

Последние записи
- Joomla 3.8 — Автоматическая авторизация по IP автоматически созданного временного пользователя с принадлежностью к заданной группе
- Конвертация MOV to MP4
- Автоматическое уничтожение объектов
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
27th
Фев
 Компилятор домашнего приготовления. Часть 4
Компилятор домашнего приготовления. Часть 4
Posted by Chas under Журнал, Статьи
Знаете, я все думал: «С чего бы продолжить написание компилятора, какой следующий шаг важнее?». Описать механизм операторов? Так к ним неплохо бы переменные, и функции могут участвовать в операциях. Описать механизм функций, опять-таки они без операторов – ничто. Описать механизм переменных? Но далеко не все типы можно обработать без функций… Дилемма. И все же продолжать с чего-то надо. А раз надо – почему бы не продолжить с того, что первое придет в голову, все равно придеться много раз править проект все новыми и новыми «фичами»…
Adding again and again…
Итак, давайте припомним, на чем мы остановились. В прошлый раз нам удалось описать парсер выражений для нашего языка. Парсер простейший. Незачем было наворачивать его всякими сложностями. Благо ЛИСПоподобность языка не требует особых телодвижений. Теперь главная задача, используя этот парсер, оттранслировать выражения, им разобранные в операционные коды, которые в результате должны сложится в программу, заставляющую процессор (ну или в принципе компьютер) просчитать выражение, и что-то сделать с результатом. Тут подвох – что делать с результатом? Понятно, что он останется в регистрах (если конечно речь идет о числах, строки массивы и прочие пока не рассматриваем), но регистр – хранилище временное, посему результат нужно выбрать куда-то. И естественно самое идеальное хранилище для него – переменная. Значит нужно работать в двух направлениях: Компиляция выражений и работа с переменными. Именно этим и займемся в ближайшее время.
Начнем, пожалуй, с устройства работы с переменными, потом уже не будем их трогать, а вплотную займемся выражениями – там больше кода будет, как ни крути. Итак, переменные. Это именованная часть хранилища (в нашем случае ОЗУ, поскольку хранилища на, скажем, жестком диске не принято называть переменными). Для хранения данных в исполнимых файлах обычно отводят секцию данных. Она может быть виртуальной, т.е. изначальные данные переменных не хранятся в файле, в этом случае переменные придется инициализировать уже в ходе программы. Это не сложно, но умные оптимизаторы стараются (и правильно делают) высчитать значения переменной до начала программы, если это возможно. Конечно же, потом, в ходе работы программы ее значение уже высчитывает процессор (мы рассмотрим, как это происходит, и будем активно это использовать) но начальное значение переменной вполне можно определить в ходе компиляции. Есть еще вариант хранения переменных в свободной памяти. Путем вызова функций ОС, с просьбой зарезервировать память подо что-то, можно динамически определить переменную в ходе самой работы. Кстати еще вариант – хранить переменные в стеке. Локальные переменные процедур и функций популярные компиляторы (а может и все) например, хранят в стеке, и это определяет их область видимости. А что, удобно. Закончилась процедура – указатель стека сместился, считается, что все данные выше его затерлись, хотя на самом деле их значения остались. Их можно достать при огромном желании, но смысла нет особого. На то она и область видимости, чтоб ее соблюдать. Для начала договоримся, чтоб себе жизнь упростить, что все наши переменные будут глобальными. Да, да. Именно глобальными. На просторах интернета целые орды программистов будут топтать сапогами саму идею использования глобальных переменных – это субъективные мнения. Глобальные переменные не так уж и опасны, если без применения мозгов использовать локальные переменные они могут натворить куда больше беды. К тому же пока что не требуется наворачивать компилятор работой с областями видимости. Потом когда функции пойдут можно будет подумать о том, как работать с переменными локальными.
Становится задача – описать механизмы «переименизации», которые будут связаны с некой секцией в программе – секцией данных. Помните, во второй части мы описали класс TAlisaSection. Тот, который отвечал у нас за компиляцию секции? Поскольку переменные должны принадлежать именно секции, логично прикрутить к нему методы работы с этими переменными. Но для начала предлагаю описать сам класс для механизмов переменных.
Давайте подумаем, чем должна характеризоваться переменная:
- Имя переменной – переменная может не иметь имени, для нее это не главное, для компилятора тоже, а вот для человека это основной мостик к пониманию, что где хранится. Имя переменной должно быть представлено символами, на понятном для человека языке и не содержать разделителей операндов. В нашем случае не содержать пробелов. Ну, это не проблема, программисты пробелы не любят в именах итак. Кстати, предлагаю не ограничиваться в выборе символов для имени. Любой язык, любая длина имени, практически любые символы.
- Ее адрес – если точнее смещение относительно секции. Я, как и сказано выше, сейчас предлагаю не заморачиваться над динамически создаваемыми переменными, указателями и прочими нямками программирования. Пока хватит с головой простого смещения относительно секции данных.
- Секция – раз уж мы решили использовать именно смещение, то нужно знать и базу, от чего смещаться то. Не будем особо оригинальными – пусть каждая переменная знает свою секцию, которая естественно знает базовый адрес. Он да плюс смещение относительно секции и даст нам абсолютный адрес в памяти процесса.
- Тип переменной – это свойство неоднозначно. Типов можно навыдумывать бесконечность. Я предлагаю постараться унифицировать типы. Чуть ниже я опишу, что имеется в виду и почему я так решил.
Четыре позиции. Вполне немного. Теперь давайте уточним правила игры с именем переменной и типом. Начнем с имени. Скажите мне: почему многие особенно старой школы компиляторы так жутко ограничивают имя переменной? Например, в ДОС-овских компиляторах Паскаля и Си переменная не имела право содержать символы отличные от латиницы. Ладно, тут допустим понятно, что американцы всегда думают только о себе. И, кроме того, латиница считается, чуть ли не самым распространенным на земле алфавитом. Простим им это, уж привыкли. Зачем нужно было ограничивать имена переменных в длине? В классическом паскале, если не память мне не изменяет нельзя ввести более 80 символов. Больше не воспримет компилятор. Почему? Откуда такое ограничение. Распространено мнение (вернее раньше такая байка была), что это максимум что может вместить в себя стандартная строка консоли. Ну, в смысле стандартное разрешение экрана в ДОС в текстовом режиме – 80х25. Может быть, и было раньше это целесообразно, учитывая, что человеку все равно неудобно давать длинные имена – писать много лень, а лень программистов вообще легендарная штука, иначе бы они ничего не автоматизировали, полагаясь на свое трудолюбие. Еще один прикол – первый символ в имени обязательно должен быть латинским символом-буквой или символом подчерка. Видимо это делалось для того, чтобы анализатор быстрее работал за счет того, что можно определить по началу слова что оно собой представляет – число или некую директиву. Для старых, ужатых рамками ограниченности самой операционки и слабенького по современным меркам железа, программ – это справедливое правило. Современные компиляторы первые два атавизма уже отбросили, слава Ктулху, а вот последний еще действует, не смотря на то, что совсем не обязательно его соблюдать. Если хотя бы один из символов в имени не числовой – это уже не может быть числом, но… почему бы не быть именем? Итак. Я предлагаю полностью снять ограничения с имен. Разрешим использовать любую раскладку, любой длины (Сколько в String влезет. Как вы думаете 2Gb для имени хватит? Думаю, да) и разрешить использовать в имени любые, абсолютно любые символы. Если у вас Delphi, понимающий юникод, значит, вам повезло, и имена переменных действительно можно писать на любом из земных языков. Единственное условие – имя переменной не должно совпадать с именем оператора, зарезервированного слова или функции. Например, имена могут быть “MemName”, “12-thisMemName” или даже “Маша+Петя=Гиброхоботабр”. Любые символы.
Теперь что касается типа переменной. Многие компиляторы предпочитают идти по накатанной дорожке, имея в арсенале внушительный список типов. Вот сколько целых типов (см. рисунок 1) в Делфи?
Рис. 1. Типы в Делфи
Аж 7 типов. Фундаментальных имеется ввиду. А в Си (см. рисунок 2)?

Рис. 2. Целые в Си
Еще больше, хотя размеры те же. А как они обрабатываются? Процессор-то у нас, скорее всего 32-х разрядный. Все эти числа четко укладываются в один регистр – 4 байта. Кроме того, элемент стека тоже имеет размер 4 байта. Процессору по большему счету все равно один байт обрабатывать или четыре. Единственное, что можно сказать в оправдание, регистры процессора исторически разделены на группы. Например, для обработки байта существуют команды, работающие с младшей частью регистра AL, AH (если брать на примере регистра аккумулятора). Они работают только с 8-ю битами. Раньше когда процессоры были слабенькими это, безусловно, оправдывалось, и однозначно было удобно в одном регистре обрабатывать два операнда, потому и придумали столько вариаций одной команды обработки данных с аккумулятором и прочими несколькими регистрами. Вот смотрите в хелпе по Ассемблеру (см. рисунок 3):
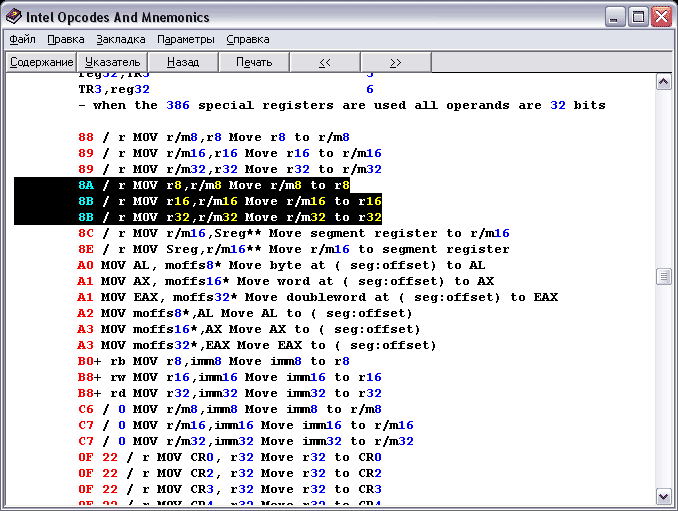
Рис. 3. Вариации работы с процессором
Одна команда на человеческом языке может быть интерпретирована компилятором в разные формы с разными опкодами, в зависимости от данных которыми она должна оперировать. Компилятор определяет, что в процессор помещается, скажем, число 20. Оно занимает максимум 1 байт, значит сгенерировать опкод 8А. А если число будет, скажем 500? Тогда компилятор, понимая что оно в один байт не влезет, сгенерирует опкод 8В, для того чтоб процессору сказать что это число должно «прихавать» 16 или 32 бита. Процессор, скорее всего, отлистает для него все свои 32 бита красоты. Интересно, что разработчики процессоров разделили его на три группы – Все 32 бита, верхнее слово/нижнее слово, Верх нижнего слова/низ нижнего слова. Видимо поэтому команда для обработки 16 бит и 32 имеет один и тот же опкод. Впрочем, это мои наблюдения. Может быть смысл такого «полиморфизма». Да-да, а вы всерьез думали, что полиморфизм пришел к нам с ООП? Совсем в другом. Соответственно и с вещественными типами – там тоже разработчики компиляторов предпочли их разделить.
На фоне всего этого я предлагаю упростить нам задачу. Вместо того, чтобы плодить кучу типов (зарезервированные слова которых еще придется обрабатывать усложняя код и свою жизнь) лучше иметь тип, который позволит вместить в себе все возможные данные. Слышали, что такое вариантные типы? Case тип в паскале, он же Variant в Делфи, или Union в Си? Если нет, то поясню – это инструкция, говорящая компилятору «Hey, body, зарезервируй-ка мне памяти так, чтобы ее хватило для всех значений, которые я туда буду пихать, и все равно что, может быть, останется неиспользуемое место, если данных будет меньше». На что компилятор ответит – «Ок, дружище, чего там у тебя по размерам самое большое? Float? Так. Это 64 бита? Даю тебе поле памяти в 8 байт – сей туда, что хочешь из своего списка все поместится». Это и есть вариантные записи – переменная размером с максимально возможной длиной значения разных типов, которая может использоваться как хранилище для значений с длиной поменьше. Вот и мы поразмышляем – из всех типов, самый максимальный какой? Что мы будем считать? Целые – максимум 32 бита (ну или 64, но пока на него губу раскатывать не будем). Вещественные – максимум 80-битное значение. 10 байт. TBYTE если говорить по ассемблерному. Указатели? 4 байта. Строки? Это уже из другой оперы – это массивы. Впрочем, сейчас строки принято хранить в свободной памяти как массивы символов, на начало которых пишется указатель, опять 4 байта всплыло. Итак, максимум у нас 10 байт. Вот пусть наши переменные заранее резервируют эти 10 байт, таким образом, чтобы одна переменная сама «хавала» значения любого из возможных типов*.
* Комментарий автора.
Кстати можно провести легкую аналогию с C#, там есть тип var. Переменная неопределенного или я бы даже сказал любого типа. Его используют, когда программист заранее не знает, какой тип нужен, и полагается на компилятор, которому ставится задача самостоятельно подобрать тип для переменной. Рекомендуют очень при работе с LINQ. Уверен, что найдутся «язычники», готовые натереть на язык фразу типа «10 байт это расточительство, ламерство и кощунство». Это веселые люди, скажу я вам, они без геморроя не могут жить. Вместо того чтобы писать маленькие программы такие люди пишут Windows, в котором несмотря на все ужимки памяти почему-то этой самой памяти вдруг резко не хватает. Опять-таки все нужно использовать с умом. Если эти 10 байт использовать с умом, то много программа занимать в памяти не будет. С другой стороны можно не парится по поводу приведения типов – он один на все случаи. Программисту, уже по идее, должно быть, удобно работать с такой переменной. Встает только дилемма о том стоит ли в памяти отделать ячейку, где будет указан тип переменной для якобы определения типа во время выполнения. Пока не стоит. В любом случае у нас в руках флаг экспериментов, почему бы не попробовать пойти именно этой тропой.
Кстати можно провести легкую аналогию с C#, там есть тип var. Переменная неопределенного или я бы даже сказал любого типа. Его используют, когда программист заранее не знает, какой тип нужен, и полагается на компилятор, которому ставится задача самостоятельно подобрать тип для переменной. Рекомендуют очень при работе с LINQ. Уверен, что найдутся «язычники», готовые натереть на язык фразу типа «10 байт это расточительство, ламерство и кощунство». Это веселые люди, скажу я вам, они без геморроя не могут жить. Вместо того чтобы писать маленькие программы такие люди пишут Windows, в котором несмотря на все ужимки памяти почему-то этой самой памяти вдруг резко не хватает. Опять-таки все нужно использовать с умом. Если эти 10 байт использовать с умом, то много программа занимать в памяти не будет. С другой стороны можно не парится по поводу приведения типов – он один на все случаи. Программисту, уже по идее, должно быть, удобно работать с такой переменной. Встает только дилемма о том стоит ли в памяти отделать ячейку, где будет указан тип переменной для якобы определения типа во время выполнения. Пока не стоит. В любом случае у нас в руках флаг экспериментов, почему бы не попробовать пойти именно этой тропой.
Итак, ничего не забыли в теории? Вроде нет. Если что, дофантазируем. Пора оформить мысли в виде кода. Опишем класс, который будет заведовать переменными:
TAlisaMem=class
public
MemName:string; // Имя переменной
Data:Variant; // Начальное значение
TypeMem:TypeOper; // Тип переменной
Section:TObject; // Секция, которой она принадлежит
Offset:DWord; // Смещение
Function Addr:String; // Вычисление полного адреса как строки
Function PointerToMe:DWORD; // Полный адрес как число
end;[/code]
Здесь стоит пояснить функции. Давайте сразу с их кодом. Посмотрим, что они должны делать:
public
MemName:string; // Имя переменной
Data:Variant; // Начальное значение
TypeMem:TypeOper; // Тип переменной
Section:TObject; // Секция, которой она принадлежит
Offset:DWord; // Смещение
Function Addr:String; // Вычисление полного адреса как строки
Function PointerToMe:DWORD; // Полный адрес как число
end;[/code]
Здесь стоит пояснить функции. Давайте сразу с их кодом. Посмотрим, что они должны делать:
[code]function TAlisaMem.Addr: String;
begin
Result:=DWordToStr(PointerToMe);
end;
function TAlisaMem.PointerToMe: DWORD;
begin
Result:=(
Offset+
TAlisaSection(Section).VirtualAddress+
TAlisaCompiler(TAlisaSection(Section).ParentCompiler).PE.ImageBase
);
end;
PointerToMe – функция, вычисляющая абсолютный адрес переменной. Это сумма базового адреса, адреса начала секции (или точнее смещение секции) и само смещение переменной внутри секции. Например, базовый адрес 400000h, секция сама лежит по смещению 2000h, и в ней третья переменная (помните каждая переменка 10 байт). Итого адрес переменной равен 400000h+2000h+10*3, которая в 16-тиричной системе равна 0Аh = 402014h.
Адрес вычислили, а теперь для пущего удобства переведем его в строку. Помните, у нас компиляция проходит в переменную строкового типа, которая затем и пишется в файл. Именно для этого и нужна функция Addr, которая всего лишь конвертирует число в строку, правильно представляя ее в понятном для загрузчика виде. Функцию DWordToStr я описывал во второй части статьи.
Класс, заведующий, переменными готов. Теперь его нужно связать с секцией. Но прежде предлагаю определить предварительно список типов, переменными которых будем оперировать:
type
TypeOper = (_Unknown,_Int,_Double,_String,_Operator,_Member);[/code]
TypeOper = (_Unknown,_Int,_Double,_String,_Operator,_Member);[/code]
Стоит ли пояснять – что это за типы? ,_Int,_Double,_String – это предпочитаемые типы переменных, которые в ближайшее время мы хотим использовать. _Unknown – это слово указывает, что в ходе операции тип ее результата не определен. Бывает и такое. Operator,_Member скажет компилятору, что очередной операнд вложенное выражение и переменная. Пока этого хватит.
Чтобы воспользоваться этим, допишем в классе секций парочку усовершенствований:
TAlisaSection=class // Класс, описывающий секции
Private
Mems:TObjectList;
…
public
…
Function Operator(SourceCode:String):String;
function Mem(AName:string):TAlisaMem;
function NewMem(ANameMem:string;AData:Variant):TAlisaMem;
end;
Private
Mems:TObjectList;
…
public
…
Function Operator(SourceCode:String):String;
function Mem(AName:string):TAlisaMem;
function NewMem(ANameMem:string;AData:Variant):TAlisaMem;
end;
Что это за методы? Mems – это список всех переменных. Переменные будут создаваться по ходу их появления в коде. В этом я вижу удобство. В Паскале просто таки необходимо строго описать все переменные в секции VAR. К этому нужно привыкать. В Си больше вольности, там можно описать переменную где угодно. Естественно ее область видимости начинается как минимум с места описания. Возьмем это на вооружение без учета области видимости.
Следующая важная функция NewMem. Она призвана вносить в список переменных** новую переменную, если парсер вдруг обнаружит операнд, не подходящий под описания числа:
function TAlisaSection.NewMem;
begin
// Создаем объект переменную
Result:=TAlisaMem.Create;
// вносим ее в список
Mems.Add(Result);
// Присваиваем ей имя
Result.MemName:=AnsiLowerCase(ANameMem);
// Запоминаем начальные данные (если они есть)
Result.Data:=AData;
// Привязываем к секции, в которой она будет помещаться
Result.Section:=self;
// вычисляем ее смещение
Result.Offset:=length(_Data);
// И помещаем в нее инициализационные данные
// Если это Вещественное
if VarIsFloat(AData) then _Data:=_Data+TWordToStr(AData) else
// Если это целое
if VarIsOrdinal(AData) then _Data:=_Data+DWordToStr(AData)+#0#0#0#0#0#0 else
// Или это строка
if VarIsStr(AData) then begin
_Data:=_Data+AData;
// Выравнивая ее до 10 байт
while (length(_Data) mod 10)<>0 do _Data:=_Data+#0;
end;
end;
begin
// Создаем объект переменную
Result:=TAlisaMem.Create;
// вносим ее в список
Mems.Add(Result);
// Присваиваем ей имя
Result.MemName:=AnsiLowerCase(ANameMem);
// Запоминаем начальные данные (если они есть)
Result.Data:=AData;
// Привязываем к секции, в которой она будет помещаться
Result.Section:=self;
// вычисляем ее смещение
Result.Offset:=length(_Data);
// И помещаем в нее инициализационные данные
// Если это Вещественное
if VarIsFloat(AData) then _Data:=_Data+TWordToStr(AData) else
// Если это целое
if VarIsOrdinal(AData) then _Data:=_Data+DWordToStr(AData)+#0#0#0#0#0#0 else
// Или это строка
if VarIsStr(AData) then begin
_Data:=_Data+AData;
// Выравнивая ее до 10 байт
while (length(_Data) mod 10)<>0 do _Data:=_Data+#0;
end;
end;
Тут всплывает еще одна важная функция. TwordToStr – функция формирует число вещественного типа в правильную для компиляции форму. Помните, в файле байты все должны быть перевернуты, потому что загрузчик загружает сначала байты по младшему адресу, потому скажем число нужно перевернуть верх тормашками, чтоб младший байт шел первым слева. Она тоже простенькая:
// Функция для перевода Extended 80-bit
function TWordToStr(d:Extended):string;
type qw=array[1..10] of byte;
var i:integer;
begin Result:=»;
for i:=1 to 10 do
Result:=Result+char(qw(d)[i]);
end;
function TWordToStr(d:Extended):string;
type qw=array[1..10] of byte;
var i:integer;
begin Result:=»;
for i:=1 to 10 do
Result:=Result+char(qw(d)[i]);
end;
Банально – превращаем вещественное число в массив байт, и записываем*** его в обратном порядке, такое себе зеркальное отражение числа. Скажем, было число 123456h – получится 563412h, загрузчик загрузит сначала 56 потом 34 и так далее.
Вполне логично, что нам понадобится функция поиска переменной по ее имени. Это и будет делать метод Mem. Вот как выглядит его реализация:
function TAlisaSection.Mem(AName: string): TAlisaMem;
var i:integer;
begin
Result:=nil;
// Преобразуем искомое имя в нижний регистр
AName:=AnsiLowerCase(AName);
// И в цикле пока не найдено такое имя проходим
// по списку переменных
// Если такой переменной нет функция вернет nil
for i:=0 to Mems.Count-1 do
if TAlisaMem(Mems[i]).MemName=AName then begin
Result:=TAlisaMem(Mems[i]);
break;
end;
end;
var i:integer;
begin
Result:=nil;
// Преобразуем искомое имя в нижний регистр
AName:=AnsiLowerCase(AName);
// И в цикле пока не найдено такое имя проходим
// по списку переменных
// Если такой переменной нет функция вернет nil
for i:=0 to Mems.Count-1 do
if TAlisaMem(Mems[i]).MemName=AName then begin
Result:=TAlisaMem(Mems[i]);
break;
end;
end;
Банальный поиск в цикле, если объект с переменной такого имени найден, то он возвращается, иначе возвращается nil, т.е. такой переменной нет (и возможно ее нужно будет создавать, в чем наш компилятор сам разберется).
Теперь слегка отступим от дела. Секция может хранить в себе не только переменные. Помните секцию кода? Она ведь хранит не переменные, а исполняемый код. Данные, которые процессор считает командами. И в принципе таких секций может быть несколько. Не смотря на то, что нам хватит для кода одной секции, код это данные, и принадлежат они все-таки секции, именно поэтому я предусмотрел в качестве метода секции обработчик операций – желудок компилятора, которому мы будет скармливать исходный код-сырец – метод Operator.
Что же он должен делать? Давайте попробуем разобрать в теории примитивную программу. Каждая программа должна иметь начало и конец. Если нет начала программы, то непонятно с чего ей начинать. В любом компиляторе, интерпретаторе есть так называемая точка входа. Это оператор, с которого процессор начинает свое путешествие в недра программы. Очень показательно это оформлено в Си – там всякое действо разбито на функции, и есть главная функция, с которой начинается старт программы – функция main(). Найдя ее компилятор проглатывает все, что в ней между {…} и начинает свои странные танцы с бубном. Транслируя строчку, за строчкой, переводя оператор за оператором, подтягивает вызываемые в выражениях функции, он, таким образом, формирует операционные коды программы. Можно сказать что main() в Си это главный оператор. Оператор, который первым скармливается компилятору (я не беру сейчас во внимание директивы сопроцессора и прочие сервисные инструкции).
Именно такую стратегию я предлагаю перенять нашему компилятору – все должно быть разбито на функции, среди которых будет одна главная – функция с точкой входа. Пока это не важно, пока у нас будет одна единственная функция, неважно даже как она будет называться, но главное скормить компилятору выражение, написанное по правилам языка. Его текст будет передаваться методу Operator, который должен быть снабжен рекурсивным механизмом для обработки вложенных в него выражений-блоков кода. В этом механизме будет работать парсер, разбивающий строку на элементы. В цикле проходя по ним, компилятор должен определять, что это за элемент, число, переменная, может функция, и вызывать соответствующий обработчик, передав ему этот операнд.
Причем предлагаю реализовать это по следующей схеме:
- примем, что тип операции будет определять первый операнд – это оператор. Все остальные элементы выражения – его операнды;
перед циклом выясняем, о какой операции идет речь – получаем первый элемент – оператор; - согласно ему создаем объект класса, который будет отвечать за компиляцию операции. Каждой операции свой класс. Если это операция сложения – создается объект класса, где методы будут компилировать опкоды сложения, если это операция присваивания – соответствующий класс. Таким образом, удастся избегать каши в ядре компилятора, отделив каждому оператору свою конуру, и пусть там гавкает на прохожих, не путаясь под ногами ядра-хозяина;
- далее инициируем цикл. В нем проходим по операндам, выясняем их сущность (число это или строка), и в зависимости от этого вызываем нужный метод класса-обработчика, передав ему соответствующий операнд. Тут как раз весьма пригодится ООПшные механизмы – материнский класс-шаблон, где заранее должны быть определены абстрактные методы, присущие всем классам-обработчикам;
- если в качестве очередного операнда попадается выражение (вложенный оператор) то метод инициирует рекурсивную обработку этого оператора, предварительно стараясь сохранить регистры, в которых происходит основное вычисление.
Итак. Давайте внимательнее посмотрим на сам код этого метода:
function TAlisaSection.Operator(SourceCode: String): String;
var sc:TAlisaScaner;i:integer; krn:TAlisaKernel;
begin
// Инициируем парсер
sc:=TAlisaScaner.Create;
// Передав ему исходный код оператора (программы)
sc.Text:=SourceCode;
// Не забываем инициализировать выходную переменную.
// мало ли какой там мусор в ней, ибо она располагается в стеке
Result:=»;
// Создаем объект ядра
krn:=TAlisaKernel.Create(self);
// Указав ему секцию с данными
krn.ParentSection:=TAlisa(TAlisaCompiler(ParentCompiler).ParentAlisa).MemberSection;
// И в цикле пропускаем через механизм ядра каждый операнд операции
// получая на выходе скомпилированную строку с операционными кодами
for i:=0 to sc.High do begin
Result:=Result+krn.Operator(sc[i]).Res;
end;
// Незабыв после убрать за собой мусор
krn.Free; krn:=nil;
sc.Free; sc:=nil;
end;
var sc:TAlisaScaner;i:integer; krn:TAlisaKernel;
begin
// Инициируем парсер
sc:=TAlisaScaner.Create;
// Передав ему исходный код оператора (программы)
sc.Text:=SourceCode;
// Не забываем инициализировать выходную переменную.
// мало ли какой там мусор в ней, ибо она располагается в стеке
Result:=»;
// Создаем объект ядра
krn:=TAlisaKernel.Create(self);
// Указав ему секцию с данными
krn.ParentSection:=TAlisa(TAlisaCompiler(ParentCompiler).ParentAlisa).MemberSection;
// И в цикле пропускаем через механизм ядра каждый операнд операции
// получая на выходе скомпилированную строку с операционными кодами
for i:=0 to sc.High do begin
Result:=Result+krn.Operator(sc[i]).Res;
end;
// Незабыв после убрать за собой мусор
krn.Free; krn:=nil;
sc.Free; sc:=nil;
end;
Здесь код не столь сложный, но появилось много новых введений. Для начала обратим внимание на класс TAlisaKernel. Я повторюсь, что решил, как можно подробнее сгруппировать действия по компиляции. Классов получилось много, но зато действия по определенной операции локализованы и не мешают друг другу. Так и здесь. Для каждого оператора должно создаваться свое ядро-обработчик, естественно вложенные операторы будут так же пропускаться через этот обработчик. Здесь же ядру передается секция данных, где будут располагаться переменные (MemberSection). Мы вернемся к описанию ядра чуть позже, ибо от него тянется цепочка, которую стоит рассмотреть подробнее, а пока необходимо пояснить еще один момент.
* Комментарий автора.
В предыдущих статьях я описал главный класс компиляции TAlisaCompiler, который по идее должен генерировать выходную строку, записываемую в файл. Но сам по себе он некрасиво смотрится. Голо. Как автомобиль без кузова. Поэтому я решил, что красивее будет и его обернуть в оболочку.
В предыдущих статьях я описал главный класс компиляции TAlisaCompiler, который по идее должен генерировать выходную строку, записываемую в файл. Но сам по себе он некрасиво смотрится. Голо. Как автомобиль без кузова. Поэтому я решил, что красивее будет и его обернуть в оболочку.
Вот давайте сейчас и поговорим об этом удобстве:
TAlisa=class(TComponent)
private
// Обьект компилятора — мотор
Compiler:TAlisaCompiler;
// Секция данных. Определим ее пока что одну
MemberSection:TAlisaSection;
// Исходник, скармливаемый мотору
FSource: String;
procedure SetSource(const Value: String);
public
Property Source:String read FSource write SetSource;
Constructor Create(AOwner:TComponent); override;
Destructor Free;
// Метод, построения ( сюда же можно прикрутить запуск)
Procedure Run(AFileName:String);
end;
private
// Обьект компилятора — мотор
Compiler:TAlisaCompiler;
// Секция данных. Определим ее пока что одну
MemberSection:TAlisaSection;
// Исходник, скармливаемый мотору
FSource: String;
procedure SetSource(const Value: String);
public
Property Source:String read FSource write SetSource;
Constructor Create(AOwner:TComponent); override;
Destructor Free;
// Метод, построения ( сюда же можно прикрутить запуск)
Procedure Run(AFileName:String);
end;
Это обертка для пользователя. Согласитесь, когда вы пишете и компилируете программы, вам совсем не хочется знать какими методами будет сформирован выходной файл. Вас интересует его имя и путь, куда он ляжет плюс конечно исходный код. Именно этими вопросами и будет заниматься эта обертка, управляя компилятором. Программист скармливает объекту этого класса исходный код в свойство Source, и вызывает метод Run, который уже сам напрягает компилятор (предварительно его создав, конечно же) на генерацию опкода, и он же формирует выходной файл:
procedure TAlisa.Run(AFileName: String);
var f:file of byte;cdata:String;
begin
// Готовим файл
AssignFile(f,AFileName);rewrite(f);
//Просто таки требуем от компилятора танцев
//над исходником
cdata:=Compiler.Compile;
//Все его телодвижения записываем открытой строкой
// в файл.
BlockWrite(f,cdata[1],length(cdata));
// Не забыв его закрыть.
CloseFile(f);
end;
var f:file of byte;cdata:String;
begin
// Готовим файл
AssignFile(f,AFileName);rewrite(f);
//Просто таки требуем от компилятора танцев
//над исходником
cdata:=Compiler.Compile;
//Все его телодвижения записываем открытой строкой
// в файл.
BlockWrite(f,cdata[1],length(cdata));
// Не забыв его закрыть.
CloseFile(f);
end;
Естесственно компилятор нужно создать и после работы освободить:
constructor TAlisa.Create(AOwner: TComponent);
begin
inherited;
Compiler:=TAlisaCompiler.Create;
Compiler.ParentAlisa:=self;
MemberSection:=Compiler.NewSection(‘Данные’,dataSec);
end;
destructor TAlisa.Free;
begin
Compiler.Free; Compiler:=nil;
end;
begin
inherited;
Compiler:=TAlisaCompiler.Create;
Compiler.ParentAlisa:=self;
MemberSection:=Compiler.NewSection(‘Данные’,dataSec);
end;
destructor TAlisa.Free;
begin
Compiler.Free; Compiler:=nil;
end;
Тут практически нечего комментировать за исключением создания секции данных, чем занимается метод компилятора NewSection. Помните, я писал, что имя секции может быть любое? Напишем его на русском, что тут такого? Лишь бы вместилось в 8 символов. Естественно не забудем скормить компилятору операцию на точке входа – главную функцию, чем и займется обработчик свойства Source:
procedure TAlisa.SetSource(const Value: String);
var Mainsource:String; b,f,t:integer;
begin
FSource := Value;
// Находим начало главной функции
f:=pos(‘(main’,FSource);
b:=1;t:=f;
while (b>0)and(t<=length(FSource)) do begin
if FSource[t]=‘(‘ then inc(b);
if FSource[t]=‘)’ then dec(b);
inc(t);
end;
// Найдя ее последний брекет, передадим ее тело компилятору
Mainsource:=copy(FSource,f,t-f+1);
Compiler._Code._Data:=Compiler._Code._Data+Compiler._Code.Operator(Mainsource)+#$C3;
// C3 — это опкод ret. Наша программа должна завершиться корректно.
// Можно будет потом при желании, когда научимся импортировать
// функции использовать ExitProcess
end;
var Mainsource:String; b,f,t:integer;
begin
FSource := Value;
// Находим начало главной функции
f:=pos(‘(main’,FSource);
b:=1;t:=f;
while (b>0)and(t<=length(FSource)) do begin
if FSource[t]=‘(‘ then inc(b);
if FSource[t]=‘)’ then dec(b);
inc(t);
end;
// Найдя ее последний брекет, передадим ее тело компилятору
Mainsource:=copy(FSource,f,t-f+1);
Compiler._Code._Data:=Compiler._Code._Data+Compiler._Code.Operator(Mainsource)+#$C3;
// C3 — это опкод ret. Наша программа должна завершиться корректно.
// Можно будет потом при желании, когда научимся импортировать
// функции использовать ExitProcess
end;
В принципе можно было натравить на программу парсер, но вдруг нам захочется еще какие то механизмы директив прикрутить… Пока проще оформить вычленение кода главной функции простейшими операторами. На будущее стоит помнить про один недостаток такого – в строках могут присутствовать круглые скобки. Парсер наш уже умеет строки отличать, а вот этот код еще нет. Но, мы пока что не умеем работать со строками, поэтому оставим это на последующие апдейты компилятора. В любом случае его нужно будет дополнять новыми методами, классами и прочей, гарантирующей удобство, мишурой.
Посмотрим на главную программу. Она будет выглядеть просто и незатейливо – на главной форме будет Мемо поле, куда будет грузиться или писаться исходный код. А в обработчике, допустим нажатия горячей клавиши <F9>, будет такое:
var a:TAlisa;
begin
Memo1.Lines.SaveToFile(ExtractFilePath(ParamStr(0))+‘file.source’);
a:=TAlisa.Create(nil);
a.Source:=Memo1.Lines.Text;
a.Run(ExtractFilePath(ParamStr(0))+‘File.exe’);
a.Free;
Close;
end;
begin
Memo1.Lines.SaveToFile(ExtractFilePath(ParamStr(0))+‘file.source’);
a:=TAlisa.Create(nil);
a.Source:=Memo1.Lines.Text;
a.Run(ExtractFilePath(ParamStr(0))+‘File.exe’);
a.Free;
Close;
end;
Ничего особенного. Создается компонент Alisa, которому скармливается исходник кода, и выполняется метод компиляции, создающий исполнимый файл. Ну, что… Вроде платье само сшито. Давайте заглянем непосредственно по него.
Enter the machine…
Мы остановились на классе TAlisaKernel. Напомню – это ядро, передающее задания на компиляцию объектам, отвечающим за свои операторы. Посмотрим, как оно выглядит в описании:
TAlisaOperRes=record
Res:String; //Скомпилированная операция
TypeofOperator:TypeOper; // Тип операции
end;
TAlisaKernel=class
private
// Секция, на которую ядро будет ссылаться
// В данном случае ссылаться оно должно на секцию данных
// с которыми будет оперировать
ParentSection:TAlisaSection;
// Эти поля понадобятся для того чтоб передавать объекту-обработчику
// очередной операнд, приведенный к соответствующему для него типу
FoundedMem:TAlisaMem;
FoundedInt:Integer;
FoundedDouble:Extended;
FoundedString:String;
// Этот метод призван инициализировать компиляцию,
// заставив объект-обработчик оператора выполнить трансляцию
// в машинные коды
Function CompileOper(Scaner:TAlisaScaner):TAlisaOperRes;
// Но перед этим необходимо этот объект подготовить
// корректно создать — чем и займется следующий метод
Function PrepareOperation(Oper:string):TAlisaReserved;
// Для удобства я предлагаю выделить определение типа
// операнда в отдельную функцию
Function WhatIs(Obj:String):TypeOper;
public
// Главный метод, которому будет передаваться исходный код
Function Operator(ASource:String):TAlisaOperRes;
Constructor Create(ASection:TAlisaSection);
Destructor Free;
end;
Res:String; //Скомпилированная операция
TypeofOperator:TypeOper; // Тип операции
end;
TAlisaKernel=class
private
// Секция, на которую ядро будет ссылаться
// В данном случае ссылаться оно должно на секцию данных
// с которыми будет оперировать
ParentSection:TAlisaSection;
// Эти поля понадобятся для того чтоб передавать объекту-обработчику
// очередной операнд, приведенный к соответствующему для него типу
FoundedMem:TAlisaMem;
FoundedInt:Integer;
FoundedDouble:Extended;
FoundedString:String;
// Этот метод призван инициализировать компиляцию,
// заставив объект-обработчик оператора выполнить трансляцию
// в машинные коды
Function CompileOper(Scaner:TAlisaScaner):TAlisaOperRes;
// Но перед этим необходимо этот объект подготовить
// корректно создать — чем и займется следующий метод
Function PrepareOperation(Oper:string):TAlisaReserved;
// Для удобства я предлагаю выделить определение типа
// операнда в отдельную функцию
Function WhatIs(Obj:String):TypeOper;
public
// Главный метод, которому будет передаваться исходный код
Function Operator(ASource:String):TAlisaOperRes;
Constructor Create(ASection:TAlisaSection);
Destructor Free;
end;
На что здесь стоит обратить внимание? Founded – поля, которые будут принимать очередной операнд, который будет приведен в определенный тип, согласно своему виду. Если это целое – то проинициализируется FoundedInt, операнд будет приведен к целому типу. Если это имя переменной, FoundedMem получит объект из списка переменных, и передастся классу-обработчику, а тот уж пусть сам разбирается что с ним делать (помните, «котлеты стоит держать подальше от мух, а то котлеты всех мух съедят», они такие) и так далее. По мере надобности можно будет подкидывать поля новых типов, функций, массивов, объектов и прочее.
Схема тут проста:
- методу Operator передается исходный код;
- он инициализирует его локальный парсинг, и вызывает код компиляции CompileOper;
- тот в свою очередь путем вызова PrepareOperation подготавливает класс-обработчик, а после в цикле, проходя по распарсеным операндам, скармливает их классу-обработчику.
Поскольку все эти классы унаследованы от одного класса-шаблона, и имеют общий набор методов – ядру по все равно, что там объект-обработчик будет делать в них, он просто их вызовет, передав им операнд, любезно препарированный методом WhatIs. Этот метод определит, какого типа операнд, и приведет его к божескому виду, согласно ему в цикле и будет вызываться тот или иной метод в зависимости от типа операнда. Смотрите:
function TAlisaKernel.Operator;
var i:integer; Scaner:TAlisaScaner;
begin
// Проинициализируем выходные от функции, чтоб невзначай мусора не было
Result.Res:=»;Result.TypeofOperator:=_Unknown;
// Если исходного кода нет, то и делать нам нечего
if ASource=» then exit;
// Создадим парсер для выражения
Scaner:=TAlisaScaner.Create;
// Передав в него исходник
Scaner.Text:=ASource;
// Запустим цикл компиляции
Result:=CompileOper(Scaner);
// После чего освободим парсер.
Scaner.Free;
end;
var i:integer; Scaner:TAlisaScaner;
begin
// Проинициализируем выходные от функции, чтоб невзначай мусора не было
Result.Res:=»;Result.TypeofOperator:=_Unknown;
// Если исходного кода нет, то и делать нам нечего
if ASource=» then exit;
// Создадим парсер для выражения
Scaner:=TAlisaScaner.Create;
// Передав в него исходник
Scaner.Text:=ASource;
// Запустим цикл компиляции
Result:=CompileOper(Scaner);
// После чего освободим парсер.
Scaner.Free;
end;
Комментарии, надеюсь, понятные. Перед тем как распарсить исходник и передать его циклам ядра укажем тип операции _Unknown. Это будет говорит о том, что пока нам тип результата этого выражения еще не известен. Теперь «потопаем» в циклы:
function TAlisaKernel.CompileOper;
var i:integer;
ThisOperator:TAlisaReserved;
op:TAlisaOperRes;
begin
// Приготовим выходную переменную очистив от мусора
op.Res:=»;
// На основании первого элемента выражения, который определяет операцию,
// является собственно оператором, создадим и приготовим объект,
// отвечающий за компиляцию конкретного оператора с его операндами
ThisOperator:=TAlisaReserved(PrepareOperation(Scaner[0]));
// Если оператор не распознан то ничего не делать, завершив функцию
// Ничего не будет скомпилированно
if ThisOperator=nil then exit;
ThisOperator.ItFirstDoubleOperand:=true;
// Передаем в объект-обработчик парсер. Он там может пригодится.
ThisOperator.Scaner:=Scaner;
{ TODO : Ядро транслятора }
// эта строчка для операторов, в которых нужно делать подмену.
// Например для += m 2 нужно будет подменять := m (+ m 2)
if ThisOperator is TAlisaSelfOper then begin
// Это для += -= и прочих самоприсваиваемых-операций
op.Res:=ThisOperator.OnDouble(0);
end else begin
// Циклом по распарсеным операндам
for i:=1 to Scaner.High do begin
// Передавая объекту номер операнда, с которым ему нужно работать
// Это пригодится для инициализации регистра первым операндом
ThisOperator.OperandNumber:=i;
// Проверяем тип операнда, и если возможно приводим его, помещая
// значение в Found-поля
// В зависимости от типа операнда вызывается метод объекта-обработчика
// отвечающего за свой тип
case WhatIs(Scaner[i]) of
_Int:op.Res:=op.Res+ThisOperator.OnInt(FoundedInt);
_Double:op.Res:=op.Res+ThisOperator.OnDouble(FoundedDouble);
_Operator:op.Res:=op.Res+ThisOperator.OnOperator(FoundedString);
_Member:op.Res:=op.Res+ThisOperator.OnMember(FoundedMem);
end;
end;
end;
// После чего результирующий тип возвращаем. Иногда родительскому выражению
// полезно знать что вернуло его дите, чтоб корректно привести к единому типу
op.TypeofOperator:=ThisOperator.TypeOfLastOperand;
// Не забываем освобождать объект-обработчик.
ThisOperator.Free; ThisOperator:=nil;
// и возвращать скомпилированный результат-строку
Result:=op;
end;
var i:integer;
ThisOperator:TAlisaReserved;
op:TAlisaOperRes;
begin
// Приготовим выходную переменную очистив от мусора
op.Res:=»;
// На основании первого элемента выражения, который определяет операцию,
// является собственно оператором, создадим и приготовим объект,
// отвечающий за компиляцию конкретного оператора с его операндами
ThisOperator:=TAlisaReserved(PrepareOperation(Scaner[0]));
// Если оператор не распознан то ничего не делать, завершив функцию
// Ничего не будет скомпилированно
if ThisOperator=nil then exit;
ThisOperator.ItFirstDoubleOperand:=true;
// Передаем в объект-обработчик парсер. Он там может пригодится.
ThisOperator.Scaner:=Scaner;
{ TODO : Ядро транслятора }
// эта строчка для операторов, в которых нужно делать подмену.
// Например для += m 2 нужно будет подменять := m (+ m 2)
if ThisOperator is TAlisaSelfOper then begin
// Это для += -= и прочих самоприсваиваемых-операций
op.Res:=ThisOperator.OnDouble(0);
end else begin
// Циклом по распарсеным операндам
for i:=1 to Scaner.High do begin
// Передавая объекту номер операнда, с которым ему нужно работать
// Это пригодится для инициализации регистра первым операндом
ThisOperator.OperandNumber:=i;
// Проверяем тип операнда, и если возможно приводим его, помещая
// значение в Found-поля
// В зависимости от типа операнда вызывается метод объекта-обработчика
// отвечающего за свой тип
case WhatIs(Scaner[i]) of
_Int:op.Res:=op.Res+ThisOperator.OnInt(FoundedInt);
_Double:op.Res:=op.Res+ThisOperator.OnDouble(FoundedDouble);
_Operator:op.Res:=op.Res+ThisOperator.OnOperator(FoundedString);
_Member:op.Res:=op.Res+ThisOperator.OnMember(FoundedMem);
end;
end;
end;
// После чего результирующий тип возвращаем. Иногда родительскому выражению
// полезно знать что вернуло его дите, чтоб корректно привести к единому типу
op.TypeofOperator:=ThisOperator.TypeOfLastOperand;
// Не забываем освобождать объект-обработчик.
ThisOperator.Free; ThisOperator:=nil;
// и возвращать скомпилированный результат-строку
Result:=op;
end;
Обратите внимание на класс TAlisaReserved. Это и есть наш шаблон. Абстрактный класс, от которого классы-обработчики операторов унаследуют свои главные методы, которые будут вызваны в цикле ядра. ООП «рулит», как ни крути.
Попозже, при рассмотрении тел обработчиков операторов, мы вернемся к описанию этого класса, а сейчас рассмотрим функцию, определяющую тип операнда:
function TAlisaKernel.WhatIs(Obj: String): TypeOper;
var m:TAlisaMem; i:integer;d:Double;
begin
// Если операнд пустая строка то вернуть тип, дающий ядру понятие что с ним
// не стоит работать, потому как он нераспознан
if Obj=» then begin
Result:=_Unknown;exit;
end;
// Если попытка привести операнд к целому числу окончится удачей,
// поместить его значение в Found-поле, которое подходит к типу переменной
// и выйти
if TryStrToInt(Obj,i) then begin
Result:=_Int;
FoundedInt:=i;
exit;
end;
// Если это не целое число, может быть оно вещественное?
// При этом будем считать, что разделителем в числе должна быть точка
DecimalSeparator:=‘.’;
if TryStrToFloat(Obj,d) then begin
Result:=_Double;
FoundedDouble:=d;
exit;
end;
//Если же операнд не число, и первый его символ брекет — открывающая скобка
//то это вложенное выражение, и нужно его преподнести как оператор для
//рекурсивного вызова
if Obj[1]=‘(‘ then begin
Result:=_Operator;
FoundedString:=Obj;
exit;
end;
// В противном случае это имя объекта
m:=ParentSection.Mem(obj);
if m=nil then begin
m:=ParentSection.NewMem(Obj,0);
m.TypeMem:=_Unknown;
end;
Result:=_Member;
FoundedMem:=m;
end;
var m:TAlisaMem; i:integer;d:Double;
begin
// Если операнд пустая строка то вернуть тип, дающий ядру понятие что с ним
// не стоит работать, потому как он нераспознан
if Obj=» then begin
Result:=_Unknown;exit;
end;
// Если попытка привести операнд к целому числу окончится удачей,
// поместить его значение в Found-поле, которое подходит к типу переменной
// и выйти
if TryStrToInt(Obj,i) then begin
Result:=_Int;
FoundedInt:=i;
exit;
end;
// Если это не целое число, может быть оно вещественное?
// При этом будем считать, что разделителем в числе должна быть точка
DecimalSeparator:=‘.’;
if TryStrToFloat(Obj,d) then begin
Result:=_Double;
FoundedDouble:=d;
exit;
end;
//Если же операнд не число, и первый его символ брекет — открывающая скобка
//то это вложенное выражение, и нужно его преподнести как оператор для
//рекурсивного вызова
if Obj[1]=‘(‘ then begin
Result:=_Operator;
FoundedString:=Obj;
exit;
end;
// В противном случае это имя объекта
m:=ParentSection.Mem(obj);
if m=nil then begin
m:=ParentSection.NewMem(Obj,0);
m.TypeMem:=_Unknown;
end;
Result:=_Member;
FoundedMem:=m;
end;
По мере добавления новых типов, эта процедура должна будет пополняться новыми механизмами приведения типов. Пока что нам хватит и этого. Функций у нас нет, а значит, определению переменной дается приоритет. Именно поэтому я поместил в этот код создание новой переменной, если операнд не число и не выражение. Возможно, в дальнейшем понадобится убрать из этого метода создание переменной, отдав это действие классу-обработчику, отвечающему за оператор присваивания. Поживем – увидим. А теперь давайте посмотрим в кастрюлю, где готовятся объекты-обработчики оператора:
function TAlisaKernel.PrepareOperation;
begin Result:=nil;
// Не забудем что наш язык регистронезависимый, потому приведем имя оператора к нижнему регистру как бы он ни был написан.
Oper:=AnsiLowerCase(Oper);
// Если оператор содержит имя ":=" то создать определенный класс
if Oper=‘:=’ then Result:=TAlisaSet.Create else
// Иначе попробовать следующую проверку
if (Oper[length(Oper)]=‘=’)and(length(Oper)>1) then begin
Result:=TAlisaSelfOper.Create;
TAlisaSelfOper(Result).Operation:=copy(Oper,1,length(Oper)-1);
end else
// и так далее по остальным операторам, зарезервированным словам
if Oper=‘+’ then Result:=TAlisaPlus.Create else
if Oper=‘++’ then Result:=TAlisaInc.Create else
if Oper=‘—‘ then Result:=TAlisaDec.Create else
if Oper=‘-‘ then Result:=TAlisaMinus.Create else
if Oper=‘*’ then Result:=TAlisaMul.Create else
if (Oper=‘sin’)or(Oper=‘cos’)
then Result:=TAlisaTranc.Create(Oper) else
if pos(Oper,‘/ % div mod делить остаток’)<>0 then begin
Result:=TAlisaDiv.Create;
// Если нужно поделить и вернуть вещественное
if (Oper=‘/’) then TAlisaDiv(Result).TypeDiviation:=1;
// Если нужно поделив взять остаток
if (Oper=‘%’)or(Oper=‘mod’)or(Oper=‘остаток’) then TAlisaDiv(Result).TypeDiviation:=2;
// Если нужно поделить и вернуть только целое
if (Oper=‘div’)or(Oper=‘делить’) then TAlisaDiv(Result).TypeDiviation:=3;
end
;
if Result<>nil then
Result.ParentKernel:=self;
end;
begin Result:=nil;
// Не забудем что наш язык регистронезависимый, потому приведем имя оператора к нижнему регистру как бы он ни был написан.
Oper:=AnsiLowerCase(Oper);
// Если оператор содержит имя ":=" то создать определенный класс
if Oper=‘:=’ then Result:=TAlisaSet.Create else
// Иначе попробовать следующую проверку
if (Oper[length(Oper)]=‘=’)and(length(Oper)>1) then begin
Result:=TAlisaSelfOper.Create;
TAlisaSelfOper(Result).Operation:=copy(Oper,1,length(Oper)-1);
end else
// и так далее по остальным операторам, зарезервированным словам
if Oper=‘+’ then Result:=TAlisaPlus.Create else
if Oper=‘++’ then Result:=TAlisaInc.Create else
if Oper=‘—‘ then Result:=TAlisaDec.Create else
if Oper=‘-‘ then Result:=TAlisaMinus.Create else
if Oper=‘*’ then Result:=TAlisaMul.Create else
if (Oper=‘sin’)or(Oper=‘cos’)
then Result:=TAlisaTranc.Create(Oper) else
if pos(Oper,‘/ % div mod делить остаток’)<>0 then begin
Result:=TAlisaDiv.Create;
// Если нужно поделить и вернуть вещественное
if (Oper=‘/’) then TAlisaDiv(Result).TypeDiviation:=1;
// Если нужно поделив взять остаток
if (Oper=‘%’)or(Oper=‘mod’)or(Oper=‘остаток’) then TAlisaDiv(Result).TypeDiviation:=2;
// Если нужно поделить и вернуть только целое
if (Oper=‘div’)or(Oper=‘делить’) then TAlisaDiv(Result).TypeDiviation:=3;
end
;
if Result<>nil then
Result.ParentKernel:=self;
end;
Здесь, в этом салате, представлена банальная лесенка из условий – если оператор такой-то, создать объект соответствующего класса, иначе проверить на сходимость со следующим зарезервированным словом. По мере пополнения языка зарезервированными словами эта часть компилятора может пополняться новыми сверками. Обратите внимание – я для показухи оператор деления описал разными словами. Почему бы нет? Точно так же можно написать:
if (Oper=‘-‘)or(Oper=’Вычесть’) then Result:=TAlisaMinus.Create
Ничего не мешает нам сделать дубли зарезервированных слов в разном обличии. Единственный момент, по которому не стоит этого делать – сокращается число возможных имен функций. На переменные это вряд ли повлияет, так как имя переменной не должно стоять на месте оператора, а вот если мы будем описывать функции – имя функции вполне может идти в качестве имени оператора – первым в списке парсера. Поэтому не стоит уж очень расширять лики одного оператора, тем более, что знак минуса привычнее слова. Ну, да ладно, это уж выбирать каждому. А мы продолжим путешествие в недра… будущих «залежей глюков».
В представленном выше коде уже можно увидеть классы-обработчики операторов. Это тигли компилятора. В них будет вариться металл операционных кодов, выливаясь в порой причудливые формы – программы на машинном языке.
Lets heavy metall…
Прежде чем начать описывать кишки этих классов, давайте в теории расставим все «И» под точками, чтоб было понятно, кого за что ругать. У нас есть куча классов, которые наследуются от абстрактного класса-шаблона. Эти классы генерируют смесь опкодов, выдавая ассемблерные операции (в виде строки байтов, которые характеризуют ту или иную операцию). Во второй части в конце статьи был дан пример, показывающий наготу машинного кода в байтах. Вспомним: #$A1#$00#$20#$40#$00#$C3. Это вид ассемблерного оператора, помещающего в регистр число из памяти. Именно такую последовательность и должны генерировать классы-обработчики операторов в выходную строку. Я еще раз напомню, что предлагаю (и позже вы это увидите) сгруппировать механизмы по своим признакам:
- каждый класс-оператор помещается в отдельный модуль;
- cтроку опкодов, типа представленной выше, передать под покровительство функций, возвращающих эту строку классам, которые их вызывают. Для этих функций выделить отдельный модуль, подключаемый во всех классах-обработчиках операторов.
Например, функция типа:
function PushEAX;
begin
Result:=#$50;
end;
begin
Result:=#$50;
end;
будет возвращать опкод команды помещения значения регистра ЕАХ в стек.
Думаю, такая схема будет удобна. Опкоды будут собраны в один модуль, обработчики в другой (другие) модули. Никто не будет мешать друг другу, если понадобится быстро найти или добавить новую команду-опкод не придется долго лазить по модулю ядра, выискивая, где же это его нужно добавить.
То есть получается следующая иерархия:
- класс-шаблон, описывающий методы, общие для всех классов-обработчиков операторов, которые наследуя их, будут по-разному обрабатывать;
- классы-обработчики оператора будут вызывать функции, возвращающие строку опкодов, какие им понадобятся в ходе компиляции, в зависимости от того какой из методов вызван – обработки целого или переменной, и от того какой оператор;
- сами же функции, возвращающие опкоды, будут преспокойненько транслировать в строку машинный язык, находясь на своей территории в отдельном модуле.
Вот давайте и пройдемся по этой схеме начиная с самого начала и заканчивая тем чем должно закончится. Сначала опишем класс-шаблон, чтоб иметь представления о том, как будут выглядеть его дети:
TAlisaReserved=class
protected
// Поле, определяющее приведение к типу, наиболее
// подходящему для дальнейшей обработки
TypeOfLastOperand:TypeOper;
// Парсер. Пригодится
Scaner:TAlisaScaner;
Private
// Объекты, вызвавшие объект. Тоже пригодятся
ParentKernel,ParentOperator:TObject;
public
// Поле покажет, встречались ли в выражении уже вещественные.
ItFirstDoubleOperand:Boolean;
// Номер операнда
OperandNumber:Integer;
// Методы. Для каждого типа операнда свои.
Function OnInt(i:integer):String; dynamic;
Function OnDouble(d:Extended):String; dynamic;
Function OnOperator(Oper:string):String; dynamic;
Function OnMember(m:TAlisaMem):String; dynamic;
Function OnString(s:string):String; dynamic;
Function OnArray(a:string):String; dynamic;
Function OnFunc(m:TAlisaMem):String; dynamic;
end;[
protected
// Поле, определяющее приведение к типу, наиболее
// подходящему для дальнейшей обработки
TypeOfLastOperand:TypeOper;
// Парсер. Пригодится
Scaner:TAlisaScaner;
Private
// Объекты, вызвавшие объект. Тоже пригодятся
ParentKernel,ParentOperator:TObject;
public
// Поле покажет, встречались ли в выражении уже вещественные.
ItFirstDoubleOperand:Boolean;
// Номер операнда
OperandNumber:Integer;
// Методы. Для каждого типа операнда свои.
Function OnInt(i:integer):String; dynamic;
Function OnDouble(d:Extended):String; dynamic;
Function OnOperator(Oper:string):String; dynamic;
Function OnMember(m:TAlisaMem):String; dynamic;
Function OnString(s:string):String; dynamic;
Function OnArray(a:string):String; dynamic;
Function OnFunc(m:TAlisaMem):String; dynamic;
end;[
Давайте я поясню, что тут к чему предлагается подробнее. TypeOfLastOperand – призван хранить тип результата выражения. Проблема вот в чем. Процессор на самом деле – «узколобое существо». Он может оперировать только с целыми числами, да и то не со всеми. Если у нас есть выражение типа 2+3*5, его вполне можно обработать центральным процессором. Результат будет естественно целым. Мало того, что он вполне умещается в 32 бита регистра, так и для таких результатов созданы все условия, чтобы они себя комфортно чувствовали (помните – я упоминал, что наши переменные будут вариантного типа). Они вполне без особенных усилий, руководствуясь только стандартными командами «центрального камушка», обнимут результат. В этом случае, тип выражения и результата – целое число. А представим, что у нас выражение 2.56/85.30. Центральный процессор не умеет работать с вещественными числами. Для этого в недрах компьютера содержится «коморка папы FPU», где помещается математический сопроцессор. Во! Смотрите, какой красавец (из Википедии выдернул, см. рисунок 4):

Рис. 4. Сопроцессор
Правда, это 287-й, использовавшийся в старых компьютерах. «Честное пионерское», – я не знаю, как сейчас дела обстоят с современными процессорами. Если наш уважаемый редактор достанет фотки современного сопроцессора, любопытно будет на него посмотреть.
Так вот, работой с вещественными числами заведует именно он. И для него была разработана особая линейка машинных команд. И, стало быть, наше выражение выполнять ему. Выше я уже говорил, что максимальный размер вещественного числа равен 80 битам (10 байт) – это разрядность регистров сопроцессора. Если встретится такое выражение, его уже не приведешь к целому типу (если конечно не дать в программе указание округлить), поскольку результат будет неверным. А ведь может быть и такое выражение – 2*5-3.7. В начале, оно даст целочисленный результат – 2*5=10 (точно 10? Проверьте на калькуляторе). И ресурсов ЦП (это центральный процессор) вполне хватит на эту часть вычисления. А потом «облом». Всплыло вещественное число. Значит, придется результат уже вычисленного выражения передавать сопроцессору, поскольку «главный камушек» уже разводит руками мол «Сори, ребята это мы не проходили это нам не задавали». А стало быть, и тип выражения уже должен изменится, чтоб последующие операнды в любом случае приводились к вещественному – все равно нигде не указано что нужно 3.7 округлить, значит так просто отбрасывать 0.7 нельзя. Именно для этого необходимо иметь свойство класса, указывающее с каким процессором работать (имеются ввиду численные арифметические операции).
Условимся, что приоритет обработки вещественных чисел выше приоритета целых, если конечно явно не будет указана инструкция округления, которую, кстати, еще писать придется. Потом, не сейчас, но придется. То есть, как только встретилось первое вещественное, вся власть переходит в руки сопроцессора. В рамках одного выражения, конечно. Вложенные выражения вполне могут обрабатываться ЦП, если там нет необходимости вычисления вещественных. Однако и такие вложенные выражения должны быть приведены к вещественному типу, если уже стало ясно, что в выражении всплыло вещественное значение.
С приведением типов предварительно разобрались, поедем дальше. OperandNumber – зачем и кому он нужен? Поясню. Возьмем выражение 2+3. От перестановки слагаемых сумма не меняется. Представим, что у нас есть регистр процессора, который изначально нам кто-то «тихий и большой» приготовил, поместив в него ноль. Регистр чистый. Нам можно без тени сомнения прибавить к нулю 2, а потом еще прибавить 3, вот так: 0+2+3. Получится тот же результат. Нам не понадобилось помещать первую 2 в регистр, ибо, как уже сказано, от перестановки… В общем, все в «ажуре». И этим можно было бы воспользоваться, организовать цикл, перед которым командой XOR очищать плацдарм регистра, а потом в цикле одной и той же командой суммирования проталкивать все выражение. Кода, как «кот наплакал», все просто и прозрачно. Но, на этом веселье заканчивается.
Возьмем 2-3. С ним такой фокус не пройдет. Нельзя переписать его безнаказанно в выражение 0-2-3. То есть, нельзя будет в цикле для всех операндов использовать только операцию разности, результат будет неправильный. Сначала придется поместить в регистр первую 2, а уж потом от нее отнять последующие операнды. И именно для этого нам понадобится это свойство. Первый операнд помещаем, а все остальные обрабатываем относительно первого.
Теперь, что касается абстрактных методов. Как было выше сказано, цикл ядра будет вызывать их согласно типу операнда, передавая им значение операнда. Наследуемые классы могут не переопределять все методы, это не обязательно. Например, у меня пока что определены только методы работы с числами, переменными и вложенным выражением. Остальные все потом по мере наворачивания компилятора. Допустим, я пока еще не знаю, как лучше описать работу со строками, видимо понадобится импортировать функции операционки, распределяющие память, тоже самое с массивами. Пусть будут на перспективу.
Единственное на что стоит еще обратить внимание – можно передать шаблону-классу обработку вложенных выражений по умолчанию:
function TAlisaReserved.OnOperator;
var op:TAlisaOperRes;
begin
// компилируем выражение по умолчанию
// Все равно его придется компилировать везде и всюду
op:=TAlisaKernel(ParentKernel).Operator(Oper);
// Возвращаем результат
Result:=op.Res;
// и тип результата
TypeOfLastOperand:=op.TypeofOperator;
end;
var op:TAlisaOperRes;
begin
// компилируем выражение по умолчанию
// Все равно его придется компилировать везде и всюду
op:=TAlisaKernel(ParentKernel).Operator(Oper);
// Возвращаем результат
Result:=op.Res;
// и тип результата
TypeOfLastOperand:=op.TypeofOperator;
end;
А в наследуемых классах, просто вызывать метод родителя – все равно во всех их придеться компилировать вложенные выражения, так зачем этот «механайз» пихать во все классы, когда можно четко выделить ему место «под крылышком предка», расположенного в одном же модуле с компилятором, что дает ему доступ к полям компилятора. Тела остальных методов я описывать не буду, они пустые, вроде этого:
function TAlisaReserved.OnInt;
begin
end;
begin
end;
Проще не бывает, пока что. Все их тела будут разные, полиморфные, если можно так выразиться.
PostScriptum
Все эти классы желательно описать в одном модуле. Во-первых, меньше проблем с подключаемыми модулями, во-вторых, свойства этих классов тесно связаны между собой, а значит, область их видимости должна быть одна и та же. Так что следует их поместить в тот же модуль к остальным классам, которые формируют PE и MZ заголовки, ведают секциями, и запускают машину компиляции.
Продолжение следует…
The Чтиво
- Flat Assembler 1.64. Мануал программиста http://flatassembler.narod.ru/fasm.htm
Статья из одиннадцатого выпуска журнала «ПРОграммист».
Обсудить на форуме — Компилятор домашнего приготовления. Часть 4
Похожие статьи
Купить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
