

Последние записи
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы
- Склеить несколько файлов в один

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
23rd
Фев
 WMI. Wладение Mагической Iнформацией. Часть 2
WMI. Wладение Mагической Iнформацией. Часть 2
Здравствуйте, уважаемые читатели! Помните меня? А статью про WMI, где я на двух языках показывал как просто получить власть над Windows посредством… Ктулху? Не-е-е. Читаем дальше? Однозначно, сегодня мы продолжим наши изыскания…
Продолжение. Начало смотрите в предыдущем номере журнала…
Виталий Белик
by Stilet www.programmersforum.ru
Ну, да ладно. Мы же пойдем ровным путем, дающим краткое, но четкое представление о том, как будет работать система. Заранее раскрывая карты, скажу, что с Делфийском коде обращение к записям и полям таблицы будет похоже на обращение к ячейкам массива.
Двумерного разумеется. На С++
TWMIRecord* TWMI::Item(int i){
TWMIRecord *r=0;
// Инициируем итератор для списка
list<twmirecord>::iterator k;
// Пройдемся циклом по списку пока не дойдем
// до указанной по номеру записи
for(k=RecList.begin();(k!=RecList.end())&&(i>0);k++,i—);
// Если записть такая нойдена, в том смысле
// что индекс запрошенной записи
// не вылезает за пределы списка
// то вернем объект из списка
if(k!=RecList.end()&&i>=0){
r=&*k;
}
return r;
};Syhi-подсветка кода
TWMIRecord *r=0;
// Инициируем итератор для списка
list<twmirecord>::iterator k;
// Пройдемся циклом по списку пока не дойдем
// до указанной по номеру записи
for(k=RecList.begin();(k!=RecList.end())&&(i>0);k++,i—);
// Если записть такая нойдена, в том смысле
// что индекс запрошенной записи
// не вылезает за пределы списка
// то вернем объект из списка
if(k!=RecList.end()&&i>=0){
r=&*k;
}
return r;
};Syhi-подсветка кода
Здесь единственный бок – я не знаю, как проверить выход за пределы списка указанного номера запрошенной записи, и так же не знаю другого способа получить по номеру из списка без прохода циклом. Поэтому я решил просто написать проход циклом по списку, пока не конец, или пока нужный номер записи в списке не достигнут. В принципе это работает, так что пусть так и остается.
Ладушки. Пора приступать к описанию второго класса, класса отвечающего за обработку записи TWMIRecord (на Делфи):
TWMIRecord=class
private
// Список полей и их значений
FFields:TStringList;
// Процедура получения данных из полей записи
Procedure Enum(Obj:OleVariant);
Constructor Create;
Destructor Free;
function GetItem(v: Variant): String;
public
Path:String;
// Функция возвращающая число полей
Function HighRecordIndex:Integer;
// Функция, возвращающая имя i-того поля
Function FieldName(i:integer):String;
// Свойство получающее значение определенного поля
Property Item[v:Variant]:String read GetItem; default;
end;Syhi-подсветка кода
private
// Список полей и их значений
FFields:TStringList;
// Процедура получения данных из полей записи
Procedure Enum(Obj:OleVariant);
Constructor Create;
Destructor Free;
function GetItem(v: Variant): String;
public
Path:String;
// Функция возвращающая число полей
Function HighRecordIndex:Integer;
// Функция, возвращающая имя i-того поля
Function FieldName(i:integer):String;
// Свойство получающее значение определенного поля
Property Item[v:Variant]:String read GetItem; default;
end;Syhi-подсветка кода
Здесь особое внимание должно быть уделено процедуре Enum(), которая, приняв объект-запись от энумератора записей, прокатится по ее полям, выделив ее значения в свой список, и свойство Item, объявленное по умолчанию. Оно может принимать как строку – при этом получить значение по имени поля, так и число, чтоб получить значение из поля по определенному номеру. Это дает серьезную мобильность, можно в цикле пройтись по полям, а можно просто получить значение по имени поля (на С++):
struct sField{
// Имя поля
wstring Name;
// Значение поля, переведенное в строку
wstring Value;
};
class TWMIRecord
{
private:
// Свойство, принимающее значение поля
VARIANT Prop;
// Обьект-записи полученный от провайдера
IWbemClassObject *Obj;
wstring FString;
// Список полей и их значений
list<sfield> FFields;
// Количество полей
int CountList;
public:
TWMIRecord(IWbemClassObject *AObj);
~TWMIRecord(void);
// Метод, получающий поле по имени
sField Field(wstring AName);
// Метод получающий поле по номеру
sField Field(int iName);
// Функция, получающая верхний индекс в списке полей
int high();
};Syhi-подсветка кода
// Имя поля
wstring Name;
// Значение поля, переведенное в строку
wstring Value;
};
class TWMIRecord
{
private:
// Свойство, принимающее значение поля
VARIANT Prop;
// Обьект-записи полученный от провайдера
IWbemClassObject *Obj;
wstring FString;
// Список полей и их значений
list<sfield> FFields;
// Количество полей
int CountList;
public:
TWMIRecord(IWbemClassObject *AObj);
~TWMIRecord(void);
// Метод, получающий поле по имени
sField Field(wstring AName);
// Метод получающий поле по номеру
sField Field(int iName);
// Функция, получающая верхний индекс в списке полей
int high();
};Syhi-подсветка кода
Кто-то скажет: «А зачем Field(wstring AName) возвращает структуру, достаточно ведь вернуть значение?». Верно, но вдруг захочется пополнить структуру еще какой-нибудь характеристикой поля, например, типом, так что пусть этот метод возвращает всю структуру – ничего пагубного в этом нет. Ок. Реализуем этот класс (на Делфи):
{ TWMIRecord }
constructor TWMIRecord.Create;
begin
// Создается класс списка полей и их значения
FFields:=TStringList.Create;
// Здесь я не предполагал хранить ничегокроме имя и значения поля
// так что TString’a вполне хватит
end;
// Метод проходя по полям
procedure TWMIRecord.Enum(Obj: OleVariant);
var PropEnum:IEnumVariant; i:Cardinal; s:string; d:double;
begin
// Приготовим список для внесения в него данных
FFields.Clear;
// Инициализируем энумератор
PropEnum:=IEnumVariant(IUnknown(Obj.Properties_._NewEnum)); //Поля
// и начнем по нему лазить, пока он выбирает записи
while (PropEnum.Next(1, Obj, i) = S_OK) do begin
try
// Здесь я прикрутил распознавание типа даты
// если поле содержит дату, то привести ее в
// понятный человеку вид
if obj.CIMType=$00000065 then begin
s:=Obj.Value;
s:=copy(s,7,2)+‘.’+copy(s,5,2)+‘.’+copy(s,1,4);
end else
// если же это не дата, то пусть сама программа приводит
// значение к строке. в противном случае в строку
// должно писаться значение [NULL], если такое поле пусто
if VarIsNull(Obj.Value) then s:=WMIValueNull else s:=Obj.Value;
FFields.Values[Obj.Name]:=s;
except
end;
end;
end;
function TWMIRecord.FieldName(i: integer): String;
begin Result:=»;
// если номер попадает в список полей, вернем имя поля
// по его номеру
if (i>=0)and(i<FFields.Count) then
Result:=FFields.Names[i];
end;
destructor TWMIRecord.Free;
begin
// Освободим список, уберем мусор
FFields.Free;FFields:=nil;
end;
function TWMIRecord.GetItem(v: Variant): String;
begin
Result:=»;
// Если мы хотим получить значение по номеру поля
// нужно проверить, не выходит ли указанный индекс
// за пределы списка полей
if VarIsOrdinal(v)and(v>=0)and(v<FFields.Count) then
// И если не выходит — вернуть это поле
Result:=FFields.Values[FFields.Names[v]];
// если же мы хотим получить значение поля по имени
if VarIsStr(v) then
// мы просто передаем имя, и если
// поле с таким именен есть возвращается его значение
Result:=FFields.Values[v];
// иначе вернется пустая строка
end;
function TWMIRecord.HighRecordIndex: Integer;
begin
// Последний индекс в списке полей
Result:=FFields.Count-1;
end;Syhi-подсветка кода
constructor TWMIRecord.Create;
begin
// Создается класс списка полей и их значения
FFields:=TStringList.Create;
// Здесь я не предполагал хранить ничегокроме имя и значения поля
// так что TString’a вполне хватит
end;
// Метод проходя по полям
procedure TWMIRecord.Enum(Obj: OleVariant);
var PropEnum:IEnumVariant; i:Cardinal; s:string; d:double;
begin
// Приготовим список для внесения в него данных
FFields.Clear;
// Инициализируем энумератор
PropEnum:=IEnumVariant(IUnknown(Obj.Properties_._NewEnum)); //Поля
// и начнем по нему лазить, пока он выбирает записи
while (PropEnum.Next(1, Obj, i) = S_OK) do begin
try
// Здесь я прикрутил распознавание типа даты
// если поле содержит дату, то привести ее в
// понятный человеку вид
if obj.CIMType=$00000065 then begin
s:=Obj.Value;
s:=copy(s,7,2)+‘.’+copy(s,5,2)+‘.’+copy(s,1,4);
end else
// если же это не дата, то пусть сама программа приводит
// значение к строке. в противном случае в строку
// должно писаться значение [NULL], если такое поле пусто
if VarIsNull(Obj.Value) then s:=WMIValueNull else s:=Obj.Value;
FFields.Values[Obj.Name]:=s;
except
end;
end;
end;
function TWMIRecord.FieldName(i: integer): String;
begin Result:=»;
// если номер попадает в список полей, вернем имя поля
// по его номеру
if (i>=0)and(i<FFields.Count) then
Result:=FFields.Names[i];
end;
destructor TWMIRecord.Free;
begin
// Освободим список, уберем мусор
FFields.Free;FFields:=nil;
end;
function TWMIRecord.GetItem(v: Variant): String;
begin
Result:=»;
// Если мы хотим получить значение по номеру поля
// нужно проверить, не выходит ли указанный индекс
// за пределы списка полей
if VarIsOrdinal(v)and(v>=0)and(v<FFields.Count) then
// И если не выходит — вернуть это поле
Result:=FFields.Values[FFields.Names[v]];
// если же мы хотим получить значение поля по имени
if VarIsStr(v) then
// мы просто передаем имя, и если
// поле с таким именен есть возвращается его значение
Result:=FFields.Values[v];
// иначе вернется пустая строка
end;
function TWMIRecord.HighRecordIndex: Integer;
begin
// Последний индекс в списке полей
Result:=FFields.Count-1;
end;Syhi-подсветка кода
Что тут добавить еще? Энумератором получаем поля и их значения, раскладывая в «массив». И даем возможность выбирать из этого массива в самой программе, любым способом, по индексу или по имени. И еще константа const WMIValueNull='[NULL]’. На С++:
TWMIRecord::TWMIRecord(IWbemClassObject *AObj)
{
Obj=AObj;
HRESULT hres;
BSTR pstrName;
VARIANT pVal;
CIMTYPE pvtType;
sField field;
// Начинаем перечисление
hres=Obj->BeginEnumeration(0);
CountList=0;
// Если это возможно конечно, проходимся циклом
// пока не нарвемся на ошибку, или пока энумератор не
// выберет все данные
while(!FAILED(hres)&&(hres!=WBEM_S_NO_MORE_DATA)){
// Получим очередное "следующее" поле
hres=Obj->Next(0,&pstrName,&pVal,&pvtType,0);
// Если оно удачно получено
if(!FAILED(hres)&&(hres!=WBEM_S_NO_MORE_DATA)){
field.Name.clear();
// Запишем его имя
field.Name=wstring(_bstr_t(pstrName,false));
// Если его значение не пусто
if(pVal.vt!=VT_NULL){
field.Value.clear();
// получим его, преобразовав в строку в зависимости
// от типа
switch(pvtType){
case wbemCimtypeBoolean:
field.Value=(pVal.boolVal)?L"TRUE":L"FALSE";
break;
case wbemCimtypeString:
field.Value=wstring(_bstr_t(pVal.bstrVal,false));
break;
case wbemCimtypeSint32:
int i=pVal.intVal;
char c[30]="";
itoa(i,c,10);
for(int i=0;i<10&&c[i]!=0;i++){field.Value+=c[i];}
break;
}
}
// и внеся новое поле в наш список
FFields.push_back(field);
// увеличим счетчик количества полей
CountList++;
}
}
}
int TWMIRecord::high()
{
// Вернем верхний индекс списка полей
return CountList-1;
}
TWMIRecord::~TWMIRecord(void)
{
// Освободим список
FFields.clear();
}
sField TWMIRecord::Field(wstring AName){
FString=L"";
sField res={L"",L""};
// Приготовим итератор для прохода по списку
list<sfield>::iterator i=FFields.begin();
// пока не конец списка
for(;i!=FFields.end();i++){
// получим очередной элемент
sField ws=*i;
// проверим не совпадает ли имя поля
// полученного элемента с указанным нами
if(ws.Name==AName){
// Если совпадает — выйдем из цикла
res=*i;
break;
}
}
return res;
};
sField TWMIRecord::Field(int iName){
FString=L"";
sField res;
// Приготовим итератор для прохода по списку
list<sfield>::iterator i;
// пока не конец списка или не достигнут указанный индекс поля
for(i=FFields.begin();(i!=FFields.end())&&(iName>=0);i++,iName—);
// Если список полей весь пройден а индекс поля еще не достигнут
// вернем пустые строки.
if(i!=FFields.end() && iName>=0){ res.Name=L"";res.Value=L"";}
// Иначе вернем данные из списка
else {res=*i;}
return res;
};Syhi-подсветка кода
{
Obj=AObj;
HRESULT hres;
BSTR pstrName;
VARIANT pVal;
CIMTYPE pvtType;
sField field;
// Начинаем перечисление
hres=Obj->BeginEnumeration(0);
CountList=0;
// Если это возможно конечно, проходимся циклом
// пока не нарвемся на ошибку, или пока энумератор не
// выберет все данные
while(!FAILED(hres)&&(hres!=WBEM_S_NO_MORE_DATA)){
// Получим очередное "следующее" поле
hres=Obj->Next(0,&pstrName,&pVal,&pvtType,0);
// Если оно удачно получено
if(!FAILED(hres)&&(hres!=WBEM_S_NO_MORE_DATA)){
field.Name.clear();
// Запишем его имя
field.Name=wstring(_bstr_t(pstrName,false));
// Если его значение не пусто
if(pVal.vt!=VT_NULL){
field.Value.clear();
// получим его, преобразовав в строку в зависимости
// от типа
switch(pvtType){
case wbemCimtypeBoolean:
field.Value=(pVal.boolVal)?L"TRUE":L"FALSE";
break;
case wbemCimtypeString:
field.Value=wstring(_bstr_t(pVal.bstrVal,false));
break;
case wbemCimtypeSint32:
int i=pVal.intVal;
char c[30]="";
itoa(i,c,10);
for(int i=0;i<10&&c[i]!=0;i++){field.Value+=c[i];}
break;
}
}
// и внеся новое поле в наш список
FFields.push_back(field);
// увеличим счетчик количества полей
CountList++;
}
}
}
int TWMIRecord::high()
{
// Вернем верхний индекс списка полей
return CountList-1;
}
TWMIRecord::~TWMIRecord(void)
{
// Освободим список
FFields.clear();
}
sField TWMIRecord::Field(wstring AName){
FString=L"";
sField res={L"",L""};
// Приготовим итератор для прохода по списку
list<sfield>::iterator i=FFields.begin();
// пока не конец списка
for(;i!=FFields.end();i++){
// получим очередной элемент
sField ws=*i;
// проверим не совпадает ли имя поля
// полученного элемента с указанным нами
if(ws.Name==AName){
// Если совпадает — выйдем из цикла
res=*i;
break;
}
}
return res;
};
sField TWMIRecord::Field(int iName){
FString=L"";
sField res;
// Приготовим итератор для прохода по списку
list<sfield>::iterator i;
// пока не конец списка или не достигнут указанный индекс поля
for(i=FFields.begin();(i!=FFields.end())&&(iName>=0);i++,iName—);
// Если список полей весь пройден а индекс поля еще не достигнут
// вернем пустые строки.
if(i!=FFields.end() && iName>=0){ res.Name=L"";res.Value=L"";}
// Иначе вернем данные из списка
else {res=*i;}
return res;
};Syhi-подсветка кода
Опять-таки, итерации по списку – в Делфи, дяди из Борланда дали возможность обращаться к элементам списка как к массиву, как сделано в STL я не знаю, поэтому банально – прошелся циклом по list’y.
Так… Вроде ничего не забыли описать? Если нет, то пора попробовать эту махину в действии.
Starting Line
Начнем, пожалуй, с Делфи. Создадим проект с формой, на него кинем StringGrid, и в обработчике создания формы OnCreate напишем такой код (на Делфи):
procedure TForm1.FormCreate(Sender: TObject);
var w:TWMI;i,j:integer; wr:TWMIRecord;
begin
// Создадим обьект WMI
w:=TWMI.Create(nil);
// Выкатим ему запрос
w.SQL:= ‘SELECT caption, CommandLine FROM Win32_Process’;
with StringGrid1 do begin
// Развернем Грид на нужно е количество записей
RowCount:=w.HighObject+1;
FixedCols:=0;
// В цикле пройдясь по записям
for i:=0 to w.HighObject do begin
wr:=w[i];
if ColCount<(wr.HighRecordIndex+1) then ColCount:=(wr.HighRecordIndex+1);
// впишем значения полей в таблицу
for j:=0 to wr.HighRecordIndex do begin
Cells[j,i]:=wr[j];
end;
end;
end;
w.Free;
end;Syhi-подсветка кода
var w:TWMI;i,j:integer; wr:TWMIRecord;
begin
// Создадим обьект WMI
w:=TWMI.Create(nil);
// Выкатим ему запрос
w.SQL:= ‘SELECT caption, CommandLine FROM Win32_Process’;
with StringGrid1 do begin
// Развернем Грид на нужно е количество записей
RowCount:=w.HighObject+1;
FixedCols:=0;
// В цикле пройдясь по записям
for i:=0 to w.HighObject do begin
wr:=w[i];
if ColCount<(wr.HighRecordIndex+1) then ColCount:=(wr.HighRecordIndex+1);
// впишем значения полей в таблицу
for j:=0 to wr.HighRecordIndex do begin
Cells[j,i]:=wr[j];
end;
end;
end;
w.Free;
end;Syhi-подсветка кода
Перед этим не забудем создать в проекте Unit (назовем его Unit2), и вложить в него код классов, не забыв в нем указать необходимые модули для работы механизма в описанный классах uses Classes,contnrs,variants,ActiveX,Comobj; Не забыв указать в разделе uses модуля формы этот самый Unit2.
Теперь код обработчика на форме связан с модулем, где описаны классы.
Если все проделано правильно после жмака по F9 на экран выкатится форма со списком процессов (см. рисунок 1):
Рис. 1. Работа программы написанной на Делфи
Ну вот. Запрос SELECT caption, CommandLine FROM Win32_Process получил набор с заголовками запущенных в целевой системе процессов, и путями к файлам этих процессов. Администратору сразу видно, что запущено у пользователя, не нужно идти к нему, или использовать платные средства удаленного администрирования. Увы, не все они могут показать такую информацию, а иногда это важно для понимания состояния системы.
А теперь тоже самое но на С++. Лукаво не мудрствуя, сделаем это в консоли, это попроще будет:
#include "stdafx.h"
#include "TWMI.h"
#include <locale>
#include <iostream>
int _tmain(int argc, _TCHAR* argv[])
{
// Включим русский язык для консоли
setlocale(LC_ALL,"russian");
// Создадим класс WMI
TWMI *wmi=new TWMI();
// Скормим ему запрос
if(wmi->SetQuery("SELECT caption FROM Win32_Process")){
// Если запрос удачно обработал
printf("Получили данные\n");
int i=0;
// В цикле пройдемся по записям,
for(TWMIRecord *r=wmi->Item(i);r;i++,r=wmi->Item(i)){
// И выведем значение поля
wcout<<r->Field(L"Caption").Value<<‘\n‘;
}
} else {printf("Неудача");}
// после чего уберем мусор
delete wmi;
getchar();
return 0;
}Syhi-подсветка кода
#include "TWMI.h"
#include <locale>
#include <iostream>
int _tmain(int argc, _TCHAR* argv[])
{
// Включим русский язык для консоли
setlocale(LC_ALL,"russian");
// Создадим класс WMI
TWMI *wmi=new TWMI();
// Скормим ему запрос
if(wmi->SetQuery("SELECT caption FROM Win32_Process")){
// Если запрос удачно обработал
printf("Получили данные\n");
int i=0;
// В цикле пройдемся по записям,
for(TWMIRecord *r=wmi->Item(i);r;i++,r=wmi->Item(i)){
// И выведем значение поля
wcout<<r->Field(L"Caption").Value<<‘\n‘;
}
} else {printf("Неудача");}
// после чего уберем мусор
delete wmi;
getchar();
return 0;
}Syhi-подсветка кода
Здесь тоже самое, разве что я изменил запрос. Попросил только заголовки процессов. В консоли красиво не выведешь. Здесь же применен метод получения поля по его имени, но с таким же успехом его можно заменить на:
for(int i=0;i<r->high();i++){
sField f=r->Field(i);
wcout<<f.Name<<‘=’<<f.Value<<‘\n‘;
} wcout<<‘\n‘;Syhi-подсветка кода
sField f=r->Field(i);
wcout<<f.Name<<‘=’<<f.Value<<‘\n‘;
} wcout<<‘\n‘;Syhi-подсветка кода
Где в цикле будет вестись проход по всем полям по их номеру. Запустим и посмотрим, что же получилось (см. рисунки 2, 3):
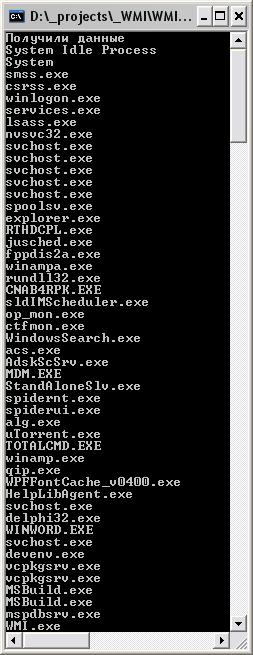
Рис. 2. Получение по имени поля
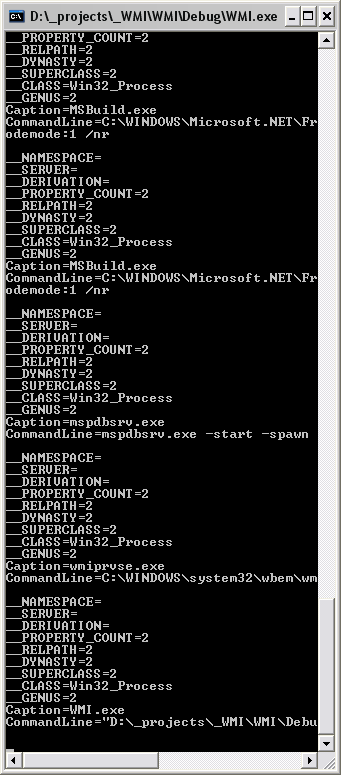
Рис. 3. Получение нескольких полей
Запрос на рисунке 2 показывает, что все хорошо прошло. Объект получил от провайдера WMI информацию, и программа вывела ее на экран. На втором же рисунке показана возможность показа всех полей, одна запись тут разделена пустой строкой. Вообще я в запросе указал два поля CommandLine, но провайдер предоставляет кроме этого еще несколько, судя по всему стандартных полей, характеризующих тип самого запроса. Например, свойство __PROPERTY_COUNT=2 говорит о том, что мы запросили два поля, между прочим, им можно пользоваться, чтоб узнать количество полей. А __CLASS=Win32_Process говорит о том, какое «представление» использовалось. Мы хотели получить список процессов – вот и получили, соответственно и класс Win32_Process. Ну и, конечно же, в конце данные о тех самых наших полях, которые мы запрашивали, Caption и CommandLine. Все работает замечательно.
Теперь можно самостоятельно написать свою «тулзу» для удаленного администрирования. Учитывая, что классов в WMI много, можно много чего узнать о компьютерах в сети. Например, можно узнать, что за пользователи описаны в компьютере, выкатив запрос SELECT * FROM Win32_Account (см. рисунок 4):
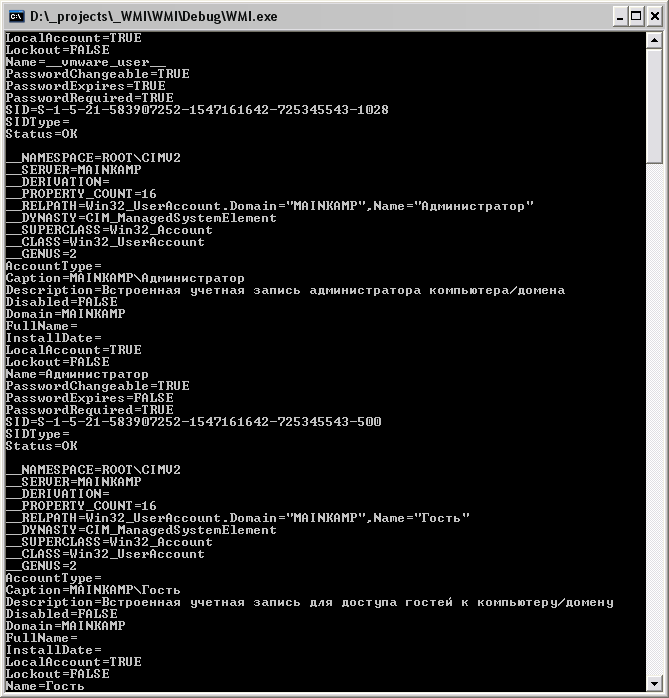
Рис. 4. Информация о пользователях на целевой машине
Или предположим звонит юзер:
-у меня материнка с ума сошла, дайте дрова!
-какая у вас материнка?
-пластиковая, из магазина…
Да-да. Это не анекдот. Юзеры, иногда в силу своей компьютерной неграмотности, такое откалывают, что Задорнов «плякаль». А, запросив SELECT * FROM Win32_BaseBoard у виндоуса того пользователя можно увидеть, что у него (см. рисунок 5):
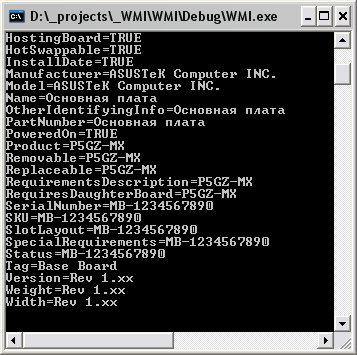
Рис. 5. Параметры материнской платы
Оказывается Асус. О! И даже серийник есть. Ну, теперь просто запросить на сайте производителя дровишки для P5GZ-MX и удаленно RAdmin’ом например проинсталлировать. Кто-то скажет: «Так, а чего самим РАдмином или типа него не посмотреть денить в свойствах?» Где? Все знают, где информация такая лежит? Ану-ка, партизаны: «шнель шпрехен… ». Я лично не знаю, где можно посмотреть такие подробности. А тут раз – и все как на ладони. А тем паче, своя Наташка… ))))
Post Scriptum
Ну вот. Собственно, на этом можно поставить точку. А можно и троеточие, ибо WMI помимо получения информации позволяет управлять компьютером. Опять-таки теми же запросами. «Тушить процессы» или выключать компьютер удаленно.
Например, если вызвать метод Terminate класса, полученного по запросу на Win32_Process, то можно потушить все процессы из запроса. Порывшись в MSDN, можно даже найти пример [2]. Если ссылку еще не завалили, посмотрите, как это делается: Запросом получается набор объектов, у которых вызывается метод Terminate, и они тушатся.
В общем, все это очень обнадеживает, и, если системный администратор владеет этим каратэ – цены ему нет. Домен свой он будет держать атланту подобно. Так что рекомендую вляпаться в эти микрософтовские катакомбы – не пожалеете.
The Чтиво
- Ресурс вики http://ru.wikipedia.org/wiki/WMI
- MSDN http://msdn.microsoft.com/en-us/library/aa393907%28VS.85%29.aspx
Статья из девятого выпуска журнала «ПРОграммист».
Обсудить на форуме — WMI. Wладение Mагической Iнформацией. Часть 2
23rd
Быстрое написание программ на WinAPI
Все программисты делятся на две группы – oldschool и новую волну. Сыны старой школы помнят историю о 640 килобайтах, помнят о тысяче игр на одной дискете… Новая волна, чаще всего, даже не знает устройство компьютера, но так же считается – программистами. Использование IDE изменило представление о программистах. Посмотрим, что же может дать отказ от визуального программирования. В этой статье я опишу один из способов быстрого написания приложений с использованием функций WinAPI.
Алексей Шишкин
by Alex Cones http://flsoft.ru
Вступление или «Кому это нужно?»
Вы можете задаться вопросом, зачем же насиловать свой мозг, если давным-давно изобретена VCL, MFC и прочие прелести визуального программирования? Для ответа на этот вопрос давайте посмотрим на плюсы и минусы визуального и низкоуровневого* программирования.
Итак, рассмотрим плюсы визуального программирования:
- быстрое написание программ (достаточно накидать кнопок на форму и написать их процедуры);
- удобство использования (это удобнее, чем описывать каждый шаг на низком уровне, не нужно заботиться о памяти).
И минусы:
- огромный размер приложений — «пустое» приложение на Delphi «весит» ~300 кб;
- из-за огромного количества надстроек быстродействием приходится пренебречь, особенно в плане графики на Canvas.
И в противоположность, рассмотрим плюсы низкоуровневого программирования на WinAPI:
- малый размер конечных файлов (согласитесь, что между 30 кб и 300 кб есть большая разница);
- быстродействие на достаточно высоком уровне (быстрее получится только, если писать целиком на ассемблере – то еще удовольствие).
И минусы:
- нет визуализации (труднее представить, что создать, что уничтожить, что где писать);
- для создания обычного окна потребуется примерно 50 строк кода (создать и зарегистрировать само приложение, создать окно, заботиться о всех параметрах);
- необходимо помнить о необходимости следить за использованием памяти — освобождением, взятием. Здесь обычным *.Free не обойдешься.
Но, если мы представим, что избавились о минусах программирования на WinAPI, чаша весов склонится в сторону низкоуровневого программирования. Так как же нам от них избавиться? Итак, взглянем в сторону фреймворков, которые это позволяют. За всю мою практику программирования на Delphi сталкивался с таким только единожды** – APIx 2 (Visual WinAPI). Но данное средство разработки не предполагает активное использование графики, только создание окон и кнопок. Поэтому я решил создать такую библиотеку, которая позволит не только быстро создавать окна, но и активно использовать графику.
Не хвастаясь особо, сообщу, что мне это удалось. И через три недели разработки GRAY FUR был готов.
WTF… или что это даст?
Mon ami, это же элементарно: не нужно заботиться о расходе и приходе памяти, размышлениям о бренности окон. Да, мы по прежнему не имеем дела с визуальностью, но, согласитесь, что намного удобнее вызвать одну процедуру, чем записывать пару десятков с многочисленными параметрами. Так, например отрисовать текстуру на экране можно так:
Var
Loc : HDC;
TNum : Integer;
Begin
Loc := CreateCompatibleDC(DC);
SelectObject(Loc, Bitmap);
BitBlt(DC,
X, Y,
Width,
Height,
Loc,
0, 0,
SRCCOPY);
DeleteDC(Loc);
End;Syhi-подсветка кода
Loc : HDC;
TNum : Integer;
Begin
Loc := CreateCompatibleDC(DC);
SelectObject(Loc, Bitmap);
BitBlt(DC,
X, Y,
Width,
Height,
Loc,
0, 0,
SRCCOPY);
DeleteDC(Loc);
End;Syhi-подсветка кода
А можно и так:
Причем, если мы не подумаем о том, как создать двойную буферизацию в первом случае изображение будет мерцать при отрисовке. Во втором случае все это уже встроено в систему.
Panic button
Рассмотрим написание Panic button с использованием нашей системы. Для того, кто еще не читал моей статьи о создании Panic Button на WinAPI [1] поясню, что эта кнопка на экране будет сворачивать все окна по нажатию на нее.
Итак, скачаем FrameWork и посмотрим, как же это делается. По привычке, я буду делать это на Lazarus, но вы так же можете использовать Delphi, используя пакет для разработки под Delphi.
Для начала создадим то, что кнопка должна делать:
Procedure HideAll(Handle : HWND); // Эту процедуру будем использовать по клику левой кнопки мыши
Begin
Keybd_event(VK_LWIN,0,0,0); // Эмулируем нажатие клавиши Win
Keybd_event(VK_D ,0,0,0); // Эмулируем нажатие клавиши D
Keybd_event(VK_D ,0,KEYEVENTF_KEYUP,0); // Отпустим D — все окна свернутся
Keybd_event(VK_LWIN,0,KEYEVENTF_KEYUP,0); // Отпустим Win.
End;Syhi-подсветка кода
Begin
Keybd_event(VK_LWIN,0,0,0); // Эмулируем нажатие клавиши Win
Keybd_event(VK_D ,0,0,0); // Эмулируем нажатие клавиши D
Keybd_event(VK_D ,0,KEYEVENTF_KEYUP,0); // Отпустим D — все окна свернутся
Keybd_event(VK_LWIN,0,KEYEVENTF_KEYUP,0); // Отпустим Win.
End;Syhi-подсветка кода
Так же сделаем процедуру закрытия приложения:
Procedure KillMe(Handle : HWND); // Процедура жестокого убийства
Begin
DestroyTimer(ID); // Удалим таймер, созданием которого мы еще займемся
DestroyApplication; // Уничтожим приложение
End;Syhi-подсветка кода
Begin
DestroyTimer(ID); // Удалим таймер, созданием которого мы еще займемся
DestroyApplication; // Уничтожим приложение
End;Syhi-подсветка кода
И для полного счастья сделаем так, чтобы кнопка всегда была наверху:
Procedure OnTop;
Begin
SetformOnTop(Form1, TRUE); // Установим её всегда сверху.
End;Syhi-подсветка кода
Begin
SetformOnTop(Form1, TRUE); // Установим её всегда сверху.
End;Syhi-подсветка кода
Да, и еще создадим функцию для вычисления вертикальной позиции:
Function CalculateYp : Integer;
Var
R : Rect;
H : Handle;
W : Integer;
PH : Integer;
Begin
W := GetSystemMetrics(SM_CYSCREEN); // Получаем вертикальное разрешение
ZeroMemory(@R, SizeOf(R));
H := FindWindow(‘Shell_TrayWnd’, Nil); // Найдем окно панели задач
GetWindowRect(H, R); // Его размеры
PH := R.Bottom — R.Top; // Вычислим высоту
Result := W — PH — Form1.Height; // И получим искомое
End;Syhi-подсветка кода
Var
R : Rect;
H : Handle;
W : Integer;
PH : Integer;
Begin
W := GetSystemMetrics(SM_CYSCREEN); // Получаем вертикальное разрешение
ZeroMemory(@R, SizeOf(R));
H := FindWindow(‘Shell_TrayWnd’, Nil); // Найдем окно панели задач
GetWindowRect(H, R); // Его размеры
PH := R.Bottom — R.Top; // Вычислим высоту
Result := W — PH — Form1.Height; // И получим искомое
End;Syhi-подсветка кода
Рассмотрим само тело программы:
program Project1;
{$mode delphi}{$H+} // Директивы для Lazarus
Uses
Windows, // Подключим Windows
Scow; // Подключим модуль-связку проекта
Var
Form1 : TForm; // Наше главное окно. Тип описан в Scow
ID : Integer; // ID таймера
// Здесь находятся процедуры, описанные выше
begin
CreateApplication; // Создаем приложение
SetApplicationReaction1(HN_LBUTTONDOWN, HideAll); // Назначим событие по левому клику
SetApplicationReaction1(HN_RBUTTONDOWN, KillMe); // Назначим событие по правому клику
CreateForm(Form1, FALSE); // Создадим форму FALSE — не показывать на панели задач
ShowForm(Form1, TRUE); // Покажем ее на экране
ResizeForm(Form1, 64, 64); // Назначим размеры
MoveForm(Form1, 0, CalculateYp); // И положение
LoadTexture(Form1, ‘Button.bmp’, ‘Button’); // Загрузим текстуру в хранилище****
Draw(Form1, ‘Button’, 0, 0, FALSE); // Нарисуем текстуру на буфере
BufferDraw(Form1); // И выведем его на экран
ID := CreateTimer(1000, OnTop); // Создадим таймер для вызова процедуры OnTop
CollectMessages; // И организуем цикл сбора сообщений для корректной работы приложения
end. // That’s all, folks!Syhi-подсветка кода
{$mode delphi}{$H+} // Директивы для Lazarus
Uses
Windows, // Подключим Windows
Scow; // Подключим модуль-связку проекта
Var
Form1 : TForm; // Наше главное окно. Тип описан в Scow
ID : Integer; // ID таймера
// Здесь находятся процедуры, описанные выше
begin
CreateApplication; // Создаем приложение
SetApplicationReaction1(HN_LBUTTONDOWN, HideAll); // Назначим событие по левому клику
SetApplicationReaction1(HN_RBUTTONDOWN, KillMe); // Назначим событие по правому клику
CreateForm(Form1, FALSE); // Создадим форму FALSE — не показывать на панели задач
ShowForm(Form1, TRUE); // Покажем ее на экране
ResizeForm(Form1, 64, 64); // Назначим размеры
MoveForm(Form1, 0, CalculateYp); // И положение
LoadTexture(Form1, ‘Button.bmp’, ‘Button’); // Загрузим текстуру в хранилище****
Draw(Form1, ‘Button’, 0, 0, FALSE); // Нарисуем текстуру на буфере
BufferDraw(Form1); // И выведем его на экран
ID := CreateTimer(1000, OnTop); // Создадим таймер для вызова процедуры OnTop
CollectMessages; // И организуем цикл сбора сообщений для корректной работы приложения
end. // That’s all, folks!Syhi-подсветка кода
Да, и это все, как и говорится в последней строке программы. Попробуйте поискать многочисленные работы с памятью и прочими непристойностями — их просто нет. Таким образом, мы избавились от главного минуса программ на WinAPI – скорости и сложности написания. И получили плюсы – размер проекта на Delphi всего ~20 кБ по сравнению с ~300 и 39 кБ в Lazarus по сравнению с ~900 кБ. Так же не пострадало и быстродействие – прямые работы с памятью в операциях с графикой и прямой вызов WinAPI функций в проекте.
Вместо заключения
Итак, использование фреймворка дало свои плюсы. Быстрота написания (на это у меня ушло не более 3-х минут), малый размер и быстродействие – все это в одном флаконе. Так же, так как практически все функции имеют понятные названия и параметры то его можно запросто использовать для обучения основам управления программой на WinAPI. В общем, я надеюсь, что он, повторяя путь развития паскаля, перейдет в массы.
Ссылки
- Алексей Шишкин. WinAPI графика. Panic button. – ПРОграммист, Клуб ПРОграммистов, 2010, №8, с.24
- Скачать проект GRAY FUR http://squary.ru/wiki/index.php
Статья из девятого выпуска журнала «ПРОграммист».
23rd
О правильном составлении ТЗ. Часть 2
Прежде всего, хочу извиниться перед читателями, за то, что продолжение первой статьи запоздало, простуда подкралась незаметно. Ну, вот я готова представить вашему вниманию следующую часть рассказа о правильном составлении ТЗ. В прошлой статье я постаралась ответить на вопросы: что такое ТЗ, зачем оно нам необходимо и кто должен его писать. Также постаралась раскрыть возможные последствия отсутствия ТЗ и его неграмотного написания. В этой части я постараюсь рассказать, что нужно и как нужно писать в первых четырех частях ТЗ.
Дарья Устюгова
by Sparky ustyugova90@mail.ru
Введение
В прошлой части материала я привела содержание ТЗ, сложившееся у меня на основе написанных мною ТЗ и прочтенных книгах. Для того, чтобы не заставлять вас искать содержание в прошлом номере и сохранить целостность повествования, приведу его еще раз.
Прежде, чем начать разбор того, что же нам писать в ТЗ, хочу затронуть еще один формальный и очень важный момент: оформление ТЗ. Касаться моментов оформления текста ТЗ я не буду, все описано в ГОСТ 19.106-78 Требования к программным документам, выполненным печатным способом. Что же я хочу обсудить? Я хочу заострить ваше внимание на титульном листе. Что же в нем такого важного и ценного? Именно на нем ставятся подписи разработчика и заказчика. Собственно только после того когда мы и заказчик поставим их, можно приступать к работе. До этого момента ТЗ не имеет никакого юридического веса. Здесь необходимо вспомнить о плюсе ТЗ: ТЗ документ официальный. И именно на его основе будет решаться, выполнили ли мы все необходимые работы. Как оформить титульный лист описано в ГОСТ 19.104-78 Основные надписи. Теперь мы разберемся с каждым пунктом содержания по отдельности.
Содержание ТЗ:
1. Введение
1.1. Наименование программы
1.2. Краткая характеристика области применения программы
1.3. Сроки исполнения работ
2. Основания для разработки
2.1. Заказчик
2.2. Исполнитель
2.3. Основание для разработки
3. Назначение разработки
3.1. Общая концепция системы
3.2. Описание функциональности системы
4. Требования к программе
4.1. Требования к информационным структурам и методам решения
4.2. Требования к функциональным характеристикам
4.3. Требования к надежности
4.3.1. Требования к обеспечению надежного функционирования системы
4.3.2. Типы отказов при работе с системой
4.3.3. Время восстановления после отказа
4.3.4. Допустимые потери данных при отказе
4.3.5. Важная информация, которая должна быть защищена от разрушения
4.3.6. Отказы из-за некорректных действий пользователей системы
4.4. Условия эксплуатации
4.4.1. Климатические условия эксплуатации
4.4.2. Требования к квалификации и численности персонала
4.5. Требования к составу и параметрам технических средств
4.5.1. Требования к серверному аппаратному обеспечению
4.5.2. Требования к клиентскому аппаратному обеспечению
4.5.3. Требования к сетевому аппаратному обеспечению
4.6. Требования к информационной и программной совместимости
4.6.1. Требования к исходным кодам и языкам программирования
4.6.2. Требования к программным средствам, используемым программой
4.6.3. Требования к защите информации и программы
4.7. Маркировка и упаковка
4.8. Транспортировка и хранение
4.9. Специальные требования
5. Требования к программной документации
6. Технико-экономические показатели
7. Стадии и этапы разработки
7.1. Стадии разработки
7.2. Этапы разработки
7.3. Содержание работ по этапам
8. Порядок контроля и приемки
8.1. Виды испытаний
8.2. Общие требования к приемке работ
9. Порядок корректировки Технического задания
Наименование программы
В данном пункте все довольно просто и банально… Мы просто пишем имя нашей программы. Ничего сложного, главное наша фантазия.
Краткая характеристика области применения программы
Здесь описываем, в какой предметной области будет применяться наше творение. Для того чтобы было более понятно приведу пример из моей практики: Программа применяется для автоматизации учета имеющихся книжных изданий, имеющихся читателей, выдачи книжных изданий.
Сроки исполнения работ
Вот мы и подошли к одному из самых сложных пунктов. Наверное, многие читали байку о том, как программисты строят дом. Для тех, кто не слышал, обязательно прочитайте. Да я согласна ставить перед собой сроки выполнения работ тяжело. Часто мы не укладываемся в указанные нами сроки. С чем же это связанно? С тем, что мы не умеем планировать свое время, не можем правильно рассчитать количество ресурсов, которые нам понадобятся для достижения поставленной цели, также нельзя сбрасывать со счетов прочие форс-мажорные обстоятельства.
Вообще советую прочитать такие книги как:
- Фредерик Брукс: «Мифический человеко-месяц или как создаются программные системы»
- Йордан Э., Йордон Эдвард: «Путь камикадзе: Как разработчику программного обеспечения выжить в безнадежном проекте»
Описывать этот пункт в общих чертах и на основе своих проектов, довольно сложно. Нужно помнить, что проекты могут отличаться в корне: сложностью, количеством исполнителей, профессионализмом исполнителей и т.д. Поэтому просто скажу: читайте про управление проектами, в частности про Project Time Management.
Но программу мы пишем для конкретного заказчика, и не факт что заказчик не поставит перед нами какие-то свои сроки. Скорее всего, поставит. Что же нам делать в этом случае? Мы на время забываем про сроки, предложенные или навязанные заказчиком, и рассчитываем их самостоятельно. Дальше все будет зависеть от того, насколько наши сроки и сроки заказчика будут отличаться. Если они совсем не различаются или заказчик предлагает более длительный срок, мы соглашаемся. Ни в коем случае нельзя говорить заказчику: «Что это за гигантские сроки, мы справимся в 2 раза быстрее». Мы, конечно, теоретически сможем это сделать, а если мы сократим сроки и не успеем, мы останемся в «минусе». Поэтому некий запас во времени никогда не помешает. Мы рассмотрели оптимальный вариант, но сроки, предложенные заказчиком, могут оказаться меньше. Что же делать в таком случае? Вариантов немного – всего 3.
- Первый вариант: сразу же скажу он самый наихудший. Согласиться на эти сроки. Почему же? Если сроки чуть меньше наших, это не смертельно, но довольно опасно. Согласитесь, работать на износ довольно тяжело, но все-таки возможно, вот только не известно насколько это уменьшит реальные сроки, и уменьшит ли. Вообщем решать придется самостоятельно, во многом решение будет зависеть от того насколько вас заинтересует проект и какие риски появятся, если вы не уложитесь в сроки.
Но, если сроки отличаются сильно, и мы беремся за этот проект, проект сразу, же можно записывать в безнадежные, а нам готовить компенсацию заказчику, потому как зачастую заказчику не достаточно фразы: «подождите еще месяц и все будет сделано». Нет, конечно, заказчик может подождать месяц, но вот, если нам понадобится второй, заказчик задумается, и все может закончиться плачевно для нас. Заказчик сможет наказать нас рублем или еще хуже – обратиться в суд, нужно отметить, что основания для этого у него будут. Также может пострадать наша репутация, и если заказчику понадобится еще какая-либо программа, вероятно, что к нам он уже не обратится, еще и отговорит своих партнеров и просто знакомых.
Тут мы снова подошли к мысли о том, что ТЗ документ официальный. И если там написано, что мы должны завершить свою работу 12.12.2010, то мы должны это сделать.
- Второй вариант: отказаться от выполнения этого проекта.
- Третий вариант: самый наилучший для нас, но не факт что это устроит заказчика. Необходимо ему объяснить, что уложиться в сроки, предложенные им нереально. Сделать это нужно в доступной для его понимания форме.
В заключение хочу сказать, что начинать нужно именно с 3 варианта. Заказчик тоже человек, и если грамотно аргументировать, почему наше детище не может родиться быстрее определенного нами срока.
Заказчик
В данном пункте нет ничего нетривиального, просто пишем, кто является нашим родным и любимым заказчиком
Исполнитель
Данный пункт похож на предыдущий, но есть одна особенность, если мы работаем в команде, необходимо упомянуть обо всех участниках проекта, указать одного себя любимого недостаточно. Нет, конечно, это можно сделать, но в таком случае, за все косяки будем отвечать самостоятельно. Заказчику будет все равно, что это ошибка Васи, которого заказчик никогда не видел, и ранее о нем не слышал.
Основание для разработки
Еще один довольно важный пункт. В большинстве случаев помимо ТЗ, заказчик и исполнитель заключают договор, за подробностями обращаемся к гражданскому и трудовому кодексам. В ТЗ указываем, что был подписан договор на указание услуги по созданию программного продукта, указываем номер договора. Если договора нет, этот пункт будет отсутствовать.
Общая концепция системы
Для того чтобы написать этот пункт необходимо провести анализ предметной области для которой предназначена наша программа, определить какие бизнес-задачи будут решать с ее помощью. Но в данном пункте не требуется глубокий анализ, все это ждет нас впереди. Просто описываем, зачем же наше творение создается, и какой же от него будет толк. Для того чтобы более понятно приведу пример: Система позволяет организовать работу библиотекаря, систематизировать информацию об имеющихся книжных изданиях, студентах, преподавателях и сотрудниках использующих библиотеку.
Описание функциональности системы
Вот мы и подошли к одному из самых важных пунктов. Именно в этом пункте описываются функциональные требования к приложению. Если вдруг случится так, что заказчик предъявит нам претензии, это будет, чуть ли не первый пункт проверки экспертов. Поэтому его написанию стоит уделить особое внимание. Именно здесь в большей степени описывается то, что от нас хочет заказчик. Но не нужно забывать, что в половине случаев, заказчик сам не совсем понимает, что, же его душе хочется увидеть в нашем творении, и мы должны каким-то образом это из него вытянуть. Как уже писала в предыдущей статье, это отдельное искусство. Договоримся, что все функциональные требования были сформулированы, осталось их записать в ТЗ.
Как же это сделать? Если в системе представлено несколько категорий пользователей, мы должны это отразить. Кроме того все функции нужно разделить между этими категориями. Если такого разделения нет, то просто перечисляем функции, которые будет выполнять наше приложение.
Есть небольшой нюанс, если приложение добавляет/изменяет какие-либо данные, в скобках необходимо написать какие именно данные добавляются/изменяются. В противном случае, когда при сдаче программы в эксплуатацию заказчик скажет: «А почему в этой табличке нет поля телефон» мы не сможем ему аргументировано возразить. А в случае если мы укажем, какие именно поля содержит таблица, мы просто показываем заказчику документ, в котором написано что этого поля быть не должно.
Требования к информационным структурам и методам решения
Название данного пункта звучит страшно, но на самом деле ничего страшного и не понятно в нем нет. Просто описываем, какие технологии будут применяться в нашем приложении. Чтобы стало совсем понятно, приведу пример: система должна быть реализована согласно технологии «клиент-сервер»; В качестве сервера используется СУБД – сервер; Взаимодействие клиентской и серверной частей системы должно осуществляться согласно протоколу TCP/IP.
Требования к функциональным характеристикам
Этот пункт дублирует пункт Описание функциональности системы, только в более литературной форме. Также здесь описывается, каким образом реализуется взаимодействие с пользователем, например, при помощи набора первичный и вторичных форм.
Требования к обеспечению надёжного функционирования системы
Вот мы и добрались до формальных пунктов, которые пишутся по шаблону. В данном пункте описывается что должен предпринимать заказчик для того чтобы наша программа работала надежно. Просмотрев большое количество ТЗ, я пришла к выводу, что текст данного пункта везде одинаков, поэтому просто приведу его ниже.
Надежное (устойчивое) функционирование программы должно быть обеспечено выполнением Заказчиком совокупности организационно-технических мероприятий, перечень которых приведен ниже:
- Организацией бесперебойного питания технических средств;
- Использованием лицензионного программного обеспечения;
- Регулярным выполнением рекомендаций Министерства труда и социального развития РФ, изложенных в Постановлении от 23 июля 1998 г. «Об утверждении межотраслевых типовых норм времени на работы по сервисному обслуживанию ПЭВМ и оргтехники и сопровождению программных средств»;
- Регулярным выполнением требований ГОСТ 51188-98. Защита информации. Испытания программных средств на наличие компьютерных вирусов;
Типы отказов
Следующий пункт, текст которого тоже не меняется. Здесь мы просто описываем, какие типы сбоев возможны. В процессе работы системы могут случаться отказы следующих типов:
- Сбои в подсистеме работы с сетевыми соединениями (ошибки, связанные с передачей информации между сервером и клиентами, а также ошибки при работе с базой данных системы);
- Отказы, вызванные сбоем электропитания технических средств (иными внешними факторами);
- Отказы, вызванные неисправностью технических средств;
- Отказы, вызванные не фатальным сбоем (не крахом) операционной системы;
- Отказы, вызванные фатальным сбоем (крахом) операционной системы.
Время восстановления после отказа
Этот пункт напрямую связан с предыдущим. Мы просто указываем, какое количество времени понадобится на восстановление работы нашего приложения при возникновении сбоев типы, которых описаны выше. Причем конкретное время в минутах указывать не обязательно. Допустим, если произошел отказ, вызванный фатальным сбоем операционной системы, достаточно написать: время восстановления не должно превышать времени, требуемого на устранение неисправностей технических средств и переустановки программных средств.
Допустимые потери данных при отказе
Каким бы надежным приложением не было наше приложение, сбои в его работе и работе операционной системы и технических средствах возможны. Для того чтобы заказчик знал чего же ему ждать после сбоя как раз и пишется этот пункт. Мы, конечно же, мы можем написать, что при сбое данные потеряны, не будут. К сожалению это вариант утопический. Полная противоположность этому варианту, данные будут потеряны полностью. Но это не устроит нашего любимого заказчика. Думаю, это никого не устроит, тем более, когда транзакциями, механизмами резервного копирования и восстановления никого не удивишь. Думаю для того чтобы стало понятно что писать, я приведу пример: при сбое в подсистеме работы с сетевыми соединениями допускается потеря информации, относящейся к тому справочнику или к той читательской карточке, о которой информация передавалась по каналу связи в момент сбоя. Главным критерием при определении допустимых потерь информации при сбое в перечисленных компонентах является сохранение целостности данных системы.
Важная информация, которая должна быть защищена от разрушения
Почти в каждом приложении есть информация, которая всегда должна оставаться целостной. Данный пункт предназначен для того чтобы зафиксировать что именно относится к наиболее важной информации, какие именно данные необходимо обезопасить в первую очередь. Допустим, что наше приложение работает с какой-либо БД, то, прежде всего, необходимо обеспечить целостность этой БД.
Отказы из-за некорректных действий пользователей системы
Всегда нужно помнить о том, что пользователи бывают разные. Исходя из личного опыта, половина из них общается с компьютером на Вы. Следовательно, наше творение должно терпеть все нападки таких пользователей и не падать. Поэтому срочно вспоминаем про try catch =) Нет, конечно, можно не обрабатывать ошибочные ситуации, но это не правильно. Поэтому в данном пункте пишем, что такие отказы не возможны и реализуем это.
Климатические условия эксплуатации
Работа программы зависит от того сможет ли работать технические средства в данных климатических условиях, поэтому пишем: климатические условия эксплуатации, при которых должны обеспечиваться заданные характеристики, должны удовлетворять требованиям, предъявляемым к техническим средствам в части условий их эксплуатации.
Требования к квалификации и численности персонала
Здесь указываем минимальное количество персонала, который будет работать с нашей программой, также описываем требования к их образованию. Также для каждого пользователя указываем, какие задачи он будет решать, используя наше приложение.
Требования к составу и параметрам технических средств
Все мы хотя бы раз играли в компьютерные игры, держали коробочку от диска, на которой пишут какими характеристиками должен обладать компьютер, чтобы мы могли насладиться игрой. Вот замечательный пример, иллюстрирующий данный пункт ТЗ.
Требования к исходным кодам и языкам программирования
Данный пункт предназначен для отображения прихотей очень привередливых заказчиков разбирающихся в языках программирования. Если по каким-то причинам заказчик просит или требует, чтобы приложение было написано на конкретном языке, именно это отмечаем в данном пункте. Также здесь отмечаем, хочет ли получить заказчик исходники программы.
Требования к программным средствам, используемым программой
Здесь описываем, что же из стороннего софта необходимо для работы нашей программы, начиная с операционной системы и заканчивая каким-нибудь ODBC-драйвером.
Требования к защите информации и программы
Нам может несказанно «повести» и заказчик скажет, что в его приложении будет обрабатываться коммерческая тайна или еще хуже персональные данные или государственная тайна. В таком случае нам придется читать различные ФЗ и реализовывать все требования описанные там. А в ТЗ необходимо отметить какие именно требования по защите информации были выполнены. Но все может быть проще в том случае если заказчик просто попросит сделать авторизацию или что-то подобное.
Если же заказчик не предъявляет никаких требований к защите информации, мы должны не забыть указать это, чтобы исключить какие-либо вопросы при сдаче проекта.
Маркировка и упаковка
В данном пункте описывается, по какому принципу будут нумероваться версии данной программы. Также указывается, на каких носителях программа будет распространяться.
Транспортировка и хранение
Увидев этот пункт впервые, я улыбнулась, потому как что в нем писать не понятно. До сих пор данный пункт остается загадкой, поэтому просто приведу, если можно так выразить свою отписку: специальных требований к транспортировке и хранению не предъявляется.
Специальные требования
Для чего нужен данный пункт? Поясню, если у заказчика остались требования, которые мы не сможем включить ни в один из предыдущих пунктов, то записываем их сюда. Зачем их вообще записывать? Не забываем, что именно ТЗ определяет «все ли мы сделали» и в нем должны быть указаны все требования заказчика.
Вместо заключения
Вот я и рассказала вам о первых четырех главах ТЗ, надеюсь, что вам после прочтения уже не страшно при упоминании ТЗ, вы уже имеете представление о том, что и как в нем писать. В дальнейшем, расскажу об оставшихся моментах.
Источники
- ГОСТ 19.201-78 Техническое задание, требования к содержанию и оформлению http://www.nist.ru/hr/doc/gost/19201-78.htm
- ГОСТ 19.106-78 Требования к программным документам, выполненным печатным способом. http://www.nist.ru/hr/doc/gost/19106-78.htm
- «В круге разработки» Наталья Дубова http://citforum.ru/SE/project/circle
- Единая система программной документации (ЕСПД) http://www.philosoft.ru/espd.zhtml
- Комплексный/Унифицированный процесс разработки ПО http://www.rup-rus.ru
- Введение в управление проектами http://www.prjman.ru/theory/32
Статья из девятого выпуска журнала «ПРОграммист».
23rd
БПФ. Практика использования
Получение спектра в радиотехнике уже стало обыденным явлением. Появились как аппаратные высокоскоростные реализации, например от таких брендов как Tektronix, так и совмещенные варианты анализаторов на основе DSP процессоров или ПЛИС в промышленных или офисных компьютерах. Данным материалом мы начинаем цикл статей посвященных теме анализа спектра сигналов и их визуализации, для чего сегодня разработаем компонент, работающий с цифровым аудиопотоком, и освоим методику Фурье-анализа применительно к распознаванию DTMF.
Сергей Бадло
by raxp http://raxp.radioliga.com
Краткий экскурс…
Спектроанализатор* — это прибор для наблюдения и измерения относительного распределения энергии электромагнитных колебаний в заданной полосе частот и бывает как параллельного или последовательного типа, так и совмещенным. По способу обработки — различают аналоговые и цифровые, а по характеру анализа — скалярные (получение частотно-амплитудных спектров) и векторные (фазо-частотных спектров).
Анализатор спектра позволяет определить амплитуду и частоту спектральных составляющих, входящих в состав анализируемого сигнала. Важнейшим его параметром – является разрешающая способность, т.е. наименьший интервал по частоте между двумя гармониками, которые еще можно измерить.

Рис. 1. «Преимущества софтовых вариантов очевидны лишь на малых частотах, либо при использовании аппаратно-программных реализаций»
Физический смысл или… для чего мы учим математику
Вспомним курс математики [1-6]. Как вы знаете, периодическим сигналом называют такой вид воздействия, когда форма сигнала повторяется через некоторый интервал времени T, который называется периодом. Простейшей формой периодического сигнала является гармонический сигнал или синусоида, которая характеризуется амплитудой, фазой и периодом. Все остальные сигналы будут негармоническими.
Cуществует общая методика исследования периодических негармонических сигналов, основанная на разложении сигналов в ряд Фурье. Данная методика заключается в том, что всегда можно подобрать ряд гармонических сигналов с такими амплитудами, частотами и начальными фазами, алгебраическая сумма ординат которых в любой момент времени равна ординате исследуемого несинусоидального сигнала. В общем случае, ряд Фурье записывают в виде суммы бесконечного числа гармонических составляющих разных частот (см. формула):
U(t) = Uo + SUM ( Um * sin ( k * ? * t + ? ) );
где k — номер гармоники;
k? — угловая частота k- ой гармоники;
? = 2*pi/T — угловая частота первой гармоники;
? — начальная фаза сигнала;
Uo — нулевая гармоника.
Для выделения спектра в радиотехнике, как правило, используется быстрое преобразование Фурье (БПФ). БПФ — это быстрый алгоритм вычисления дискретного преобразования Фурье. То есть алгоритм вычисления за количество действий, меньшее чем O(N2), требуемых для прямого вычисления ДПФ.
Для чего нужно быстрое преобразование Фурье? Допустим у нас есть периодическая функция изменяющаяся по закону синуса x = sin(t) (см. рисунок 2). Максимальная амплитуда этого колебания равна 1. Если умножить его на некоторый коэффициент A, то получим тот же график (см. риснок 3), растянутый по вертикали в A раз: x = A*sin(t)

Рис. 2. Периодическая функция

Рис. 3. Увеличение амплитуды
Период колебания равен 2pi. Если мы хотим увеличить период до T, то надо умножить переменную t на коэффициент [0; 1]. Это вызовет растяжение графика по горизонтали: x = A*sin(2pi/T). Как вы знаете, частота колебания обратна периоду: f = 1/T. Также говорят о круговой частоте, которая вычисляется по формуле: ? = 2pi/T, где x = A*sin(?t).
И, наконец, есть фаза, обозначаемая как ?. Она определяет сдвиг графика колебания влево. В результате сочетания всех этих параметров получается гармоническое колебание (гармоника) или спектральная составляющая.
Если изменить фазу на 90 градусов, то можно перейти от синуса к косинусу. Для удобства, далее будем работать с функцией косинуса:
x = A * cos ( 2pi/T + ? ) = A * cos ( ?t + ? );
Преобразуем по формуле косинуса суммы:
x = A * cos ? * cos ( 2pi/T ) — A * sin ? * sin ( 2pi*t/T );
Выделим элементы, независимые от времени t, и обозначим их как Re и Im (действительная и мнимая части):
x = Re * cos ( 2pi*t/T ) – Im * sin ( 2pi*t / T );
Re = A * cos ?, Im = A * sin ?;
Re = A * cos ?, Im = A * sin ?;
По величинам Re и Im можно однозначно восстановить амплитуду и фазу исходной гармоники:
? = arctg ( Im/Re ), A = sqrt ( Re^2 + Im^2 );
Теперь возьмем обратное преобразование Фурье:
Xn = ( 1/N ) * SUM ( Xk* e ^ ( j*2*pi*k*n / N ) );
И выполним над этой формулой следующие действия:
разложим каждое комплексное Xn на мнимую и действительную составляющие Xn = Re + j*Im разложим экспоненту по формуле Эйлера на синус и косинус действительного аргумента перемножим внесем множитель 1/N под знак суммы и перегруппируем элементы в две суммы:
Xn = ( 1/N ) * SUM ( Xk * [ cos ( 2*pi*k*n/N ) + j * sin ( 2*pi*k*n/N ) ] ) =>
=> ( 1/N ) * SUM ( ( Rek + j*Imk ) * [ cos ( 2*pi*k*n/N ) + j*sin ( 2*pi*k*n/N ) ] ) =>
=> SUM ( ( Rek/N )* cos ( 2*pi*k*n/N ) – ( Imk/N ) * sin ( 2*pi*k*n/N ) ) +
+ j*SUM ( ( Rek/N )* sin ( 2*pi*k*n/N ) + ( Imk/N ) * cos ( 2*pi*k*n/N ) );
=> ( 1/N ) * SUM ( ( Rek + j*Imk ) * [ cos ( 2*pi*k*n/N ) + j*sin ( 2*pi*k*n/N ) ] ) =>
=> SUM ( ( Rek/N )* cos ( 2*pi*k*n/N ) – ( Imk/N ) * sin ( 2*pi*k*n/N ) ) +
+ j*SUM ( ( Rek/N )* sin ( 2*pi*k*n/N ) + ( Imk/N ) * cos ( 2*pi*k*n/N ) );
Как видите, слева стоит действительное число Xn, а справа две суммы, одна из которых помножена на мнимую единицу j. Сами же суммы состоят из действительных слагаемых. Отсюда следует, что вторая сумма равна нулю, если исходная последовательность была действительной. Отбросим ее и получим:
Xn = SUM ( ( Rek/N ) * cos ( 2*pi*k*n/N ) – ( Imk/N ) * sin ( 2*pi*k*n/N ) );
Поскольку при дискретизации мы брали tn = nT/N и Xn = F(tn), то можем выполнить замену: n = tn*N/T. Следовательно, в синусе и косинусе вместо 2pi*k*n/N можно написать 2pi*k*tn/T. В результате получим:
Xn = F(tn) = SUM ( ( Rek/N ) * cos ( 2*pi*k*tn/N ) – ( Imk/N ) * cos ( 2*pi*k*tn/N ) );
Сопоставим эту формулу с формулами для гармоники:
x = A * cos ( 2*pi*t/T + ? ) = A * cos ( ?t + ? );
x = Re * cos ( 2*pi*t/T ) – Im * sin ( 2pi*t / T );
x = Re * cos ( 2*pi*t/T ) – Im * sin ( 2pi*t / T );
Следовательно, сумма представляет собой сумму из N гармонических колебаний разной частоты, фазы и амплитуды:
F(tn) = SUM ( Ak * cos ( 2*pi*tn/Tk + ?k ) ) = SUM ( Gk(tn) );
Далее будем функцию Gk(t) = Ak*cos(2pi*tk/T + ?k) называть k-й гармоникой. Амплитуда, фаза, частота и период каждой из гармоник связаны с коэффициентами Xk формулами:
Xk = Rek + j * Imk;
Xk = N * Ak * e ^ ( j * ?k );
Ak = ( 1/N ) * sqrt ( Rek^2 + Imk^2 );
?k = arctg ( Imk / Rek );
Tk = T/k;
Xk = N * Ak * e ^ ( j * ?k );
Ak = ( 1/N ) * sqrt ( Rek^2 + Imk^2 );
?k = arctg ( Imk / Rek );
Tk = T/k;
Физический смысл дискретного преобразования Фурье состоит в том, чтобы представить некоторый дискретный сигнал в виде суммы гармоник. Параметры каждой гармоники вычисляются прямым преобразованием, а сумма гармоник обратным. При обратном преобразовании мы восстановим исходный или обработанный сигнал.
Описание компонента спектроанализатора
Разрабатываемый компонент предназначен для построения спектра аудио-сигнала, кодирования и декодирования двух-тоновых посылок DTMF (Dual Tone Multi Frequency) и получения «сырых» отсчетов в реальном времени. Его можно использовать в системах сигнализации, различных плеерах аудио-видео файлов и учебных программах работы со звуком. В основу работы компонента положено использование алгоритма быстрого преобразования Фурье (БПФ).
Входным является внутренний буфер с аудиоданными, частотой дискретизации 44100 герц и форматом 16 бит/семпл. Длина буфера фиксирована, в данной версии компонента выбор не реализован и ограничен величиной в 3000 отсчетов. Сам компонент невизуальный.
Внешние свойства и события компонента:
- property About — Copyright

- property DTMF_keys — строка для генерации DTMF
- property DTMF_volume — установка амплитуды генерации
- property DTMF_duration_ms — установка длительности генерации
- property FFT_point — выбор количества точек преобразования БПФ
- property FFT_window — выбора типа сглаживающих окон
- property Key — событие декодированных команд DTMF
- property Spektra — // — выдача спектра после БПФ
- property DataOsc — // — выдача «сырых» отсчетов с аудио-буфера
Результат работы компонента и типичный спектр сигнала DTMF с его распознаванием представлен на (см. рисунок 4):
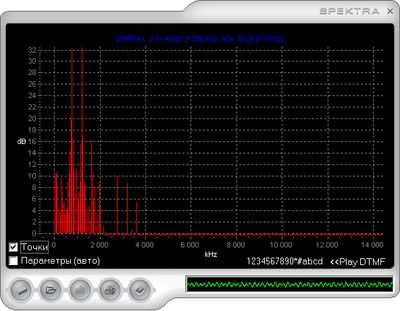
Рис. 4. Визуализация сигнала. Типичный спектр сигнала DTMF
Практика. Разработка ПО и средства отладки
Итак, приступим к основной задаче. Для работы нам следует запастись следующим:
- среда разработки TurboDelphi-Lite portable
- аудиокарта
Вкратце, процедура (прямого) БПФ в компоненте будет включать в себя следующие шаги:
- берем из сигнала N выборок кратным степени 2, т.е. 2^k
- рассчитываем комплексное БПФ, мнимые части заполняем нулями, получаем 2N значений
- амплитуду сигнала для каждой гармоники получаем складывая квадраты действительной и мнимой части и извлекая из суммы корень квадратный
- получаем N значений, из которых значения от 0 до (N/2-1) представляют наш спектр в области от 0 до половины частоты дискретизации, вторую половину (зеркалку) отбрасываем
- для адекватного представления пересчитываем в дБ, с учетом максимальной величины в выборке по формуле 20lg(Ai/Amax), для напряжений
- при необходимости используем различные сглаживающие окна для взвешивания входного сигнала во временной области, например Блэкмана-Харриса
- добавляем порог чувствительности (подставку)
- результаты выводим в качестве события компонента, например, используя series для подключения к TChart-у
Разбор принципов генерации и декодирования DTMF сигналов проведен в статье [6] и в данном материале рассматриваться не будет. В листинге 1 приведен полный код компонента с подробными комментариями…
…
unit DTMF;
interface
uses MMSystem, Windows, SysUtils, Messages, Classes, controls, extctrls, series, TeEngine, math;
type // тип данных wave- ind
TData16 = array [0..127] of smallint;
PData16 = ^TData16;
Type // установки для waveform
SINEWAVE = packed record
dblFrequency : Double;
dblDataSlice : Double;
dblAmplitudeL : Double;
dblVolumeF : Double;
end;
type
Twindow = (dB_0,
dB_54,
dB_67,
dB_72,
dB_92); // функции окна-
type
Tkeys = procedure(Sender:TObject; key:string; a1,a2,f1,f2: double) of object; // выдача DTMF
Tspektr = procedure(Sender:TObject; series: TbarSeries) of object; // выдача спектра
TdataOsc = procedure(Sender:TObject; series: TfastlineSeries) of object; // сырой набор данных
TDTMF=class(TComponent)
private
fabout : string;
fkey : string;
fvol : integer;
flen : integer;
fcntp : integer;
FOnKeys : TKeys;
FOnSpektr : TSpektr;
FOnDataOsc : TDataOsc;
ftimer : Ttimer;
ftimer2 : Ttimer;
tmr_en : boolean;
fwindow : twindow;
protected
procedure gen_dtmf(const Value: string); // передача строки DTMF для генерации
procedure setabout(const Value: string); // мой Copyright
procedure set_window(const Value: twindow); // выбор окна сглаживания
procedure f_cntp(const Value: integer); // установка к-ва точек БПФ
procedure wcard; // инит-деинит работы с аудио
procedure ind(Sender: TObject); // события компонента
procedure ind2(Sender: TObject); // генерация одиночного DTMF с перебором
public
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
published // внешние свойства компонента
property About : string read Fabout write setabout;
property DTMF_keys : string read Fkey write gen_dtmf;
property DTMF_volume : integer read Fvol write fvol default 100;
property DTMF_duration_ms : integer read Flen write flen default 250;
property FFT_point : integer read Fcntp write f_cntp default 2048;
property FFT_window : twindow read fwindow write set_window;
property Key : TKeys read FOnKeys write FOnKeys;
property Spektra : TSpektr read FOnSpektr write FOnSpektr;
property DataOsc : TDataOsc read FOnDataOsc write FOnDataOsc;
end;
procedure Register;
const // таблица соответствия частот DTMF
keys = ‘1234567890*#abcd’;
DTMF1: array [1..16] of integer
=(697,697,697,770,770,770,852,852,852,941,941,941,697,770,852,941);
DTMF2: array [1..16] of integer
=(1209,1336,1477,1209,1336,1477,1209,1336,1477,1336,1209,1477,1633,1633,1633,1633);
var stp: boolean = FALSE;
inwav, outwav : TfastLineSeries;
spektr : TbarSeries;
// декодер DTMF
adr2 : pWaveHdr;
BufHead1,BufHead2 : TWaveHdr;
bufsize : integer;
header : TWaveFormatEx;
hwi2 : HWAVEIN;
hBuf : THandle;
pnt : PPointArr;
f_window : smallint = 5; // тип окна – без сглаживания
fcntpp : integer = 2048; // к-во точек FFT
unit DTMF;
interface
uses MMSystem, Windows, SysUtils, Messages, Classes, controls, extctrls, series, TeEngine, math;
type // тип данных wave- ind
TData16 = array [0..127] of smallint;
PData16 = ^TData16;
Type // установки для waveform
SINEWAVE = packed record
dblFrequency : Double;
dblDataSlice : Double;
dblAmplitudeL : Double;
dblVolumeF : Double;
end;
type
Twindow = (dB_0,
dB_54,
dB_67,
dB_72,
dB_92); // функции окна-
type
Tkeys = procedure(Sender:TObject; key:string; a1,a2,f1,f2: double) of object; // выдача DTMF
Tspektr = procedure(Sender:TObject; series: TbarSeries) of object; // выдача спектра
TdataOsc = procedure(Sender:TObject; series: TfastlineSeries) of object; // сырой набор данных
TDTMF=class(TComponent)
private
fabout : string;
fkey : string;
fvol : integer;
flen : integer;
fcntp : integer;
FOnKeys : TKeys;
FOnSpektr : TSpektr;
FOnDataOsc : TDataOsc;
ftimer : Ttimer;
ftimer2 : Ttimer;
tmr_en : boolean;
fwindow : twindow;
protected
procedure gen_dtmf(const Value: string); // передача строки DTMF для генерации
procedure setabout(const Value: string); // мой Copyright
procedure set_window(const Value: twindow); // выбор окна сглаживания
procedure f_cntp(const Value: integer); // установка к-ва точек БПФ
procedure wcard; // инит-деинит работы с аудио
procedure ind(Sender: TObject); // события компонента
procedure ind2(Sender: TObject); // генерация одиночного DTMF с перебором
public
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
published // внешние свойства компонента
property About : string read Fabout write setabout;
property DTMF_keys : string read Fkey write gen_dtmf;
property DTMF_volume : integer read Fvol write fvol default 100;
property DTMF_duration_ms : integer read Flen write flen default 250;
property FFT_point : integer read Fcntp write f_cntp default 2048;
property FFT_window : twindow read fwindow write set_window;
property Key : TKeys read FOnKeys write FOnKeys;
property Spektra : TSpektr read FOnSpektr write FOnSpektr;
property DataOsc : TDataOsc read FOnDataOsc write FOnDataOsc;
end;
procedure Register;
const // таблица соответствия частот DTMF
keys = ‘1234567890*#abcd’;
DTMF1: array [1..16] of integer
=(697,697,697,770,770,770,852,852,852,941,941,941,697,770,852,941);
DTMF2: array [1..16] of integer
=(1209,1336,1477,1209,1336,1477,1209,1336,1477,1336,1209,1477,1633,1633,1633,1633);
var stp: boolean = FALSE;
inwav, outwav : TfastLineSeries;
spektr : TbarSeries;
// декодер DTMF
adr2 : pWaveHdr;
BufHead1,BufHead2 : TWaveHdr;
bufsize : integer;
header : TWaveFormatEx;
hwi2 : HWAVEIN;
hBuf : THandle;
pnt : PPointArr;
f_window : smallint = 5; // тип окна – без сглаживания
fcntpp : integer = 2048; // к-во точек FFT
signal : string; // декодированный DTMF (временная переменная)
a1,a2, // амплитуды-
f1,f2 : double; // частоты-
// кодер DTMF
waveOut : hWaveOut;
outHdr : TWaveHdr;
header2 : TWaveFormatEx;
pBuf : tHandle;
pBuffer : pointer;
Opened, lock : boolean;
gl_key : integer;
implementationSyhi-подсветка кода
Обычно, генерацию звука в памяти и воспроизведение в среде Windows осуществляют через Waveform Audio Win32 API. Нам понадобятся следующие функции:
- waveOutOpen — открывает имеющееся устройство вывода Waveform audio для сигнала
- waveOutPrepareHeader — выполняет подготовку буфера для операции вывода данных
Далее зададимся законом модуляции, форматом вывода PCM, частотой дискретизации, количеством каналов и длительностью генерации…
//——————————————————————————
// КОДЕР DTMF – генерация 2-х тонального сигнала
//——————————————————————————
procedure stopPlay;
begin
WaveOutReset(WaveOut);
WaveOutClose(WaveOut);
GlobalUnlock(pBuf);
GlobalFree(pBuf)
end;
procedure PlayBuffer(h: hwnd; SampleRate: integer; Bits: Byte; Buffer: array of byte);
var Err: integer;
begin
with header2 do begin
wFormatTag := WAVE_FORMAT_PCM;
nChannels := 1;
nSamplesPerSec := SampleRate;
wBitsPerSample := Bits;
nBlockAlign := nChannels * (wBitsPerSample div 8);
nAvgBytesPerSec := nSamplesPerSec * nBlockAlign;
cbSize := 0;
end;
if Opened = true then stopPlay;
err:= WaveOutOpen(addr(waveOut), 0, @header2,h, 0, CALLBACK_WINDOW);
if Err <> 0 then Exit;
pBuf := GlobalAlloc(GMEM_MOVEABLE and GMEM_SHARE, length(Buffer));
pBuffer := GlobalLock(pBuf);
with outHdr do begin
lpData := PBuffer;
dwBufferLength := length(Buffer);
dwUser := 0;
dwFlags := 0;
dwLoops := 0
end;
err:= WaveOutPrepareHeader(waveOut, @outHdr, sizeof(outHdr));
if Err <> 0 then Exit;
copyMemory(pBuffer, @Buffer, length(Buffer));
err:= WaveOutWrite(waveOut, @outHdr, sizeof(outHdr));
if Err <> 0 then Exit
end;
function sel_byte(lngWord: Longint; intPosition: Smallint): byte;
var lngTemp: Longint;
intByte: byte;
begin
if intPosition=3 then begin
// Byte 2
lngTemp := lngWord;
// Mask off byte and shift right 24 bits.
// Mask -> 2130706432 = &H7F000000
// Shift -> Divide by 16777216
lngTemp := Round((lngTemp and 2130706432)/16777216);
intByte := lngTemp;
end else if intPosition=2 then begin
// Byte 2
lngTemp := lngWord;
lngTemp := Round((lngTemp and 16711680)/65536);
intByte := lngTemp;
end else if intPosition=1 then begin
// Byte 1
lngTemp := lngWord;
// Mask off high byte and shift right 8 bits.
// Mask -> 65290 = &HFF00
// Shift -> Divide by 256
lngTemp := Round((lngTemp and 65290)/256);
intByte := lngTemp;
end else begin
// Byte 0
intByte := lngWord and $FF;
end;
result:= intByte
end;
procedure toneGenerate(lngSampleRate: integer; intBits: byte; dblVolume: array of double; var Freq:
array of Smallint; Seconds: Double; var FreqBuffer: variant); // создание WAVEFORM
var i, j : integer;
lngLimit, lngData : longint;
lngSamples, lngDataSize : integer;
dblDataPtL, dblWaveTime,
dblSampleTime, dblFrequency: Double;
tmpBuf : array of byte;
intSineCount : Smallint;
SineWaves : array of SINEWAVE;
begin
setLength(SineWaves, length(freq));
for i:=0 to length(freq) — 1 do begin
with SineWaves[i] do begin
dblAmplitudeL:= 0.25;
dblFrequency := freq[i]; // задаем частоты генерации WAVEFORM
dblVolumeF := dblVolume[i]
end
end;
intSineCount := length(SineWaves)-1;
for i:=0 to intSineCount do begin
dblWaveTime := 1 / SineWaves[i].dblFrequency;
dblSampleTime := 1 / lngSampleRate;
SineWaves[i].dblDataSlice := (2*Pi)/(dblWaveTime/dblSampleTime);
end;
lngSamples := round(Seconds/dblSampleTime);
lngDataSize := Round(lngSamples*(intBits/8));
SetLength(tmpBuf, lngDataSize);
if intBits=8 then lngLimit := 127
else lngLimit := 32767;
for i:=0 to lngSamples-1 do begin
if intBits=8 then begin
// ————————————————————————
// 8 Bit Data
// ————————————————————————
dblDataPtL := 0;
for j:=0 to intSineCount do
dblDataPtL := dblDataPtL +
(sin(i*SineWaves[j].dblDataSlice)*SineWaves[j].dblAmplitudeL*SineWaves[j].dblVolumeF);
lngData := round(dblDataPtL*lngLimit)+lngLimit;
tmpBuf[i] := ExtractByte(lngData, 0);
end else begin
// ————————————————————————
// 16 Bit Data
// ————————————————————————
dblDataPtL := 0;
for j:=0 to intSineCount do
dblDataPtL := dblDataPtL +
(sin(i*SineWaves[j].dblDataSlice)*SineWaves[j].dblAmplitudeL*SineWaves[j].dblVolumeF);
lngData := Round(dblDataPtL*lngLimit);
tmpbuf[2*i] := sel_byte(lngData, 0);
tmpbuf[(2*i)+1] := sel_byte (lngData, 1);
end
end;
FreqBuffer:= tmpBuf
end;
procedure tdtmf.gen_dtmf(const Value: string); // передача строки DTMF для генерации-
begin
fkey:= value;
if fkey<>» then tmr_en:= true // запрещаем генерацию, если пусто
end;
procedure TDTMF.ind2(Sender: TObject); // генерация одиночного DTMF с перебором-
var Freq: array [0..1] of smallint;
Buffer:array of byte;
dblVolume: array [0..1] of double;
SoundBuffer: variant;
i: integer;
begin
if tmr_en then begin
inc(gl_key);
if gl_key > length(fkey) then begin
gl_key:= 0;
tmr_en:= false; // если перебрали все введенные символы – останов генерации
fkey:= »
end else for i:= 1 to length(keys) do
if keys[i]= lowercase(fkey[gl_key]) then begin
Freq[0]:= dtmf1[i]; // задаем частоты-
Freq[1]:= dtmf2[i];
dblVolume[0]:= fvol / 100; // задаем уровень громкости-
dblVolume[1]:= fvol / 100;
toneGenerate(22050, 8, dblVolume, Freq, flen/1000, SoundBuffer); // создание WAVEFORM-
buffer:= SoundBuffer;
PlayBuffer(0,22050, 8, Buffer) // воспроизведение-
end
end
end;
// END DTMF KODER ————————————————————-Syhi-подсветка кода
// КОДЕР DTMF – генерация 2-х тонального сигнала
//——————————————————————————
procedure stopPlay;
begin
WaveOutReset(WaveOut);
WaveOutClose(WaveOut);
GlobalUnlock(pBuf);
GlobalFree(pBuf)
end;
procedure PlayBuffer(h: hwnd; SampleRate: integer; Bits: Byte; Buffer: array of byte);
var Err: integer;
begin
with header2 do begin
wFormatTag := WAVE_FORMAT_PCM;
nChannels := 1;
nSamplesPerSec := SampleRate;
wBitsPerSample := Bits;
nBlockAlign := nChannels * (wBitsPerSample div 8);
nAvgBytesPerSec := nSamplesPerSec * nBlockAlign;
cbSize := 0;
end;
if Opened = true then stopPlay;
err:= WaveOutOpen(addr(waveOut), 0, @header2,h, 0, CALLBACK_WINDOW);
if Err <> 0 then Exit;
pBuf := GlobalAlloc(GMEM_MOVEABLE and GMEM_SHARE, length(Buffer));
pBuffer := GlobalLock(pBuf);
with outHdr do begin
lpData := PBuffer;
dwBufferLength := length(Buffer);
dwUser := 0;
dwFlags := 0;
dwLoops := 0
end;
err:= WaveOutPrepareHeader(waveOut, @outHdr, sizeof(outHdr));
if Err <> 0 then Exit;
copyMemory(pBuffer, @Buffer, length(Buffer));
err:= WaveOutWrite(waveOut, @outHdr, sizeof(outHdr));
if Err <> 0 then Exit
end;
function sel_byte(lngWord: Longint; intPosition: Smallint): byte;
var lngTemp: Longint;
intByte: byte;
begin
if intPosition=3 then begin
// Byte 2
lngTemp := lngWord;
// Mask off byte and shift right 24 bits.
// Mask -> 2130706432 = &H7F000000
// Shift -> Divide by 16777216
lngTemp := Round((lngTemp and 2130706432)/16777216);
intByte := lngTemp;
end else if intPosition=2 then begin
// Byte 2
lngTemp := lngWord;
lngTemp := Round((lngTemp and 16711680)/65536);
intByte := lngTemp;
end else if intPosition=1 then begin
// Byte 1
lngTemp := lngWord;
// Mask off high byte and shift right 8 bits.
// Mask -> 65290 = &HFF00
// Shift -> Divide by 256
lngTemp := Round((lngTemp and 65290)/256);
intByte := lngTemp;
end else begin
// Byte 0
intByte := lngWord and $FF;
end;
result:= intByte
end;
procedure toneGenerate(lngSampleRate: integer; intBits: byte; dblVolume: array of double; var Freq:
array of Smallint; Seconds: Double; var FreqBuffer: variant); // создание WAVEFORM
var i, j : integer;
lngLimit, lngData : longint;
lngSamples, lngDataSize : integer;
dblDataPtL, dblWaveTime,
dblSampleTime, dblFrequency: Double;
tmpBuf : array of byte;
intSineCount : Smallint;
SineWaves : array of SINEWAVE;
begin
setLength(SineWaves, length(freq));
for i:=0 to length(freq) — 1 do begin
with SineWaves[i] do begin
dblAmplitudeL:= 0.25;
dblFrequency := freq[i]; // задаем частоты генерации WAVEFORM
dblVolumeF := dblVolume[i]
end
end;
intSineCount := length(SineWaves)-1;
for i:=0 to intSineCount do begin
dblWaveTime := 1 / SineWaves[i].dblFrequency;
dblSampleTime := 1 / lngSampleRate;
SineWaves[i].dblDataSlice := (2*Pi)/(dblWaveTime/dblSampleTime);
end;
lngSamples := round(Seconds/dblSampleTime);
lngDataSize := Round(lngSamples*(intBits/8));
SetLength(tmpBuf, lngDataSize);
if intBits=8 then lngLimit := 127
else lngLimit := 32767;
for i:=0 to lngSamples-1 do begin
if intBits=8 then begin
// ————————————————————————
// 8 Bit Data
// ————————————————————————
dblDataPtL := 0;
for j:=0 to intSineCount do
dblDataPtL := dblDataPtL +
(sin(i*SineWaves[j].dblDataSlice)*SineWaves[j].dblAmplitudeL*SineWaves[j].dblVolumeF);
lngData := round(dblDataPtL*lngLimit)+lngLimit;
tmpBuf[i] := ExtractByte(lngData, 0);
end else begin
// ————————————————————————
// 16 Bit Data
// ————————————————————————
dblDataPtL := 0;
for j:=0 to intSineCount do
dblDataPtL := dblDataPtL +
(sin(i*SineWaves[j].dblDataSlice)*SineWaves[j].dblAmplitudeL*SineWaves[j].dblVolumeF);
lngData := Round(dblDataPtL*lngLimit);
tmpbuf[2*i] := sel_byte(lngData, 0);
tmpbuf[(2*i)+1] := sel_byte (lngData, 1);
end
end;
FreqBuffer:= tmpBuf
end;
procedure tdtmf.gen_dtmf(const Value: string); // передача строки DTMF для генерации-
begin
fkey:= value;
if fkey<>» then tmr_en:= true // запрещаем генерацию, если пусто
end;
procedure TDTMF.ind2(Sender: TObject); // генерация одиночного DTMF с перебором-
var Freq: array [0..1] of smallint;
Buffer:array of byte;
dblVolume: array [0..1] of double;
SoundBuffer: variant;
i: integer;
begin
if tmr_en then begin
inc(gl_key);
if gl_key > length(fkey) then begin
gl_key:= 0;
tmr_en:= false; // если перебрали все введенные символы – останов генерации
fkey:= »
end else for i:= 1 to length(keys) do
if keys[i]= lowercase(fkey[gl_key]) then begin
Freq[0]:= dtmf1[i]; // задаем частоты-
Freq[1]:= dtmf2[i];
dblVolume[0]:= fvol / 100; // задаем уровень громкости-
dblVolume[1]:= fvol / 100;
toneGenerate(22050, 8, dblVolume, Freq, flen/1000, SoundBuffer); // создание WAVEFORM-
buffer:= SoundBuffer;
PlayBuffer(0,22050, 8, Buffer) // воспроизведение-
end
end
end;
// END DTMF KODER ————————————————————-Syhi-подсветка кода
Как быть с обработкой в реальном времени? Воспользуемся API функцией WaveInOpen, чтобы получить доступ к текущему аудиоустройству. Также заведем два буфера BufHead1 и BufHead2, один для накопления, второй для получения данных. Размер буфера определим в 3000 отсчетов, т.к. нам не требуется высокое разрешение по частоте, допустимую погрешность при определении DTMF будем задавать доверительным интервалом по частоте. Частоту дискретизации зададим типичную (максимальную) для большинства аудиокарт в 44100 Гц, 16 бит на канал. После чего, передадим полученный набор данных в нашу процедуру БПФ и строим спектр как обычно. Причем, заметьте, основное время тратится не на обработку данных и БПФ, а на набивку в series. Поэтому, если вам дорого время и вы хотите максимально увеличить размер буфера для повышения разрешения по частоте, то придется отказаться от удобства использования TChart (именно этим обусловлено использование series)…
//————————————————————————————
// ДЕКОДЕР DTMF + СПЕКТРОАНАЛИЗ
//————————————————————————————
function FFT(var x, y:array of double;var nn:integer;nf, ii: integer): integer;
var c,s,t1,t2,t3,t4,u1,u2,u3,z,a0,a1,a2,a3,w:double; // функции окна-
i,j,p,rt,l,ll,m,m1,k:integer;
begin
rt:= 1;
nn:= nn div 2;
while rt<nn do
rt:=rt*2;
nn:= rt;
z:= 2*pi/nn;
// выбор окна подавления
…
a0:=1; // без изменений
a1:=0;
a2:=0;
a3:=0;
for i:=0 to nn-1 do begin
w:=a0-a1*cos(z*i)+a2*cos(z*2*i)+a3*cos(z*3*i);
x[i]:=x[i]*w;
y[i]:=y[i]*w;
end;
//——————————————-
ll:= nn;
M := nn div 2;
M1:= Nn-1;
while ll>=2 do begin
l:=ll div 2;
u1:=1;
u2:=0;
t1:=PI/l;
c:=cos(t1);
s:=(-1)*ii*sin(t1);
for j:=0 to l-1 do
begin
i:=j;
while i<nn do
begin
p:=i+l;
t1:=x[i]+x[p];
t2:=y[i]+y[p];
t3:=x[i]-x[p];
t4:=y[i]-y[p];
x[p]:=t3*u1-t4*u2;
y[p]:=t4*u1+t3*u2;
x[i]:=t1;
y[i]:=t2;
i:=i+ll;
end;
u3:=u1*c-u2*s;
u2:=u2*c+u1*s;
u1:=u3;
end;
ll:=ll div 2
end;
j:=0;
for i:=0 to m1-1 do begin
if i>j then begin
t1:=x[j];
t2:=y[j];
x[j]:=x[i];
y[j]:=y[i];
x[i]:=t1;
y[i]:=t2;
end;
k:=m;
while j>=k do begin
j:=j-k;
k:=k div 2;
end;
j:=j+k;
end
end;
// ДЕКОДЕР DTMF + СПЕКТРОАНАЛИЗ
//————————————————————————————
function FFT(var x, y:array of double;var nn:integer;nf, ii: integer): integer;
var c,s,t1,t2,t3,t4,u1,u2,u3,z,a0,a1,a2,a3,w:double; // функции окна-
i,j,p,rt,l,ll,m,m1,k:integer;
begin
rt:= 1;
nn:= nn div 2;
while rt<nn do
rt:=rt*2;
nn:= rt;
z:= 2*pi/nn;
// выбор окна подавления
…
a0:=1; // без изменений
a1:=0;
a2:=0;
a3:=0;
for i:=0 to nn-1 do begin
w:=a0-a1*cos(z*i)+a2*cos(z*2*i)+a3*cos(z*3*i);
x[i]:=x[i]*w;
y[i]:=y[i]*w;
end;
//——————————————-
ll:= nn;
M := nn div 2;
M1:= Nn-1;
while ll>=2 do begin
l:=ll div 2;
u1:=1;
u2:=0;
t1:=PI/l;
c:=cos(t1);
s:=(-1)*ii*sin(t1);
for j:=0 to l-1 do
begin
i:=j;
while i<nn do
begin
p:=i+l;
t1:=x[i]+x[p];
t2:=y[i]+y[p];
t3:=x[i]-x[p];
t4:=y[i]-y[p];
x[p]:=t3*u1-t4*u2;
y[p]:=t4*u1+t3*u2;
x[i]:=t1;
y[i]:=t2;
i:=i+ll;
end;
u3:=u1*c-u2*s;
u2:=u2*c+u1*s;
u1:=u3;
end;
ll:=ll div 2
end;
j:=0;
for i:=0 to m1-1 do begin
if i>j then begin
t1:=x[j];
t2:=y[j];
x[j]:=x[i];
y[j]:=y[i];
x[i]:=t1;
y[i]:=t2;
end;
k:=m;
while j>=k do begin
j:=j-k;
k:=k div 2;
end;
j:=j+k;
end
end;
procedure FFTQuad(seriesin,seriesout: TChartSeries; max:integer); // max- точечное БПФ
var a,b : array of double;
i,k : integer;
d : real;
begin
i:=0;
if Seriesin.yValues.count = 0 then exit;
k:= Seriesin.YValues.Count;
while (k>1) and (power(2, i)<max) do
begin
k:=k div 2;
inc(i)
end;
k:= ceil(power(2, i));
SetLength(a,k); // инициализируем массив Re, Im
SetLength(b,k);
for i:=0 to k-1 do
begin
a[i]:= Seriesin.YValue[i];
b[i]:= 0
end;
FFT(a, b, k, f_window, 1); // домножаем на выбранное окно, получение спектра
for i:=0 to k div 2-1 do begin // отсекаем зеркалку
d:= sqrt(a[i]*a[i] + b[i]*b[i]); // получаем модуль из Re и Im
d:= 20*log10(d/k + 0.000001) -25; // приведение к дБ и нормирование
// -25дб это подставка, чтоб убрать фоновые шумы
// по спецификации ITU-T для DTMF
// уровень шума (SNR) на уровне 15 дБ
seriesout.Add(d)
end
end;
// получение аудиоданных и построение спектра —————————————————-
procedure waveInProc2(hwi: HWAVEIN; uMsg,dwInstance,dwParam1,dwParam2: DWORD);stdcall;
var i : integer;
data16 : PData16;
temp : pWaveHdr;
a,f,cntval : double;
begin
if (uMsg=WIM_DATA) and (stp) then begin
temp:= adr2;
if adr2= @bufhead1 then adr2:= @bufhead2 // получаем указатель на данные с буфера 1/2
else adr2:= @bufhead1;
//
if stp then WaveInAddBuffer(hwi,adr2,SizeOf(TWaveHdr));
data16:= PData16(temp.lpData); // собственно сами данные
if (not lock) then try inwav.Clear; outwav.Clear; spektr.Clear; // подчищаем
for i := 0 to BufSize — 1 do begin // набиваем из аудиобуфера-
inwav.add(data16^[i])
end;
// ПОЛУЧЕНИЕ СПЕКТРА —
FFTQuad(inwav, outwav, fcntpp);
// обработка спектра и 2-x проходный поиск —
a1:= -1000;
cntval:= header.nSamplesPerSec / outwav.YValues.Count;
for i:= 0 to (outwav.YValues.Count)-1 do begin
a:= outwav.YValues[i];
f:= i * cntval; // получение истинной частоты гармоники
if a>=0 then spektr.AddXY(f,a)
else spektr.AddXY(f,0); // отсекаем отрицательные амплитуды
if a > a1 then begin a1:= a; f1:= f end // частота для max 1- гармоники
end;
a2:= -1000;
for i:= (outwav.YValues.Count)-1 downto 0 do begin
a:= outwav.YValues[i];
f:= i * cntval;
if (a > a2) and (a<>a1) then begin a2:= a; f2:= f end // частота для max 2- гармоники
end;
// ———————————————————————————————————
// ИДЕНТИФИКАЦИЯ DTMF
// ———————————————————————————————————
// по спецификации ITU-T на DTMF доверительный интервал должен быть не более 1.5%,
// но мы зададимся чуть больше, чтобы учесть разброс характеристик и небольшое заданное
// разрешение анализатора спектра по частоте (размер буфера 3000, см. выше)
signal:= »;
for i:= 1 to 16 do begin
if (DTMF2[i]*0.96<f1) and (DTMF2[i]*1.04>f1) and // 1 амплитуда >2
(DTMF1[i]*0.96<f2) and (DTMF1[i]*1.04>f2) then begin
signal:= keys[i];
break
end;
if (DTMF1[i]*0.96<f1) and (DTMF1[i]*1.04>f1) and // 1 амплитуда >2
(DTMF2[i]*0.96<f2) and (DTMF2[i]*1.04>f2) then begin
signal:= keys[i];
break
end;
end;
spektr.Title:= ‘DTMF(‘+ signal +‘): ‘ +
format(‘A1= %.2n’,[a1])+ formatfloat(‘ [0 Hz] ‘, f1) +
format(‘A2= %.2n’,[a2])+ formatfloat(‘ [0 Hz]’, f2);
except end
end else Exit
end;
//————————————————————————————————————
// инициализация-деинициализация получения аудио-данных
procedure TDTMF.wcard;
const rbuf = 6;
var BufLen : word;
buf : pointer;
begin
stp:= not stp;
try
if stp then begin // старт
BufSize:= rbuf *500;
with header do begin
wFormatTag:= WAVE_FORMAT_PCM;
nChannels := 2; // каналов
nSamplesPerSec:= 44100; // дискретизация, Гц
wBitsPerSample:= 16; // бит
nBlockAlign:= nChannels * (wBitsPerSample div 8);
nAvgBytesPerSec:= nSamplesPerSec * nBlockAlign;
cbSize:= 0;
end;
WaveInOpen(Addr(hwi2), WAVE_MAPPER, addr(header),integer(@waveInProc2),
0,CALLBACK_FUNCTION);
BufLen:= header.nBlockAlign * BufSize;
hBuf:= GlobalAlloc(GMEM_MOVEABLE and GMEM_SHARE, BufLen);
Buf:= GlobalLock(hBuf);
with BufHead1 do begin
lpData:= Buf;
dwBufferLength:= BufLen;
dwFlags:= 0;
end;
with BufHead2 do begin
lpData:= Buf;
dwBufferLength:= BufLen;
dwFlags:= 0;
end;
adr2:= @BufHead1;
waveInPrepareHeader(hwi2, Addr(BufHead1), sizeof(BufHead1));
waveInPrepareHeader(hwi2, Addr(BufHead2), sizeof(BufHead2));
WaveInAddBuffer(hwi2, addr(BufHead1), sizeof(BufHead1));
WaveInStart(hwi2)
end else begin // стоп
WaveInReset(hwi2);
WaveInUnPrepareHeader(hwi2, addr(BufHead1), sizeof(BufHead1));
WaveInClose(hwi2);
GlobalUnlock(hBuf); GlobalFree(hBuf);
end
//
except end
end;
//————————————————————————————————————
// СОБЫТИЯ КОМПОНЕНТА
//————————————————————————————————————
// в принципе содержимое можно перенести в процедуру waveInProc2(), но хотелось гибкости
//————————————————————————————————————
procedure TDTMF.ind(Sender: TObject);
begin
lock:= true; // блокируем очистку, БПФ и декодирование DTMF на время выдачи
inwav.SeriesColor := rgb(0,0,255); // синий цвет серии
spektr.SeriesColor:= rgb(255,0,0); // красный-
if Assigned(FOnSpektr) then FOnSpektr(self, spektr); // спектр
if Assigned(FOnDataOsc) then FOnDataOsc(self,inwav); // сырые данные (осциллограф)
if signal<>» then
if Assigned(FOnKeys) then FOnKeys(self, signal, a1, a2, f1, f2); // декодированный DTMF
lock:= false
end;
//————————————————————————————————————
// СЕРВИС-МОДУЛЬ (СКЕЛЕТ)
//————————————————————————————————————
constructor TDTMF.Create(AOwner: TComponent);
begin
inherited Create(aowner);
fvol := 100;
flen := 250;
Fcntp := fcntpp; // устанавливаем по умолчанию 2048 точек БПФ
fwindow:= dB_0;
Fabout := ‘Badlo Sergey’;
Inwav := tfastlineseries.Create(nil);
Outwav := tfastlineseries.Create(nil);
Spektr := tbarseries.Create(nil); // визуально удобнее-
spektr.Marks.Visible:= false;
ftimer:= ttimer.Create(self);
ftimer.Enabled := false;
ftimer.interval := 200;
ftimer.ontimer := ind;
ftimer.Enabled := true;
//
ftimer2:= ttimer.Create(self);
ftimer2.Enabled := false;
ftimer2.interval := 350;
ftimer2.ontimer := ind2;
ftimer2.Enabled := true;
wcard // инициализация получения аудиоданных
end;
destructor TDTMF.Destroy;
begin
stopplay; // запрещаем генерацию DTMF
wcard; // деинициализация аудио
ftimer.Free; ftimer2.Free;
inwav.Free; outwav.Free; spektr.Free;
inherited
end;
procedure TDTMF.f_cntp(const Value: integer);
begin
fcntp:= value; fcntpp:= value
end;
procedure TDTMF.set_window(const Value: twindow); // выбираем окно сглаживания-
begin
fwindow:= value;
case value of
dB_0 : f_window:= 5; // без сглаживания
…
end
end;
procedure TDTMF.setabout(const Value: string);
begin
fabout:= ‘Badlo Sergey’
end;
//============================================================
procedure Register;
begin
RegisterComponents(‘RAMEDIA’, [TDTMF])
end;
end.Syhi-подсветка кода
Осталось проверить работоспособность нашего модуля. Для этого (см. рисунки 5-7):
Рис. 5. Инсталлируем компонент
Выбрав в меню «Component/Install Component», проинсталлируем компонент DTMF (модуль <dtmf.pas>). Создав новый проект «File/New Application», перенесем наш компонент на форму. После чего, станут доступными его свойства и методы (см. рис.6). Также нам понадобится TChart (визуализация), TMemo (декодированные посылки) и TEdit (строка ввода команд генерации) (см. рисунок 7). Теперь напишем следующий код в событиях компонента (см. листинг 2):
Рис. 6. Задаем параметры

Рис. 7. События компонента
тестовый модуль
…
procedure TForm1.DTMF1Key(Sender: TObject; key: String; a1, a2, f1,
f2: Double);
var s: string;
begin
CAPTION:= ‘ Тестовый спектроанализатор. Декодер-кодер DTMF (‘ + key + ‘)’;
s:= key +
format(‘ — A1= %.2n’,[a1])+ formatfloat(‘ [0 Hz] ‘,f1) +
format(‘A2= %.2n’,[a2])+ formatfloat(‘ [0 Hz]’,f2);
memo1.Lines.add(s);
chart1.Title.Text[0]:= ‘Декодирован ‘ +s
end;
procedure TForm1.Edit1KeyPress(Sender: TObject; var Key: Char);
begin
if key=#13 then dtmf1.DTMF_keys:= edit1.Text
end;
procedure TForm1.DTMF1Spektra(Sender: TObject; series: TBarSeries);
begin
series1.Assign(series)
end;Syhi-подсветка кода
…
procedure TForm1.DTMF1Key(Sender: TObject; key: String; a1, a2, f1,
f2: Double);
var s: string;
begin
CAPTION:= ‘ Тестовый спектроанализатор. Декодер-кодер DTMF (‘ + key + ‘)’;
s:= key +
format(‘ — A1= %.2n’,[a1])+ formatfloat(‘ [0 Hz] ‘,f1) +
format(‘A2= %.2n’,[a2])+ formatfloat(‘ [0 Hz]’,f2);
memo1.Lines.add(s);
chart1.Title.Text[0]:= ‘Декодирован ‘ +s
end;
procedure TForm1.Edit1KeyPress(Sender: TObject; var Key: Char);
begin
if key=#13 then dtmf1.DTMF_keys:= edit1.Text
end;
procedure TForm1.DTMF1Spektra(Sender: TObject; series: TBarSeries);
begin
series1.Assign(series)
end;Syhi-подсветка кода
После чего, запустив проект на компиляцию, введем строку для генерации. Нажав ENTER можем наблюдать спектр сигнала и декодированные посылки (см. рисунок 8):
Рис. 8. Окно тестового модуля спектроанализатора-кодера-декодера DTMF
Данная методика, с добавлением анализатора файлов WAV/MP3, была использована при разработке многофункционального ПО «SPEKTRA» [7, 8] (см. рисунок 9). Следует обратить ваше внимание, что разработанный декодер DTMF не полностью соответствует всем требованиям ITU-T, т.к. не учтен анализ вторичных гармоник, например при речевом сигнале. Что это означает? Как вы наверняка знаете, человеческая речь и речь вообще, музыка характеризуются большим количеством гармоник, а сам DTMF сигнал обладает низким уровнем его вторичных гармоник. Поэтому для избежания ложного детектирования DTMF сигнала, необходимо добавить оценку этого уровня и сравнивать его с уровнями определенных частот в спектре для речи и музыки. Эти характерные частоты (форманты)** для речи в принципе известны, например характерный мужской бас сосредоточен в области 200-250 Гц и женский голос ближе к 500-700 Гц.
Но это уже тема для отдельной статьи…

Рис. 9. Отсчеты и спектр сигнала DTMF. Буква «A»
Заключение
Полные исходные тексты компонента спектроанализатора-кодера-декодера DTMF и ресурсы тестового проекта приведены в виде ресурсов в теме «Журнал клуба программистов. Восьмой выпуск» или непосредственно в архиве с журналом.
Ресурсы
- AVR314: Двутональный DTMF генератор http://www.gaw.ru/html.cgi/txt/app/micros/avr/index.htm
- MSP430: DTMF-Controlled http://www.gaw.ru/html.cgi/txt/app/micros/msp430/index.htm
- Practical Design Techniques for Sensor Signal Conditioning, Analog Devices, 1998
- DTMF Detector Data Sheet, 2001 http://www.miketdspsolutions.com/dtmf.pdf
- Рабинер Л., Гоулд Б. Теория и применение цифровой обработки сигналов. – М., Мир, 1978
- Л.А.Осипов. Обработка сигналов на цифровых процессорах. Линейно-аппроксимирующий метод. – М., Горячая линия — Телеком, 2001
- Е.Бадло, С.Бадло. Виртуальные приборы. Спектроанализатор своими руками. – Радиолюбитель, Минск, 2009, №3, с.32-36 http://raxp.radioliga.com/cnt/s.php?p=v3.pdf или
- Ресурсы анализатора спектра файлов и сигналов DTMF-FFT http://raxp.radioliga.com/cnt/s.php?p=dtmf_res.zip
- Ресурсы компонента спектроанализатора-кодера-декодера DTMF http://raxp.radioliga.com/cnt/s.php?p=fft.zip
Статья из восьмого выпуска журнала «ПРОграммист».
23rd
Работа с NetLink в Linux. Часть 1
И вновь, после вынужденного долгого перерыва приветствую уважаемых читателей нашего журнала. За время этого перерыва накопилось достаточно много интересных материалов, которые я постараюсь осветить в новых статьях. Начну с этой. Надеюсь, что эта информация кому-то поможет и пригодится, как, в свое время, помогла мне. В прошлой статье я рассказал о системном вызове IOCTL и обещал рассказать о Netlink. Пришло время выполнять обещание К сожалению, невозможно изложить все в рамках одной журнальной статьи. Поэтому материал я разбил на несколько частей. Настоящая статья – первая часть.
Олег Кутков
by Oleg Kutkov elenbert@gmail.com
Итак, Netlink представляет из себя особый компонент Linux ядра. С ним можно общаться через обычный сокет передавая и принимая сообщения, сформированные особым образом. Что же дает нам netlink?
С помощью Netlink мы можем:
- получать уведомления об изменении сетевых интерфейсов (название изменившегося интерфейса и что именно произошло), таблиц маршрутизации, файрволла;
- управлять всеми таблицами маршрутизации;
- управлять параметрами сетевых интерфейсов;
- управлять параметрами файрволла;
- управлять arp таблицей;
- реализовать взаимодействие со своим модулем в ядре.
Кроме этого Netlink позволяет нам отказаться от устаревшего вызова ioctl, упростить и унифицировать код, так как все операции выполняются посредством стандартного сокета. Гарантируется быстрая работа кода и его общая надежность. Именно Netlink использует мощная утилита администрирования iproute2, пришедшая на смену утилитам ifconfig, route и другие.
К сожалению о Netlink очень мало материалов как на русском языке, так и на английском. Пожалуй, наиболее ценным источником можно считать две статьи в Linux journal и Doxygen- документацию. В этой статье я постараюсь приподнять завесу тайны и рассказать как можно больше.
Архитектура Netlink
Как уже говорилось выше, Netlink – это особый компонент ядра, с которым пользователь может общаться посредством обычных сокетов. Для работы с netlink существует особое семейство протоколов – AF_NETLINK, его необходимо указывать при создании нового сокета. Тип сокета следует выбирать SOCK_RAW или SOCK_DGRAM, для протокола, в данном случае, нет разницы. Как можно догадаться, протокол netlinka является диаграммным и не гарантирует доставку сообщений, хоть и старается это сделать всеми доступными средствами.
Каждое сообщение netlink представляет собой поток байт, содержащий один или несколько заголовков, представленных структурой nlmsghdr, а так же связанных с ними данными, которые называются «полезной нагрузкой» (playload). Сообщение, во время доставки, может быть разбито на несколько частей. В таких случаях каждый следующий пакет помечается флагом NLM_F_MULTI, а последний флагом NLMSG_DONE. Для разбора сообщений имеется целый набор макросов, определенный в заголовочном файле netlink.h. Там же определено все прочее, связанное с Netlink.
Надо сказать, что существует отдельная библиотека для работы с netlink – libnl. Она реализует особый уровень абстракции над netlink сокетами и предоставляет множество методов. Лично мне она не очень нравится, т.к. немного имеет немного запутанный и плохо документированный API, который любит часто меняться, что требует изменений и в приложениях, использующих эту библиотеку. Я один раз напоролся на такой сюрприз, поэтому мы не будет рассматривать эту библиотеку, а реализуем весь протокол сами, увидите, это не очень сложно.
Создание сокета netlink
Объявление netlink сокета выглядит так:
socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE)
Где:
AF_NETLINK – протокол Netlink,
SOCK_RAW – тип сокета,
NETLINK_ROUTE – семейство Netlink протокола
Последний параметр может быть различным, в зависимости от того, что мы именно хотим получить от Netlink.
Приведу таблицу со наиболее интересными параметрами (полный список параметров можно посмотреть в документации):
- NETLINK_ROUTE – получать уведомления об изменениях таблицы маршрутизации и сетевых интерфейсов (так же может использоваться для изменения всех параметров вышеперечисленных объектов).
- NETLINK_USERSOCK – зарезервировано для определения пользовательских протоколов.
- NETLINK_FIREWALL – служит для передачи IPv4 пакетов из сетевого фильтра на пользовательский уровень
- NETLINK_INET_DIAG – мониторинг inet сокетов
- NETLINK_NFLOG – ULOG сетевого/пакетного фильтра
- NETLINK_SELINUX – получать уведомления от системы Selinux
- NETLINK_NETFILTER – работа с подсистемой сетевого фильтра
- NETLINK_KOBJECT_UEVENT – получение сообщений ядра
Далее созданные сокет можно использовать для отправки сообщений, с помощью стандартной функции send и приема сообщений с помощью recvmsg.
Сообщения Netlink
Как уже выше сообщалось – каждое netlink сообщение представлено одним или несколькими заголовками, за которыми следуют полезные данные. Заголовок сообщения представлен структурой nlmsghdr:
struct nlmsghdr
{
__u32 nlmsg_len; // размер сообщения, с учетом заголовка
__u16 nlmsg_type; // тип содержимого сообщения (об этом ниже)
__u16 nlmsg_flags; // различные флаги сообщения
__u32 nlmsg_seq; // порядковый номер сообщения
__u32 nlmsg_pid; // идентификатор процесса (PID), отославшего сообщение
};Syhi-подсветка кода
{
__u32 nlmsg_len; // размер сообщения, с учетом заголовка
__u16 nlmsg_type; // тип содержимого сообщения (об этом ниже)
__u16 nlmsg_flags; // различные флаги сообщения
__u32 nlmsg_seq; // порядковый номер сообщения
__u32 nlmsg_pid; // идентификатор процесса (PID), отославшего сообщение
};Syhi-подсветка кода
Поле nlmsg_type может указывать на один из стандартных типов сообщений:
NLMSG_NOOP – сообщения такого типа игнорируются.
NLMSG_ERROR – сообщение с ошибкой, и в секции полезных данных будет структура nlmsgerr (о ней чуть ниже)
NLMSG_DONE – сообщение с этим флагом должно завершать сообщение, разбитое на несколько частей
Структура nlmsgerr:
struct nlmsgerr
{
int error; // отрицательное значение кода ошибки
struct nlmsghdr msg; // заголовок сообщения, связанного с ошибкой
};Syhi-подсветка кода
{
int error; // отрицательное значение кода ошибки
struct nlmsghdr msg; // заголовок сообщения, связанного с ошибкой
};Syhi-подсветка кода
Сообщения могут быть одного или нескольких (различные типы объеденяются с помощью операции логического или – |) типов:
- NLM_F_REQUEST – сообщение – запрос чего либо
- NLM_F_MULTI – сообщение, часть сообщения разбитого на части
- NLM_F_ACK – сообщение – запрос подтверждения
- NLM_F_ECHO – эхо запрос. обычное направление – запросы из уровня ядра на пользовательский уровень
- NLM_F_ROOT – данный тип запроса возвращает некую таблицу, внутри некой сущности
- NLM_F_MATCH – запрос возвращает все найденные соответствия
- NLM_F_ATOMIC – возвращает атомарный срез некой таблицы
- NLM_F_DUMP – аналог NLM_F_ROOT|NLM_F_MATCH
Дополнительные флаги:
- NLM_F_REPLACE – заменить существующий аналогичный объект
- NLM_F_EXCL – не заменять, если такой объект уже существует
- NLM_F_CREATE – создать объект, если он не существует
- NLM_F_APPEND – добавить объект в список к уже существующему
Для идентификации клиентов (на уровне ядра и на пользовательском уровне) существует специальная адресная структура – nladdr:
struct sockaddr_nl
{
sa_family_t nl_family; // семейство протоколов – всегда AF_NETLINK
unsigned short nl_pad; // поле всегда заполнено нулями
pid_t nl_pid; // идентификатор процесса
__u32 nl_groups; // маска групп получателей/отправителей
};Syhi-подсветка кода
{
sa_family_t nl_family; // семейство протоколов – всегда AF_NETLINK
unsigned short nl_pad; // поле всегда заполнено нулями
pid_t nl_pid; // идентификатор процесса
__u32 nl_groups; // маска групп получателей/отправителей
};Syhi-подсветка кода
nl_pid – это уникальный адрес сокета. Для клиентов в ядре он всегда равен нулю. Для клиентов на пользовательском уровне он равен идентификатору процесса, владеющего сокетом. Каждый идентификатор должен быть уникальным, поэтому тут вы можете натолкнутся на проблему, когда попытаетесь создать несколько netlink сокетов в многопоточном приложении: при создании нового сокета будет возвращаться ошибка «Operation not permitted».
Для обхода данного ограничения следуют nl_pid присваивать значение данного выражения:
pthread_self() << 16 | getpid();
Присваивать значение идентификатора следует до того, как будет вызван bind() для сокета.
Так же идентификатору можно присвоить нулевое значение. В этом случае генерацией уникальных идентификаторов будет заниматься ядро, но первому сокету созданному в приложение всегда будет присваиваться значение идентификатора данного приложения.
nl_groups – это битовая маска, каждый бит которой представляет номер группы netlink. При вызове bind() для сокета netlink следует указывать битовую маску группы, которую желает прослушивать приложение, в данном контексте. Различные группы могут быть объединены с помощью логического или – |
Основные группы определены в заголовочном файле netlink. Пример некоторых из них:
- RTMGRP_LINK – эта группа получает уведомления об изменениях в сетевых интерфейсах (интерфейс удалился, добавился, опустился, поднялся)
- RTMGRP_IPV4_IFADDR – эта группа получает уведомления об изменениях в IPv4 адресах интерфейсов (адрес был добавлен или удален)
- RTMGRP_IPV6_IFADDR – эта группа получает уведомления об изменениях в IPv6 адресах интерфейсов (адрес был добавлен или удален)
- RTMGRP_IPV4_ROUTE – эта группа получает уведомления об изменениях в таблице маршрутизации для IPv4 адресов
- RTMGRP_IPV6_ROUTE – эта группа получает уведомления об изменениях в таблице маршрутизации для IPv6 адресов
После структуры заголовка nlmsghdr всегда расположен указатель на блок данных. Доступ к нему можно получить с помощью макросов, о которых будет рассказано далее.
Макросы Netlink
- NLMSG_ALIGN – округляет размер сообщения netlink до ближайшего большего значения, выровненного по границе.
- NLMSG_LENGTH – принимает в качестве параметра размер поля данных (payload) и возвращает выровненное по границе значение размера для записи в поле nlmsg_len заголовка nlmsghdr.
- NLMSG_SPACE – возвращает размер, который займут данные указанной длины в пакете netlink.
- NLMSG_DATA – возвращает указатель на данные, связанные с переданным заголовком nlmsghdr.
- NLMSG_NEXT – возвращает следующую часть сообщения, состоящего из множества частей. Макрос принимает следующий заголовок nlmsghdr в сообщении, состоящем из множества частей. Вызывающее приложение должно проверить наличие в текущем заголовке nlmsghdr флага.
- NLMSG_DONE – функция не возвращает значение NULL при завершении обработки сообщения. Второй параметр задает размер оставшейся части буфера сообщения. Макрос уменьшает это значение на размер заголовка сообщения.
- NLMSG_OK – возвращает значение TRUE (1), если сообщение не было усечено и его разборка прошла успешно.
- NLMSG_PAYLOAD – возвращает размер данных (payload), связанных с заголовком nlmsghdr.
От теории к практике
Ну что же. Думаю, что я достаточно помучал Вас теорией Может быть что-то показалось запутанным или не понятным – постараюсь разжевать все в наглядных примерах, там на самом деле нет ничего сложного.
Итак, давайте-ка напишем небольшое приложение, которое будет получать уведомления об изменениях в сетевых интерфейсах и таблице маршрутизации! Ниже будет введен целый ряд новых структур и объектов, я о них обязательно расскажу, но обо всем по порядку… Исходный код (монитор интерфейсов):
/*
* monitor.c
* мониторинг сетевых интерфейсов и таблицы маршрутизации
*/
#include <errno.h>
#include <stdio.h>
#include <memory.h>
#include <net/if.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <linux/rtnetlink.h>
// небольшая вспомогательная функция, которая с помощью макрасов netlink разбирает сообщение и
// помещает блоки данных в массив атрибутов rtattr
void parseRtattr(struct rtattr *tb[], int max, struct rtattr *rta, int len)
{
memset(tb, 0, sizeof(struct rtattr *) * (max + 1));
while (RTA_OK(rta, len)) { // пока сообщение не закончилось
if (rta–>rta_type <= max) {
tb[rta–>rta_type] = rta; //читаем атрибут
}
rta = RTA_NEXT(rta,len); // получаем следующий атрибут
}
}
int main()
{
int fd = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE); // создаем нужный сокет
if (fd < 0) {
printf("Ошибка создания netlink сокета: %s", (char*)strerror(errno));
return 1;
}
struct sockaddr_nl local; // локальный адрес
char buf[8192]; // буфер сообщения
struct iovec iov; // структура сообщения
iov.iov_base = buf; // указываем buf в качестве буфера сообщения для iov
iov.iov_len = sizeof(buf); // указываем размер буфера
memset(&local, 0, sizeof(local)); // очищаем структуру
local.nl_family = AF_NETLINK; // указываем семейство протокола
local.nl_groups = RTMGRP_LINK | RTMGRP_IPV4_IFADDR | RTMGRP_IPV4_ROUTE; // указываем необходимые группы
local.nl_pid = getpid(); //в качестве идентификатора указываем идентификатор данного приложения
// структура сообщения netlink – инициализируем все поля
struct msghdr msg;
{
msg.msg_name = &local; // задаем имя – структуру локального адреса
msg.msg_namelen = sizeof(local); // указываем размер
msg.msg_iov = &iov; // указываем вектор данных сообщения
msg.msg_iovlen = 1; // задаем длину вектора
}
if (bind(fd, (struct sockaddr*)&local, sizeof(local)) < 0) { // связываемся с сокетом
printf("Ошибка связывания с netlink сокетом: %s", (char*)strerror(errno));
close(fd);
return 1;
}
// читаем и разбираем сообщения из сокета
while (1) {
ssize_t status = recvmsg(fd, &msg, MSG_DONTWAIT); // после вызова bind() мы можем принимать сообщения для указанных групп
// небольшие проверки
if (status < 0) {
if (errno == EINTR || errno == EAGAIN)
{
usleep(250000);
continue;
}
printf("Ошибка связывания приема сообщения netlink: %s", (char*)strerror(errno));
continue;
}
if (msg.msg_namelen != sizeof(local)) { //провряем длину адреса, мало ли
printf("Некорректная длина адреса отправителя");
continue;
}
// собственно разбор сообщения
struct nlmsghdr *h; // указатель на заголовок сообщения
for (h = (struct nlmsghdr*)buf; status >= (ssize_t)sizeof(*h); ) { // для всех заголовков сообщений
int len = h–>nlmsg_len; // длина всего блока
int l = len – sizeof(*h); // длина текущего сообщения
char *ifName; // имя соединения
if ((l < 0) || (len > status)) {
printf("Некорректная длина сообщения: %i", len);
continue;
}
// смотрим тип сообщения
if ((h–>nlmsg_type == RTM_NEWROUTE) || (h–>nlmsg_type == RTM_DELROUTE)) { // если это изменения роутов – печатаем сообщение
printf("Произошли изменения в таблице маршрутизации\n");
} else { // в остальных случаях начинаем более детально разбираться
char *ifUpp; // состояние устройства
char *ifRunn; // состояние соединения
struct ifinfomsg *ifi; // указатель на структуру, содержащюю данные о сетевом подключении
struct rtattr *tb[IFLA_MAX + 1]; // массив атрибутов соединения, IFLA_MAX определен в rtnetlink.h
ifi = (struct ifinfomsg*) NLMSG_DATA(h); // получаем информацию о сетевом соединении в кором произошли изменения
parseRtattr(tb, IFLA_MAX, IFLA_RTA(ifi), h–>nlmsg_len); // получаем атрибуты сетевого соединения
if (tb[IFLA_IFNAME]) { // проверяем валидность атрибута, хранящего имя соединения
ifName = (char*)RTA_DATA(tb[IFLA_IFNAME]); //получаем имя соединения
}
if (ifi–>ifi_flags & IFF_UP) { // получаем состояние флага UP для соединения
ifUpp = (char*)"UP";
} else {
ifUpp = (char*)"DOWN";
}
if (ifi–>ifi_flags & IFF_RUNNING) { // получаем состояние флага RUNNING для соединения
ifRunn = (char*)"RUNNING";
} else {
ifRunn = (char*)"NOT RUNNING";
}
char ifAddress[256]; // сетевой адрес интерфейса
struct ifaddrmsg *ifa; // указатель на структуру содержащую данные о сетевом интерфейсе
struct rtattr *tba[IFA_MAX+1]; // массив атрибутов адреса
ifa = (struct ifaddrmsg*)NLMSG_DATA(h); // получаем данные из соединения
parseRtattr(tba, IFA_MAX, IFA_RTA(ifa), h–>nlmsg_len); // получаем атрибуты сетевого соединения
if (tba[IFA_LOCAL]) { // проверяем валидность указателя локального адреса
inet_ntop(AF_INET, RTA_DATA(tba[IFA_LOCAL]), ifAddress, sizeof(ifAddress)); // получаем IP адрес
}
switch (h–>nlmsg_type) { //что конкретно произошло
case RTM_DELADDR:
printf("Был удален адрес интерфейса %s\n", ifName);
break;
case RTM_DELLINK:
printf("Был удален интерфейс %s\n", ifName);
break;
case RTM_NEWLINK:
printf("Новый интерфейс %s, состояние интерфейса %s %s\n", ifName, ifUpp, ifRunn);
break;
case RTM_NEWADDR:
printf("Был добавлен адрес для интерфейса %s: %s\n", ifName, ifAddress);
break;
}
}
status –= NLMSG_ALIGN(len); // выравниваемся по длине сообщения (если этого не сделать – будет очень плохо, можете проверить :))
h = (struct nlmsghdr*)((char*)h + NLMSG_ALIGN(len)); //получаем следующее сообщение
}
usleep(250000); // немножко спим, что бы не очень грузить процессор
}
close(fd); // закрываем дескриптор сокета
return 0;
}Syhi-подсветка кода
* monitor.c
* мониторинг сетевых интерфейсов и таблицы маршрутизации
*/
#include <errno.h>
#include <stdio.h>
#include <memory.h>
#include <net/if.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <linux/rtnetlink.h>
// небольшая вспомогательная функция, которая с помощью макрасов netlink разбирает сообщение и
// помещает блоки данных в массив атрибутов rtattr
void parseRtattr(struct rtattr *tb[], int max, struct rtattr *rta, int len)
{
memset(tb, 0, sizeof(struct rtattr *) * (max + 1));
while (RTA_OK(rta, len)) { // пока сообщение не закончилось
if (rta–>rta_type <= max) {
tb[rta–>rta_type] = rta; //читаем атрибут
}
rta = RTA_NEXT(rta,len); // получаем следующий атрибут
}
}
int main()
{
int fd = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE); // создаем нужный сокет
if (fd < 0) {
printf("Ошибка создания netlink сокета: %s", (char*)strerror(errno));
return 1;
}
struct sockaddr_nl local; // локальный адрес
char buf[8192]; // буфер сообщения
struct iovec iov; // структура сообщения
iov.iov_base = buf; // указываем buf в качестве буфера сообщения для iov
iov.iov_len = sizeof(buf); // указываем размер буфера
memset(&local, 0, sizeof(local)); // очищаем структуру
local.nl_family = AF_NETLINK; // указываем семейство протокола
local.nl_groups = RTMGRP_LINK | RTMGRP_IPV4_IFADDR | RTMGRP_IPV4_ROUTE; // указываем необходимые группы
local.nl_pid = getpid(); //в качестве идентификатора указываем идентификатор данного приложения
// структура сообщения netlink – инициализируем все поля
struct msghdr msg;
{
msg.msg_name = &local; // задаем имя – структуру локального адреса
msg.msg_namelen = sizeof(local); // указываем размер
msg.msg_iov = &iov; // указываем вектор данных сообщения
msg.msg_iovlen = 1; // задаем длину вектора
}
if (bind(fd, (struct sockaddr*)&local, sizeof(local)) < 0) { // связываемся с сокетом
printf("Ошибка связывания с netlink сокетом: %s", (char*)strerror(errno));
close(fd);
return 1;
}
// читаем и разбираем сообщения из сокета
while (1) {
ssize_t status = recvmsg(fd, &msg, MSG_DONTWAIT); // после вызова bind() мы можем принимать сообщения для указанных групп
// небольшие проверки
if (status < 0) {
if (errno == EINTR || errno == EAGAIN)
{
usleep(250000);
continue;
}
printf("Ошибка связывания приема сообщения netlink: %s", (char*)strerror(errno));
continue;
}
if (msg.msg_namelen != sizeof(local)) { //провряем длину адреса, мало ли
printf("Некорректная длина адреса отправителя");
continue;
}
// собственно разбор сообщения
struct nlmsghdr *h; // указатель на заголовок сообщения
for (h = (struct nlmsghdr*)buf; status >= (ssize_t)sizeof(*h); ) { // для всех заголовков сообщений
int len = h–>nlmsg_len; // длина всего блока
int l = len – sizeof(*h); // длина текущего сообщения
char *ifName; // имя соединения
if ((l < 0) || (len > status)) {
printf("Некорректная длина сообщения: %i", len);
continue;
}
// смотрим тип сообщения
if ((h–>nlmsg_type == RTM_NEWROUTE) || (h–>nlmsg_type == RTM_DELROUTE)) { // если это изменения роутов – печатаем сообщение
printf("Произошли изменения в таблице маршрутизации\n");
} else { // в остальных случаях начинаем более детально разбираться
char *ifUpp; // состояние устройства
char *ifRunn; // состояние соединения
struct ifinfomsg *ifi; // указатель на структуру, содержащюю данные о сетевом подключении
struct rtattr *tb[IFLA_MAX + 1]; // массив атрибутов соединения, IFLA_MAX определен в rtnetlink.h
ifi = (struct ifinfomsg*) NLMSG_DATA(h); // получаем информацию о сетевом соединении в кором произошли изменения
parseRtattr(tb, IFLA_MAX, IFLA_RTA(ifi), h–>nlmsg_len); // получаем атрибуты сетевого соединения
if (tb[IFLA_IFNAME]) { // проверяем валидность атрибута, хранящего имя соединения
ifName = (char*)RTA_DATA(tb[IFLA_IFNAME]); //получаем имя соединения
}
if (ifi–>ifi_flags & IFF_UP) { // получаем состояние флага UP для соединения
ifUpp = (char*)"UP";
} else {
ifUpp = (char*)"DOWN";
}
if (ifi–>ifi_flags & IFF_RUNNING) { // получаем состояние флага RUNNING для соединения
ifRunn = (char*)"RUNNING";
} else {
ifRunn = (char*)"NOT RUNNING";
}
char ifAddress[256]; // сетевой адрес интерфейса
struct ifaddrmsg *ifa; // указатель на структуру содержащую данные о сетевом интерфейсе
struct rtattr *tba[IFA_MAX+1]; // массив атрибутов адреса
ifa = (struct ifaddrmsg*)NLMSG_DATA(h); // получаем данные из соединения
parseRtattr(tba, IFA_MAX, IFA_RTA(ifa), h–>nlmsg_len); // получаем атрибуты сетевого соединения
if (tba[IFA_LOCAL]) { // проверяем валидность указателя локального адреса
inet_ntop(AF_INET, RTA_DATA(tba[IFA_LOCAL]), ifAddress, sizeof(ifAddress)); // получаем IP адрес
}
switch (h–>nlmsg_type) { //что конкретно произошло
case RTM_DELADDR:
printf("Был удален адрес интерфейса %s\n", ifName);
break;
case RTM_DELLINK:
printf("Был удален интерфейс %s\n", ifName);
break;
case RTM_NEWLINK:
printf("Новый интерфейс %s, состояние интерфейса %s %s\n", ifName, ifUpp, ifRunn);
break;
case RTM_NEWADDR:
printf("Был добавлен адрес для интерфейса %s: %s\n", ifName, ifAddress);
break;
}
}
status –= NLMSG_ALIGN(len); // выравниваемся по длине сообщения (если этого не сделать – будет очень плохо, можете проверить :))
h = (struct nlmsghdr*)((char*)h + NLMSG_ALIGN(len)); //получаем следующее сообщение
}
usleep(250000); // немножко спим, что бы не очень грузить процессор
}
close(fd); // закрываем дескриптор сокета
return 0;
}Syhi-подсветка кода
Компиляция: gcc monitor.c –o monitor. Запуск: <img1.png>
Пояснения к программе
Как обещал – появились новые структуры. Давайте рассмотрим их, а так же более детально логику приложения:
struct iovec
{
void *iov_base; // буфер данных
__kernel_size_t iov_len; // размер данных
};Syhi-подсветка кода
{
void *iov_base; // буфер данных
__kernel_size_t iov_len; // размер данных
};Syhi-подсветка кода
Эта структура служит хранилищем полезных данных, передаваемых через сокеты netlink. Полю iov_base присваивается указатель на байтовый массив. Именно в этот байтовый массив будут записаны данные сообщения:
struct msghdr {
void *msg_name; // адрес клиента (имя сокета)
int msg_namelen; // длина адреса
struct iovec *msg_iov; // указатель на блок данных
__kernel_size_t msg_iovlen; // количество блоков данных
void *msg_control; // магическое число для протокола, не используется в данных случаях
__kernel_size_t msg_controllen; // длина предидущего поля данных
unsigned msg_flags; // флаги сообщения
};Syhi-подсветка кода
void *msg_name; // адрес клиента (имя сокета)
int msg_namelen; // длина адреса
struct iovec *msg_iov; // указатель на блок данных
__kernel_size_t msg_iovlen; // количество блоков данных
void *msg_control; // магическое число для протокола, не используется в данных случаях
__kernel_size_t msg_controllen; // длина предидущего поля данных
unsigned msg_flags; // флаги сообщения
};Syhi-подсветка кода
Эта структура непосредственно передается через сокет. Она содержит в себе указатель на блок полезных данных, количество данных блоков, а так же ряд дополнительных флагов и полей, пришедших, по большей части, с платформы BSD:
struct ifinfomsg
{
unsigned char ifi_family; // семейство (AF_UNSPEC)
unsigned short ifi_type; // тип устройства
int ifi_index; // индекс интерфейса
unsigned int ifi_flags; // флаги устройства
unsigned int ifi_change; // маска смены, зарезервировано для использования в будущем и всегда должно быть равно 0xFFFFFFFF
};Syhi-подсветка кода
{
unsigned char ifi_family; // семейство (AF_UNSPEC)
unsigned short ifi_type; // тип устройства
int ifi_index; // индекс интерфейса
unsigned int ifi_flags; // флаги устройства
unsigned int ifi_change; // маска смены, зарезервировано для использования в будущем и всегда должно быть равно 0xFFFFFFFF
};Syhi-подсветка кода
Эта структура используется для представления сетевого устройства, его семейства, типа, индекса и флагов:
struct ifaddrmsg
{
unsigned char ifa_family; // Тип адреса (AF_INET или AF_INET6)
unsigned char ifa_prefixlen; // Длина префикса адреса (длина сетевой маски)
unsigned char ifa_flags; // Флаги адреса
unsigned char ifa_scope; // Область адреса
int ifa_index; // Индекс интерфейса, равен аналогичному полю в ifinfomsg
};Syhi-подсветка кода
{
unsigned char ifa_family; // Тип адреса (AF_INET или AF_INET6)
unsigned char ifa_prefixlen; // Длина префикса адреса (длина сетевой маски)
unsigned char ifa_flags; // Флаги адреса
unsigned char ifa_scope; // Область адреса
int ifa_index; // Индекс интерфейса, равен аналогичному полю в ifinfomsg
};Syhi-подсветка кода
Эта структура служит для представления сетевого адреса, назначенного на сетевой интерфейс:
struct rtattr
{
unsigned short rta_len; // Длина опции
unsigned short rta_type; // Тип опции
/* данные */
}Syhi-подсветка кода
{
unsigned short rta_len; // Длина опции
unsigned short rta_type; // Тип опции
/* данные */
}Syhi-подсветка кода
Эта структура* служит для хранения, какого–либо параметра соединения или адреса.
Пояснения к коду
После запуска программы мы создаем netlink сокет и проверяем успешность его создания. Далее происходит объявление необходимых переменных и заполнение структуры локального адреса. Тут мы указываем группы сообщений, на которые хотим подписаться: RTMGRP_LINK, RTMGRP_IPV4_IFADDR, RTMGRP_IPV4_ROUTE.
Так же объявляем структуру сообщения и связываем с ней один блок данных. После этого происходит связывание с сокетом, с помощью bind(). После этого мы становимся подписанными на сообщения для указанных групп. Можно принимать сообщения через сокет.
Далее следует бесконечный цикл приема сообщений из сокета. Так как принимаемый блок данных может иметь несколько заголовков и ассоциированных с ними данных – начинаем перебирать, с помощью netlink макросов все принятые данные. Каждое новое сообщение расположено по указателю struct nlmsghdr *h. Теперь можно разбирать собственно сообщение. Смотрим на поле nlmsg_type и выясняем, что же за сообщение к нам приехало. Если оно связано с таблицей маршрутизации – печатаем сообщение и идем к следующему сообщению. А если нет – начинаем детально разбираться.
Объявляются массивы опций rtattr, куда будут складываться все необходимые данные. За получение этих данных отвечает вспомогательная функция parseRtattr. Она использует макросы Netlink и заполняет указанный массив всеми атрибутами из блока данных структуры ifinfomsg или ifaddrmsg.
После того как мы получили массивы, заполненные атрибутами – можем работать с этим значениями, анализировать их, печатать. Доступ к каждому атрибуту осуществляется по его индексу. Все индексы определены в заголовочных файлах netlink и прокомментированы. В данном случае мы используем следующие индексы:
- IFLA_IFNAME – индекс атрибута с именем интерфейса.
- IFA_LOCAL – индекс атрибута с локальным IP адресом.
После всего этого мы обладаем полной информацией о том, что произошло и можем печатать информацию на экран. Как видите ничего страшного.
Заключение
Итак, мы получили базовые знания о Netlink и его протоколе, рассмотрели все основные структуры и написали наглядный пример. На этом я бы хотел завершить первую часть. Надюсь, что Вам понравилось. Если есть, какие то вопросы – с удовольствием отвечу.
В следующей части мы изучим работу с таблицей маршрутизации и научимся выполнять специализированные запросы. Будет изучено еще ряд структур и методик. Так же будет рассмотрен пример определения своего собственного протокола и общение, с помощью него, со своим модулем в ядре. Для тех, кому нетерпимость изучить что-то новое и кто умеет и хочет учиться чему-то самостоятельно, думаю, пригодится полный RFC протокола Netlink [1], а так же статья в Linux journal [2]. До встречи на страницах журнала клуба ПРОграммистов!
Продолжение следует…
Литература
- RFC-3549 Linux Netlink as an IP Services Protocol http://tools.ietf.org/html/rfc3549
- Kernel Korner — Why and How to Use Netlink Socket http://www.linuxjournal.com/article/7356
Статья из восьмого выпуска журнала «ПРОграммист».
23rd
WMI. Wладение Mагической Iнформацией. часть 1
Чего тут писать-то? Про то, как вы думаете, что нужно хорошему системному администратору? «Монога» пива? Ну, это тоже не плохо бы. Но, что еще? Чтобы пользователи никогда не звонили? Ну, а если среди них симпатичные девчонки, к которым приятно нагрянуть для «осмотра» их компушек? Нет, все это отмазки. Хороший администратор должен иметь в своем арсенале как можно больше инструментов управления подчиненной ему сети. Конечно, такие инструменты существуют и давно, кстати, но большинство из них требуют наличие установленного клиента на целевой машине, а это не всегда кошерно. Можно, но вдруг пользователь запротестует: «…нечего мне на винду ставить хлам». К тому же, не все из этих инструментов бесплатные. Что же делать в таких случаях, когда и нужно и никак? Ответ прост – написать инструмент самому, но на своих условиях игры.
Виталий Белик
by Stilet www.programmersforum.ru
/ Посвящается моему другу сисадмину Вадиму Фареннику /
Как бы не ругали Виндоус – это все таки могучая операционная система, и если уметь владеть ей в полной мере, она станет надежнее плохо настроенного (из-за незнания) Линукса, к примеру. Я веду к тому, что в винде уже встроены механизмы удаленного администрирования. Например, это «Удаленный рабочий стол». Не Радмин, но уже неплохо – стандартный. А мы сегодня поговорим о другом механизме. О механизме, позволяющем пройтись по операционке аки по таблицам базы данных – это WMI…
Мы начинаем КВН
Итак, предлагаю начать с того момента, где упоминается эта самая технология. Что это, почему это, что она может? Заглянем в Википедию [1]. Это инструментарий управления Виндоусом. Уже обнадеживает. Три эти слова подразумевают возможность контроля за происходящим в операционной системе, это как раз то, что нужно хорошему администратору.
Читаем дальше: «WMI* представляет собой набор классов, содержащих свойства, доступ к которым открывает информацию о компьютере, операционной системе, их параметрах и установках». Особенную важность уделили динамическому изменению этой информации, поэтому доступ к ней происходит посредством запросов. Получается, что Виндовс выступает в роли системы управления базой данных, откуда мы эту информацию и запрашиваем. Ну, а раз это база данных, согласитесь, было бы просто замечательно, если-бы работа с ней велась на языке, привычном для многих (если не всех) СУБД – SQL.
Читаем дальше. Опа! Угадали. То ли мы верно догадались, то ли Микрософт просчитал заранее удобство… В любом случае, для получения информации используется язык запросов WQL, являющийся одной из разновидностью SQL. Вот это уже радует. Зная язык SQL, трудно будет запутаться при запросах WMI. Это облегчает задачу, еще и потому что запрос сам по себе является строкой, и может быть введен самим пользователем программы непосредственно во время работы самой программы.
Отличненько. По логике в SQL описывается тот или иной доступ к таблицам и объектам базы данных, но в случае с СУБД программисту известно о том, к каким объектам в БД у него есть доступ, который ставит админ базы данных, либо же сам программист знает, какими финтами обладает его база данных. Как же быть в случае с WMI? Кто скажет: какова структура таблиц? Ой, пардон, речь-то шла о классах… какова структура классов WMI и вообще что они из себя представляют?
Вот эту информацию можно почерпнуть в MSDN [2]. Кстати, счастливые обладатели Visual Studio с MSDN-ом, могут набрать в хелпе в поиске WMI, и получить ту же информацию. Ну, предположим, у нас нет такого хелпа (хотя я лично для себя запасся им), и нам придется напрягать интернет. Ничего. Не так сложно выйдя по ссылке [2], попасть на одну из ветвей, описывающих все это благо, с названием «WMI Service Management Classes», а уж на ней можно выйти на WMI Classes, где собственно описаны все классы, которые можно получить запросом**.
Ну, да ладно. Билл им судья. Я на всякий случай приведу ссылку, по которой точнее можно выйти на список классов [3]. Не знаю, что с ней случится через год-два, но на момент написания статьи она была актуальна.
Давайте посмотрим, что за информацию нам предлагает Микрософт…430 классов.… Не кисло. Такое впечатление, что о системе, о ее состоянии на момент запроса можно узнать все-все. Это хорошо. Такая информация для администратора иногда оказывается очень ценной.
Ладно. Что может эта загогулина мы теперь знаем. А как получить эти самые классы? То есть объекты, или что там у них… интерфейсы?
Вот тут немного придется мыслить неравномерно. Думаю, многим привычно, что указатели на объекты возвращают конструкторы класса. Однако, в случае с WMI это не совсем так. Здесь бал правит особый провайдер (все-таки получение информации происходит путем взаимодействия с операционкой через язык запросом, а стало быть, должен быть «черный ящичек», обрабатывающий эти запросы) – WBEM. Механизм этот представляет СОМ сервер, который можно использовать в своих программах, предварительно заполучив его инстанцию. Это делается стандартными методами загрузки СОМ сервера. Например, в Делфи это функция CreateOleObject, которая вызывает CoCreateInstance из библиотеки ole32.dll, и возвращает указатель на объект-провайдер, от которого, скормив ему WQL запрос, можно получить указатели на WMI классы.
Его механизм открывает набор-энумератор. Таким образом, проходя в цикле по динамическому списку, получаем указатели на классы, которые и содержат информацию по запросу. Вообще, если проводить аналогию с базами данных очень легко представить класс WMI как плоскую таблицу, где имена свойств – это имена полей, а их содержимое… нет, не записи, а запись. Один экземпляр класса – одна запись. Таким образом, получается два цикла: один перечисляет список объектов, запрошенного класса, а второй перечисляет поля объекта с информацией.
Что еще нужно знать о WMI? То, что эта технология позволяет не только получать информацию о системе, но и вызывать команды управления системой. То есть классы, полученные энумерацией, имеют методы, вызов которых приведет к выполнению на целевой машине неких, подлежащих ему действий. Не думайте, что я описался, назвав локальный компьютер целевым. WMI позволяет проводить все эти операции с любым хостом Windows в сети, лишь бы имелись административные права на подключение к целевой машине.
Итак, пора написать программку, которая будет нашим телескопом в локальной сети.
Show must go on…
Ради интереса, предлагаю небольшой холливар. Да, да… Вот такой вот я нехороший провокатор. Предлагаю написать программу на двух языках – Делфи и Си. В качестве компиляторов я взял Delphi 6 (на мой взгляд, самая лучшая версия Делфи) и Visual Studio 2010. Не потому что VS2008 или VS6 хуже, а просто у меня нет их под рукой.
Для начала давайте определимся со стратегией. Чтобы получить набор данных от WMI нам нужно следующее:
- запустить СОМ сервер, провайдер WMI. А точнее WbemLocator – это имя провайдера;
- приконнектить его к целевой машине;
- заставить его выполнить запрос;
- пройтись энумератором по коллекции записей;
- пройтись энумератором по коллекции полей каждой записи.
Мы, кстати, реализуем механизмы получения значения поля, как по его названию, так и по его номеру. Для этого предлагаю выделить два класса. Первый назовем TWMI. Он будет главным. Его задача принять запрос, подключится к компьютеру, выполнить запрос, и, перебрав его записи, создать список объектов типа TWMIRecord. Этот второй класс будет отвечать за получение данных из полей переданной ему записи (записи передаются в виде объекта) либо по имени, либо по номеру поля. Опять таки и тут без энумерации не обойтись.
Ладушки. Начнем. Сначала опишем главный класс. Листинг 1 и 2 показывает, как он может выглядеть в Делфи и Си:
Листинг 1 (Делфи)
TWMI=class(TComponent)
private
// Список объектов-записей
FRecords:TObjectList;
FSQL: String;
FRoot: String;
FHost: String;
FSQL2: String;
FLogin: String;
FPassword: String;
procedure SetHost(const Value: String);
procedure SetRoot(const Value: String);
function GetItem(i: Variant): TWMIRecord;
procedure SetSQL2(const Value: String);
procedure SetLogin(const Value: String);
procedure SetPassword(const Value: String);
Public
//**************************************
// Функция для циклов. Выдает номер последней записи
Function HighObject:Integer;
// Функция поиска записи по имени поля
Function Find(AFieldName,AValue:String):TWMIRecord;
//**************************************
// Свойство, получающее по номеру запись из набора
Property Item[i:Variant]:TWMIRecord read GetItem; default;
Constructor Create(AOwner:TComponent);
Destructor Free;
published
// Свойства Логина и пароля. Чтоб подключится к компьютеру и
// получить информацию нужны привилегии администратора
Property Login:String read FLogin write SetLogin;
Property Password:String read FPassword write SetPassword;
// Имя машины к которой подключаемся
Property Host:String read FHost write SetHost;
// Путь к таблице с данными
Property Root:String read FRoot write SetRoot;
// Свойство, принимающее строку запроса
// и инициализирующее его выполнение
Property SQL:String read FSQL2 write SetSQL2;
end;
//******************************************Syhi-подсветка кода
private
// Список объектов-записей
FRecords:TObjectList;
FSQL: String;
FRoot: String;
FHost: String;
FSQL2: String;
FLogin: String;
FPassword: String;
procedure SetHost(const Value: String);
procedure SetRoot(const Value: String);
function GetItem(i: Variant): TWMIRecord;
procedure SetSQL2(const Value: String);
procedure SetLogin(const Value: String);
procedure SetPassword(const Value: String);
Public
//**************************************
// Функция для циклов. Выдает номер последней записи
Function HighObject:Integer;
// Функция поиска записи по имени поля
Function Find(AFieldName,AValue:String):TWMIRecord;
//**************************************
// Свойство, получающее по номеру запись из набора
Property Item[i:Variant]:TWMIRecord read GetItem; default;
Constructor Create(AOwner:TComponent);
Destructor Free;
published
// Свойства Логина и пароля. Чтоб подключится к компьютеру и
// получить информацию нужны привилегии администратора
Property Login:String read FLogin write SetLogin;
Property Password:String read FPassword write SetPassword;
// Имя машины к которой подключаемся
Property Host:String read FHost write SetHost;
// Путь к таблице с данными
Property Root:String read FRoot write SetRoot;
// Свойство, принимающее строку запроса
// и инициализирующее его выполнение
Property SQL:String read FSQL2 write SetSQL2;
end;
//******************************************Syhi-подсветка кода
Листинг 2 (С++)
class TWMI
{
private:
// Обьект-провайдер, через который можно будет приконнектится
// к компьютеру.
IWbemLocator *loc;
// обьект, которому будем скармливать запрос, и получать
// записи
IWbemServices *serv;
// поле, хранящее наш запрос
string FQuery;
// энумератор записей
IEnumWbemClassObject* enum_Record;
// список, который будет хранить объекты-записи
list<TWMIRecord> RecList;
// функция, активирующая запуск провайдера
bool RunLocatorInstance();
// функция, активирующая подключение к хосту
bool ConnectToWBEM();
// процедура, создающая новыйй обьект-запись
// в ходе энумерации
void CreaRecord(IWbemClassObject *O);
public:
TWMI(void);
~TWMI(void);
// Функция, открывающая набор данных
// по переданному ей запросу
bool SetQuery(string wql);
// Функция, получающая запись по ее номеру
TWMIRecord* Item(int i);
};Syhi-подсветка кода
{
private:
// Обьект-провайдер, через который можно будет приконнектится
// к компьютеру.
IWbemLocator *loc;
// обьект, которому будем скармливать запрос, и получать
// записи
IWbemServices *serv;
// поле, хранящее наш запрос
string FQuery;
// энумератор записей
IEnumWbemClassObject* enum_Record;
// список, который будет хранить объекты-записи
list<TWMIRecord> RecList;
// функция, активирующая запуск провайдера
bool RunLocatorInstance();
// функция, активирующая подключение к хосту
bool ConnectToWBEM();
// процедура, создающая новыйй обьект-запись
// в ходе энумерации
void CreaRecord(IWbemClassObject *O);
public:
TWMI(void);
~TWMI(void);
// Функция, открывающая набор данных
// по переданному ей запросу
bool SetQuery(string wql);
// Функция, получающая запись по ее номеру
TWMIRecord* Item(int i);
};Syhi-подсветка кода
На всякий случай хочу сказать, что для Сишного кода нужны инструкции:
Листинг 3
#pragma once
#pragma comment(lib, "wbemuuid.lib")
#include <comdef.h>
#include <WbemIdl.h>
#include "TWMIRecord.h"
#include <string>
#include <list>
using namespace std;Syhi-подсветка кода
#pragma comment(lib, "wbemuuid.lib")
#include <comdef.h>
#include <WbemIdl.h>
#include "TWMIRecord.h"
#include <string>
#include <list>
using namespace std;Syhi-подсветка кода
Здесь единственный хедер, который стоит описать – TWMIRecord.h. Он описывает наш класс, отвечающий за получение и хранение полей записи, переданной ему. Все остальное – стандартный набор. Я не буду их описывать, ибо их описание вполне можно найти на MSDN или в хелпе.
Теперь можно описать конструкторы и деструкторы главных классов. На Делфи:
constructor TWMI.Create(AOwner: TComponent);
begin
inherited;
FRecords:=TObjectList.Create;
FHost:=‘.’;
FRoot:=‘root\cimv2’;
end;
destructor TWMI.Free;
begin
FRecords.Free;FRecords:=nil;
end;Syhi-подсветка кода
begin
inherited;
FRecords:=TObjectList.Create;
FHost:=‘.’;
FRoot:=‘root\cimv2’;
end;
destructor TWMI.Free;
begin
FRecords.Free;FRecords:=nil;
end;Syhi-подсветка кода
На Си:
TWMI::TWMI(void)
{
{
loc=NULL; serv=NULL;
CoInitialize(0);
}
TWMI::~TWMI(void)
{
CoUninitialize();
RecList.clear();
Здесь мало интересного. Инициализируются главные свойства, и в случае с Си инициализируется (в конструкторе) и сбрасывается (в деструкторе) СОМ библиотека. В случае с Делфи инициализация будет не здесь, а в коде обработки запроса.
Для Делфи:
На всякий случай, чтоб не было недомолвок, скажу, что обработчики свойств Login, Password, Host, Root стандартные для любого проекта, я не буду приводить их реализацию, ибо там всего лишь внутреннему полю класса, отвечающему за значение этих свойств, описывается методика присвоения нового значения. Если что станьте курсором на эти свойства и нажмите CTRL+SHIFT+C – будут созданы стандартные тела обработчиков – именно их я и имею в виду.
Самое главное для этого класса – метод обработки запроса. Именно здесь сконцентрирована вся магия работы с WMI. Давайте посмотрим, как она выглядит (на Делфи):
procedure TWMI.SetSQL2(const Value: String);
var
// Переменная провайдер. подключается к хосту,
// Через нее будем получать объект для обработки
// запросов
objSWbemLocator,
// Переменная объекта обработки запросов
// Ей будем скармливать запрос и ее же
// энумератором будем получать записи
objWMIService,
// Сервисные переменные. Нужны для
// получения энумераторов
Records,o1,o2
:OleVariant;
var
// Переменная провайдер. подключается к хосту,
// Через нее будем получать объект для обработки
// запросов
objSWbemLocator,
// Переменная объекта обработки запросов
// Ей будем скармливать запрос и ее же
// энумератором будем получать записи
objWMIService,
// Сервисные переменные. Нужны для
// получения энумераторов
Records,o1,o2
:OleVariant;
i:Cardinal;
// Интерфейс, который будет являться посредником
// между провайдером и объектом запросов
id:IDispatch;
// Энумератор для прохода по записям
Enum:IEnumVariant;
// Переменная класса, который будет обрабатывать
// переданную ему запись
r:TWMIRecord;
begin
FSQL2 := Value;
// инициализируем СОМ модель
CoInitialize(0);
// Получаем объект провайдера WMI, Локатор, если говорить
// по микрософтовски
objSWbemLocator:=CreateOleObject(‘WbemScripting.SWbemLocator’);
// Если он успешно получен, то можно далее с ним работать
if not VarIsClear(objSWbemLocator) then begin
// Присоединяемся к хосту, получив интерфейс для
// отработки запросов
objWMIService:=objSWbemLocator.ConnectServer(Host,Root,FLogin,FPassword,»,»,0,id);
// Если присоединение прошло успешно то можно
// скармливать запрос
if not VarIsClear(objWMIService) then begin
// Скормим запрос WQL нашему провайдеру
Records:=objWMIService.ExecQuery(FSQL2,‘WQL’,0,id);
// Он вернет объект записей. Ну если конечно вернет
if not VarIsClear(Records) then begin
//**************************************
// В случае когда все удачно, инициализируем
// энумератор для прохода по записям
Enum:=IEnumVariant(IUnknown(Records._NewEnum)); //Список Записей
// Приготовим список для наполнения объектами,
// обрабатывающими переданные им записи
FRecords.Clear;
// и пройдемся энумератором, пока он
// не достигнет конца коллекции записей
// или точнее пока очередная запись выбрана успешно
while (Enum.Next(1, o1, i) = S_OK) do begin
// Создадим объект — запись
r:=TWMIRecord.Create;
// внеся его в список
FRecords.Add(r);
// И заставим его пройтись по полям,
// переданной ему записи
r.Enum(o1);
end;
//**************************************
// после чего приберем мусор. Набор мы уже получили
// так что можно отключаться
Records:=Unassigned;
end;
objWMIService:=Unassigned;
end;
objSWbemLocator:=Unassigned;
end;
// и освободить ресурсы СОМ машины.
CoUninitialize;
end;Syhi-подсветка кода
Добавлю, что у класса TWMIRecord предусмотрен метод Enum, которому передается объект записи. Он инициализирует проход по полям, получая из них значения. Теперь в С++:
Листинг 7
bool TWMI::SetQuery(string wql){
// Переменная для результатов СОМ механизмов
HRESULT hres;
// результат выполнения запроса.
// он будет подаваться на выход метода, дабы
// программист знал, отработал ли метод успешно
// или не отработал
bool res=false;
// Если Локатор запустился нормально
if(RunLocatorInstance()){
// И присоединился к хосту
if(ConnectToWBEM()){
// Можно скармливать провайдеру
// запрос, не забыв преобразовать типы
hres=serv->ExecQuery(bstr_t("WQL"),
bstr_t(wql.c_str()),
WBEM_FLAG_FORWARD_ONLY | WBEM_FLAG_RETURN_IMMEDIATELY,
NULL,
&enum_Record);
// Если запрос скормлен, и провайдер отработал его правильно
// можно идти далее. Предидущей функцией был
// получен энумератор записей, который позволит
// сделать проход по ним
if(!FAILED(hres)){
// Обьявим переменную — запись. В нее на итерации
// будет подаваться очередная запись
IWbemClassObject *Obj;
// и переменную, в которую будет подаваться сколько // записей
// выбрано. На итерациях это значение будет равно 1,
// ведь мы будет проходитьпо каждой записи
ULONG uReturn = 0;
hres=S_OK;
// приготовим список, хранящий объекты записей
RecList.clear();
// и прокатимся по энумератору
while(enum_Record){
// получим очередную запись
hres=enum_Record->Next(
//указав что мы будем ждать до последнего, пока на сервере выбирается запись
WBEM_INFINITE,
// проходя по одной записи за итерацию,
1,
// передавая ее в переменную вышеописанную нами для этого
&Obj,
// и получая ответ "сколько записей пройдено", короче 1
&uReturn
);
// Если же всетки мы достигли конца набора, вернется 0 пройденных
// записей. Придется прервать цикл
if( uReturn==0) break;
// А пока записи прибывают будем составлять на них
// опись, протокол, сдал-принял… отпечатки пальцев
CreaRecord(Obj);
}
// по прошествии цикла будем считать что функция успешно отработала
// соответственно вернем позитивный ответ
res=true;
}
// и освободим нашего провайдера и его сервис
serv->Release();
}
loc->Release();
}
return res;
};Syhi-подсветка кода
// Переменная для результатов СОМ механизмов
HRESULT hres;
// результат выполнения запроса.
// он будет подаваться на выход метода, дабы
// программист знал, отработал ли метод успешно
// или не отработал
bool res=false;
// Если Локатор запустился нормально
if(RunLocatorInstance()){
// И присоединился к хосту
if(ConnectToWBEM()){
// Можно скармливать провайдеру
// запрос, не забыв преобразовать типы
hres=serv->ExecQuery(bstr_t("WQL"),
bstr_t(wql.c_str()),
WBEM_FLAG_FORWARD_ONLY | WBEM_FLAG_RETURN_IMMEDIATELY,
NULL,
&enum_Record);
// Если запрос скормлен, и провайдер отработал его правильно
// можно идти далее. Предидущей функцией был
// получен энумератор записей, который позволит
// сделать проход по ним
if(!FAILED(hres)){
// Обьявим переменную — запись. В нее на итерации
// будет подаваться очередная запись
IWbemClassObject *Obj;
// и переменную, в которую будет подаваться сколько // записей
// выбрано. На итерациях это значение будет равно 1,
// ведь мы будет проходитьпо каждой записи
ULONG uReturn = 0;
hres=S_OK;
// приготовим список, хранящий объекты записей
RecList.clear();
// и прокатимся по энумератору
while(enum_Record){
// получим очередную запись
hres=enum_Record->Next(
//указав что мы будем ждать до последнего, пока на сервере выбирается запись
WBEM_INFINITE,
// проходя по одной записи за итерацию,
1,
// передавая ее в переменную вышеописанную нами для этого
&Obj,
// и получая ответ "сколько записей пройдено", короче 1
&uReturn
);
// Если же всетки мы достигли конца набора, вернется 0 пройденных
// записей. Придется прервать цикл
if( uReturn==0) break;
// А пока записи прибывают будем составлять на них
// опись, протокол, сдал-принял… отпечатки пальцев
CreaRecord(Obj);
}
// по прошествии цикла будем считать что функция успешно отработала
// соответственно вернем позитивный ответ
res=true;
}
// и освободим нашего провайдера и его сервис
serv->Release();
}
loc->Release();
}
return res;
};Syhi-подсветка кода
Здесь применены методы, описанные выше:
bool TWMI::RunLocatorInstance(){
HRESULT hres;
bool rt=false;
hres=CoCreateInstance(CLSID_WbemLocator,0,CLSCTX_INPROC_SERVER,
IID_IWbemLocator,(LPVOID *)&loc);
if(!FAILED(hres)){
hres = CoInitializeSecurity(
NULL,
-1, // COM authentication
NULL, // Authentication services
NULL, // Reserved
RPC_C_AUTHN_LEVEL_DEFAULT, // Default authentication
RPC_C_IMP_LEVEL_IMPERSONATE, // Default Impersonation
NULL, // Authentication info
EOAC_NONE, // Additional capabilities
NULL // Reserved
);
rt=(!FAILED(hres))?true:false;
}
return rt;
}
bool TWMI::ConnectToWBEM(){
HRESULT hres;
BSTR bUser=NULL,bPassword=NULL;
BSTR bHost=L"ROOT\\CIMV2";
if(Host!=""){bHost=L"\\\\"+_bstr_t(Host.c_str())+L"\\ROOT\\CIMV2";}
hres=loc->ConnectServer(
bHost, // Хост с веткой WMI
// User name. NULL = current user
(Login!="")?_bstr_t(Login.c_str()):bUser,
// User password. NULL = current (Password!="")?_bstr_t(Password.c_str()):bPassword,
0, // Locale. NULL indicates current
NULL, // Security flags.
0, // Authority (e.g. Kerberos)
0, // Context object
&serv // pointer to IWbemServices proxy
);
return (!FAILED(hres))?true:false;
};Syhi-подсветка кода
HRESULT hres;
bool rt=false;
hres=CoCreateInstance(CLSID_WbemLocator,0,CLSCTX_INPROC_SERVER,
IID_IWbemLocator,(LPVOID *)&loc);
if(!FAILED(hres)){
hres = CoInitializeSecurity(
NULL,
-1, // COM authentication
NULL, // Authentication services
NULL, // Reserved
RPC_C_AUTHN_LEVEL_DEFAULT, // Default authentication
RPC_C_IMP_LEVEL_IMPERSONATE, // Default Impersonation
NULL, // Authentication info
EOAC_NONE, // Additional capabilities
NULL // Reserved
);
rt=(!FAILED(hres))?true:false;
}
return rt;
}
bool TWMI::ConnectToWBEM(){
HRESULT hres;
BSTR bUser=NULL,bPassword=NULL;
BSTR bHost=L"ROOT\\CIMV2";
if(Host!=""){bHost=L"\\\\"+_bstr_t(Host.c_str())+L"\\ROOT\\CIMV2";}
hres=loc->ConnectServer(
bHost, // Хост с веткой WMI
// User name. NULL = current user
(Login!="")?_bstr_t(Login.c_str()):bUser,
// User password. NULL = current (Password!="")?_bstr_t(Password.c_str()):bPassword,
0, // Locale. NULL indicates current
NULL, // Security flags.
0, // Authority (e.g. Kerberos)
0, // Context object
&serv // pointer to IWbemServices proxy
);
return (!FAILED(hres))?true:false;
};Syhi-подсветка кода
В принципе, здесь пояснять особо нечего. Создается инстанция провайдера, говоря по-русски, запускается для нашей программы механизм WMI (аналог CreateOleObject(‘WbemScripting.SWbemLocator’); примененной мной в Делфи варианте) и происходит подключение к хосту, учитывая логин и пароль пользователя.
Если логин и пароль отсутствуют, берется аккаунт текущего сеанса (Если уж по правде то текущий контекст безопасности, т.е. с чьими правами запущена программа. Будем считать, что запуск программы будет от текущего сеанса. Мы ведь рассчитываем, что это будет запускать администратор всея сети). Если отсутствует указание хоста – подключение идет к нашей машинке.
Почему я выделил в Сишном классе эти функции подключения отдельно? Захотелось так. Мне показалось, что слишком много в Си писанины, и я не хотел загромождать метод обработки запроса лишним кодом, это бы выглядело некрасиво. Казалось бы сложным. На Делфи эти функции как-то срослись в две строчки, к сожалению, в Си мне не удалось так же аккуратно написать их, может потому, что я плохо знаю Си, или потому что в Делфи действительно удобнее описывать работу с СОМ интерфейсами… Да и работа со строками в Делфи попрозрачнее будет… Впрочем, это не важно. Ну и сюда же следует приписать реализацию процедуры, создания класса для обработки записи:
void TWMI::CreaRecord(IWbemClassObject *O){
// создаем новый объект, скормив ему
// переданную строку
TWMIRecord *r=new TWMIRecord(O);
// Помещаем его в список строк
RecList.push_back(*r);
};Syhi-подсветка кода
// создаем новый объект, скормив ему
// переданную строку
TWMIRecord *r=new TWMIRecord(O);
// Помещаем его в список строк
RecList.push_back(*r);
};Syhi-подсветка кода
Энумерация по полям записи будет инициирована конструктором. Опять таки, в Си я описал создание класса в отдельную процедуру не по каким-то особым причинам, а потому что просто так захотелось. Запросто эти две строчки можно поместить в энумерацию SetQuery.
Так, набор получили. Прокатились по нему. Теперь нужен механизм, проходя по списку объектов TWMIRecord. Надо же как-то получать выбранные данные. Посмотрим, как это можно сделать (на Делфи):
function TWMI.GetItem;
var ii:integer;
begin Result:=nil;
if VarIsOrdinal(i) then
// Если переданный номер записи не
// вылезает за рамки списка
// получим ее
if (i>=0)and(i<FRecords.Count) then
Result:=TWMIRecord(FRecords[i]);
end;Syhi-подсветка кода
var ii:integer;
begin Result:=nil;
if VarIsOrdinal(i) then
// Если переданный номер записи не
// вылезает за рамки списка
// получим ее
if (i>=0)and(i<FRecords.Count) then
Result:=TWMIRecord(FRecords[i]);
end;Syhi-подсветка кода
Эта функция повешена на свойство:
Хорошо зная Делфи, могу заверить, что возможность объявлять свойство для класса по умолчанию очень полезна. Достаточно в выражениях указать имя переменной объекта, если какое-то из его свойств установлено по умолчанию, оно вызовется, так как будто программист руками его вызвал в коде.
Например, многим известен Дельфийский Listbox. У него есть свойство Items[номер строки]. Вызывают его так ListBox.Items[такой-то] – Это дает строку по указанному номеру. Но далеко не все знают, что при написании такого на самом деле Делфи воспринимает это указание как ListBox.Items.Strings[такая-то], потому что Strings описана как свойство по умолчанию для поля Items, да еще и с указанием индексации. Согласитесь удобнее не писать Items.Strings раз среда позволяет это. Код становится короче и красивее. Кстати некоторые нерадивые авторы методичек на этом деле спекулируют. В одних методичках пишут длинную форму обращения, в других краткую. Учеников это часто путает, появляется вопросы «В каких случаях писать длинную форму инструкции в каких короткую». Ответ то на самом деле прост – эти две формы равнозначны. Кто как хочет, пусть так и пишет. Линейкой по рукам нужно проехаться этим борзописцам-преподавателям. Сразу видно они сами мало понимают в программировании. Это большая беда нашей системы обучения, но, увы… Законы Подлости диктуют свою игру.
Продолжение следует…
The Чтиво
- Ресурс вики http://ru.wikipedia.org/wiki/WMI
- MSDN http://social.msdn.microsoft.com/Search/ru-RU?query=WMI&ac=8
- MSDN. Win32 Classes http://msdn.microsoftcom/en-us/library/aa394084%28v=VS.85%29.aspx
- Марк Русинович. Внутри Windows Management Interface. – Magazine/RE, 05, 2000
Статья из восьмого выпуска журнала «ПРОграммист».
Обсудить на форуме — WMI. Wладение Mагической Iнформацией. часть 1
21st
Фев
Panic button — WinAPI графика
Здравствуйте, уважаемые читатели. Прочитав эту статью, Вы получите навыки создания «чистых» WinAPI приложений и управления графикой в среде разработки Lazarus.
21st
Эксплойты. Анализ состава преступления
С каждым годом происходит увеличение количества объектов и источников информации. Для организаций и отдельных лиц становится необходимостью обеспечение трех базовых принципов информационной безопасности: целостности, доступности, конфиденциальности. Обеспечение правовой защиты компьютерной информации выходит на первый план в деятельности любой организации. Поэтому компьютерные преступления, любое противоправное действие, при котором компьютер выступает либо как объект, против которого совершается преступление, либо как инструмент, используемый для совершения преступных действий, могут привести к серьезным убыткам и к другим негативным последствиям. (читать всё…)
21st
Почему сыр в мышеловке бесплатный?
По данным ассоциации производителей программного обеспечения (BSA) в 2009 году 67% программного обеспечения в России было установлено незаконным путем. И 43 % исходят из 111 стран мира. Потери мировой индустрии от распространения пиратского софта оцениваются в 51.4 млрд долларов. Рынок бесплатного программного обеспечения (само словосочетание уже является парадоксом) в Российской Федерации пока что находится в зачаточном состоянии (по данным 2009 года), однако быстро развивается. Так почему же во многих странах складывается ситуация когда пользователь не желает платить за программы? Сегодня мы с вами поговорим о причинах использования бесплатного и пиратского программного обеспечения…
21st
Работа с MySQL в С++ с использованием библиотеки mysql++
Под впечатлением от предыдущей статьи форумчанина Psycho-coder, я решил написать свой небольшой мануал по работе с СУБД MySQL, используя библиотеку mysql++. Данная библиотека является кроссплатформенным решением, написанным на С++, и предоставляет богатый набор классов, позволяяя создавать эффективные приложения.
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
