор после действия некой функции (какой-то там, сейчас не важно), но команда деления, учитывая его, воспринимает его содержимое как число, участвующее в делении – старшую часть числа из ЕАХ, а там 7C910208, что равно 2089878024. Итого, получается 2 делим на 20898780240000000020… Так что ли? О, ужас! Вот оно переполнение. О чем нам это говорит?
- Нужно обнулять EDX перед делением, ну или если это важно запоминать его значение где-нибудь.
- Бегом читать умные книги по ассемблеру
Программу подкорректировать несложно:
//***** деление *********************************
procedure div_(Operand,num:integer;fromStack:boolean);
begin
if num=1 then begin
if not fromStack then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
end else begin
if not fromStack then begin
// иначе задействовав дополнительный регистр
// перемножим константу на значение в аккумуляторе
cdata:=cdata+#$BB+DWordToStr(Operand);//MOV EBX, …
cdata:=cdata+#$33#$D2; //XOR EDX, EDX
cdata:=cdata+#$F7#$F3; //DIV EBX
end else begin
// Если же работа предстоит с уже посчитанным значением
// подвыражения придется делить на значение из стека.
// предварительно не забыв поменять местами
// поскольку операция деления как и вычитания тоже строга
// к положениям операндов
cdata:=cdata+#$87#$04#$24; //XCHG DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$33#$D2; //XOR EDX, EDX
cdata:=cdata+#$F7#$34#$24; //DIV DWORD PTR SS:[ESP]
end;
end;
end;
//**************************************
procedure div_(Operand,num:integer;fromStack:boolean);
begin
if num=1 then begin
if not fromStack then
// Если это первый операнд положим его в аккумулятор
cdata:=cdata+#$B8+DWordToStr(Operand)
end else begin
if not fromStack then begin
// иначе задействовав дополнительный регистр
// перемножим константу на значение в аккумуляторе
cdata:=cdata+#$BB+DWordToStr(Operand);//MOV EBX, …
cdata:=cdata+#$33#$D2; //XOR EDX, EDX
cdata:=cdata+#$F7#$F3; //DIV EBX
end else begin
// Если же работа предстоит с уже посчитанным значением
// подвыражения придется делить на значение из стека.
// предварительно не забыв поменять местами
// поскольку операция деления как и вычитания тоже строга
// к положениям операндов
cdata:=cdata+#$87#$04#$24; //XCHG DWORD PTR SS:[ESP], EAX
cdata:=cdata+#$33#$D2; //XOR EDX, EDX
cdata:=cdata+#$F7#$34#$24; //DIV DWORD PTR SS:[ESP]
end;
end;
end;
//**************************************
Исправили? Ну-ка проверим на деле (см. рисунок 6):
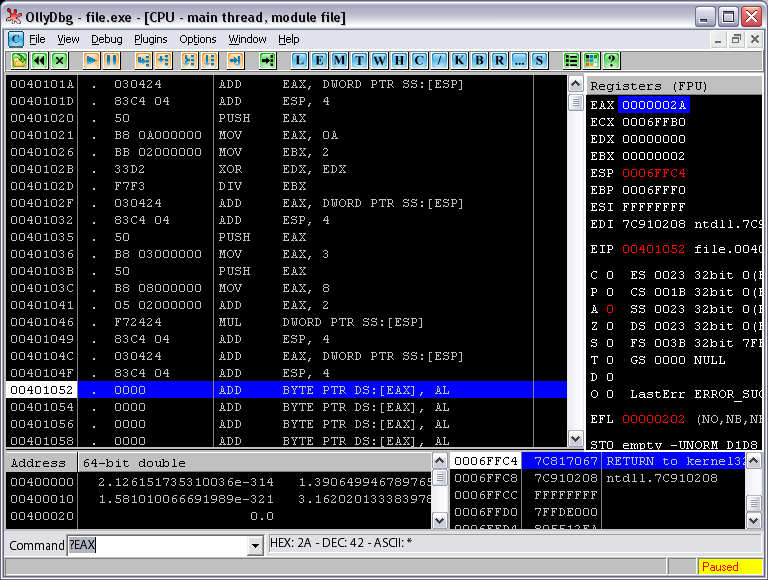
Рис. 6. Исправленный баг
Во. Теперь порядок 42 (2А в ЕАХ) – тот самый результат выражения. Как раз то, что нужно.
Post Scriptum
Ну вот. Теперь можно спокойно фантазировать, придумывая самые замысловатые выражения с многочисленными вложенными выражениями – эту возможность дарит нам рекурсия. Одно жаль – не удастся малой кровью написать универсальную процедуру, которая бы вмещала в себя все операторы. У каждого оператора свои особенности, и их все желательно… то есть, нет… не желательно, а просто необходимо учитывать. Именно поэтому стоит для каждого оператора (я имею ввиду встроенные в язык операторы – ключевые слова) описать свой отдельный класс. Дабы он занимался только им и никем более. Единственное, что более-менее может быть общего у всех этих классов – цикл, проходящий по операндам, передающий их классу. Это да. Опять-таки в этом цикле можно предусмотреть возможность определения типов операндов, если операнд-функция – вызова этой функции, и последующей работы с ее результатом, если это переменная – определение ее типа, приведение к единому типу – типу выражения.
Поправьте меня, по-моему, умными людьми принято проводить тип по первому операнду. Вполне можно взять и это на вооружение, и это (думается мне) тоже может иметь единый механизм для всех классов, занимающихся операторами. А так, стало быть, можно унаследовать классы, обработчики операторов от одного родителя, в котором и будет заряжен этот цикл, в котором будут вызываться стандартные методы для этих классов. Их там много не будет: метод обработки при константе-операнде, метод обработки, если операнд – переменная, метод обработки при операнде-функции и метод при операнде-выражении. Для старта, по крайней мере, хватит с головой. Можно конечно описывать все процедурами, как выше, но мы то живем в век ООП.
Поэтому в следующей части я покажу свое видение все этой жуткой схемы с классами-обработчиками операторов. А на сегодня, все. Всем доброго времени суток, где бы вы ни находились.
The Чтиво
- Официальный сайт журнала «ПРОграммист» — Раздел загрузки
- Ресурс Викпедии http://ru.wikipedia.org/wiki/Зарезервированное_слово
Статья из десятого выпуска журнала «ПРОграммист».
Обсудить на форуме — Компилятор домашнего приготовления. Часть 3
Похожие статьи
Купить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
