

Последние записи
- Автоматическое уничтожение объектов
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
4th
Июн
 Работа с LPT портом в Дельфи или компьютер в роли управляющего контроллера. Часть 1
Работа с LPT портом в Дельфи или компьютер в роли управляющего контроллера. Часть 1
Большинство пользователей персонального компьютера привыкли к тому, что весь результат деятельности на компьютере в той или иной степени все равно отражается в самом компьютере. В крайнем случае, отправляется на принтер или в Интернет, или же запись информации происходит на внешние носители (диски, флеш-память и т.п.). И уж мало кто задумывается, что с помощью простого РС – компьютера можно управлять различными внешними физическими устройствами.

Рис. 1. «Рабочая лошадка LPT еще даст о себе знать»
Владимир Дегтярь
by DeKot degvv@mail.ru
Тем не менее, на форуме http://www.programmersforum.ru (да и на других также) часто появляются вопросы: «Как с компьютера зажечь светодиод?», «Как управлять освещением?» или «Можно ли компьютером закрывать шторы на окне?». Ответ: «…однозначно да». С помощью современного персонального компьютера можно создавать, воспроизводить, управлять, хранить, моделировать, обучать и еще реализовать много и много других функций.
Введение
Мы же рассмотрим возможности управления внешними устройствами – при этом возможно управление, как простым вентилятором или светодиодом, так производственными устройствами. Как известно, любой персональный компьютер, да и не только персональный, а и любое компьютерное (еще одно общепринятое название – микропроцессорное) устройство имеет устройства ввода и вывода информации, называемые портами. Для нас пользователей – это просто разъемы для подключения (клавиатура, мышь, модем, флешка и т. д.). Следует заметить, что по одному и тому порту (разъему)
можно как выводить информацию, так и вводить. Кроме этого понятие порт – это не только физически внешний элемент (разъем), а больше наоборот – внутренняя логическая структура устройства компьютера, часть его архитектуры.
Думаю что уже достаточно теории. Перейдем к практической реализации – управлению реальными устройствами с помощью компьютера. Более всего для этого подходит «параллельный» порт LPT. Более подробно смотрим о LPT http://ru.wikipedia.org/wiki/IEEE_1284.
Параллельный порт LPT
Итак, почему параллельный, а не перпендикулярный? А какие еще бывают? Параллельный, потому что информация через такое устройство передается параллельным способом. А еще может передаваться последовательным – тогда устройство (порт) называется последовательным (последовательные порты компьютера: COM-порт, USB- порт). Наглядно это можно увидеть на рисунке 2:
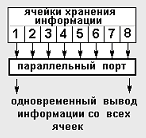
Рис. 2. Методы вывода информации
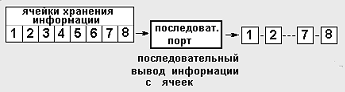
Аналогично ввод информации также может быть параллельным или последовательным. Порты (устройства) через которые можно вводить и выводить информацию называют двунаправленными устройствами или устройствами ввода/вывода. Таким и есть параллельный порт LPT, имеющийся в большинстве компьютеров. Посмотрим, что из себя представляет этот порт (см. рисунок 3):
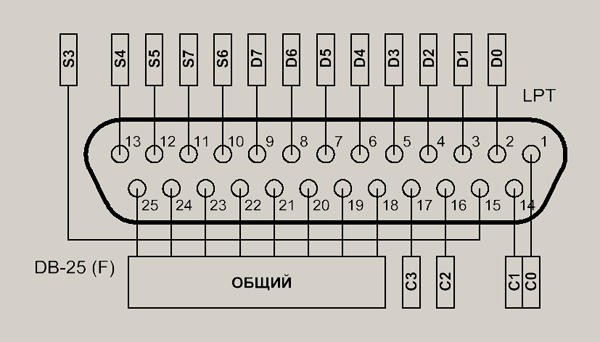
где С0…С3 – регистры контроля, S3…S7 – регистры статуса, D0…D7 – регистры данных
Как видите, это такой разъем с 25-ю выводами на задней стенке системного блока компьютера. Итак, имеем физический порт LPT, который фактически состоит из трех регистров. Состав регистров и распределение по контактам разъема приведены в таблице 1:
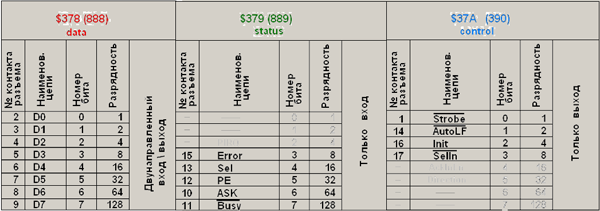
Табл. 1. Распределение выводов LPT по регистрам
Каждый из регистров может содержать байт информации (256 состояний). Часть битов не используется или используется только во внутренней архитектуре компьютера для организации прерываний при работе с принтером или для переключения режимов ввод/вывод регистра «Data».
Регистр данных «Data», номер регистра в шестнадцатеричной системе счисления $378 (в десятичной 888) – двунаправленный, восьмибитный. Данные через этот регистр можно как вводить, так и выводить с компьютера, программно устанавливая уровни на выходе порта или же вводить в компьютер, также программно считывая уровни, устанавливаемые внешними устройствами.
Регистр управления «Control» $37A (890). Через него можно только выводить информацию из компьютера. На разъем LPT выводятся четыре младших байта.
Регистр статуса «Status» $379 (889). Через порт можно только считывать уровни, установленные внешними устройствами. На разъем LPT выведены пять старших байтов.
Таким образом, на разъеме LPT задействовано 17 сигнальных контактов (8 двунаправленных – регистр 888, четыре только на вывод информации – регистр 890 и пять только на ввод информации – регистр 889).
Порт LPT разрабатывался еще на заре создания персональных компьютеров для подключения печатающих устройств (принтер). Этим объясняется специфическое наименования цепей и инверсия некоторых битов, из-за которой наблюдается несоответствие уровней напряжения на контактах и логических кодов регистров. В связи с этим, операции с информацией через LPT порт требуют учитывать эти особенности соответствия физических уровней и логических кодов.
Следует отметить, что в некоторых компьютерах может быть до трех портов LPT: LPT1, LPT2, LPT3 (в современных компьютерах LPT порты зачастую вообще отсутствуют). Адрес самого LPT порта соответствует адресу регистра «Data» и может быть $278, $378 или $3BC. Регистры в соответствующих портах имеют адресацию +1 и +2.
Следующие таблицы (см. таблицы 2, 3) показывают эти особенности данного порта. Для регистра $378 (888) соблюдается полное соответствие между уровнями напряжения на контактах и логическим кодом. А вот с регистрами $379 (889) и $37A (890) все обстоит по-другому:
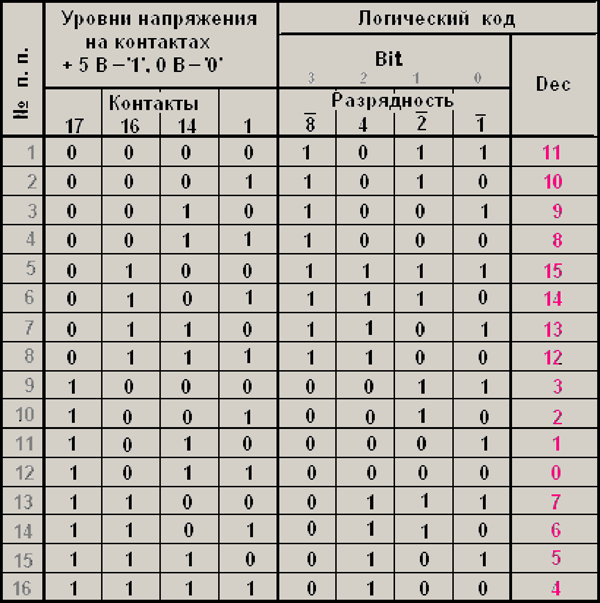
Табл. 2. Порт $37A (890) «Control»
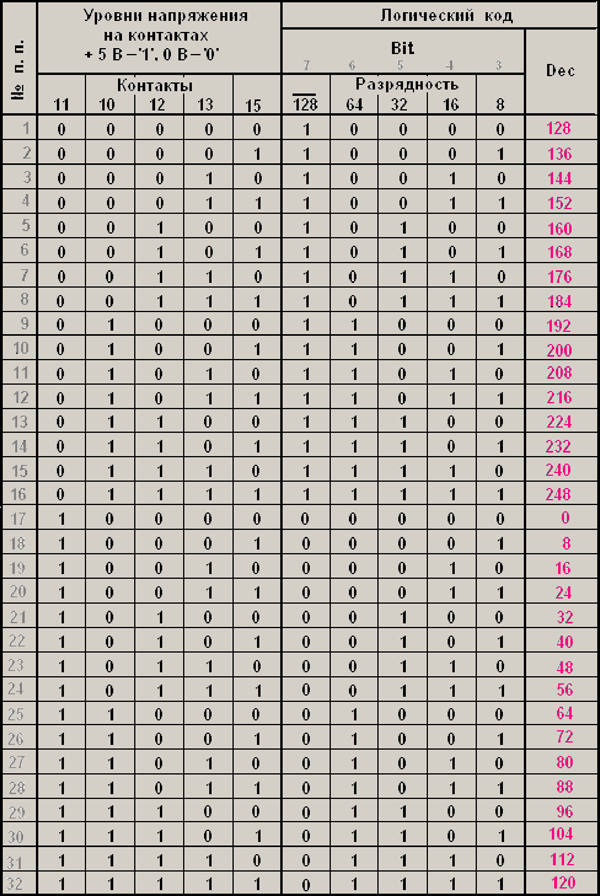
Табл. 3. Порт $379 (889) «Status»
Управление регистрами
В компьютерах с операционными системами MS-DOS, Windows 9x возможен доступ к портам непосредственно из самой операционной системы, тогда как в системах с NT такой прямой доступ невозможен. Для этих целей используются драйвера в виде библиотек (Inpout32.dll, WinIO, Giveo). Подключив соответствующие библиотеки к средам программирования, получаем возможность программно работать с портами (считывание состояния порта или установка выводов порта в необходимое состояние).
* Автор отдает предпочтение библиотеке <inpout32.dll> для работы в среде Дельфи. Библиотека
<inpout32.dll> свободно распространяется в Интернете (см. ресурсы к статье).
Итак, во-первых – помещаем <inpout32.dll> в папке с проектом. Далее в коде модуля Unit после раздела uses размещаем объявления необходимых нам функций из библиотеки:
// импорт функций inpout32.dll
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs,StdCtrls, ExtCtrls, ComCtrls;
function Inp32(PortAdr: word): byte; stdcall; external 'inpout32.dll';
function Out32(PortAdr: word; Data: byte): byte; stdcall; external 'inpout32.dll';
Функция Inp32(PortAdr) возвращает число (тип – байт), соответствующее коду, находящемся в регистре PortAdr. Функция Out32(PortAdr, Data) возвращает число (Data, тип – байт), которое запишется в регистр PortAdr. Проще сказать Inp32 считывает значение регистра, а Out32 устанавливает значение в регистр. Пример применения функций:
var val1, val2: byte;
val1:= Inp32($378); // значение регистра «data» запишется в переменную val1
val2:= 54;
Out32($378,val2); // в регистр «data» запишется число 54 (b 0 0 1 1 0 1 1 0)
При этом следует учитывать, что состояние уровней напряжения на выходных контактах LPT порта соответствует таблице 2 и 3. При необходимости управления отдельными битами регистров можно применить следующие функции преобразований десятичного числа в двоичное и наоборот:
// weight (для byte(8 разр.)) = 128, j = 7; weight( для word (16 разр.)) = 32 768, j = 15 ;
function Dec_Bin(N_dec: integer; weight: integer; _bit: byte): byte;
var i ,j : byte;
mas_bin: array[0..j] of byte;
N_dec: integer;
begin
for i:= 0 to j do
begin
mas_bin:= N_dec div weight;
if mas_bin = 1 then N_dec:= N_dec - weight;
weight:= weight div 2;
end;
Result:= mas_bin[_bit]; // возвращает значение бита (0 или 1) двоичного числа,
// соответствующего N_dec
end;
function Bin_Dec(weight: integer): integer;
var i , j: byte;
mas_bin: array[0..j] of byte;
N_dec: integer;
begin
N_dec:= 0;
for i:= 0 to j do
begin
N_dec:= N_dec + mas_bin * weight;
weight:= weight div 2;
end;
Result:= N_dec; // возвращает десятичное число, соответствующее двоичному
// в виде массива битов mas_bin [ 0 .. j ]
end;
Пример применения функций:
var bit : byte;
bit := Dec_Bin(Inp32($378))[3]; // переменная bit принимает значение 3-го бита регистра «data»
** Переключение регистра «data» ($378) c «выхода» на « вход»
Возможность использования регистра «data» ($378) в качестве порта ввода определяется в настройках
BIOS для параллельного порта. Следует установить Parallel Port в EPP. Переключение регистра на «вход»
осуществляется программно, путем установки 5-го бита регистра «control» ($37A) в «1» (при этом все биты
регистра «data» устанавливаются в «1»). Следует отметить, что данная процедура возможна не на каждом
компьютере и определяется, кроме настроек, еще и конструктивными особенностями порта LPT или
материнской платы.
Вариант тестовой утилиты управления и считывания состояния регистров LPT представлен на рисунке 4 и приведен в ресурсах к статье [1]:

Рис. 4. Утилита считывания и контроля состояний регистров LPT порта
Заключение
Продолжение смотрите в следующем выпуске журнала «ПРОграммист»…
Ресурсы
. Модули и проекты, использованные в статье http://programmersclub.ru/pro/pro3.zip
. Сайт Валерия Ковтуна с множеством интересных программ для работы с LPT портом
http://valery-us4leh.narod.ru/main.html
Это статья из третьего номера журнала “ПРОграммист”.
Скачать его можно по ссылке.
Ознакомиться со всеми номерами журнала.
30th
Май
Как работать с графикой на канве в среде Дельфи
Здравствуйте, уважаемые читатели. Как и обещал, сегодня с вами мы подробно рассмотрим процедуры работы с графическими объектами, вынесенными в отдельный модуль, позволяющий использовать универсальные методы для создания движущихся изображений, находящихся в файлах, обычно в виде спрайтов…
Продолжение. Начало цикла смотрите в первом и втором выпусках журнала…
Владимир Дегтярь
DeKot degvv@mail.ru
Создание проекта с несколькими движущимися объектами. Урок 5
Создадим новый проект <Lesson 3> аналогично предыдущим. Введем в него новые движущиеся графические объекты (в папке <data> добавлено еще четыре звездолета. Размер каждого спрайта 100х80 pix. Новые звездолеты будут появляться по случайному закону (используем функцию Randomize) и двигаться будут сверху вниз. Вывод фона и основного звездолета ’ship1′ осуществляется также как и в предыдущем проекте <Lesson 2>. Для новых объектов вводим дополнительно BufShipR и BufPicR. Также объявим новые переменные – координаты вывода новых звездолетов и приращения этих координат.
Одновременно у нас будут отображаться основной звездолет ’ship 1′ и два из ’ship 2′ – ’ship 5′, выбираемые по случайному закону (см. листинг 1):
ЛИСТИНГ 1
Var
Form1: TForm1;
BufFon,BufFonDop,Buffer: TBitMap;
BufShip1,BufShipR: TBitMap; // буферы спрайтов
BufPicS1,BufPicR: TBitMap; // буферы изображений одного спрайта
xf,yf: integer; // координаты вывода общего буфера на форму
dyf: integer; // приращение изменения координаты yf по вертикали
xS1,yS1: integer; // координаты звездолета 'ship1'
dxS1,dyS1: integer; // приращение координат 'ship1' по гориз. и вертик.
xR1,yR1,xR2,yR2: integer; // координаты звездолетов 'ship2 - ship5'
dyR1,dxR2,dyR2: integer; // приращение координат 'ship2 - 5'
ns,nr1: byte; // номер спрайта и выбор ship2 - ship5
nr2: byte = 3;
implementation
В процедуре OnCreate формы проведем инициализацию буферов и введем начальные данные для переменных. Процедура DrawShipR(i,j: byte) для вывода новых объектов (’ship2′ – ’ship5′) имеет два
параметра: i (изменение номера рисунка в файле спрайтов) и j (переменная для номера файла спрайтов). Т.к. выбор файла спрайта происходит по передаваемому параметру j, то инициализация буфера BufShipR и загрузка в него файла спрайтов находится в процедуре DrawShipR(i,j: byte) (см. листинг 2):
ЛИСТИНГ 2
procedure DrawShip1(i: byte);
begin
// загрузка одного спрайта в буфер рисунка
BufPicS1.Canvas.CopyRect(bounds(0,0,BufPicS1.Width,
BufPicS1.Height),
BufShip1.Canvas,
bounds(i * 66,0,
BufPicS1.Width,
BufPicS1.Height));
BufPicS1.Transparent:= true; // зададим прозрачность фона рисунка спрайта
BufPicS1.TransparentColor:= BufPicS1.Canvas.Pixels[1,1];
end;
Все движения организованы в обработчике таймера. Звездолеты ’ship2′ — ’ship5′ выводятся в Buffer в координаты xR1, yR1 и xR2, yR2 вне видимого окна формы выше. В каждом такте таймера происходит приращение координат для одного dyR1 по вертикали, для другого dxR2 и dyR2 – по горизонтали и вертикали. После того, как объекты выходят за пределы видимого окна формы внизу, вызываются методы random( ) для задания новых координат xR1, xR2 и номера файла спрайта (nr1, nr2). Координаты yR1, yR2 привязаны к координате yS1 , так как ’ship1′ неподвижен в координатах окна формы. Функция
random ( 4 ) возвращает числа в дипазоне 0 .. 3, а файлы спрайтов встречных звездолетов имеют номера 2 .. 5. Поэтому в процедуре загрузки спрайтов BufShipR.LoadFromFile(’data/ship’ + IntToStr(j+2) + ‘.bmp’) номер загружаемого файла определяется как IntToStr(j + 2)… В остальном процедуры обработчиков таймера и нажатия клавиш не отличаются от проекта <Lesson 2>.
Использование универсального модуля для работы с графикой. Урок 6
Если рассмотреть внимательно код программы в проекте <Lesson 3>, можно заметить, что многие методы часто повторяются для разных графических объектов (создание буферов, загрузка изображений из файлов, копирование и т.п.). При этом для упрощения, я сознательно применил файлы спрайтов одинакового размера и с равным количеством рисунков в файлах. А если файлов спрайтов будет не пять, а больше и если количество рисунков в каждом файле будет разным? Придется значительно увеличивать код для
каждого вида спрайтов. Следовательно, необходимо оптимизировать код программы. Выход здесь в написании методов обработки объектов, не зависящих от количества объектов и применимых для разных изображений.
Даная задача реализована в отдельном модуле <LoadObjectToBufferMod>, позволяющий использовать универсальные методы для создания движущихся графических объектов (находящихся в файлах, обычно в виде спрайтов), имеющих различный размер и разное количество изображений отдельных рисунков.
Модуль находится в папке <Lesson 4> (см. ресурсы к статье). Принцип организации модуля следующий:
- вся работа с графическими объектами проводится через битовые образы TBitMap и области
копирования битовых образов TRect
- для работы с фоном используются процедуры InitFon (инициализация) и LoadFon (загрузка фона из
файлов)
- функция InitSprite предназначена для инициализации и загрузки рисунков спрайтов
- для вывода фона и изображений спрайтов использован общий буфер типа TBitMap
- в процедуре InitBuff происходит инициализация общего буфера, а в процедуре FreeBuff ”переустановка”,
т.е. уничтожение общего буфера и создание снова, но уже без изображений спрайтов
- в процедуре LoadBuff происходит наложение изображений спрайтов на фон
Подробно работа модуля показана ниже…
Применение модуля LoadObjectToBufferMod
1. procedure InitFon(nw, nh: byte; FileName: string)
Создаем дополнительный и основной буферы фона:
BufFonD:= TBitmap.Create;
BufFon := TBitmap.Create;
Далее загружаем рисунок одного из фонов в дополнительный буфер:
BufFonD.LoadFromFile(FileName) или
LoadFromResourceName(hinstance.filename);
По загруженному рисунку получаем размер одного рисунка фона (см. рисунок 1):
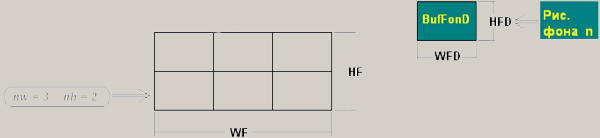
Рис. 1. Определение размера рисунка
Причем, размер буфера фона определяем как:
WF:= nw * WFD;
HF:= nh * HFD;
2. procedure LoadFon(xf, yf: integer; FileName: string)
Загружаем все рисунки фонов в буфер фона через дополнительный буфер (см. рисунок 2):
BufFonD.LoadFromFile(FileName) или
LoadFromResourceName(hinstance.filename);
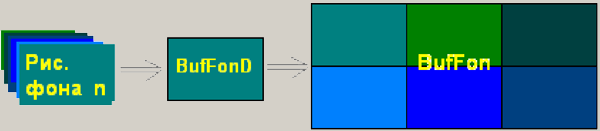
Рис. 2. Загрузка всех рисунков фона
3. procedure initBuffer
Создаем основной буфер (Buffer) через который выводим спрайты на форму:
Buffer:= TBitmap.Create;
Размер основного буфера устанавливаем равным размеру буфера фона WF и HF. Загружаем в основной буфер весь фон (cм. рисунок 3):
Buffer.Canvas.Draw(0, 0, BufFon);

Рис. 3. Загрузка в буфер фона
4. procedure FreeBuffer
Процедура уничтожаем основной буфер Buffer. Применяется когда необходимо убрать какой-либо спрайт с формы:
Buffer.Free;
Восстанавливаем-же основной буфер с фоном так:
InitBuffer;
Спрайты, которые должны оставаться на форме, следует перерисовать по новому (см. процедуру InitStprite)…
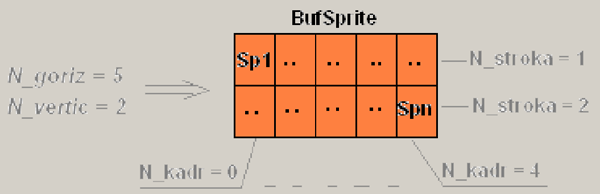
5. procedure InitStprite(SpriteName: string; N_goriz, N_vertic, N_stroka, N_kadr: byte): byte
Cоздаем буфер массива спрайтов и загружаем туда файл спрайтов (см. рисунок 4):
BufSprite:= TBitmap.Create; BufSprite.LoadFromFile(SpriteName) или LoadFromResourceName(hinstance.spritename);Рис. 4. Загрузка файла спрайтов в буфер спрайтов
Создаем буфер рисунка (одного спрайта):
BufPic:= TBitmap.Create;
Далее определяем размеры буферов массива спрайтов и буфера рисунка, а также области (типа TRoot) загрузки рисунка. Загружаем спрайт в буфер рисунка (см. рисунок 5):
BufPic.Canvas.CopyRect(RectPic.BufSprite.Canvas, rectSprite);
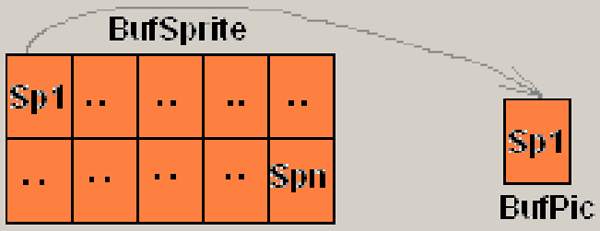
Рис. 5. Загрузка спрайта в буфер рисунка
Задаем прозрачность рисунку:
BufPic.Transparent:= true;
Для вывода следующего спрайта функция возвращает (правильнее сказать – функция принимает значение = Result) значение следующего номера спрайта N_kadr:
Result:= N_kadr;
Уничтожаем буфер массива спрайтов
BufSprite.Free;
6. procedure LoadBuffer(xf, yf, xs, ys, bs: integer)
В этой процедуре на Buffer выводится участок фона с координатами ранее выведенного спрайта, а затем очередное положение спрайта. Определяем область фона и область дополнительного буфера (см. рисунок 6):

Рис. 6. Определение области фона и буфера
Выводим участок фона в буфер, т.е. затираем спрайт фоном (см. рисунок 7):
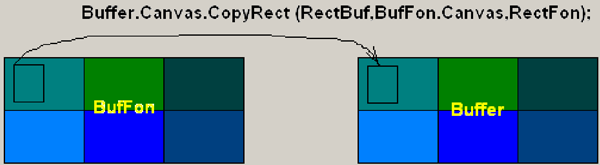
Рис. 7. Затираем спрайт фоном
Выводим очередной спрайт в дополнительный буфер Buffer (см. рисунок 8):
Buffer.Canvas.StretchDraw(Bounds(xs, ys, WP + bs, HP + bs), BufPic);
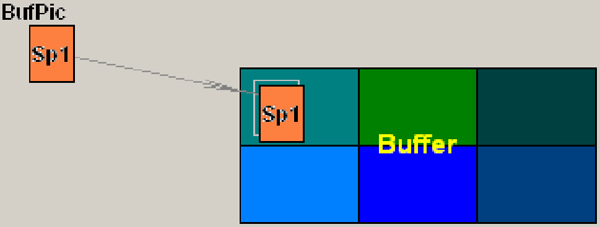
Рис. 8. Вывод следующего спрайта
Уничтожаем буфер рисунка:
BufPic.Free;
Далее в программе выводим дополнительный буфер Buffer на форму методом Draw:
Form1.Canvas.Draw(x, y, Buffer);
Битовые образы фона (BufFon и BufFonD инициализируются (создаются – Create) в программе проекта всего один раз при инициализации программы (обычно вызовом процедуры InitFon в событиях OnCreate или OnActivate). Методы InitBuff, FreeBuff, InitSprite, LoadBuf в программе вызываются неоднократно*. Соответственно и объекты Buffer, BufSprite, BufPic создаются многократно. Поэтому после окончания действия каждого из методов происходит уничтожение битовых образов Buffer, BufSprite, BufPic методом Free.
Комментарий автора.
Загрузку фона можно производить из n – количества файлов, c одинаковым размером не более 1024 х
1024. Для этого вызывать процедуру LoadFon n -раз для разных файлов FonName и изменяя
координаты xf и yf.
Модуль можно применять и для простых объектов (один рисунок в файле SpriteName). Присвойте
переменным N_goriz и N_vertic значения = 1. Если размер спрайта не изменяется, присвойте
переменной bs значение = 0.
Можно загружать рисунки из файлов .jpg. Для этого вместо TBitMap применять класс TJpegImage и в
разделах uses LoadObjectToBufferMod и uses Unit1 добавить модуль Jpeg.
Как работать с модулем?
Для этого необходимо выполнить следующие действия:
1. В процедуре FormActivate (можно в FormCreate) инициализируем буфер фона. Вызываем procedure InitFon(nw,nh: byte; FonName: string) с одним из файлов фонов:
. n раз вызываем procedure LoadFon(xf,yf: integer; FonName: string), последовательно прикрепляя рисунки фонов как бы друг к другу
. инициализируем дополнительный буфер Buffer, вызвав procedure InitBuff. Он получит размер равный сумме размеров всех файлов фонов.
2. Для вывода необходимых спрайтов в нужном месте программы вызываем function InitSprite(SpriteName: string; N_goriz,N_vertic,N_stroka, N_kadr: byte). Функция возвращает очередной номер спрайта для последующего вывода очередного спрайта. Этот номер (N_kadr) необходимо передавать в функцию при каждом ее вызове. Причем, функцию можно использовать для вывода нескольких спрайтов, не забывая передавать ей значение N_kadr для каждых спрайтов.
Далее, вызвав процедуру LoadBuff(xf,yf,xs,ys,bs: integer), выводим спрайт на канву дополнительного буфера поверх фона. Окончательный вывод дополнительного буфера на канву формы производим методом Draw().
Заключение
Рассматриваемые в данной статье проекты полностью приведены в виде ресурсов в теме «Журнал клуба программистов. Третий выпуск» или непосредственно в архиве с журналом (папка Lesson3). Продолжение наших уроков смотрите в следующем выпуске журнала «ПРОграммист»…
Комментарий автора.
Перед запуском в среде Дельфи скопируйте в папку с проектом папку data с графическими файлами.
Это статья из третьего номера журнала “ПРОграммист”.
Скачать его можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Как работать с графикой на канве в среде Дельфи
27th
Май
Передача звука по сети. Прототип VoIP телефона
Данная статья будет полезна начинающим программистам, которые никогда не имели дело со звуком и его передачей по сети. Смысл этой статьи заключается в изучении и применении: WINAPI функций ввода и вывода звука WaveIn() и WaveOut() в среде разработки Delphi 7.0, самих компонентов TIdUDPServerSocket и TIdUDPClientSocket. Данные компоненты можно найти в библиотеке Indy, которая в свою очередь находится в свободном распространении на просторах Internet’а.
Передача звука по сети. Прототип VoIP телефона
Уколов Александр Владимирович
by ImmortalAlexSan st_devil@mail.ru
Комментарий автора.
Если вы никогда не программировали в Delphi 7.0, версиями ниже или выше, если вы вообще никогда не программировали на подобных ЯВУ, то эта статья не для вас.
Введение
К написанию программы для передачи звука по сети меня побудило желание получить-таки зачет по УИРС (это что-то вроде НИР – научно исследовательской работы студента) у преподавателя, ведущего мой основной предмет, и являющимся моим дипломным руководителем. Перед тем как сесть за Delphi и начать набирать код, предварительно, я изучил кучу литературы в бумажном и электронном виде о принципах упаковки звука и его передачи, о функциях ввода и вывода в самом Delphi и многом другом [1, 2]. Именно ввод и вывод заставил меня задуматься о сложности преподносимого материала. Для человека, никогда не имевшего с этим дело, разобраться в этой области очень сложно, имея под рукой множество кода без комментариев с непонятными процедурами и функциями непонятного WIN API, а если эти процедуры и функции описаны, то это описание предназначено не для начинающих программистов, приходилось все додумывать самому: смотреть подноготную каждой процедуры, и методом проб и ошибок идти медленно, но уверенно к вершине созидания. Но в конечном итоге я добился поставленной цели. И сейчас, разложив всю информацию, предоставленную мне в кашеобразном виде, по полочкам, я готов поделиться своими знаниями с вами, дорогие читатели! Итак, приступим…
Средства разработки
Прежде всего, для работы нам понадобится:
. IDE Delphi версии 7.0 и выше
. Библиотека Indy для Delphi 7.0 (TIdUDPServerSocket и TIdUDPClientSocket) [3, 4]
. колонки и микрофон
Сразу же перейдем к практической части. По мере появления неизвестных функций и процедур в листинге, они будут незамедлительно описываться…
Практическая часть. Создадим клиента
Передача звука в моей программе осуществляется с клиента на сервер, т.е. в одном направлении. Клиент может только писать и передавать, сервер – только принимать и воспроизводить. Первым делом начнем писать клиент.
Для этого, создадим новый проект в Дельфи, разместим на форме кнопку TButton и изменим ее свойство Caption на «начать отправку». После чего, разместим на форме компонент из библиотеки Indy TIdUDPClientSocket (см. рисунок 1):
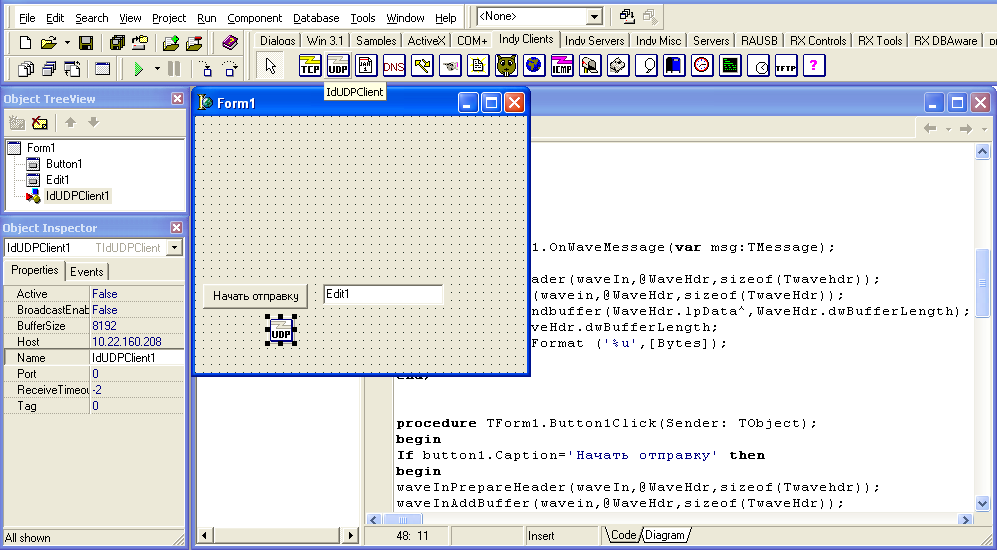
Рис. 1. Режим проектирования формы тестового клиента
Так как тестирование программы будет проводиться на локальном компьютере, то изменим значение свойства Host компонента TIdUDPClientSocket на «localhost». Далее я просто перечислю свойства компонента и их значения, что должны быть установлены: Active (false), BroadCastEnabled (false), BufferSize (8192), Name (IdUDPClient1), Port (0), ReceiveTimeOut (-2), Tag (0).
Примечание: описание некоторых вышеуказанных свойств выходит за рамки данной статьи.
Теперь, нажимаем двойным щелчком по вынесенному на форму компоненту TButton и появится обработчик события Button1Click(), где Button1 – это значение свойства Name данного компонента. В этом обработчике пишем или копируем следующий код:
procedure TForm1.Button1Click(Sender: TObject);
begin
// если на кнопке написано «начать отправку» то
If button1.Caption='Начать отправку' then Begin // выполняем этот код, где:
// готовим заголовок для буфера, здесь WaveIn – переменная типа интегер, для
// указания идентификатора устройства ввода (микрофона например), @WaveHdr –
// указатель на структуру TWaveHdr, sizeof(Twavehdr) – размер данной структуры в байтах.
waveInPrepareHeader(waveIn,@WaveHdr,sizeof(Twavehdr));
// заносим данные в буфер
waveInAddBuffer(wavein,@WaveHdr,sizeof(TwaveHdr));
// активируем сокет клиента
IdUDPClient1.Active:= true;
// считываем данные с микрофона
waveInStart(waveIn);
// в едит для наглядности заносим количество записанных байт (делал для себя,
// чтобы проверять, пишется звук или нет)
Edit1.Text:= inttostr(WaveHdr.dwBufferLength);
// меняем название кнопки, чтобы создать возможность прервать отправку пакетов
button1.Caption:='Остановить отправку'
end else Begin // если название кнопки «остановить отправку» то
//переименовываем её
button1.Caption:='Начать отправку';
//закрываем сокет клиента
IdUDPClient1.Active:=false;
//разгружаем буфер
waveInUnprepareHeader(Wavein,@WaveHdr,sizeof(TwaveHdr));
// приостанавливаем считывание. ЗАМЕТЬТЕ! ПРИОСТАНАВЛИВАЕМ! Если мы
// напишем waveInClose(Wavein), то устройство будет закрыто, и при повторном
// нажатии на кнопку, не будет никакого результата.
waveInStop(Wavein);
// смотрим кол-во не записанных байт
Edit1.Text:=inttostr(Wavehdr.dwBytesRecorded);
end
end;
Вы спросите, а что же такое waveInPrepareHeader? Это функция, выполняющая подготовку буфера для операции загрузки данных. Общий вид:
function waveInPrepareHeader(
hWaveIn: HWAVEIN;
lpWaveInHdr: PWaveHdr;
uSize: UINT
): MMRESULT; stdcall;
Здесь:
HWaveIn – идентификатор открытого устройства
LpWaveInHdr – адрес структуры WaveHdr
type TWaveHdr = record
lpData: PChar; { указатель на буфер}
dwBufferLength: DWORD; { длина буфера }
dwBytesRecorded: DWORD; { записанный байты }
dwUser: DWORD; { переменная для использования её пользователем }
dwFlags: DWORD; { флаги }
dwLoops: DWORD; { контролер }
lpNext: PWaveHdr; { переменная для драйвера }
reserved: DWORD; { переменная для драйвера }
end;
Здесь:
lpData – адрес буфера для загрузки данных
dwBufferLength – длина буфера в байтах
dwBytesRecorded – для режима загрузки данных определяет количество загруженных в буфер байт
dwUser – пользовательские данные
dwFlags – флаги. Могут иметь следующие значения: WHDR_DONE устанавливается
драйвером при завершении загрузки буфера данными
WHDR_PREPARED – устанавливается системой. Показывает готовность буфера к загрузке данных
WHDR_INQUEUE – устанавливается системой, когда буфер установлен в очередь
dwLoops – используется только при воспроизведении. При записи звука всегда 0
lpNext – зарезервировано
reserved – зарезервировано
uSize – размер структуры WaveHdr в байтах
Функция waveInPrepareHeader вызывается только один раз для каждого устанавливаемого в очередь загрузки буфера. Что такое waveInAddBuffer()? Функция waveInAddBuffer() ставит в очередь на загрузку данными буфер памяти. Когда буфер заполнен, система уведомляет об этом приложение:
function waveInAddBuffer(
hWaveIn: HWAVEIN;
lpWaveInHdr: PWaveHdr;
uSize: UINT
): MMRESULT; stdcall;
Здесь:
hWaveIn – идентификатор открытого Waveform audio устройства ввода
lpWaveInHdr – адрес структуры TWaveHdr
uSize – размер WaveHdr в байтах
Что такое waveInStart(), waveInStop(), waveInClose()? Общий вид записи таков:
function waveInStart(hWaveIn: HWAVEIN): MMRESULT; stdcall;
waveInStop(), waveInClose() имеют совершенно одинаковый параметр – как и WaveInStart(), которую описывать не имеет смысла, ибо и так понятно, что она начинает считывать данные с устройства ввода, а вот waveInClose() закрывает устройство для записи, и его снова придется открывать с помощью WaveInOpen(), но об этом ниже… А вот waveInStop(), ставит запись как бы на паузу, и нам не надо повторно использовать WaveInOpen().
Что такое waveInUnprepareHeader? Функция аналогичная waveInPrepareHeader(), однако она возвращает выделенную память на буфер, т.е. как бы «уничтожая» его.
Как узнать, что уже можно передавать данные?
Мы разобрали некоторые функции WIN API, относящиеся к вводу данных. Не устали? Нет? Тогда двигаемся дальше! Создадим собственную процедуру для определения завершения передачи данных в блок памяти посредством WaveInAddBuffer(). А выглядит она так:
procedure TForm1.OnWaveMessage(var msg:TMessage);
begin
waveInPrepareHeader(waveIn,@WaveHdr,sizeof(Twavehdr));
waveInAddBuffer(wavein,@WaveHdr,sizeof(TwaveHdr));
// отправляем буфер на сервер, где WaveHdr.lpData^ - это ссылка на память, где
// хранятся считанные с микрофона данные, уже преобразованные в
// последовательность нулей и единиц, WaveHdr.dwBufferLength – длина буфера данных
idUDPClient1.Sendbuffer(WaveHdr.lpData^,WaveHdr.dwBufferLength);
// В переменную заносим количество отправленных байт
Bytes:=Bytes+WaveHdr.dwBufferLength;
// Формат строки. Посмотрите в google фразу format дельфи
Caption:=Format ('%u',[Bytes]);
UpDate
end;
В этой процедуре используются уже известные вам функции, по этому второй раз описывать их не будем. Пишем её сразу после строки {$R *.dfm}. А описываем эту процедуру в разделе private класса TForm1 как:
procedure OnWaveMessage(var msg:TMessage); message MM_WIM_DATA;
Эта процедура будет выполняться каждый раз как только передача данных в буфер будет завершена и система сгенерирует сообщение WIM_DATA. Заполним обработчик события формы OnClose():
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);
begin
// завершаем все действия
Action:= caFree;
// деактивируем сокет
IdUDPClient1.Active:=false;
// закрываем, теперь уже совсем, устройство записи
waveInClose(Wavein);
end;
И конечно же, заполним обработчик события формы OnCreate():
procedure TForm1.FormCreate(Sender: TObject);
begin
// with – оператор, благодаря которому можно не писать переменные, а указывать
// сразу их свойства. В данном случае WaveFormat: TWAVEFORMATEX – отвечает
// за сигнал, т.е. за все его характеристики, описан ниже.
with waveformat do begin
nChannels:=1;
wFormatTag:=WAVE_FORMAT_PCM;
nSamplesPerSec:=8000;
wBitsPerSample:=8;
nBlockAlign:=1;
nAvgBytesPerSec:=8000;
cbSize:=0;
end;
// для удобства загоняем размер буфера в переменную, которую будем вызывать
bufsize:= waveformat.nAvgBytesPerSec*2 div 16;
// размеру буфера сокета присваиваем размер буфера bufsize
IdUDPClient1.BufferSize:=bufsize;
// waveInOpen опишем чуть ниже, как и обещал, WAVE_MAPPER – система
// сама выбирает устройство
waveInOpen(@Wavein,WAVE_MAPPER,addr(waveformat),self.Handle,0,CALLBACK_WINDOW);
// выделяем память под заголовок буфера данных
WaveHdr.lpData:=Pchar(GlobalAlloc(GMEM_FIXED, bufsize));
// присваиваем длину буфера TWaveHdr’у
WaveHdr.dwBufferLength:=bufsize;
// сбрасываем флаги
WaveHdr.dwFlags:=0;
// устанавливаем порт подключения для клиента
IdUDPClient1.Port:= 10090
end;
Что же такое WaveInOpen()?
Функция waveInOpen() открывает имеющееся устройство ввода Waveform Audio для оцифровки сигнала. Типичная ее структура выглядит следующим образом:
function waveInOpen(
lphWaveIn: PHWAVEIN;
uDeviceID: UINT;
lpFormatEx: PWaveFormatEx;
dwCallback,
dwInstance,
dwFlags: DWORD
): MMRESULT; stdcall;
Здесь:
lphWaveIn – указатель на идентификатор открытого Waveform audio устройства. Идентификатор используется после того, как устройство открыто, в других функциях Waveform audio;
uDeviceID – номер открываемого устройства (см. waveInGetNumDevs). Это может быть также идентификатор уже открытого ранее устройства. Вы можете использовать значение WAVE_MAPPER для того, чтобы функция автоматически выбрала совместимое с требуемым форматом данных устройство;
lpFormatEx - указатель на структуру типа TWaveFormatEx
type TWaveFormatEx = packed record
wFormatTag: Word; { format type }
nChannels: Word; { number of channels (i.e. mono, stereo, etc.) }
nSamplesPerSec: DWORD; { sample rate }
nAvgBytesPerSec: DWORD; { for buffer estimation }
nBlockAlign: Word; { block size of data }
wBitsPerSample: Word; { number of bits per sample of mono data }
cbSize: Word; { the count in bytes of the size of }
end;
В этой структуре значения полей следующие:
wFormatTag – формат Waveform audio. Мы будем использовать значение WAVE_FORMAT_PCM
(это означает импульсно-кодовая модуляция) другие возможные значения
смотрите в заголовочном файле MMREG.H;
nChannels – количество каналов. Обычно 1 (моно) или 2(стерео);
nSamplesPerSec – частота дискретизации. Для формата PCM – в классическом смысле, т.е.
количество выборок в секунду. Согласно теореме отсчетов должна вдвое
превышать частоту оцифровываемого сигнала. Обычно находится в диапазоне от
8000 до 44100 выборок в секунду;
nAvgBytesPerSec – средняя скорость передачи данных. Для PCM равна nSamplesPerSec*nBlockAlign;
nBlockAlign – для PCM равен (nChannels*wBitsPerSample)/8;
wBitsPerSample – количество бит в одной выборке. Для PCM равно 8 или 16;
cbSize – равно 0. Подробности в Microsoft Multimedia Programmer’s Reference;
dwCallback – адрес callback-функции, идентификатор окна или потока, вызываемого при
наступлении события;
dwInstance – пользовательский параметр в callback-механизме. Сам по себе не используется
dwFlags – флаги для открываемого устройства:CALLBACK_EVENT dwCallback-параметр –
код сообщения (an event handle);
CALLBACK_FUNCTION dwCallback – параметр – адрес процедуры-обработчика
CALLBACK_NULL dwCallback – параметр не используется
CALLBACK_THREAD dwCallback – параметр – идентификатор потока команд;
CALLBACK_WINDOW dwCallback – параметр – идентификатор окна
WAVE_FORMAT_DIRECT если указан этот флаг, ACM-драйвер не выполняет преобразование данных
WAVE_FORMAT_QUERY функция запрашивает устройство для определения
поддерживает ли оно указанный формат, но не открывает его
Мы использовали callback функцию в OnWaveMessage(). В последнюю очередь я опишу переменные, которые использовались:
type
TForm1 = class(TForm)
IdUDPClient1: TIdUDPClient;
Button1: TButton;
Edit1: TEdit;
procedure Button1Click(Sender: TObject);
procedure FormClose(Sender: TObject; var Action: TCloseAction);
procedure FormCreate(Sender: TObject);
private
procedure OnWaveMessage(var msg:TMessage); message MM_WIM_DATA;
{ Private declarations }
public
{ Public declarations }
Wavein:HWAVEIN;
WaveHdr:TWaveHdr;
bufsize:Cardinal;
end;
var
Form1: TForm1;
WaveDataLength:integer;
bytes:integer;
device:word;
waveformat: TWAVEFORMATEX;
a:integer;
Так же для работы программы необходимо добавить модуль MMSystem в раздел uses. Клиент готов! Как видите, не так страшен черт, как его малюют! Перед тем как перейти к написанию сервера, я бы вам настоятельно рекомендовал бы покопаться в генофонде всех выше описанных функций и самостоятельно глубже разобраться в том, как они устроены. Так для более углубленного изучения, советую переворошить содержимое таких компонентов из серии ACM как AcmIn, AcmOut. Только самообучением можно чего-нибудь добиться.
А что же сервер?
С чистой перед клиентом совестью, можем приступить к написанию сервера! Возможно, эта процедура покажется вам более сложной, но, разобравшись в ней, вы поймете, что это не так. Единственное, что работать мы будем не с одним буфером, а с восьмью, для удобства воспроизведения звука. В один записываем, воспроизводим, очищаем, готовим, записываем и т.д. по очереди каждый из восьми. Так же будет рассмотрена работа с флагами (dwflags) и приема потока данных (TMemoryStream) на сервер. Приступим, нетерпеливые мои!
Как обычно, создадим новый проект и вынесем на форму компонент TMemo (name=memo1) (опять же-таки я использовал его в целях определения получения потока данных, перегоняя его в шестнадцатиричный формат), кнопку TButton и IdUDPServerSocket (см. рисунок 2):
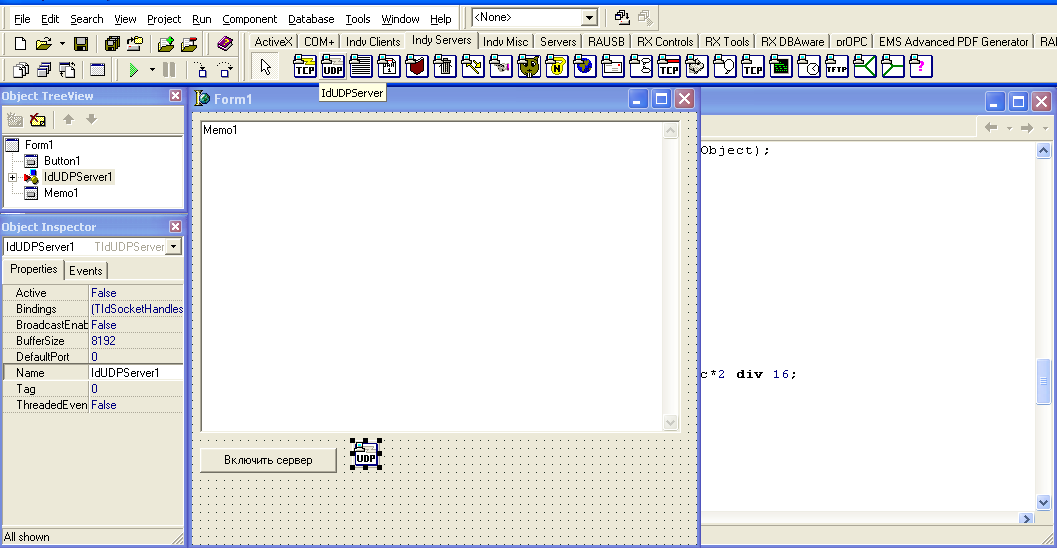
Рис. 2. Режим проектирования формы тестового сервера
Пожалуй, начнем с простого. Напишем ниже приведенный код в обработчике события OnClose() формы:
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);
begin
// завершаем действия
Action:= caFree;
// выключаем сервер
IdUDPServer1.Active:= False
end;
Далее займемся обработчиком события OnClick() кнопки TButton1 (см. код):
procedure TForm1.Button1Click(Sender: TObject);
begin
If button1.Caption='Включить сервер' then Begin
// активируем сокет сервера
IdUDPServer1.Active:= true;
button1.Caption:='Выключить сервер'
end else begin
// деактивируем сокет сервера
IdUDPServer1.Active:= false;
button1.Caption:= 'Включить сервер'
end
end;
Теперь напишем процедуру, которую мы будем использовать для воспроизведения принятого звука:
procedure TForm1.playsound(s:Tstream); // получаемый поток
Var // переменная типа сообщения
msg:Tmessage;
begin
// пока а не равно нашему количеству буферов выполняем следующее
While a<>CWaveBufferCount do Begin
// проверку пользовательской установки на то, что буфер готов к записи
If FHeaders[a].dwUser=0 then begin
// записываем в буфер данные из потока, пришедшего от клиента
s.Read(Fheaders[a].lpdata^,bufsize);
// процедура waveOutPrepareHeader аналогична процедуре waveInPrepareHeader
waveOutPrepareHeader(WaveOut,@FHeaders[a],sizeof(FHeaders));
// Процедура waveOutWrite аналогична процедуре waveInAddBuffer, только она
// осуществляет воспроизведение данных из буфера
waveOutWrite(WaveOut,@FHeaders[a],sizeof(FHeaders));
memo1.Lines.Add('...Двоичный код потока...');
// обнуляем флаги буфера/ов в цикле
FHeaders[a].dwFlags:= 0;
// уже знакомая нам структура
With FHeaders[a] do begin
dwBufferLength:= bufsize;
dwBytesRecorded:= 0;
dwUser := 0;
dwLoops:= 1;
// А вот здесь мы присваиваем флагу только что воспроизведенного буфера
// значение, которое отвечает за то что буфер установлен в очередь, т.е. мы как бы
// циклично используем эти 8 буферов
dwFlags:= WHDR_INQUEUE
end;
// Увеличиваем индекс, чтобы перейти к следующему буферу
inc(a);
// соответственно после воспроизведения и подготовки нам больше не нужен цикл и
// мы выходим из него
exit;
end
end
end;
Процедура разобрана, осталось ей воспользоваться… Как это осуществить? Все просто, достаточно в обработчике события OnUDPRead() idUDPServerSocket-a написать следующий код:
procedure TForm1.IdUDPServer1UDPRead(Sender: TObject; AData: TStream;
ABinding: TIdSocketHandle);
Begin
// если мы воспроизвели последний буфер то, начинаем всё сначала (с первого)
If a = CWaveBufferCount then
a:= 0;
//вызываем нашу процедуру, в скобках пишем наш поток, пришедший на сервер,
//смотрите процедуру сокета.
playsound(Adata);
// определяем сколько байт мы приняли
Bytes:=Bytes + aData.Size;
// показываем это в названии формы
Caption:= 'Принятых байт' + Format('%u', [Bytes]);
// обновляем форму
UpDate
end;
И не забыть при создании формы проинициализировать наши аудиоустройства. Для этого в обработчике OnCreate() формы запишем:
procedure TForm1.FormCreate(Sender: TObject);
begin
bytes:= 0;
WaveOut:= 0;
With WaveFormatOut do begin
nChannels:= 1;
wFormatTag:= WAVE_FORMAT_PCM;
nSamplesPerSec:= 8000;
wBitsPerSample:= 8;
nBlockAlign:= 1;
nAvgBytesPerSec:= 8000;
cbSize:= 0
end;
bufsize:= WaveFormatOut.nAvgBytesPerSec*2 div 16;
For a:= 0 to CWaveBufferCount-1 do
With FHeaders[a] do begin
dwFlags:= WHDR_INQUEUE;
dwBufferLength:= bufsize;
dwBytesRecorded:= 0;
dwUser:= 0;
dwLoops:= 1;
GetMem(Fheaders[a].lpData, bufsize);
end;
IdUDPServer1.BufferSize:= bufsize;
IdUDPServer1.DefaultPort:= 10090;
waveOutOpen(@WaveOut, WAVE_MAPPER, @WaveFormatOut, self.Handle, 0, CALLBACK_WINDOW);
end;
Уважаемые читатели, здесь я пишу без комментариев только для того, что дать вам возможность самим додуматься, что здесь к чему, это не так сложно, тем более, что вы это уже все знаете (мы с вами выше подробно разбирали эти аналогичные функции ввода и вывода и работы с сокетами).
Далее осталось описать переменные и константы:
Const
CwaveBufferCount = 8;
type
TForm1 = class(TForm)
IdUDPServer1: TIdUDPServer;
Button1: TButton;
Memo1: TMemo;
procedure IdUDPServer1UDPRead(Sender: TObject; AData: TStream;
ABinding: TIdSocketHandle);
procedure FormCreate(Sender: TObject);
procedure FormClose(Sender: TObject; var Action: TCloseAction);
procedure Button1Click(Sender: TObject);
procedure playsound(s:Tstream);
private
hdr: PwaveHdr;
{ Private declarations }
public
{ Public declarations }
WaveOut:HWAVEOUT;
WaveHdrOut,WaveHdrOut2:TWaveHdr;
WaveFormatOut:tWAVEFORMATEX;
bufsize:word;
FBuffer:Pointer;
FSndBuffer:Pointer;
FHeaders:array[0..CWaveBufferCount-1] of TWAVEHDR;
FBufSize:Cardinal;
end;
var
Form1: TForm1;
bytes:Cardinal;
WaveOut: HWAVEOUT;
WaveHdrOut,WaveHdrOut2: TWaveHdr;
WaveFormatOut: tWAVEFORMATEX;
bufsize:word;
a:integer;
Я не стал описывать процедуру перегонки потока в HEX-формат, так как писал ради передачи данных в TMемо. В конце концов, вы сами запросто можете убрать ненужные строки, относящиеся к ней.
Заключение
Хочу заметить, что размеры буферов сокетов на сервере и клиенте должны быть равны размерам буферов структуры TWaveHdr, иначе вы не получите никаких звуков на выходе, кроме шипения с прерываниями, равными по длительности размеру вашего воспроизводимого буфера. Также для более быстрой реакции на события приема звука используйте меньшие размеры буферов, но и соответственно увеличьте их количество (8-ми вполне хватит). При желании, лучше использовать динамический.
Статья была написана специально для форума Клуба ПРОграммистов www.programmersforum.ru. Исходники тестового проекта (клиента и сервера) прилагаются в виде ресурсов в теме «Журнал клуба программистов. Третий выпуск» или непосредственно в архиве с журналом [5].
Выражаю огромную благодарность человеку, чей ник на вышеуказанном форуме raxp, который активно помогал мне в изучении этого материала кодами и советами.
Ресурсы
. Азбука WIN API http://letitbit.net/download/1868.1502ee9dae8ee96cec9816babb/Azbuka_WIN_API.rar.html
. Описание звуковых функций http://www.delphikingdom.com/asp/viewitem.asp?catalogid=213
. Репозитарий Indy 9: https://svn.atozed.com:444/svn/Indy9 (имя пользователя: Indy-Public-RO)
. Репозитарий Indy 10: https://svn.atozed.com:444/svn/Indy10 (имя пользователя: Indy-Public-RO)
. Модули и проекты, использованные в статье http://programmersclub.ru/pro/pro3.zip
. Обсуждение на форуме разработки прототипа VoIP телефона
http://www.programmersforum.ru/showthread.php?t=91506
Это статья из третьего номера журнала “ПРОграммист”.
Скачать его можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Передача звука по сети. Прототип VoIP телефона
25th
Май
Поиск пути
Многие начинающие игроделы сталкиваются с проблемой автоматической прокладки маршрутов ботами на карте. Основных проблем две – генерация вейпоинтов и прокладка по ним кратчайшего (либо оптимального по другим параметрам) маршрута. Данная статья, делает небольшой экскурс по реализации алгоритма поиска кратчайшего пути по ранее установленным вейпоинтам (на основе алгоритма Дейкстры).
ПОИСК ПУТИ
На пути постижения мудрости не надо бояться, что свернёшь не туда.
Пауло Коэльо
Автор Utkin www.programmersforum.ru
Прокладка маршрута называется навигацией. Она бывает двух видов: автономная – когда объект (бот) самостоятельно прокладывает маршрут из одной точки карты в другую, запоминает его индивидуально (либо в общем, хранилище маршрутов для одной группы юнитов), и предварительная – когда маршруты уже проложены во время проектирования карты (опять же автоматически или программистом), или же на этапе загрузки карты игрового мира. Маршрут обычно представляет собой некоторую совокупность точек (или их координат) со связями между ними, то есть это маршрут, проложенный на графе. Сами точки называются вейпоинтами – это углы (или вершины) графа. Соответственно подавляющее большинство алгоритмов поиска пути есть алгоритмы по работе с графами.
Краткий экскурс…
Наиболее простой способ – это проложить ключевые точки уже на карте (в момент ее проектирования), а уже на основании имеющейся информации вырабатывать маршрут в зависимости от игрового процесса. Как уже было указано выше, маршрут имеет не только точки, но также и взаимосвязи между ними. В самом простом случае это ссылки на те точки, на которые можно попасть из данной точки, а также отношения между ними (например, это может быть время прохождения или расстояние между точками). В случае если вейпоинты генерируются до игры (во время разработки карты, а не ботом во время игрового процесса) отношения также должны быть уже рассчитаны (например, как расстояния между доступными точками). Также иногда некоторые маршруты уже изначально заложены и бот «знает» куда идти, но такой вариант должен комбинироваться с алгоритмами самостоятельной выработки маршрута по ряду причин – это делает игровой процесс более динамичным, карта может изменять свои параметры (например, произошел обрыв моста, тогда связи, отношения между двумя точками разрушаются, и требуется новый путь) и т.д.
Особенностью игрового мира является тот факт, что любая ситуация может быть промоделирована, поэтому для простых карт (имеющих малое количество вейпоинтов) можно просчитать оптимальные маршруты до каждой точки на этапе проектирования карты. Для карт, имеющих большое количество вейпоинтов, можно просчитать оптимальные маршруты только для тактически важных точек (какие это точки определяет разработчик), например, от базы до основных ресурсов или от одной лестницы до другой и т.д., остальные маршруты все равно придется просчитывать во время игры.
Предварительный просчет точек осуществлен, например, в игре StarСraft. Это видно если отправить рабочего добывать ресурсы, он смело перемещается через туман войны и по неисследованной области, способен находить подъемы на другой уровень плоскости и сразу определять местоположение моста.
Алгоритм Дейкстры
Этот алгоритм находит кратчайшее расстояние от одной из вершин графа до всех остальных.
Сначала рассмотрим граф без применения алгоритма Дейкстры, это упростит понимание алгоритма в дальнейшем. Для удобства восприятия обозначим каждую вершину идентификатором, пусть это будет номер вершины (порядок нумерации на графе значения не имеет). В качестве отношения между точками возьмем расстояние. Получается, точка имеет: идентификатор, список точек, куда можно попасть из данной точки и расстояния до каждой из доступных точек.
Вот образец графа (см. рисунок 1):
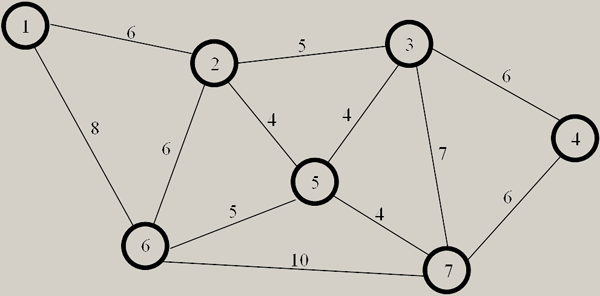
Рис. 1. Образец типичного графа
Представьте, что нам нужно попасть из точки 1 в точку 5. Сколько имеется путей достижения точки 5? Давайте посчитаем:
а) 1-2-5
б) 1-2-6-5
в) 1-6-5
г) 1-6-2-5
Итого четыре маршрута. Вычислим расстояния по каждому маршруту (суммированием расстояний между точками). Вот расстояния между точками:
а) 1-2 расстояние 6
б) 2-5 расстояние 4
в) 2-6 расстояние 6
г) 6-5 расстояние 5
д) 1-6 расстояние 8
е) 6-2, он же 2-6 расстояние 6
Общее расстояние всего маршрута:
а) 1-2-5 расстояние 6+4=10
б) 1-2-6-5 расстояние 6+6+5=17
в) 1-6-5 расстояние 8+5=13
г) 1-6-2-5 расстояние 8+6+4=18
Самый оптимальный (для нашего примера) является путь а) расстояние всего 10. Если же будут обнаружено два и более маршрутов, имеющих одинаковую длину, то выбирается, как правило, первый (либо заранее продумано, какой из маршрутов, лишь бы выбор был осуществлен).
Также нужно обратить внимание, что на первый взгляд маршруты б) и г) равны (казалось бы, от перемены мест слагаемых сумма не меняется), однако следует не забывать, что идентификаторы здесь не несут математического смысла это просто имена точек. Таким же образом мы могли бы назвать и a, b, c и т.д. Операции идут над расстояниями, а суммы пар расстояний (1-2; 2-6) и (1-6; 2-6) не эквивалентны (не равны) между собой.
Теперь сам алгоритм. Он предназначен для поиска всех наикратчайших путей от указанной вершины до всех остальных. Изначально расстояния нам не известны, поэтому будем считать, что они равны максимально возможному расстоянию до каждой из вершин (точек) графа (кроме исходной, до нее расстояние естественно равно нулю). Далее, необходимо отмечать рассмотренные точки графа (чтобы не повторяться)…
Перейдем к алгоритму
Итак, рассмотрим действие алгоритма для первой вершины нашего графа. Вершина 1 имеет отношения (в дальнейшем будем считать отношения просто расстояниями между вершинами графа) с вершинами 2 и 6. Ближайшей точкой будет являться точка 2, поскольку расстояние до нее меньше и составляет 6 единиц (в примере неважно каких единиц, в игре это могут быть условные единицы реальных км, м и т.д., единицы местоположения юнита на карте, число пикселей с привязкой к координатной сетке области отображения и т.д.). Считаем точку 1 пройденной, поскольку нам известны кратчайшие расстояния до точек 2 и 6.
Следующей рассмотрим точку 2 (потому что она ближе к 1 точке). Для нашего графа соседями точки 2 являются 1, 6, 5 и 3. Точку 1 мы рассматривать не будем, поскольку уже было отмечено, что она была просмотрена ранее. Вот расстояния:
. до точки 6 расстояние 6;
. до точки 5 расстояние 4;
. до точки 3 расстояние 5.
Отсюда следует, что ближайшей точкой к вершине 2 будет точка 5, поскольку расстояние до нее минимально, по сравнению с вершинами 6 и 3.
На данном этапе:
. расстояние до точки 1 составляет 0;
. расстояние до точки 2 составляет 6;
. расстояние до точки 5 составляет 10 (6+4);
. маршрут до точки 5 следующий – 1-2-5 (и никакой другой до данной точки более не рассматривается);
. следующей точкой будет являться точка 5;
. точка 2, также как и точка 1 считается отмеченной и больше не рассматривается;
. расстояние до точки 6 (маршрут 1-6) равен 8 (0+8), а не 12 (маршрут 1-2-6, расстояние 6+6), поскольку хоть точка 6 и не отмечена, но текущее расстояние до нее уже было вычислено и оно менее текущего (не забываем, что изначально расстояние до каждой точки равно максимально возможному для данного графа).
Собственно этих данных достаточно для того, чтобы выполнить следующие итерации для всех оставшихся точек нашего графа. Несмотря на такое простое описание реализации алгоритма Дейкстры может оставаться трудной, если не представлять, в виде каких структур выражать работу алгоритма. Вот классический вариант:
Представление точек графа
Граф можно представлять многими способами, например, в виде таблицы смежности (ru.wikipedia.org/wiki/Список_ребер). Такой способ представления удобен с математической точки зрения, но абсолютно не удобен с практической. Например, точку можно представить как ее координаты и набор отношений (где отношение можно представить как пару – указатель на точку-соседа и расстояние до точки-соседа). Если отношение представляет собой расстояние между двумя точками в данной системе координат, то его можно вычислять автоматически по формуле вычисления расстояния между двумя точками (школьный курс геометрии), при этом расстояние для системы координат с числом осей более двух вычисляется аналогично по обобщенной формуле. Собственно совокупность точек графа и будут являться самим графом.
Отмеченные точки графа
Здесь необходимо отмечать те точки графа, которые были пройдены во время работы алгоритма, чтобы не проходить их повторно. Считаю, эти данные должны лежать отдельно от точек графа, потому как такая информация собственно к графу отношения не имеет (а вот к алгоритму самое прямое).
Таблица кратчайших расстояний
Согласно алгоритму изначально расстояние до точек должно представляться максимально возможным расстоянием (за исключением стартовой, до нее расстояние минимально – 0). Затем эти расстояния заполняются в процессе выполнения алгоритма. Также эти расстояния нужны для сравнения имеющихся и предлагаемых расстояний (расстояние до точки 6 для нашего примера).
Маршруты от начальной до остальных точек
Собственно сами маршруты, по которым в дальнейшем будут осуществляться перемещения. Вообще алгоритм Дейкстры не предназначен для поиска маршрутов (только расстояний), но его работа построена таким образом, что формирование маршрута по данному алгоритму не представляет никаких сложностей (в момент оценки и внесения в таблицу кратчайшего расстояния).
Рис. 2. Тестовая утилита
Заключение
Несмотря на кажущуюся сложность данного алгоритма, при четком понимании работы, его реализация очень проста, а скорость работы вполне приемлема для не очень больших графов.
Исходники тестового проекта прилагаются в виде ресурсов в теме «Журнал клуба программистов. Третий выпуск» или непосредственно в архиве с журналом [5].
Ресурсы
. Реализация алгоритма Дейкстры http://plagiata.net.ru/?p=90
. Описание алгоритма Дейкстры http://algolist.ru/maths/graphs/shortpath/dijkstra.php
. Математическое и неформальное описание алгоритма Дейкстры
http://ru.wikipedia.org/wiki/Алгоритм_Дейкстры
. Дополнительные материалы http://borisvolfson.h11.ru/show_article.php?article_id=0000020 и
http://www.excode.ru/art6837p1.html
. Модули и проекты, использованные в статье http://programmersclub.ru/pro/pro3.zip
Это статья из третьего номера журнала “ПРОграммист”.
Скачать его можно по ссылке.
Ознакомиться со всеми номерами журнала.
25th
Разработка ресурса для журнала. Часть 1
С выходом третьего номера журнала [ПРОграммист] у него появился собственный сайт. Разработке этого ресурса и посвящен цикл статей.
Для начала оговорим, что мы решили разбить статью на две части, т.к это не поместиться в объеме одной статьи. Первая часть будет о написании ленты новостей, гостевой книги и вообще всего интерфейса пользователя, а вторая будет посвящена написанию панели администратора.
Первую часть будет вести Егор Горохов aka Revival1002, вторую — Алексей Шульга aka Levsha100, мы будем помогать друг другу в этом нелегком труде. Итак, начнем.
1. Дизайн
Для начала был нарисован PSD шаблон сайта в графическом редакторе Photoshop. Оттуда же мы потом и «выдирали» картинки для сайта. В результате у нас получилось это (см. рисунок 1):

Рис. 1. Предварительный дизайн сайта журнала
Плюс такого дизайна в том, что можно оченьбыстро сделать редизайн. Для этого достаточносменить фоновую картинку и немного подкорректировать таблицы стилей CSS.
2. Верстка
Для создания закругленных углов использовалось свойство border-radius. К сожалению, пока что свойство работает не во всех браузерах, например в IE 6…8 оно игнорируется. Конечно существуют и альтернативные способы создания круглых углов, но они зачастую требуют до 9 (!) картинок блока (4 угла, 4 стороны и центр). Так как мы «очень ленивые», да и острые углы не очень портят дизайн, мы использовали простейшее решение, с надеждой на то, что вскоре все браузеры будут поддерживать данное свойство…
Для полупрозрачности главного div не было найдено (возможно мы плохо «гуглили») кроссбраузерного решения, поэтому мы пошли на хитрость, создав однопиксельный полупрозрачный png, и поставили его на фон. Но и этот способ, как оказалось имеет свои минусы. Например*, ненавистный всеми дизайнерами/верстальщиками IE6 его игнорирует.
* Комментарий автора.
Кстати, я уже давно не видел людей использующих IE6. Все мои знакомые, даже если они мало понимают в компьютерах (например девушки) используют браузеры типа Opera и Mozilla Firefox. Поэтому причин продолжать верстать под MSIE6 я уже не вижу.
Ознакомится с CSS можно по адресу:
http://procoder.info/style.css
3. Написание скриптов
Для начала, вынесем все наиболее часто используемые переменные в отдельный файл “config.php”, и потом будем его «инклудить» во все скрипты. Мы поместили туда логин\пароль от БД, путь к сайту и т.п. В дальнейшем, если мы захотим изменить что-либо, то это займет всего- лишь несколько секунд, и не потребуется вносить изменения во множество скриптов.
Итак, при заходе на сайт пользователь должен видеть: ленту новостей, журналы доступные для скачивания, гостевую книгу. Реализция происходит практически одинаково. Покажу на примере гостевой книги (см. листинг 1):
<?php
require_once "config.php"; // Подключение файла конфигурации
// Функция обрабатывает строку, и заменяет все bb-коды на html
function bbcodes($str)
{
$bbcode = array(
"/\[b\](.*?)\[\/b\]/is" =] "<strong>$1</strong>",
"/\[u\](.*?)\[\/u\]/is" =] "<u>$1</u>",
"/\[url\=(.*?)\](.*?)\[\/url\]/is" =] "<a href='$1'>$2</a>",
"/\[color\=(.*?)\](.*?)\[\/color\]/is" =] "<font
color='$1'>$2</font>",
"/\[i\](.*?)\[\/i\]/is" =] "<i>$1</i>]",
"/\[quote\](.*?)\[\/quote\]/is" =] "<div
class=\"quote\">$1</div>",
"/\[img\](.*?)\[\/img\]/is" =] "<img src=\"$1\">"
);
$str = preg_replace(array_keys($bbcode), array_values($bbcode),
$str);
return $str;
} // Функция взята из мануалов по PHP
// Подключение к БД
$db = mysql_connect($db_server, $db_user, $db_pass);
mysql_select_db($db_name);
// Выбираем из таблицы table_gb последние 30 записей и
сортируем их по id
$db_query=mysql_query("SELECT * FROM `table_gb` ORDER BY `id`
DESC LIMIT 0 , 30", $db);
while ($res = mysql_fetch_array($db_query)) // Вывод записей
{
echo "<div class=\"guest_comment\"><b>".$res['name']."-
".$res['date']."</b><br>";
echo bbcodes(wordwrap("<pre>".$res['text']."</pre>", 75));
echo "</div><br>";
}
?>
// Тут находится форма, для добавления записей в БД, которая
передает скрипту gb.php данные
А теперь скрипт добавляющий записи в БД (см.листинг 2):
<?php
require_once "config.php";
$db = mysql_connect($db_server, $db_user, $db_pass);
mysql_select_db($db_name);
// Получаем данные и убираем из них спец-символы,
// для защиты от XSS-атак
$name = htmlspecialchars($_POST['name']);
$text = htmlspecialchars($_POST['text']);
$date_array = getdate(time());
$date =
$date_array['mday'].".".$date_array['mon'].".".$date_array['year'];
if (($text=='') or ($text=='Введите текст'))
{
echo "<script>alert('Запись не добавлена.');</script>";
echo '<meta http-equiv="Refresh" content="0;
URL='."$index_path".'">';
}
else
{
if (($name=='Ваше имя') or ($name=='')) {$name='Аноним';}
// Добавляем запись в БД
$db_query = mysql_query("INSERT INTO `table_db` (
`id` ,
`name` ,
`text` ,
`date`
) VALUES ('', '$name', '$text', '$date');", $db);
mysql_close($db);
echo "<script]alert('Запись добавлена');</script>";
echo '<meta http-equiv="Refresh" content="0;
URL='."$index_path".'">';
}
?>
Аналогичным образом выводятся записи для новостей, журналов для закачки и другая информация (см. рисунок 2):
Рис. 2. Скрин тестовой работы скриптов
Подведем предварительные итоги…
Что есть и что планируется? Пока сделано очень мало, и нововведения** будут появляться практически каждый день. Совсем скоро будет система регистрации, что позволит комментировать статьи, новости и выставлять им оценки. У каждого пользователя будет личный кабинет. Создавать отдельный форум для сайта не планируется, так как это совместный проект Клуба ПРОграммистов www.programmersclub.ru и форум уже есть. Существующие алгоритмы тоже будут улучшены. Все предложения оставляйте либо на форуме, либо отправляйте на электронный ящик редакции.
Это статья из третьего номера журнала “ПРОграммист”.
Скачать его можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Разработка ресурса для журнала. Часть 1
20th
Май
Взаимодействие с сетевыми интерфейсами в Linux
Linux программирование. Начинающим
Этой статьей я бы хотел открыть цикл публикаций, связанных с самым интересным и захватывающим в Linux – программировании. Я не собираюсь рассказывать о том, в чем писать программы, как их компилировать и запускать, информацию по данным вопросам найти очень легко и я думаю, что любой с этим справится. Языки программирования, которые будут использоваться в статьях: C, C++, bash script.
Олег Кутков http://www.programmersforum.ru/member.php?u=2583
Oleg Kutkov by elenbert@gmail.com
В последнее время программисты и простые пользователи начинают проявлять все больший интерес к Unix- подобным операционным системам, в частности к Linux. К сожалению, новичкам, не всегда просто разобраться в новой среде, даже не смотря на то, что Linux считается одной из самых хорошо документированных ОС. Информация, как правило, разбросана по форумам, множеству отдельных статей и блогов. Основное содержимое данных материалов касается администрирования и настройки дистрибутивов, программистам же, как правило, приходится довольствоваться man-документацией ил
и автоматической doxygen-документацией (документация, сгенерированная автоматически, на основе комментариев в исходном коде). К тому же, как это часто бывает – наиболее интересный материал на английском языке. Безусловно, данную ситуацию следует исправлять.
Начало. Общие сведения
Программировать в Linux очень просто и легко. Для программистов созданы практически идеальные условия: множество мощных инструментов, открытые исходные коды, сама организация системы, множество фреймворков. Работа с файлами, строками, массивами, классами, контейнерами,
в Unix- среде, практически ничем не отличается от таковой в Windows, это касается и множества других стандартных функций и библиотек. Различия начинаются на более низком уровне. Предлагаю разобраться, как работать с сетевыми интерфейсами.
Как известно, сетевые интерфейсы Linux обозначаются короткими строковыми именами – eth0, wlan0, lo и т.д. Интерфейсу можно присвоить любое удобное имя, но лучше руководствоваться общепринятыми правилами именования. Думаю, что ни для кого не секрет, что все устройства в Linux представлены в виде особых файлов в каталоге /dev, это справедливо для всех устройств, кроме сетевых адаптеров. Но так было не всегда, в прошлых версиях Linux ядра были доступны устройства /dev/eth0, /dev/tap0 и т.д., в более же новых ядрах эти устройства упразднили, и сетевые интерфейсы были перенесены в п
амять в так называемое пространство сокетов
Примечание.
* Следует сказать, что в другой популярной Unix – подобной ОС – FreeBSD по-прежнему, сохранен старый способ. Поэтому, если вы захотите переносить приложения с Linux на FreeBSD – следует учитывать это и другие мелкие различия. Но это не значит, что работа с этими устройствами каким-либо образом осложнилась, все очень и очень просто.
Далее я бы хотел рассмотреть особую и очень важную функцию, обеспечивающую обмен управляющими сообщениями между устройством и пользовательским приложениями.
Интерфейсы управления
Для взаимодействия с устройствами, а на самом деле с драйверами устройств, в Unix имеется особый вызов – ioctl, означающий Input-Output Control.
Справедливости ради, следует сказать, что Windows имеется подобный интерфейс – DeviceIoControl. Для использования данного вызова следует включить заголовочный файл <sys/ioctl.h>. Существует также возможность определять свои собственные ioctl вызовы, этим пользуются разработчики драйверов. Рассмотрим вызов ioctl детально…
int ioctl(int d, int request, …);
d – это открытый файловый дескриптор устройства.
request – это тип запроса, для различных устройств запросы различные, соответствующую информацию обычно легко найти в справочных материалов.
Примечание.
В этой статье я рассмотрю все типы запросов для сетевых устройств.
третий аргумент – это указатель на void, т.е. там могут оказаться какие угодно данные, в зависимости от того, что требует конкретный тип запроса. В случае успеха вызовом возвращается ноль. В случае ошибки возвращается «-1» и значение глобальной переменной errno устанавливается соответствующим образом. Чтобы было понятнее, пример использования:
#include <termios.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <errno.h>
int main()
{
int fd, serial, res; // дескриптор, параметр, результат
fd = open("/dev/ttyS0", O_RDONLY); // открываем устройство
if (fd < 0) { // проверяем дескриптор и в случае ошибки - выводим ее пользователю
printf("Открытие /dev/ttyS0 завершилось с ошибкой: %s\n", strerror(errno));
return 1;
}
res = ioctl(fd, TIOCMGET, &serial); // выполняем вызов ioctl с запросом TIOCMGET
if (res < 0) { // проверяем результат и в случае ошибки выводим
printf("Вызов ioctl завершился с ошибкой: %s\n", strerror(errno));
return 1;
}
if (serial & TIOCM_DTR) // проверяем результат
printf("Последовательный порт не готов\n");
else
printf("Последовательный порт готов\n");
close(fd); // закрываем дескриптор
return 0;
}
Сначала мы подключаем необходимые заголовочные файлы, в которых объявлены используемые нами функции, а так же ioctl запросы. В данном примере идет работа с последовательным портом компьютера, а точнее проверяется готовность приема данных. Вызов ioctl на открытом файловом дескрипторе, передает драйверу открытого устройства команду TIOCMGET, сохраняет и возвращает результат в переменную
Serial.
Аналогично происходит процесс передачи информации для драйвера из переменной параметра. Как уже говорил, тип переменной параметра зависит от типа запроса. Как правило, это специальная структура. Таков общий принцип работы ioctl, как видим – ничего сложного. Теперь перейдем непосредственно к теме обсуждения – сетевым интерфейсам…
Работа с сетевыми интерфейсами
Выше был рассмотрен пример использования вызова ioctl для получения данных из открытого дескриптора последовательного порта. Для сетевых интерфейсов работа выполняется аналогичная. Внимательный читатель мог обратить внимание, как выше я говорил о том, что для сетевых устройств не существует таких специальных файлов, соответственно eth0 нельзя открыть также, как и последовательный порт. Это так сетевые устройства перенесены в пространство сокетов и для доступа к этим устройствам следует использовать именно дескрипторы сокетов. Открытие сокета для упр
авления сетевым устройством выполняется так:
int sock = socket(AF_INET, SOCK_DGRAM, 0);
Результат sock и есть дескриптор сокета, перед использованием, его, как и все прочие дескрипторы, следует проверять на отрицательные значения, на случай возможных ошибок. Также, для ioctl вызовов на дескрипторе сокета применяется особая структура параметра (serail, в примере выше) – struct ifreq. Это очень важная структура, используемая во всех случаях работы с сетевыми устройствами. Разберем ее подробнее:
struct ifreq {
char ifr_name[IFNAMSIZ];
union {
struct sockaddr ifr_addr;
struct sockaddr ifr_dstaddr;
struct sockaddr ifr_broadaddr;
struct sockaddr ifr_netmask;
struct sockaddr ifr_hwaddr;
short ifr_flags;
int ifr_ifindex;
int ifr_metric;
int ifr_mtu;
struct ifmap ifr_map;
char ifr_slave[IFNAMSIZ];
char ifr_newname[IFNAMSIZ];
char * ifr_data;
};
};
Структура состоит из двух полей: имени интерфейса и объединения, каждое возможное поле, которого выражает конкретный параметр сетевого интерфейса. Данная структура позволяет, как получать параметр интерфейса, так и задавать его. Так как используется объединение – можно получать и задавать только
один параметр за раз.
Интересуемые и используемые поля:
ifr_addr – IP адрес интерфейса
ifr_dstaddr – адрес сервера (для Point-to-Point соединения)
ifr_broadaddr – широковещательный адрес интерфейса
ifr_netmask – маска подсети
ifr_hwaddr – mac адрес
ifr_ifindex – индекс интерфейса (внутри ядра сетевые интерфейсы имеют уникальные индексы, для упращения работы сетевой подсистемы)
ifr_flags – различные флаги (интерфейс поднят или опущен, интерфейс активен или неактивен и др.)
ifr_metric – метрика интерфейса
ifr_mtu – mtu интерфейса
ifr_map – структура, содержащая в себе техническую информацию (номер прерывания, память устройства и т.д.)
ifr_slave – подчиненное устройство
ifr_newname – новое имя интерфейса (для переименования)
Перед любым использованием структуры следует ее обязательно обнулять с помощью memset, а затем задавать имя интересуемого интерфейса ifr_name. Теперь перейдем от теории к действию – получим IP адрес интерфейса eth0! Соответствующий пример приведен ниже:
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/ioctl.h>
#include <string.h>
#include <net/if.h>
#include <errno.h>
#include <stdio.h>
int main()
{
int sock; // дескриптор сокета
struct sockaddr_in *in_addr; // структура интернет-адреса (поля)
struct ifreq ifdata; // структура - параметр
char *ifname = "eth0"; // имя интерфейса
sock = socket(AF_INET, SOCK_DGRAM, 0); // открываем дескриптор сокета
if (sock < 0) {
printf("Не удалось открыть сокет, ошибка: %s\n", strerror(errno));
return 1;
}
memset(&ifdata, 0, sizeof(ifdata)); // очищаем структуру
strncpy(ifdata.ifr_name, ifname, sizeof(ifname)); // задаем имя интерфейса
//получаем айпи адрес с помощью SIOCGIFADDR, одновременно проверяя результат
if (ioctl(sock, SIOCGIFADDR, &ifdata) < 0) {
printf("Не получить IP адрес для %s, ошибка: %s\n", ifname, strerror(errno));
close(sock);
return 1;
}
in_addr = (struct sockaddr_in *) &ifdata.ifr_addr; // преобразовываем из массива байт
// в структуру sockaddr_in
printf("Интерфейс %s IP адрес: %s\n", ifname, inet_ntoa(in_addr->sin_addr));
close(sock);
return 0;
}
В этом коде я ввел одну новую структуру и одну новую функцию. Начну со структуры:
struct sockaddr_in {
short sin_family;
unsigned short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
Даная структура предназначена для хранения базовых данных об адресе сетевого узла. Назначение ее полей:
sin_family - семейство адресов, может иметь два значения: AF_INET для IPv4 и AF_INET6 для IPv6
sin_port - порт узла
sin_addr - структура адреса (о ней ниже)
sin_zero - этот массив можно использовать по своему усмотрению
struct in_addr {
unsigned long s_addr; // load with inet_pton()
};
Эта структура состоит всего из одного поля – числа, представляющего собой собственно IP адрес. Например, «192.168.8.98», в таком формате, имеет вид 1644734656. Функция inet_ntoa предназначена для преобразования такого числового значения в привычный цифро-точечный формат. В качестве аргумента, функция принимает struct in_addr, а возвращает указатель на строку.
Теперь скажу о преобразовании из массива байт в структуру sockaddr_in. Как было показано выше, поле ifr_addr, в структуре ifreq, имеет тип struct sockaddr. Эта структура является своего рода, «упрощенной» структурой sockaddr_in.
struct sockaddr {
unsigned short sa_family;
char sa_data[14];
};
У нее всего два поля: семейство адресов и массив 14 байт, содержащий собственно адрес. Структуры sockaddr и sockaddr_in хорошо и естественно приводятся к типу друг друга, чем мы и воспользовались. Обратная операция – задание адреса выполняется примерно так же. Отличия только два: перед вызовом ioctl, полю ifr_addr нужно задать новое значение адреса, а тип запроса будет SIOCSIFADDR. Как видно, оба запроса SIOCSIFADDR и SIOCGIFADDR отличаются на одну букву, которая означает Set и Get, соответственно.
Я не буду приводить пример, показывающий, как задавать новое значение адреса, так как предоставленных сведений уже достаточного для того, что бы читатель разобрался сам. Дам лишь небольшую подсказку: для преобразования строкового значения адреса, например «192.168.8.98», в тип struct in_addr следует применять функцию inet_aton:
inet_aton(const char *saddr, struct in_addr *iaddr);
saddr – указатель на строку с адресом
iaddr – указатель на struct in_addr
Для получения (или задания) всех остальных параметров используется аналогичный способ, отличие лишь в типе запроса и использовании соответствующего поля в объединении структуры ifreq. Список всех возможных типов запроса для получения или задания параметров сетевого интерфейса:
SIOCGIFNAME – получить имя сетевого интерфейса
SIOCGIFINDEX – получить индекс сетевого интерфейса
SIOCGIFFLAGS, SIOCSIFFLAGS – получить/задать флаг интерфейса (о флагах ниже)
SIOCGIFMETRIC, SIOCSIFMETRIC – получить/задать метрику интерфейса
SIOCGIFMTU, SIOCSIFMTU – получить/задать mtu интерфейса
SIOCGIFHWADDR, SIOCSIFHWADDR – получить/задать mac адрес
SIOCGIFMAP, SIOCSIFMAP – получить/задать аппаратные параметры (struct ifmap)
Наиболее интересные флаги интерфейса:
IFF_UP – интерфейс запущен
IFF_BROADCAST – интерфейс является широковещательным
IFF_LOOPBACK – интерфейс является петлевым
IFF_POINTOPOINT – point-to-point интерфейс
IFF_RUNNING – интерфейс активен
IFF_MULTICAST – интерфейс поддерживает многоадресность
Небольшой пример использования флагов, получение информации о том, запущен ли интерфейс:
ioctl(sock, SIOCGIFFLAGS, &ifdata);
if (ifdata.ifr_flags && IFF_UP) {
printf("Сетевой интерфейс %s запущен\n", ifdata.ifr_name);
}
else {
printf("Сетевой интерфейс %s не запущен\n", ifdata.ifr_name);
}
На данном этапе предлагаю читателю самостоятельно написать небольшое приложение, получающее, в качестве аргумента командной строки, имя интерфейса и выводящее всю информацию о нем. Но как быть, когда заранее неизвестны имена интерфейсов, как получить просто список доступных сетевых интерфейсов? Очень просто. В помощь приходит замечательный вызов if_nameindex().
Небольшой пример, показывающий как получить список всех сетевых интерфейсов и их индексов.
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/ioctl.h>
#include <string.h>
#include <net/if.h>
#include <errno.h>
#include <stdio.h>
int main()
{
int sock; // дескриптор сокета
struct sockaddr_in *in_addr; // структура интернет адреса (поля)
struct ifreq ifdata; // структура - параметр
struct if_nameindex* ifNameIndex; // структура интерфейсов и их индексов
sock = socket(AF_INET, SOCK_DGRAM, 0); // открываем дескриптор сокета
if (sock < 0) {
printf("Не удалось открыть сокет, ошибка: %s\n", strerror(errno));
return 1;
}
ifNameIndex = if_nameindex();
if (ifNameIndex) { // если удалось получить данные
while (ifNameIndex->if_index) { // пока имеются данные
memset(&ifdata, 0, sizeof(ifdata)); // очищаем структуру
strncpy(ifdata.ifr_name, ifNameIndex->if_name, IFNAMSIZ); // получаем имя следующего интерфейса
// получаем IP адрес с помощью SIOCGIFADDR, одновременно проверяя результат
if (ioctl(sock, SIOCGIFADDR, &ifdata) < 0) {
printf("Не получить IP адрес для %s, ошибка: %s\n", ifdata.ifr_name, strerror(errno));
close(sock);
return 1;
}
// преобразовываем из массива байт в структуру sockaddr_in
in_addr = (struct sockaddr_in *) &ifdata.ifr_addr;
printf("Интерфейс %s индекес %i IP адрес: %s\n", ifdata.ifr_name, ifNameIndex->if_index, inet_ntoa(in_addr->sin_addr));
++ifNameIndex; // переходим к следующему интерфейсу
}
}
close(sock);
return 0;
}
Данный пример является доработанной версией предыдущего примера, выводя все доступные интерфейсы, их индексы и IP адреса. На рисунке ниже изображен процесс компиляции и запуска приложения с выводом всей информации. Видно, так же, сообщение об ошибке, для виртуального интерфейса, с которого не удалось получить информацию:
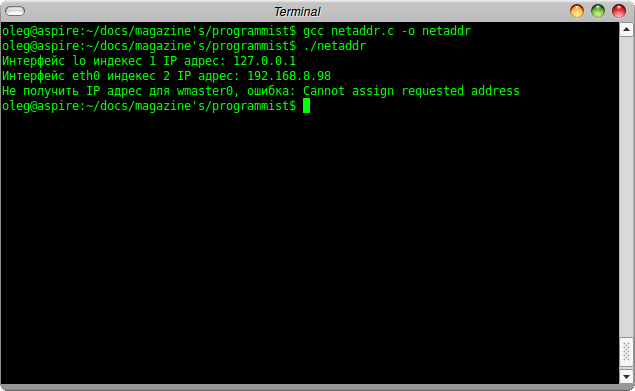
Рисунок. Процесс компиляции и запуска приложения
Заключение
В данной статье я постарался раскрыть основные аспекты взаимодействия с сетевыми интерфейсами в OC Linux, многое из этого будет справедливо и для других Unix подобных операционных систем. Надеюсь, что статья получилась интересной и полезной.
Напоследок не могу не сказать, что в Linux, работа с сетью через ioctl является устаревшим способом, на смену которого приходит Netlink. Netlink – это модуль, состоящий из двух частей, одна находится в ядре и взаимодействует непосредственно с соответствующими подсистемами, вторая – библиотека на уровне пользователя. Обе части могут обмениваться информацией между собой. Это очень мощный и удобный способ управлениями всеми параметрами сетевой подсистемы Linux, такие издания, как «Linux journal» рекомендуют пользоваться только Netlink. К сожалению, документации по данному API н
е так много, как хотелось, и приходится собирать по крупицам. Но в будущих статьях я постараюсь рассмотреть некоторые аспекты использования Netlink, так как уже имею опыт данной сфере. До встречи на страницах журнала!
Литература
. Исходные коды пакета утилит net-tools
. Doxygen документация
. Christian Benvenuti. Understanding Linux network internals. – O’reilly Media, 2005
http://www.linbai.info/computers-it/understanding-linux-network-internals.html
. Интернет ресурсы: www.linuxjournal.com, www.stackoverflow.com, различные форумы
Это статья с третьего выпуска журнала “ПРОграммист”.
Скачать этот выпуск можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Взаимодействие с сетевыми интерфейсами в Linux
12th
Май
Введение в SSE
SSE – FPU XXI века
Автор: Ivan32
Аннотация:
В данной статье рассматриваются базовые принципы работы с расширением SSE.
Введение:
С момента создания первого математического сопроцессора(FPU) для х86-процессоров, прошло уже около 30 лет.
Целая эпоха технологий и физических средств их воплощения прошла, с тех пор, и нынешние FPU стали на порядок быстрее, энергоэффективней и компактней того первого FPU – 8087. С тех пор FPU стал частью процессора, что, конечно же, положительно сказалось на его производительности. Тем не менее, нынешняя скорость выполнения команд FPU оставляет желать лучшего.
К счастью это лучшее уже есть. Им стала технология под названием SSE.
Аппаратное введение:
SSE – Streaming SIMD Extensions – был впервые представлен в процессорах серии Pentium III на ядре Katamai.
SIMD – Single Instruction Multiple Data. Аппаратно данное расширение состоит из 8(позже 16, для режима Long Mode-x86-64) и конечно контрольного регистра – MXCSR
В последующих расширениях SSE2 SSE3 SSSE3 SSS4.1 и SSE4.2 только появлялись новые инструкции, в основном нацеленные на специализированные вычисления.
В 2010 появились первые процессоры с поддержкой набора инструкций для аппаратного шифрования AES, этот набор инструкций тоже использует SSE-регистры.
Регистры SSE называются XMM и наличествуют XMM0-XMM7 для 32-битного Protected Mode и дополнительными XMM8-XMM15 для режима 64-битного Long Mode.
Все регистры XMM-регистры 128-битные, но максимальный размер данных, над которым можно совершать операции это FP64-числа. Последнее обусловлено предназначением данного расширения – параллельная обработка данных.
Программное введение:
Когда я только начинал работать с FPU, меня поразила невообразимая сложность работы с ним. Во-первых, из всех 8-ми регистров, прямой доступ был только к двум.
Во-вторых, напрямую загружать данные в них нельзя было, то есть, скажем, инструкция fld 100.0 не поддерживается. А, в-третьих, из регистров общего назначения тоже
нельзя было загрузить данные. Если вторая проблема в SSE не решена, то о первой и третье подобного сказать нельзя.
В данном обзоре рассматриваются только SISD инструкции, призванные заменить FPU аналоги.
Начнем-с. Перво-наперво стоит узнать, как же можно записать данные в xmm-регистр. SSE может работать с FP32 (float) и FP64(double) IEEE754-числами.
Для прямой записи из памяти предусмотрены инструкции MOVSS и MOVSD .
Их мнемоники расшифровываются так:
MOVSS – MOVE SCALAR(Bottom) SINGLE
MOVSD – MOVE SCALAR(Bottom) DOUBLE
Данные инструкции поддерживают только запись вида XMM-to-MEMORY и MEMORY-to-XMM.
Для записи из регистра общего назначения в регистр XMM и обратно есть инструкции MOVD и MOVQ .
Их мнемоники расшифровываются так:
MOVD – MOV DOUBLE WORD(DWORD)
MOVQ – MOV QUAD WORD(QWORD)
Перейдем к основным арифметическим операциям.
Сложение:
ADDSS – ADD SCALAR SINGLE
ADDSD – ADD SCALAR DOUBLE
Вычитание:
SUBSS – SUB SCALAR SINGLE
SUBSD – SUB SCALAR DOUBLE
Умножение:
MULSS – MUL SCALAR SINGLE
MULSD – MUL SCALAR DOUBLE
Деление:
DIVSS – DIV SCALAR SINGLE
DIVSD – DIV SCALAR DOUBLE
Примечание:
XMM-регистры могут быть разделены на два 64-битных FP64 числа или четыре 32-битные FP32 числа.
В данном случае SINGLE и DOUBLE обозначают FP32 и FP64 соответственно. SCALAR – скалярное значение, выраженное одним числом, в отличие от векторного.
В случае работы со скалярными значениями используется нижний SINGLE или DOUBLE(т.е. нижние 32 или 64-бита соответственно) XMM-регистров.
Недостаток SSE заключается в том, что среди инструкций нет тригонометрических функций. Sin Cos Tan Ctan – все эти функции придется реализовать самостоятельно.
Правда, есть бесплатная Intel Aproximated Math Library, скачать ее можно по адресу: www.intel.com/design/pentiumiii/devtools/AMaths.zip.
В связи с данным фактом, в качестве алгоритма для практической реализации был выбран ряд Тейлора для функции синуса. Это ,конечно, не самый быстрый алгоритм,
но, пожалуй, самый простой. Мы будем использовать 8 членов ряда, что предоставит вполне достаточную точность.
В связи со спецификой Protected Mode, а именно, невозможностью прямой передачи 64-битных чисел через стек (нет, конечно, можно, только по частям но неудобно),
рассмотрим еще одну инструкцию, которую мы задействуем в нашей программе.
CVTSS2SD – ConVerT Scalar Single 2(to) Scalar Double
И ее сестра делающая обратное:
СVTSD2SS – ConVerT Scalar Double 2(to) Scalar Single
Данная инструкция принимает два аргумента, в качестве второго аргумента может выступать либо XMM-регистр либо 32-битная ячейка памяти – DWORD.
Примеры использования SSE-комманд:
movss xmm0,dword[myFP32]
movss xmm0,xmm1
movss dword[myFP32],xmm0
movsd xmm0,qword[myFP64]
movsd xmm0,xmm1
movsd qword[myFP64],xmm0
movd xmm0,eax
movd eax,xmm0
add/sub/mul/div:
addss xmm0,dword[myFP32]
subsd xmm0,xmm1
mulss xmm0,dword[myFP32]
divsd xmm0,xmm1
Математическое введение:
В качестве тестового алгоритма мы будем использовать ряд Тейлора для функции синуса. Алгоритм представляет собой простой численный метод.
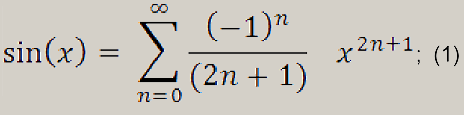
В нашем случае мы используем 8 членов этого ряда, это не слишком много и вполне достаточно для того, что бы обеспечить довольно точные вычисления.
Во всяком случае, отклонение от fsin(аппаратная реализация Sin – FPU) минимально.
Используемая формула выглядит так:
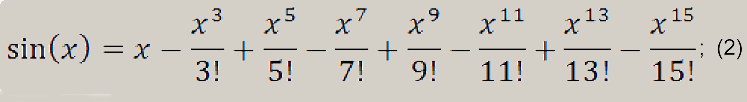
Программная реализация:
В случае с SSE мы воспользуемся всеми восемью регистрами, а что касается FPU – мы будем использовать только st0 и st1.
Благо использование памяти в качестве буфера оказалось эффективней, чем использование всех регистров FPU, к тому же так проще и удобней.
Вычисление будут проходить так:
Сначала мы вычислим значения всех членов ряда, а потом приступим к их суммированию. Подсчет факториалов проводить не будем, так как это пустая
трата процессорного времени в данном случае.
Программная реализация на SSE:
proc sin_sse angle
;Нам понадобятся два экземпляра аргумента:
cvtss2sd xmm0,[angle] ;; Первый будет выступать как результат возведения в степень.
movq xmm1,xmm0 ;; Второй как множитель, это сделано для того что б минимизировать обращения к памяти.
;; xmm0 = angle.
;; xmm1 = angle. ;; далее x=X=Angle
mulsd xmm0,xmm1 ; Возводим X в третью степень.
mulsd xmm0,xmm1 ;
movq xmm2,xmm0 ; xmm2 = xmm0 = x^3
mulsd xmm0,xmm1 ; Продолжаем возведение.
mulsd xmm0,xmm1 ; Теперь уже в пятую степень.
movq xmm3,xmm0 ; xmm3 = xmm0 = x^5
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm4,xmm0 ;; xmm4 = xmm0 = x^7
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm5,xmm0 ;; xmm5 = xmm0 = x^9
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm6,xmm0 ;; xmm6 = xmm0 = x^11
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm7,xmm0 ;; xmm7 = xmm0 = x^13
mulsd xmm0,xmm1 ;; Наконец возводим X в 15-ю степень и заканчиваем возведение.
mulsd xmm0,xmm1 ;; xmm0 = x^15
;; Переходим к делению всех промежуточных результатов X ^ n, на n!.
divsd xmm0,[divers_sd+48] ; X^15 div 15!
divsd xmm7,[divers_sd+40] ; X^13 div 13!
divsd xmm6,[divers_sd+32] ; X^11 div 11!
divsd xmm5,[divers_sd+24] ; X^9 div 9!
divsd xmm4,[divers_sd+16] ; X^7 div 7!
divsd xmm3,[divers_sd+8] ; X^5 div 5!
divsd xmm2,[divers_sd] ; X^3 div 3!
subsd xmm1,xmm2 ; x – x^3/3!
addsd xmm1,xmm3 ; + x^5 / 5!
subsd xmm1,xmm4 ; – x^7 / 7!
addsd xmm1,xmm5 ; + x^9 / 9!
subsd xmm1,xmm6 ; – x^11 / 11!
addsd xmm1,xmm7 ; + x^13 / 13!
subsd xmm1,xmm0 ; – x^15 / 15!
;; В EAX результат не поместится
movq [SinsdResult],xmm1
;; Но если нужно добавить функции переносимость, есть два варианта.
cvtsd2ss xmm1,xmm1
mov eax,xmm1
ret
SinsdResult dq 0.0
divers_sd dq 6.0,120.0,5040.0,362880.0,39916800.0,6227020800.0,1307674368000.0
endp
Что касается FPU версии данной функции, то в ней мы поступим несколько иначе. Мы воспользуемся буфером в виде 16*4 байт. В последний QWORD
запишем результат. И в качестве делителя будем использовать память, это не страшно т.к. данные будут расположены на одной и той же странице, а это
значит, что данная страница уже будет прокеширована и обращения к ней будут довольно быстрыми. Суммирование и вычитание членов ряда так же будет
проведено в конце.
Программная реализация на FPU:
proc sin_fpu angle
fld [angle] ; загружаем X. st0=X
fmul [angle]
fmul [angle] ; st0 = X^3
fld st0 ; st1 = st0
fdiv [divers_fpu] ; Делим X^3 на 3! не отходя от кассы
fstp qword[res] ; легким движением стека FPU, st1 превращается в st0 ![]()
;; qword[res] = x^3 / 3!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^5
fdiv [divers_fpu+8]
fstp qword[res+8]
;; qword[res+8] = x^5 / 5!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^7
fdiv [divers_fpu+16]
fstp qword[res+16]
;; qword[res+16] = x^7 / 7!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^9
fdiv [divers_fpu+24]
fstp qword[res+24]
;; qword[res+24] = x^9 / 9!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^11
fdiv [divers_fpu+32]
fstp qword[res+32]
;; qword[res+32] = x^11 / 11!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^13
fdiv [divers_fpu+40]
fstp qword[res+40]
;; qword[res+40] = x^13 / 13!
fmul [angle]
fmul [angle] ; st0 = st1 = X^15
fdiv [divers_fpu+48]
fstp qword[res+48]
;; qword[res] = x^15 / 15!
fld [angle] ; st0 = X
fsub qword[res] ; X – x^3/3!
fadd qword[res+8] ; + x^5 / 5!
fsub qword[res+16] ; – x^7 / 7!
fadd qword[res+24] ; + x^9 / 9!
fsub qword[res+32] ; – x^11 / 11!
fadd qword[res+40] ; + x^13 / 13!
fsub qword[res+48] ; – x^15 / 15!
fstp qword[res+56] ; Сохраняем результат вычислений.
ret
res_fpu dq 0.0
res dd 14 dup(0)
divers_fpu dq 6.0,120.0,5040.0,362880.0,39916800.0,6227020800.0,1307674368000.0
endp
Обе функции были протестированы в программе WinTest и вот ее результаты:
sin_FPU – 145-150 тактов в цикле на 1000 итераций и около 1300-1800 при первом вызове при использовании FP64 и 150-165 для FP80.
Такая потеря скорости связана с тем, что при первом вызове память еще не прокеширована.
sin_SSE – около 140-141 тактов в цикле на 1000 итераций, при первом вызове результат аналогичный FPU.
На заметку: так же я тестировал SSE через память (аналогично FPU-алгоритму) и FPU через использование всех регистров, в обоих случаях
имела место серьезная потеря производительности. 220-230 тактов для SSE-версии с использование буферов и около 250-300 для FPU через регистры.
FXCH – оказалась очень медленной инструкцией, а SSE не помогло даже то что страница с данными находилась в кеше.
Примечание:
Основываясь на результатах тестирования, я могу сказать, что разница в результатах может быть лишь погрешностью. Это было проверено опытным путем.
Я несколько раз перезагружал компьютер и в разных случаях выигрывал SSE или FPU. Это дает повод предположить, что имела место немаленькая погрешность
и разница в результатах является ее и только ее порождением. Но Intel Optimization Manual говорит об обратном. По документации разница между SSE и FPU
командами около 1-2 тактов в пользу SSE, т.е. SSE-команды на 1-2 такта в среднем, выполняются быстрее.
Выводы:
Как показала практика, при использовании SSE в качестве FPU мы почти ничего не теряем. Важно то, что такое однопоточное SISD использование не является эффективным.
Всю свою настоящую мощь SSE показывает именно в параллельных вычислениях. Какой смысл считать за N тактов, 1 FP32 сложение/вычитание
или любую другую арифметическую операцию, если можно посчитать за те же N-тактов целых четыре FP32 или 2 FP64. Вопрос остается лишь
в распараллеливании алгоритмов. Стоит ли использовать SSE? Однозначно стоит. Данное расширение присутствует во всех процессорах, начиная с Pentium III и AMD K7.
Важно: Регистры XMM предположительно не сохраняються при переключении задач и точно не сохраняются при использовании API. Тот же GDI+ не восстанавливает их значения.
Nota Bene:
1. Тестирование проводилось на процессоре с не самым старым ядром. Еще при релизе мелькала фраза о масштабных оптимизациях во всех блоках.
При схожей частоте данный процессор в ряде приложений оказывается быстрее, чем, скажем Core 2 на ядре Conroe(первое поколение Core 2).
Это собственно к чему: SSE не всегда было таким быстрым, как и FPU. На разных архитектурах вы увидите как выигрыш от использования SSE
так и серьезный проигрыш.
2. Данный численный метод не является самым быстрым, он даже не распараллелен. Аппаратный FSIN выполняется за 80-100 тактов с FP80/FP64 точностью.
Существуют так же другие численные методы для нахождения тригонометрических и других функций, которые намного эффективней данного и практически позволяют
сделать эти вычисления более быстрыми, нежели FSIN.
Програмно-аппаратная конфигурация:
CPU: Intel Core 2 Duo E8200 2.66 Ghz @ 3.6 Ghz 450.0 FSB * 8.0.
RAM: Corsair XMS2 5-5-5-18 800Mhz @ 900Mhz 5-6-6-21. FSB:MEM = 1:2
MB: Gigabyte GA P35DS3L (BIOS неизвестен – никогда не изменялся.)
GPU: Saphire Radeon HD5870 1GB GPU Clock = 850 Mhz Memory Clock = 4800(1200 Phys).
PSU: Cooler Master Elite 333 Stock PSU 450 Wt.
OS: Windows 7 Ultimate x86
FASM: 1.67 recompiled by MadMatt(Matt Childress).
Ссылки:
http://users.egl.net/talktomatt/default.html
http://programmersforum.ru/showthread.php?t=55270 – тема, где можно найти программу для тестирования времени выполнения.
Автор данной программы некто bogrus. Его профиль есть на форуме WASM.RU но, он неактивен уже 3-й год.
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
30th
Апр
Что, где, когда или с чего начать программировать?
Многие хотят стать программистами или же улучшить свои познания в этом увлекательном занятии. Но, как только человек хочет начать, что-то осваивать, перед ним встает вопрос: «…а с чего начать?». Собственно в данной статье, я попытаюсь ответить на этот распространенный вопрос.
Что, где, когда или… с чего начать программировать?
Пискунов Денис
by spamer www.programmersforum.ru
В связи с тем, что в Интернете, да и не только в нем, довольно часто можно встретить людей, которые далеки от программирования, но желают постигнуть его и которые знают некоторые азы сего занятия, но не знают, что им делать дальше, я и пишу данную статью.
«В первый раз – в первый класс»
Для начала, человеку желающему научиться программировать, необходимо скачать/купить книгу по какому-то языку программирования. Я бы советовал для начала скачать электронную книгу, потому-что вдруг вам это занятие не понравится, а деньги на бумажную версию будут уже потрачены. Теперь давайте определимся с языком.
Многие, уже знающие люди, начинают спорить на счет-того, какой язык лучше выбрать начинающим для изучения. Но в нашем случае, я спорить ни с кем не буду, а просто посоветую для начала выбрать язык программирования Pascal. С чем связан такой выбор? Да все очень просто, начинающему будет намного проще понять логику работы программы (алгоритма) в Pascal’е, чем скажем, например в С++ или Assembler.
Так, с языком определились. Теперь вернемся к выбору книги. Как в интернете, так и на прилавках магазинов, лежит огромное количество разнообразной литературы по программированию. А какой-же учебник скачать/купить нам? Скажу сразу, ни в коем случае не покупайте книги типа «Программирование для чайников». Полезного из такой брошюры вы не возьмете ничего, а вот представление о программировании, после ее прочтения, у вас будет неправильное, а то и вообще пугающее. Собственно по Pascal’ю советую следующие материалы и учебники [1-4]. В данной литературе предоставляется хорошее и понятное описание структуры языка, команд, структур данных и т.д. Также присутствуют примеры решения задач и задания для самостоятельного выполнения.
Выбираем среду разработки [5-7]
С языком и обучающим материалом определились. И вот теперь осталось выбрать и установить среду для написания программы или как правильнее – «Интегрированную среду разработки» (IDE, Integrated development environment). Собственно, что представляет собой IDE? Попросту, это набор программных средств, при помощи которых программист разрабатывает программное обеспечение. Так как изучать мы будем чистый Pascal, то и приложения мы будем писать консольные, посему я советую следующую среду разработки – Turbo Pascal 7.0 и кросс-платформенный компилятор FreePascal. Конечно, можно выбрать и что-то современнее, например TurboDelphi, Delphi 2010 или альтернативный Geany. Но для новичка в программировании, я считаю – это будет неправильно, так как в IDE Delphi увидеть логику работы программы, структуру языка и т.д., будет тяжело.
После вот таких приготовлений – садимся читать выбранную книгу, и хочу заметить, не просто читать, а читать, запоминать и разбираться в написанном. Если будете просто читать книжку, то вы потратите свое время в пустую. Поэтому, после получения некоторого теоретического материала, обязательно необходимо все полученные знания закрепить на практике. А точнее – садимся и пишем свою первую программу… Hello World J. Справились с этой задачей, ставим себе новую и реализуем, не знаете, что себе задать – в учебниках есть практические задания. После прочтения книги и при имеющихся знаниях – сделайте свой собственный не большой проект, например «Телефонный справочник», «вариант игрушки» и т.д.
Далее, после того, как вы чувствуете, что довольно хорошо владеете изученным языком, а возможно и уже некой технологией, необходимо решить для себя: «…а нравится-ли мне данная отрасль программирования?». Для ответа на этот вопрос, с помощью любого поисковика ищем информацию о следующих, так сказать, видах программирования:
. системное программирование
. прикладное программирование
. веб – программирование
После прочтения соответствующей информации и при уже имеющихся знаниях в программировании – вы должны выбрать дальнейший вид поля своей деятельности. Если вы определились, тогда начинайте углубленное изучение* выбранного направления.
* Помимо чтения литературы, также желательно общаться на соответствующих форумах. Например, выберите для себя один или два форума и, так сказать – «живите на них». На таких ресурсах Интернета можно довольно много узнать полезной информации, поделиться с кем-то такой-же информацией. Также всегда можно попросить помощи у профессионалов, например, что бы вам объяснили непонятный момент при изучении.
Вот еще такой нюанс – не надо думать, что программирование заключается только в знании языков программирования. Если вы хотите стать действительно хорошим программистом, то вам обязательно нужно знать дополнительные технологии. Например, можно полностью посвятить себя изучению программирования графики, попутно ознакомиться с разнообразными графическими библиотеками, алгоритмами, связанными с графикой и т.д. Следовательно, для достижения каких-либо целей, вам всегда необходимо читать соответствующую литературу, а также запомнить один из основных моментов – научиться пользоваться поиском. Так как большинство вопросов уже обсуждалось в Интернете, то правильный запрос в поисковую систему даст вам интересующий ответ.
Заключение
И не бойтесь спрашивать знающих людей о том, что не знаете сами – ничего предосудительного в этом нет. В общем, не надо ждать доброго дяденьку, который придет, все Вам разжует и в рот положит, а начинайте сами достигать поставленной цели. Так что, дерзайте.
Ресурсы
. Т.А. Павловская. Паскаль. Программирование на языке высокого уровня: практикум. – С.Петербург, Питер
-Юг, 2003
. Валерий Попов. Паскаль и Дельфи. Самоучитель. – С.Петербург, Питер, 2003
. В.В. Фаронов. Turbo Pascal 7.0. Начальный курс: учебное пособие. – М., КноРус, 2007
. А.Я. Архангельский. Язык Pascal и основы программирования в Delphi. – М., Бином-Пресс, 2008
. Скачать компилятор FreePascal http://www.freepascal.org/download.var
. Скачать компилятор Geany http://download.geany.org
. Скачать компиляторы DELPHI http://delphilab.ru
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Что, где, когда или… с чего начать программировать?
30th
Изменения в языке Дельфи 2010
Задача предназначена для представления краткого обзора нововведений в язык Дельфи (2010) по сравнению с Дельфи 7.
Изменения в языке Дельфи 2010
Utkin
Благодаря активным попыткам компании Embecadero влиять на рынок продуктов разработки программ язык Дельфи быстро развивается, однако это развитие направлено в основном на попытки наверстать все нововведения в современных языках программирования (таких как С#). Никаких принципиально новых разработок и концепций не внедряется.
Директива Inline (появилась в Дельфи 2005)
По аналогии с С++, функции и процедуры теперь могут быть встраиваемыми со всеми вытекающими последствиями. А именно использование данной директивы не гарантирует вставку тела функции вместо ее вызова. Кроме того, существует еще целый ряд ограничений (согласно справочной системе). Эта директива бесполезна:
. при позднем связывании (virtual, dynamic, message);
. для функций и процедур имеющих ассемблерные вставки;
. для конструкторов и деструкторов, там она работать не будет (о чем Вам компилятор обязательно пожалуется);
. для главного блока программы, секций инициализации и финализации модулей;
. если метод класса обращается к членам класса с более низкой видимостью, чем сам метод. Например, если public метод обращается к private методу, то для такого метода inline-подстановка осуществляться не будет;
. для процедур и функций, которые используются в выражениях проверки условия циклов while и repeat.
Как сделать процедуру встроенной?
Procedure Add (var x: Integer; y: Integer); Inline;
Регулировать поведение inline можно следующими директивами:
{$INLINE ON} – по умолчанию включена, разрешает работу Inline;
{$INLINE AUTO} – будет осуществлена попытка встраивание кода функций и процедур, если:
а) они помечены как Inline;
б) если их размер будет менее 32-х байт.
{$INLINE OFF} – не разрешает работу Inline.
Следует отметить, что и в классическом С++ Inline никогда не была высокоэффективным механизмом, а учитывая ограничения, накладываемые компилятором Дельфи, ее использование под большим вопросом.
Перегрузка операторов (появилась в Delphi.Net)
В отличие от С++ перегрузка осуществляется немного по-другому. Для перегрузки операторов перегружается не символ оператора, а его символическое обозначение (сигнатура). Перегружать можно только для операций с экземплярами классов.
Нужно обратить внимание – TRUNC, ROUND, INC, DEC считаются операторами, а не процедурами и функциями.
Вот пример использования:
TMyClass = class
class operator Add(a, b: TMyClass): TMyClass; // Перегрузка сложение для TMyClass
class operator Subtract(a, b: TMyClass): TMyclass; // Вычитание для TMyClass
class operator Implicit(a: Integer): TMyClass; // Неявное преобразование Integer в TMyClass
class operator Implicit(a: TMyClass): Integer; // Неявное преобразование TMyClass в Integer
class operator Explicit(a: Double): TMyClass; // Явное преобразование Double в TMyClass
end;
// Пример описание сигнатуры Add для перегрузки сложения для типа TMyClass
TMyClass.Add(a, b: TMyClass): TMyClass;
begin
…
end;
var
x, y: TMyClassbegin
x := 12; // Неявное преобразование из Integer
y := x + x; // Вызов TMyClass.Add(a, b: TMyClass): TMyClass
b := b + 100; // Вызов TMyClass.Add(b, TMyClass.Implicit(100))
end;
Подробней о перегрузке операторов можно почитать здесь: http://www.realcoding.net/articles/delphinet-peregruzka-operatorov.html
Помощники класса (Class Helpers)
Интересный механизм (ответ Дельфи на расширители классов в С#), призванный решить некоторые проблемы в обход наследования. Служит для дополнения класса новыми методами и свойствами.
type
TMyClass = class
procedure MyProc;
function MyFunc: Integer;
end;
…
procedure TMyClass.MyProc;
var
X: Integer;
begin
X := MyFunc;
end;
function TMyClass.MyFunc: Integer;
begin
…
end;
…
type
TMyClassHelper = class helper for TMyClass
procedure HelloWorld;
function MyFunc: Integer;
end;
…
procedure TMyClassHelper.HelloWorld;
begin
WriteLn(Self.ClassName); // Здесь будет возвращен тип TMyClass, а не TMyClassHelper
end;
function TMyClassHelper.MyFunc: Integer;
begin
…
end;
…
var
X: TMyClass;
Begin
X := TMyClass.Create;
X.MyProc; // Вызов TMyClass.MyProc
X.HelloWorld; // Вызов TMyClassHelper.HelloWorld
X.MyFunc; // Вызов TMyClassHelper.MyFunc
end;
По сути, вариация на тему множественного наследования, но есть одна особенность – помощники класса позволяют дополнять любой существующий класс, без создания нового. Обратите внимание, что механизм помощника класса не использует явного упоминания Self при обращении к полям класса (помогаемого класса). То есть, HelloWorld имеет право обращаться к полям TMyClass (просто в нашем примере их нет). Аналогично TMyClass также имеет доступ к полям TMyClassHelper (в случае, если класс и его помощник объявлены в одном модуле).
С практической точки зрения удобный механизм, кроме одной детали – класс должен иметь только одного помощника, имеет ли он помощника проверить во время выполнения программы нельзя. Если в классе имеется несколько помощников (неважно в каком юните, лишь бы он видел класс), считаться рабочим будет только самый последний из объявленных. Это значит, что если TMyClass уже имел помощника, то будут доступны методы именно TMyClassHelper, поскольку именно он объявлен последним. Таким образом, в лучшем случае, два и более помощника для одного класса вызовут ошибку компиляции, в худшем трудно отлавливаемую ошибку, жалобы программиста на багги в IDE и компиляторе и много потерянного времени. Чем сложней проект, тем трудней будет установить причину ошибки.
С теоретической точки зрения механизм противоречивый – он увеличивает сцепляемость объектов и юнитов между собой. Перед использованием помощника, я должен проверить все модули, из которых доступен данный класс на предмет проверки существования такого помощника (представьте большой проект). Это нарушает принципы инкапсуляции – если раньше перед использованием класса нужно было знать только его интерфейс, то теперь для использования помощников, я должен отслеживать существование класса во всех модулях, где имеется доступ к данному классу. С этого момента механизм интерфейсов уже не играет особой роли, поскольку, обращаясь к объекту какого-либо класса, всегда можно обнаружить такой букет неизвестных методов, что интерфейсная часть класса становится даже вредной. Это нарушает принцип сокрытия данных – благодаря помощникам я могу менять работу своих и чужих классов и могу иметь доступ к его полям (в рамках юнита). Кстати, это ограничение на доступ к полям в рамках юнита также сводит на нет многие его плюсы – проще вписать новые методы в сам класс (или наследовать новый), чем создавать путаницу в классе, юните и проекте.
Записи стали объектами
И теперь имеют свои методы, свойства и конструкторы.
type
TMyRecord = record
type
TInnerColorType = Integer;
var
Red: Integer;
class var
Blue: Integer;
procedure printRed();
constructor Create(val: Integer);
property RedProperty: TInnerColorType read Red write Red;
class property BlueProp: TInnerColorType read Blue write Blue;
end;
constructor TMyRecord.Create(val: Integer);
begin
Red := val;
end;
procedure TMyRecord.printRed;
begin
writeln(’Red: ‘, Red);
end;
Но, сокращенная запись по-прежнему разрешена (поэтому старые проекты должны переноситься и с сокращенной формой записей).
Абстрактные классы
type
TAbstractClass = class abstract
procedure SomeProcedure;
end;
Разрешены полностью абстрактные классы (раньше допускались только конкретные методы), содержащие объявления методов для дальнейшего их перекрытия в потомках.
strict private и strict protected
Строгое private – метод или свойство для класса и невидимое никому, вне класса даже в рамках текущего юнита.
Строгое protected – методы в этой секции будут видимы самому классу и его наследникам.
Таким образом, полное объявление выглядит теперь так
type
TKlass = class(TForm)
strict protected
protected
strict private
private
public
published
automated
end;
Не наследуемые классы
По аналогии с С#, в Дельфи 2010 существуют классы от которых дальнейшее наследование невозможно:
type
TAbstractClass = class sealed
procedure SomeProcedure;
end;
Весьма сомнительное удовольствие для рядового разработчика. Никаких реальных преимуществ такой класс не дает. Точные причины создания такого механизма не известны и преимущества от его использования очень призрачны – наследование не разрушает класса предка, поэтому и запечатывать их особой необходимости нет. Считается, что запечатанные классы работают быстрей обычных (сам не проверял) и они применяются для .NET платформы (сугубо в утилитарных целях – не все обертки над низкоуровневыми операциями, такими как WinApi, можно сделать наследуемыми).
Классовые константы (возникло в Delphi ![]()
Классы могут иметь константы – сами классы, а не порождаемые от них объекты.
type
TClassWithConstant = class
public
const SomeConst = ‘This is a class constant’;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
ShowMessage(TClassWithConstant.SomeConst);
end;
Классовые типы (возникло в Delphi ![]()
Класс может теперь содержать описание типа, которое можно использовать только в пределах данного класса.
type
TClassWithClassType = class
private
type
TRecordWithinAClass = record
SomeField: string;
end;
public
class var
RecordWithinAClass: TRecordWithinAClass;
end;
…
procedure TForm1.FormCreate(Sender: TObject);
begin
TClassWithClassType.RecordWithinAClass.SomeField := ‘This is a field of a class type declaration’;
ShowMessage(TClassWithClassType.RecordWithinAClass.SomeField);
end;
Еще одно сомнительное удовольствие. Описание типа это не конкретная структура, зачем прятать его описание в тело класса?
Классовые переменные (возникло в Delphi ![]()
Класс может содержать переменные по аналогии с константами:
Type
X = class (TObject)
Public
Var
Y: Integer;
End;
Пожалуй, единственное, где это может пригодиться это работа с RTTI, вообще классы в Дельфи стали больше напоминать юниты – такие вот юниты внутри юнитов. Обратите внимание, что переменные класса могут находиться в любой секции (секции в данном случае влияют на область видимости данных переменных), тогда как поля класса не могут быть public (в Дельфи 7 могли). Применение статических полей в классе делает Дельфи все более ориентированным в сторону С# (и менее в сторону Паскаля).
Вложенные классы
Теперь классы можно объявлять внутри классов, цель избежать конфликта имен, локализовать все связанные классы между собой:
type
TOuterClass = class
strict private
MyField: Integer;
public
type
TInnerClass = class
public
MyInnerField: Integer;
procedure InnerProc;
end;
procedure OuterProc;
end;
procedure TOuterClass.TInnerClass.InnerProc;
begin
…
end;
Классы все больше перенимают концепцию модулей. Понятно, что данное нововведение дань .Net, но реальной пользы от него опять же не очень много – раньше конфликта имен избегали префиксами A и F, не могу сказать, что новый механизм дал программистам новые возможности. Также как и попытка использовать вложенные классы для складывания всего в одну большую кучу наряду с помощниками классов сильно напоминают лебедь, рак и щуку, растаскивающие Дельфи в разные стороны.
Финальные методы класса
В классах можно создавать виртуальные методы, которые перекрыть нельзя:
TAbstractClass = class abstract
public
procedure Bar; virtual;
end;
TFinalMethodClass = class(TAbstractClass)
public
procedure Bar; override; final;
end;
Переопределить «Bar» уже больше нельзя.
Статические методы класса
У классов могут быть статические методы класса – то есть методы, которые можно вызвать от типа класса. Такие методы не имеют доступа к полям класса (также как и не могут получить Self на конкретный экземпляр данного класса):
type
TMyClass = class
strict private
class var
FX: Integer;
strict protected
// Note: accessors for class properties must be declared class static.
class function GetX: Integer; static;
class procedure SetX(val: Integer); static;
public
class property X: Integer read GetX write SetX;
class procedure StatProc(s: String); static;
end;
TMyClass.X := 17;
TMyClass.StatProc(’Hello’);
Здесь же представлен пример организации свойств классов. Их использование полностью аналогично использованию переменных и констант класса.
for-element-in-collection
Теперь компилятор способен распознавать итерации в контейнерах:
for Element in ArrayExpr do Stmt;
for Element in StringExpr do Stmt;
for Element in SetExpr do Stmt;
for Element in CollectionExpr do Stmt;
Вот развернутый пример:
var
A: Array [1..6] of String;
I: String;
….
for i in A do
begin
Memo1.Lines.Add(i);
end;
Обратите внимание, что I имеет тип String это не индекс массива, а конкретные значения, которые будут получаться из массива. Кое-где конечно автоматизирует, но представьте, что мне нужно написать некий метод, в котором происходит копирование одного массива в другой. Использовать все равно придется стандартный цикл for, либо писать еще один метод – добавление элемента в массив.
Динамическая инициализация массивов
Теперь массивы получили свои конструкторы:
Type
TMas = Array of String;
Var
Mas: TMas;
Mas := TMas.Create(‘Hello’, ’World’, ’!’);
Я, конечно, не против «Create» как конструктора по умолчанию, но уже сейчас из-за отсутствия внятной русскоязычной литературы по данной теме встречаются статьи, в которых авторитетные господа пишут, что конструктор обязательно должен называться Create (речь идет не только о массивах, но также о записях и конструкторах класса). Так вот конструктор должен называться Create только для массивов. Для всех остальных имя конструктора не обязательно должно быть Create (но желательно, особенно для классов).
Дженерики
Шаблоны, они и в С++ шаблоны. Считается что первые шаблоны возникли в С++, но вообще-то они пришли из функционального программирования и правильное их название параметрический полиморфизм. Явление, когда компилятор сам вырабатывает соответствующие варианты кода на основании обобщенного алгоритма:
TList<T> = class
private
FItems: array of T;
FCount: Integer;
procedure Grow(ACapacity: Integer);
function GetItem(AIndex: Integer): T;
procedure SetItem(AIndex: Integer; AValue: T);
public
procedure Add(const AItem: T);
procedure AddRange(const AItems: array of T);
procedure RemoveAt(AIndex: Integer);
procedure Clear;
property Item[AIndex: Integer]: T read GetItem write SetItem; default;
property Count: Integer read FCount;
end;
Вот пример списка содержащего произвольные (но однотипные элементы). Тип элементов определяется на момент объявления переменной:
ilist: TList<Integer>;
То есть мы создали список целых чисел (а можно, к примеру, список строк). Дженерики удобно использовать применительно к алгоритмам контейнеров данных и комбинаторным алгоритмам. Конкретные реализации алгоритмов можно посмотреть в модуле Generics.Collections, где есть TArray, TList, TStack, TQueue, TDictionary, TObjectList, TObjectQueue, TObjectStack, TObjectDictionary и TEnumerator, способные работать с разными типами данных.
Также необходимо отметить особенность дженериков (и шаблонов в С++) – обобщенные алгоритмы экономят время программиста, сокращая только его код, но для каждого типа (для каждой комбинации типов) всегда генерируется новая версия алгоритма (поэтому размер скомпилированных программ увеличивается).
Заключение
Большинство механизмов представленных здесь:
. обеспечивают совместимость с .NET
. дань моде
. попытка угнаться за Microsoft Visual Studio
Язык не содержит принципиальных отличий и мощных механизмов, которые действительно были бы востребованы именно программистами на языке Дельфи. Все нововведения навязаны, искусственны и не всегда соответствуют концепциям ООП. Большое количество противоречивых инструментов может только запутать программистов и в течение ближайших лет можно ожидать некоторого количества критических статей в адрес языка программирования Дельфи.
Комментарий автора
Личные впечатления о среде сложились следующие: сплошные недоделки (да и в 2009-м не лучше), ждать следующую версию наверно не стоит. FrameWork идет в комплекте, ничего доустанавливать не надо. Несмотря на заявленные требования не ниже 1 гигабайта ОЗУ, у меня и при 512-ти с тормозами, но работает.
Ресурсы
. Хроники «айтишника» http://skiminog.livejournal.com/33610.html
. Общество разработчиков Embecadero http://edn.embarcadero.com
. Углубленный материал по перегрузке операторов в Дельфи http://www.realcoding.net/articles/delphinet-peregruzka-operatorov.html.
. Онлайн-перевод англоязычных материалов статьи http://www.translate.ru
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
29th
Апр
Рабство программистов
Статья посвящена стереотипному мышлению о высокой эффективности имеющихся механизмов ООП. Для программистов использующих ООП языки. Цель статьи дать углубленное представление о базовых концепциях объектно-ориентированного программирования.
Рабство программистов
ООПрограммист – рядовой муравей, увеличивающий всемирную энтропию путем написания никому не нужного кода
http://absurdopedia.wikia.com/wiki/ООП
Атор Utkin
Каждый из тех, кто знаком с принципами ООП, прекрасно знает о тех преимуществах, удобствах и больших плюсах, которые оно представляет программистам. Но так ли это на самом деле? Все познается в сравнении, преимущества по сравнению с чем?
Что такое ООП?
Да, что такое ООП? Несмотря на значительное время существования данной концепции точного определения ООП не существует и по сей день. Есть определения ООП в рамках конкретных языков программирования, но все они различны, имеют свою терминологию, механизмы использования, особенности реализации и т.д. Любой учебник по ООП даст Вам либо определение в привязке к языку программирования, либо весьма туманное объяснение или же вовсе, с места в карьер, речь пойдет о принципах, определениях класса и объекта и т.д.
Не имея точного определения обучаемый, словно Алиса проваливается в кроличью нору нового для него мира. Особенно остро это ощущается, если уже имел навыки программирования. Но ощущения субъективны, рассмотрим основные концепции ООП под другим углом зрения.
Базовые понятия ООП
Их все знают, это:
. инкапсуляция
. наследование
. полиморфизм
Сейчас также добавляют еще понятие абстракции данных. Рассмотрим их всех по порядку…
Инкапсуляция – это принцип, согласно которому любой класс должен рассматриваться как чёрный ящик — пользователь класса должен видеть и использовать только интерфейсную часть класса (т. е. список декларируемых свойств и методов класса) и не вникать в его внутреннюю реализацию. Поэтому данные принято инкапсулировать в классе таким образом, чтобы доступ к ним по чтению или записи осуществлялся не напрямую, а с помощью методов. Принцип инкапсуляции (теоретически) позволяет минимизировать число связей между классами и, соответственно, упростить независимую реализацию и модификацию классов (определение взято из Википедии http://ru.wikipedia.org/wiki/Объектно-ориентированное_программирование).
Но, инкапсуляция не ноу-хау ООП, она существовала и ранее – это обычное описание функций и процедур. Пример на Паскале:
Function Sum (a, b: Integer): Integer;
Begin
Result := a+b
End;
Чтобы использовать функцию мне не обязательно знать, как она устроена (и в ряде случаев такое знание даже противопоказано), достаточно лишь описание интерфейса Function Sum (a, b: Integer): Integer; Я должен знать, что имя функции Sum, она принимает два параметра типа Integer (важен также порядок их следования), возвращает также Integer, а вот каким образом проводится сложение это уже совершенно безразлично. Еще пример:
Type
TMas = record
Data: Array of Integer;
Count: Integer;
End;
Procedure Sort (var Mas: TMas);
Теперь чтобы отсортировать такой вот массив, мне не нужно знать, как он устроен, сколько в нем элементов и т.д. Я просто передам его процедуре Sort.
Так чем же примечательна инкапсуляция? Справедливости ради, надо отметить, что инкапсуляция как описание указанного выше явления получило признание только в ООП. Потому что такое определение там является одним из главных особенностей построения программ. Никаких преимуществ, в сравнении с теми же структурным или функциональным программированиями, инкапсуляция в ООП не несет.
Однако на этом инкапсуляция не заканчивается:
Сокрытие данных (взят из книги Тимоти Бадд «ООП в действии») – неотделимая часть ООП, управляющая областями видимости. Является логическим продолжением инкапсуляции. Целью сокрытия является невозможность для пользователя узнать или испортить внутреннее состояние объекта. Но это тоже существует в структурном программировании:
Function fact(x: integer): integer;
var
i, n: Integer;
begin
n:=1;
for i:=1 to x do
begin
n:=n*i;
end;
fact:=n;
end;
Разве я могу получить доступ к i и n не в рамках данной функции? Также стоит еще раз внимательно почитать определение – невозможность для пользователя. Если речь идет о программисте, то он испортить может все и вся и никакое сокрытие данных Вам не поможет, по одной простой причине – раз имеются данные, то также и имеются некоторые механизмы для их использования. Поэтому область видимости не защищает данные от ошибок в методах данного класса. Пример на Дельфи:
Type
MyClass = class (TObject)
Protected
MyData: TStringList;
Private
Public
Constructor Create;
Destructor Destroy;
End;
Constructor MyClass.Create;
Begin
Inherited Create
End;
Destructor MyClass.Destroy;
Begin
Inherited Destroy
End;
Опытный программист уже догадался, о чем идет речь – любое обращение к MyData вызовет ошибку, поскольку перед использованием такие объекты нуждаются в инициализации (между прочим одна из распространенных ошибок начинающих программистов). Так что же дают игры с областями видимости?
Если же говорить о методах других объектов, то доступа к MyData они не получат, но согласно принципам ООП они и не должны его получать. Иными словами MyData никогда не должен находиться в секции Public (кстати, Дельфи это позволяет). Доступ к полям класса всегда должен осуществляться через методы либо свойства.
То есть здесь должна быть аналогия с функциями и процедурами структурного программирования – объявление структур данных должно осуществляться аналогично секции var. Это очень важный момент – сокрытие данных в рамках ООП предназначено для программирования программиста, а не реализации алгоритма. Я говорю о сокрытии данных, потому что я боюсь допустить ошибку, которая в рамках структурного программирования не может возникнуть в принципе. Компилятору безразлично, в какой секции находится поле, он выдаст код в любом случае (речь идет о Дельфи версии 7), все ограничения видимости введены для программиста.
Если Вы думаете, что в С++ это невозможно, то сильно ошибаетесь и виной тому указатели (а в С++ указатели не менее важный механизм, нежели механизмы ООП). Имея указатель на класс, можно не только прочесть его приватные поля, но и модифицировать их.
Class Sneaky
{
private:
int safe;
public:
// инициализировать поле safe значением 10
Sneaky () { safe = 10; }
Int &sorry() { return safe; }
}
И далее:
Sneaky x;
x.sorry () = 17;
Инкапсуляция тесно связана с таким понятием как абстрагирование. Это придание объекту характеристик, которые отличают его от всех других объектов, четко определяя его концептуальные границы. Основная идея состоит в том, чтобы отделить способ использования составных объектов данных от деталей их реализации в виде более простых объектов. И здесь снова модули и структуры решают эту задачу без участия ООП – интерфейсы функций, процедур и модулей могут полностью скрывать внутреннее представление по реализации тех или иных задач. Сомневаетесь? Вот пример взаимодействия модулей (Дельфи). Поместите на форму одну кнопку:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, Unit2, StdCtrls;
type
TForm1 = class(TForm)
Button1: TButton;
procedure Button1Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.Button1Click(Sender: TObject);
begin
AddX();
Button1.Caption:=IntToStr(GetX());
end;
////////////////////////////////////////////////////////////////////////////////
procedure TForm1.FormCreate(Sender: TObject);
begin
Init();
end;
////////////////////////////////////////////////////////////////////////////////
end.
И подключите второй модуль:
unit Unit2;
interface
procedure Init();
procedure AddX();
function GetX(): Integer;
implementation
var
x: Integer;
procedure Init();
begin
x:=0;
end;
////////////////////////////////////////////////////////////////////////////////
procedure AddX();
begin
x:=x+1;
end;
////////////////////////////////////////////////////////////////////////////////
function GetX(): Integer;
begin
result:=x;
end;
////////////////////////////////////////////////////////////////////////////////
end.
Выполните программу, понажимайте на кнопку. Теперь попробуйте получить доступ к Х без использования функций и процедур из Unit2. Модуль хранит в себе данные, скрывает их представление и ограничивает к ним доступ. При этом в Unit2 нет и намека на класс (и не думайте, что Вы сможете прочесть или изменить Х обычными процедурами и функциями Unit1 (не из формы)).
Наследование
один из четырёх важнейших механизмов объектно-ориентированного программирования, позволяющий описать новый класс на основе уже существующего (родительского), при этом свойства и функциональность родительского класса заимствуются новым классом. Не то чтобы я не согласен с таким определением, но давайте посмотрим очередной пример:
Type
TMas = record
Data: Array of Integer;
Count: Integer;
End;
Type
TGroupMas = record
Data: Array of TMas;
Count: Integer;
End;
Procedure Sort (var Mas: TMas);
Разве для построения TGroupMas я не опираюсь на TMas? Я ведь мог написать определение TGroupMas с нуля, но в моем случае каждый элемент массива Data структуры TGroupMas является ни кем иным как TMas. Более того, мне ничего не стоит написать процедуру сортировки указанного элемента TGroupMas. Все что требуется это лишь правильно передать параметры процедуре Sort.
Таким образом, я описываю новую структуру TGroupMas данных на основании существующей TMas и я мог создать процедуру сортировки элемента массива на основании Sort:
Procedure SortItem (var GropuMas: TGroupMas; Index: Integer);
Begin
Sort (GroupMas.Data[Index]);
End;
При этом согласно определению наследования, я заимствую все свойства TMas и функциональность Sort; и все это в рамках структурного программирования, никакого ООП для этого не требуется. Вот пример, который часто любят давать в учебниках ООП (язык программирования Дельфи):
Type
TMaterial = record
Massa: Integer;
End;
Type
TAnimal = record
Material: TMaterial;
Sort: String;
End;
Type
TMamal = record
Animal: TAnimal;
Family: String;
End;
Type
THuman = record
Mamal: TMamal;
Race: String;
Floor: String;
Name: String;
Family: String;
End;
Type
TProgrammer = record
Human: THuman;
Sertificate: String;
End;
Type
TProgrammer_of_Pascal = record
Programmer: TProgrammer;
IDE: String;
End;
И пусть в меня «кинут камнем», если программист в данной иерархии не является млекопитающим и не обладает его свойствами (имеет массу, принадлежит к определенному виду).
Для использования механизма наследования не требуется использование объектно-ориентированного программирования. Достаточно, чтобы язык имел возможность организации структур данных определяемых программистом.
Множественное наследование полностью аналогично – я могу определить новую структуру – цвет глаз и включить ее в TMamal и тогда программист обретет новые свойства. Кстати, множественное наследование одна из самых известных мозолей ООП, но именно поэтому о ней мы больше упоминать не будем. Цель данной статьи как раз показать те, моменты, о которых говорить не любят.
Полиморфизм
взаимозаменяемость объектов с одинаковым интерфейсом. Язык программирования поддерживает полиморфизм, если классы с одинаковой спецификацией могут иметь различную реализацию — например, реализация класса может быть изменена в процессе наследования. Кратко смысл полиморфизма можно выразить фразой: «Один интерфейс, множество реализаций».
Можно сказать, что полиморфизм одна из самых загадочных концепций ООП. Итак, в некотором роде полиморфизм тесно связан с наследованием. Вы получаете некоторые методы от родительского класса и можете переопределить их функциональность. Адекватного механизма в структурном программировании не существует, но какие собственно выгоды дает полиморфизм? Итак, это выглядит следующим образом – некий класс (допустим программист) имеет в своем составе метод (допустим, пить чай). Программист на Яве переопределяет метод и пьет чай марки Ява под именем метода пить чай. То есть мы подразумеваем, что когда программист на Ява пьют чай, то он пьет чай марки Ява. Стандартно, формально, но теперь вопрос, какие в этом плюсы?
. уменьшение сложности программ;
. позволяет повторно использовать один и тот же код;
. позволяет использовать в потомках одинаковые имена методов для решения схожих задач.
Не густо, ну что, рассмотрим каждый пункт:
0 – честно говоря, так и не увидел, в чем это выражается (хотя упоминается об этом практически везде), концепция структур и модулей достаточна для решения всех задач, которые могут быть решены полиморфизмом. С другой стороны, многочисленные одноименные методы усложняют программу. Результатом полиморфизма являются объекты, которые имеют и одноименные методы и могут работать с разными типами данных. Использование одноименных методов в таком случае не так тривиально, как хотелось бы. Пришлось срочно создавать новую концепцию (вернее сказать, воровать концепцию, поскольку ООП суть ряда заимствований от других парадигм) – RTTI. Проще всего ее можно представить как информацию о типе объекта во время выполнения программы. То есть перед запуском нужного метода используется явное определение того типа данных, с которым предстоит работать. Обычно такая ситуация возникает только в сложных программных объектах, но и полиморфизм в объектах с несложным поведением не имеет смысла и может быть заменен даже обычными операторами селекторами (например case в Дельфи) и введением дополнительных переменных. Более того, RTTI перечеркивает абстрагирование – для решения задачи динамически знать тип данных противопоказано, это увеличивает сцепляемость объектов – их сложней заменять, переносить, модернизировать. RTTI также уменьшает такую возможность полиморфизма, как использование обобщенных алгоритмов (о параметризации речь ниже).
1 – об этом уже упоминалось:
Procedure SortItem (var GropuMas: TGroupMas; Index: Integer);
Begin
Sort (GroupMas.Data[Index]);
End;
Я же не пишу функцию сортировки снова, просто передаю ей нужные параметры. На лицо явное использование уже существующего ранее кода и совершенно без единого класса, поэтому никакого преимущества в сравнении скажем с функциональным программированием здесь нет. Если же речь идет о параметризации, то с каждым новым набором параметров генерируется новая версия этой же функции, поэтому код в таком случае используется не повторно, а каждый раз новый.
2 – Я тоже могу написать кучу модулей для решения каждой задачи (все равно в классах каждое решение надо описывать явно) и вызывать их одноименные функции также через точечный синтаксис (в Дельфи), только в обратном порядке – имя_функции.имя_модуля. И я бы не сказал, что сильно путаюсь в программе, если однотипные действия названы по-разному (причем без разницы два у меня метода или десяток). Если имеется достаточно полное описание методов (те самые интерфейсы, которые ООП также считает своим достижением), и они имеют осмысленные имена, то никаких проблем между вызовом метода ProgrammTea и ProgrammJavaTea не возникает. ООП полностью игнорирует такие подходы как правильное оформление кода и правила именования объектов (хотя в нем же использование одноименных методов считается плюсом).
Организация тысячи то же что и организация одного. Это вопрос организации (Конфуций).
Кроме того, я не считаю, что выбор нужного метода осуществляется компилятором – все действия жестко прописаны в каждом классе, а поскольку любой класс является еще и типом, то он ничего не выбирает, выбирает программист в каком классе, какой чай должен пить объект-программист на этапе переопределения родительского метода. Вот я бы задал список методов вообще без привязки к конкретному классу, просто как набор функций и процедур в отдельном модуле, а уж компилятор сам вызывал бы соответствующий метод, тогда я бы согласился с этим утверждением на все 100. Далее в современные библиотеки классов, обычно содержат более 100 классов, которые могут содержать десятки методов, и все их держать в голове никакой полиморфизм еще никогда не помогал… Без разницы сколько мне надо знать 1000 методов или 10 000, все равно их все помнить в любой момент времени нет необходимости.
Что касается параметризации это действительно мощный механизм, но с теми же симптомами – это не универсальный рецепт, то есть имеет смысл его применять только в ряде случаев (часть из которых может быть решена комбинаторными алгоритмами) и преимущественно к простым типам. Вот пример алгоритма (С++):
// Описание шаблонной функции
template <typename T> T max(T x, T y)
{
if (x < y)
return y;
else
return x;
}
Не трудно догадаться, что она возвращает максимальный элемент из двух указанных, но только в том случае, если программист сможет описать строгое и однозначное сравнение объектов, то есть удобно для типов, которые по умолчанию поддерживаются транслятором. Для сложных типов, определяемых программистом параметризация не дает никаких преимуществ в сравнении с традиционными подходами. Весьма проблематична параметризация, когда в качестве типа выступают объекты классов, хотя, казалось бы, их строгая иерархия, наследование полей и полиморфизм должны как раз способствовать написанию обобщенных алгоритмов для работы с такими типами. Да это возможно, но требует тщательного продумывания иерархии и написание индивидуальных методов для каждого класса может оказаться предпочтительней.… Здесь решение аналогично RTTI, но проблема не в ООП, это попытка перешагнуть через строгое ограничение типов (наряду с типом Variant в Дельфи). Можно провести следующую аналогию – сначала перед бегуном понаставили барьеров и сказали, что теперь он будет учувствовать в беге с препятствиями, а потом пытаются научить его прыгать, выдают ему специальные кроссовки, рекомендуют методики тренировки…
Также не все гладко с перегрузкой операторов – трансляторы языков программирования часто не могут предоставить нужные средства идентификации перегруженных операторов (а те, что могут, сложны и не так эффективны, порождают большой и медлительный код), что вызывает двусмысленность в толковании всего выражения. Самый простой пример операция – (вычитание), дело в том, что она существует как минимум в двух видах это унарная операция и бинарная — -х и х-y (а в некоторых языках есть еще ее различные формы – инфиксная, постфиксная и т.д.). Далее, необходимо определить приоритет операции, скажем, для строк определение подобных операций может быть не так очевидно, как для чисел. Не думайте что сложение в этом случае лучше. Например, сложение строк x + y не эквивалентно y + x.
Также перегрузке свойственны общие беды полиморфизма – она не является обязательным элементом программирования (это значит, что нет алгоритмов, которые невозможно реализовать без использования перегрузки), и может привести к обратному результату – не упрощению, а усложнению программы. Подобно механизму RTTI перегрузка увеличивает связность кода – для понимания работы перегруженного оператора требуется знать тип объекта (или требуется его уточнение для понимания программистом) используемого в конкретной строке кода, отсюда всякие болячки – уменьшение переносимости, сложности при модификации отдельных объектов и т.д.
Это еще один пример, когда не программист создает алгоритм, а язык программирует программиста – Вы должны следовать этому принципу, так как это приносит некоторые удобства, но при этом все умалчивают о том, что это не гарантия преодоления нарастающей сложности программ (и более того, такой механизм сам может являться источником усложнения программы). И еще один момент – полиморфизм не обязательная черта ООП. Это значит, что если Вы напишите программу, использующую классы и объекты, но не использующую полиморфизм, то это все равно будет ООП. Кроме того, если Вам не хочется отказываться от полиморфизма, его можно имитировать в рамках модулей (юнитов) программ.
Что еще, не так как надо
ООП «вещь в себе», и оно не вписывается в ряд задач – например механизм подключения DLL. Да, функция или процедура возвращает значение, но какого типа? Это отследить невозможно (и RTTI Вам не помощник). ООП очень плохо подходит для парсинга структурированных текстов (например, программ) в сравнении с функциональным программированием. ООП не дружит с рекурсией (не то чтобы она там не возможна, просто не эффективна в сравнении с тем же функциональным программированием), которая позволяет упростить представление многих задач. Также нужно учитывать, что программа, составленная без ООП, как правило, быстрей, чем с ним. ООП официально не поддерживает концепцию ленивых вычислений (вообще это черта языков функционального программирования) – потенциальное увеличение производительности, упрощение решения ряда задач.
Итоги
Данная статья вовсе не призывает отказываться от принципов ООП, задача дать более полное представление об некоторых аспектах ООП. Без понимания этих моментов программисты уверены, что ООП существенный шаг вперед (на самом деле существенный шаг вперед – обширные библиотеки, которые в свете новых веяний написаны в стиле ООП), хотя возможно, всего лишь шаг в сторону…
Возьмите параметризацию – не стоит возлагать на нее большие надежды, она существует уже давно в том или ином виде в функциональном программировании (как и весь полиморфизм во всех его проявлениях) и пока не принесла кардинальных изменений в деле создания программ.
Список использованной литературы
. Тимоти Бадд. Объектно-ориентированное программирование в действии. – С.Петербург, Питер, перевод
по лицензии издательства Addison Wesley, 1997
. Г. Шилдт. Теория и практика С++. – С.Петербург, БХВ-Петербург, 2001
. Раздел википедии http://ru.wikipedia.org/wiki/Объектно-ориентированное_программирование
. Раздел абсурдопедии http://absurdopedia.wikia.com/wiki/ООП
. Э. Хювенен, И. Сеппянен. Мир Лиспа. – М., перевод с финского изд.Мир, в 2-х томах, 1990
. Ф. Брукс. Серебряной пули не существует. – М., Символ-Плюс, 1995, юбилейное издание первой книги
1987 года, перевод по лицензии издательства Addison Wesley
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
