

Последние записи
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы
- Склеить несколько файлов в один

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
12th
Май
 Введение в SSE
Введение в SSE
SSE – FPU XXI века
Автор: Ivan32
Аннотация:
В данной статье рассматриваются базовые принципы работы с расширением SSE.
Введение:
С момента создания первого математического сопроцессора(FPU) для х86-процессоров, прошло уже около 30 лет.
Целая эпоха технологий и физических средств их воплощения прошла, с тех пор, и нынешние FPU стали на порядок быстрее, энергоэффективней и компактней того первого FPU – 8087. С тех пор FPU стал частью процессора, что, конечно же, положительно сказалось на его производительности. Тем не менее, нынешняя скорость выполнения команд FPU оставляет желать лучшего.
К счастью это лучшее уже есть. Им стала технология под названием SSE.
Аппаратное введение:
SSE – Streaming SIMD Extensions – был впервые представлен в процессорах серии Pentium III на ядре Katamai.
SIMD – Single Instruction Multiple Data. Аппаратно данное расширение состоит из 8(позже 16, для режима Long Mode-x86-64) и конечно контрольного регистра – MXCSR
В последующих расширениях SSE2 SSE3 SSSE3 SSS4.1 и SSE4.2 только появлялись новые инструкции, в основном нацеленные на специализированные вычисления.
В 2010 появились первые процессоры с поддержкой набора инструкций для аппаратного шифрования AES, этот набор инструкций тоже использует SSE-регистры.
Регистры SSE называются XMM и наличествуют XMM0-XMM7 для 32-битного Protected Mode и дополнительными XMM8-XMM15 для режима 64-битного Long Mode.
Все регистры XMM-регистры 128-битные, но максимальный размер данных, над которым можно совершать операции это FP64-числа. Последнее обусловлено предназначением данного расширения – параллельная обработка данных.
Программное введение:
Когда я только начинал работать с FPU, меня поразила невообразимая сложность работы с ним. Во-первых, из всех 8-ми регистров, прямой доступ был только к двум.
Во-вторых, напрямую загружать данные в них нельзя было, то есть, скажем, инструкция fld 100.0 не поддерживается. А, в-третьих, из регистров общего назначения тоже
нельзя было загрузить данные. Если вторая проблема в SSE не решена, то о первой и третье подобного сказать нельзя.
В данном обзоре рассматриваются только SISD инструкции, призванные заменить FPU аналоги.
Начнем-с. Перво-наперво стоит узнать, как же можно записать данные в xmm-регистр. SSE может работать с FP32 (float) и FP64(double) IEEE754-числами.
Для прямой записи из памяти предусмотрены инструкции MOVSS и MOVSD .
Их мнемоники расшифровываются так:
MOVSS – MOVE SCALAR(Bottom) SINGLE
MOVSD – MOVE SCALAR(Bottom) DOUBLE
Данные инструкции поддерживают только запись вида XMM-to-MEMORY и MEMORY-to-XMM.
Для записи из регистра общего назначения в регистр XMM и обратно есть инструкции MOVD и MOVQ .
Их мнемоники расшифровываются так:
MOVD – MOV DOUBLE WORD(DWORD)
MOVQ – MOV QUAD WORD(QWORD)
Перейдем к основным арифметическим операциям.
Сложение:
ADDSS – ADD SCALAR SINGLE
ADDSD – ADD SCALAR DOUBLE
Вычитание:
SUBSS – SUB SCALAR SINGLE
SUBSD – SUB SCALAR DOUBLE
Умножение:
MULSS – MUL SCALAR SINGLE
MULSD – MUL SCALAR DOUBLE
Деление:
DIVSS – DIV SCALAR SINGLE
DIVSD – DIV SCALAR DOUBLE
Примечание:
XMM-регистры могут быть разделены на два 64-битных FP64 числа или четыре 32-битные FP32 числа.
В данном случае SINGLE и DOUBLE обозначают FP32 и FP64 соответственно. SCALAR – скалярное значение, выраженное одним числом, в отличие от векторного.
В случае работы со скалярными значениями используется нижний SINGLE или DOUBLE(т.е. нижние 32 или 64-бита соответственно) XMM-регистров.
Недостаток SSE заключается в том, что среди инструкций нет тригонометрических функций. Sin Cos Tan Ctan – все эти функции придется реализовать самостоятельно.
Правда, есть бесплатная Intel Aproximated Math Library, скачать ее можно по адресу: www.intel.com/design/pentiumiii/devtools/AMaths.zip.
В связи с данным фактом, в качестве алгоритма для практической реализации был выбран ряд Тейлора для функции синуса. Это ,конечно, не самый быстрый алгоритм,
но, пожалуй, самый простой. Мы будем использовать 8 членов ряда, что предоставит вполне достаточную точность.
В связи со спецификой Protected Mode, а именно, невозможностью прямой передачи 64-битных чисел через стек (нет, конечно, можно, только по частям но неудобно),
рассмотрим еще одну инструкцию, которую мы задействуем в нашей программе.
CVTSS2SD – ConVerT Scalar Single 2(to) Scalar Double
И ее сестра делающая обратное:
СVTSD2SS – ConVerT Scalar Double 2(to) Scalar Single
Данная инструкция принимает два аргумента, в качестве второго аргумента может выступать либо XMM-регистр либо 32-битная ячейка памяти – DWORD.
Примеры использования SSE-комманд:
movss xmm0,dword[myFP32]
movss xmm0,xmm1
movss dword[myFP32],xmm0
movsd xmm0,qword[myFP64]
movsd xmm0,xmm1
movsd qword[myFP64],xmm0
movd xmm0,eax
movd eax,xmm0
add/sub/mul/div:
addss xmm0,dword[myFP32]
subsd xmm0,xmm1
mulss xmm0,dword[myFP32]
divsd xmm0,xmm1
Математическое введение:
В качестве тестового алгоритма мы будем использовать ряд Тейлора для функции синуса. Алгоритм представляет собой простой численный метод.
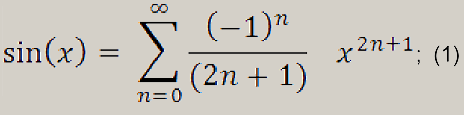
В нашем случае мы используем 8 членов этого ряда, это не слишком много и вполне достаточно для того, что бы обеспечить довольно точные вычисления.
Во всяком случае, отклонение от fsin(аппаратная реализация Sin – FPU) минимально.
Используемая формула выглядит так:
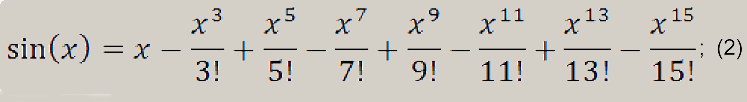
Программная реализация:
В случае с SSE мы воспользуемся всеми восемью регистрами, а что касается FPU – мы будем использовать только st0 и st1.
Благо использование памяти в качестве буфера оказалось эффективней, чем использование всех регистров FPU, к тому же так проще и удобней.
Вычисление будут проходить так:
Сначала мы вычислим значения всех членов ряда, а потом приступим к их суммированию. Подсчет факториалов проводить не будем, так как это пустая
трата процессорного времени в данном случае.
Программная реализация на SSE:
proc sin_sse angle
;Нам понадобятся два экземпляра аргумента:
cvtss2sd xmm0,[angle] ;; Первый будет выступать как результат возведения в степень.
movq xmm1,xmm0 ;; Второй как множитель, это сделано для того что б минимизировать обращения к памяти.
;; xmm0 = angle.
;; xmm1 = angle. ;; далее x=X=Angle
mulsd xmm0,xmm1 ; Возводим X в третью степень.
mulsd xmm0,xmm1 ;
movq xmm2,xmm0 ; xmm2 = xmm0 = x^3
mulsd xmm0,xmm1 ; Продолжаем возведение.
mulsd xmm0,xmm1 ; Теперь уже в пятую степень.
movq xmm3,xmm0 ; xmm3 = xmm0 = x^5
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm4,xmm0 ;; xmm4 = xmm0 = x^7
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm5,xmm0 ;; xmm5 = xmm0 = x^9
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm6,xmm0 ;; xmm6 = xmm0 = x^11
mulsd xmm0,xmm1
mulsd xmm0,xmm1
movq xmm7,xmm0 ;; xmm7 = xmm0 = x^13
mulsd xmm0,xmm1 ;; Наконец возводим X в 15-ю степень и заканчиваем возведение.
mulsd xmm0,xmm1 ;; xmm0 = x^15
;; Переходим к делению всех промежуточных результатов X ^ n, на n!.
divsd xmm0,[divers_sd+48] ; X^15 div 15!
divsd xmm7,[divers_sd+40] ; X^13 div 13!
divsd xmm6,[divers_sd+32] ; X^11 div 11!
divsd xmm5,[divers_sd+24] ; X^9 div 9!
divsd xmm4,[divers_sd+16] ; X^7 div 7!
divsd xmm3,[divers_sd+8] ; X^5 div 5!
divsd xmm2,[divers_sd] ; X^3 div 3!
subsd xmm1,xmm2 ; x – x^3/3!
addsd xmm1,xmm3 ; + x^5 / 5!
subsd xmm1,xmm4 ; – x^7 / 7!
addsd xmm1,xmm5 ; + x^9 / 9!
subsd xmm1,xmm6 ; – x^11 / 11!
addsd xmm1,xmm7 ; + x^13 / 13!
subsd xmm1,xmm0 ; – x^15 / 15!
;; В EAX результат не поместится
movq [SinsdResult],xmm1
;; Но если нужно добавить функции переносимость, есть два варианта.
cvtsd2ss xmm1,xmm1
mov eax,xmm1
ret
SinsdResult dq 0.0
divers_sd dq 6.0,120.0,5040.0,362880.0,39916800.0,6227020800.0,1307674368000.0
endp
Что касается FPU версии данной функции, то в ней мы поступим несколько иначе. Мы воспользуемся буфером в виде 16*4 байт. В последний QWORD
запишем результат. И в качестве делителя будем использовать память, это не страшно т.к. данные будут расположены на одной и той же странице, а это
значит, что данная страница уже будет прокеширована и обращения к ней будут довольно быстрыми. Суммирование и вычитание членов ряда так же будет
проведено в конце.
Программная реализация на FPU:
proc sin_fpu angle
fld [angle] ; загружаем X. st0=X
fmul [angle]
fmul [angle] ; st0 = X^3
fld st0 ; st1 = st0
fdiv [divers_fpu] ; Делим X^3 на 3! не отходя от кассы
fstp qword[res] ; легким движением стека FPU, st1 превращается в st0 ![]()
;; qword[res] = x^3 / 3!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^5
fdiv [divers_fpu+8]
fstp qword[res+8]
;; qword[res+8] = x^5 / 5!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^7
fdiv [divers_fpu+16]
fstp qword[res+16]
;; qword[res+16] = x^7 / 7!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^9
fdiv [divers_fpu+24]
fstp qword[res+24]
;; qword[res+24] = x^9 / 9!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^11
fdiv [divers_fpu+32]
fstp qword[res+32]
;; qword[res+32] = x^11 / 11!
fmul [angle]
fmul [angle]
fld st0 ; st0 = st1 = X^13
fdiv [divers_fpu+40]
fstp qword[res+40]
;; qword[res+40] = x^13 / 13!
fmul [angle]
fmul [angle] ; st0 = st1 = X^15
fdiv [divers_fpu+48]
fstp qword[res+48]
;; qword[res] = x^15 / 15!
fld [angle] ; st0 = X
fsub qword[res] ; X – x^3/3!
fadd qword[res+8] ; + x^5 / 5!
fsub qword[res+16] ; – x^7 / 7!
fadd qword[res+24] ; + x^9 / 9!
fsub qword[res+32] ; – x^11 / 11!
fadd qword[res+40] ; + x^13 / 13!
fsub qword[res+48] ; – x^15 / 15!
fstp qword[res+56] ; Сохраняем результат вычислений.
ret
res_fpu dq 0.0
res dd 14 dup(0)
divers_fpu dq 6.0,120.0,5040.0,362880.0,39916800.0,6227020800.0,1307674368000.0
endp
Обе функции были протестированы в программе WinTest и вот ее результаты:
sin_FPU – 145-150 тактов в цикле на 1000 итераций и около 1300-1800 при первом вызове при использовании FP64 и 150-165 для FP80.
Такая потеря скорости связана с тем, что при первом вызове память еще не прокеширована.
sin_SSE – около 140-141 тактов в цикле на 1000 итераций, при первом вызове результат аналогичный FPU.
На заметку: так же я тестировал SSE через память (аналогично FPU-алгоритму) и FPU через использование всех регистров, в обоих случаях
имела место серьезная потеря производительности. 220-230 тактов для SSE-версии с использование буферов и около 250-300 для FPU через регистры.
FXCH – оказалась очень медленной инструкцией, а SSE не помогло даже то что страница с данными находилась в кеше.
Примечание:
Основываясь на результатах тестирования, я могу сказать, что разница в результатах может быть лишь погрешностью. Это было проверено опытным путем.
Я несколько раз перезагружал компьютер и в разных случаях выигрывал SSE или FPU. Это дает повод предположить, что имела место немаленькая погрешность
и разница в результатах является ее и только ее порождением. Но Intel Optimization Manual говорит об обратном. По документации разница между SSE и FPU
командами около 1-2 тактов в пользу SSE, т.е. SSE-команды на 1-2 такта в среднем, выполняются быстрее.
Выводы:
Как показала практика, при использовании SSE в качестве FPU мы почти ничего не теряем. Важно то, что такое однопоточное SISD использование не является эффективным.
Всю свою настоящую мощь SSE показывает именно в параллельных вычислениях. Какой смысл считать за N тактов, 1 FP32 сложение/вычитание
или любую другую арифметическую операцию, если можно посчитать за те же N-тактов целых четыре FP32 или 2 FP64. Вопрос остается лишь
в распараллеливании алгоритмов. Стоит ли использовать SSE? Однозначно стоит. Данное расширение присутствует во всех процессорах, начиная с Pentium III и AMD K7.
Важно: Регистры XMM предположительно не сохраняються при переключении задач и точно не сохраняются при использовании API. Тот же GDI+ не восстанавливает их значения.
Nota Bene:
1. Тестирование проводилось на процессоре с не самым старым ядром. Еще при релизе мелькала фраза о масштабных оптимизациях во всех блоках.
При схожей частоте данный процессор в ряде приложений оказывается быстрее, чем, скажем Core 2 на ядре Conroe(первое поколение Core 2).
Это собственно к чему: SSE не всегда было таким быстрым, как и FPU. На разных архитектурах вы увидите как выигрыш от использования SSE
так и серьезный проигрыш.
2. Данный численный метод не является самым быстрым, он даже не распараллелен. Аппаратный FSIN выполняется за 80-100 тактов с FP80/FP64 точностью.
Существуют так же другие численные методы для нахождения тригонометрических и других функций, которые намного эффективней данного и практически позволяют
сделать эти вычисления более быстрыми, нежели FSIN.
Програмно-аппаратная конфигурация:
CPU: Intel Core 2 Duo E8200 2.66 Ghz @ 3.6 Ghz 450.0 FSB * 8.0.
RAM: Corsair XMS2 5-5-5-18 800Mhz @ 900Mhz 5-6-6-21. FSB:MEM = 1:2
MB: Gigabyte GA P35DS3L (BIOS неизвестен – никогда не изменялся.)
GPU: Saphire Radeon HD5870 1GB GPU Clock = 850 Mhz Memory Clock = 4800(1200 Phys).
PSU: Cooler Master Elite 333 Stock PSU 450 Wt.
OS: Windows 7 Ultimate x86
FASM: 1.67 recompiled by MadMatt(Matt Childress).
Ссылки:
http://users.egl.net/talktomatt/default.html
http://programmersforum.ru/showthread.php?t=55270 – тема, где можно найти программу для тестирования времени выполнения.
Автор данной программы некто bogrus. Его профиль есть на форуме WASM.RU но, он неактивен уже 3-й год.
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
30th
Апр
Что, где, когда или с чего начать программировать?
Многие хотят стать программистами или же улучшить свои познания в этом увлекательном занятии. Но, как только человек хочет начать, что-то осваивать, перед ним встает вопрос: «…а с чего начать?». Собственно в данной статье, я попытаюсь ответить на этот распространенный вопрос.
Что, где, когда или… с чего начать программировать?
Пискунов Денис
by spamer www.programmersforum.ru
В связи с тем, что в Интернете, да и не только в нем, довольно часто можно встретить людей, которые далеки от программирования, но желают постигнуть его и которые знают некоторые азы сего занятия, но не знают, что им делать дальше, я и пишу данную статью.
«В первый раз – в первый класс»
Для начала, человеку желающему научиться программировать, необходимо скачать/купить книгу по какому-то языку программирования. Я бы советовал для начала скачать электронную книгу, потому-что вдруг вам это занятие не понравится, а деньги на бумажную версию будут уже потрачены. Теперь давайте определимся с языком.
Многие, уже знающие люди, начинают спорить на счет-того, какой язык лучше выбрать начинающим для изучения. Но в нашем случае, я спорить ни с кем не буду, а просто посоветую для начала выбрать язык программирования Pascal. С чем связан такой выбор? Да все очень просто, начинающему будет намного проще понять логику работы программы (алгоритма) в Pascal’е, чем скажем, например в С++ или Assembler.
Так, с языком определились. Теперь вернемся к выбору книги. Как в интернете, так и на прилавках магазинов, лежит огромное количество разнообразной литературы по программированию. А какой-же учебник скачать/купить нам? Скажу сразу, ни в коем случае не покупайте книги типа «Программирование для чайников». Полезного из такой брошюры вы не возьмете ничего, а вот представление о программировании, после ее прочтения, у вас будет неправильное, а то и вообще пугающее. Собственно по Pascal’ю советую следующие материалы и учебники [1-4]. В данной литературе предоставляется хорошее и понятное описание структуры языка, команд, структур данных и т.д. Также присутствуют примеры решения задач и задания для самостоятельного выполнения.
Выбираем среду разработки [5-7]
С языком и обучающим материалом определились. И вот теперь осталось выбрать и установить среду для написания программы или как правильнее – «Интегрированную среду разработки» (IDE, Integrated development environment). Собственно, что представляет собой IDE? Попросту, это набор программных средств, при помощи которых программист разрабатывает программное обеспечение. Так как изучать мы будем чистый Pascal, то и приложения мы будем писать консольные, посему я советую следующую среду разработки – Turbo Pascal 7.0 и кросс-платформенный компилятор FreePascal. Конечно, можно выбрать и что-то современнее, например TurboDelphi, Delphi 2010 или альтернативный Geany. Но для новичка в программировании, я считаю – это будет неправильно, так как в IDE Delphi увидеть логику работы программы, структуру языка и т.д., будет тяжело.
После вот таких приготовлений – садимся читать выбранную книгу, и хочу заметить, не просто читать, а читать, запоминать и разбираться в написанном. Если будете просто читать книжку, то вы потратите свое время в пустую. Поэтому, после получения некоторого теоретического материала, обязательно необходимо все полученные знания закрепить на практике. А точнее – садимся и пишем свою первую программу… Hello World J. Справились с этой задачей, ставим себе новую и реализуем, не знаете, что себе задать – в учебниках есть практические задания. После прочтения книги и при имеющихся знаниях – сделайте свой собственный не большой проект, например «Телефонный справочник», «вариант игрушки» и т.д.
Далее, после того, как вы чувствуете, что довольно хорошо владеете изученным языком, а возможно и уже некой технологией, необходимо решить для себя: «…а нравится-ли мне данная отрасль программирования?». Для ответа на этот вопрос, с помощью любого поисковика ищем информацию о следующих, так сказать, видах программирования:
. системное программирование
. прикладное программирование
. веб – программирование
После прочтения соответствующей информации и при уже имеющихся знаниях в программировании – вы должны выбрать дальнейший вид поля своей деятельности. Если вы определились, тогда начинайте углубленное изучение* выбранного направления.
* Помимо чтения литературы, также желательно общаться на соответствующих форумах. Например, выберите для себя один или два форума и, так сказать – «живите на них». На таких ресурсах Интернета можно довольно много узнать полезной информации, поделиться с кем-то такой-же информацией. Также всегда можно попросить помощи у профессионалов, например, что бы вам объяснили непонятный момент при изучении.
Вот еще такой нюанс – не надо думать, что программирование заключается только в знании языков программирования. Если вы хотите стать действительно хорошим программистом, то вам обязательно нужно знать дополнительные технологии. Например, можно полностью посвятить себя изучению программирования графики, попутно ознакомиться с разнообразными графическими библиотеками, алгоритмами, связанными с графикой и т.д. Следовательно, для достижения каких-либо целей, вам всегда необходимо читать соответствующую литературу, а также запомнить один из основных моментов – научиться пользоваться поиском. Так как большинство вопросов уже обсуждалось в Интернете, то правильный запрос в поисковую систему даст вам интересующий ответ.
Заключение
И не бойтесь спрашивать знающих людей о том, что не знаете сами – ничего предосудительного в этом нет. В общем, не надо ждать доброго дяденьку, который придет, все Вам разжует и в рот положит, а начинайте сами достигать поставленной цели. Так что, дерзайте.
Ресурсы
. Т.А. Павловская. Паскаль. Программирование на языке высокого уровня: практикум. – С.Петербург, Питер
-Юг, 2003
. Валерий Попов. Паскаль и Дельфи. Самоучитель. – С.Петербург, Питер, 2003
. В.В. Фаронов. Turbo Pascal 7.0. Начальный курс: учебное пособие. – М., КноРус, 2007
. А.Я. Архангельский. Язык Pascal и основы программирования в Delphi. – М., Бином-Пресс, 2008
. Скачать компилятор FreePascal http://www.freepascal.org/download.var
. Скачать компилятор Geany http://download.geany.org
. Скачать компиляторы DELPHI http://delphilab.ru
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Что, где, когда или… с чего начать программировать?
30th
Изменения в языке Дельфи 2010
Задача предназначена для представления краткого обзора нововведений в язык Дельфи (2010) по сравнению с Дельфи 7.
Изменения в языке Дельфи 2010
Utkin
Благодаря активным попыткам компании Embecadero влиять на рынок продуктов разработки программ язык Дельфи быстро развивается, однако это развитие направлено в основном на попытки наверстать все нововведения в современных языках программирования (таких как С#). Никаких принципиально новых разработок и концепций не внедряется.
Директива Inline (появилась в Дельфи 2005)
По аналогии с С++, функции и процедуры теперь могут быть встраиваемыми со всеми вытекающими последствиями. А именно использование данной директивы не гарантирует вставку тела функции вместо ее вызова. Кроме того, существует еще целый ряд ограничений (согласно справочной системе). Эта директива бесполезна:
. при позднем связывании (virtual, dynamic, message);
. для функций и процедур имеющих ассемблерные вставки;
. для конструкторов и деструкторов, там она работать не будет (о чем Вам компилятор обязательно пожалуется);
. для главного блока программы, секций инициализации и финализации модулей;
. если метод класса обращается к членам класса с более низкой видимостью, чем сам метод. Например, если public метод обращается к private методу, то для такого метода inline-подстановка осуществляться не будет;
. для процедур и функций, которые используются в выражениях проверки условия циклов while и repeat.
Как сделать процедуру встроенной?
Procedure Add (var x: Integer; y: Integer); Inline;
Регулировать поведение inline можно следующими директивами:
{$INLINE ON} – по умолчанию включена, разрешает работу Inline;
{$INLINE AUTO} – будет осуществлена попытка встраивание кода функций и процедур, если:
а) они помечены как Inline;
б) если их размер будет менее 32-х байт.
{$INLINE OFF} – не разрешает работу Inline.
Следует отметить, что и в классическом С++ Inline никогда не была высокоэффективным механизмом, а учитывая ограничения, накладываемые компилятором Дельфи, ее использование под большим вопросом.
Перегрузка операторов (появилась в Delphi.Net)
В отличие от С++ перегрузка осуществляется немного по-другому. Для перегрузки операторов перегружается не символ оператора, а его символическое обозначение (сигнатура). Перегружать можно только для операций с экземплярами классов.
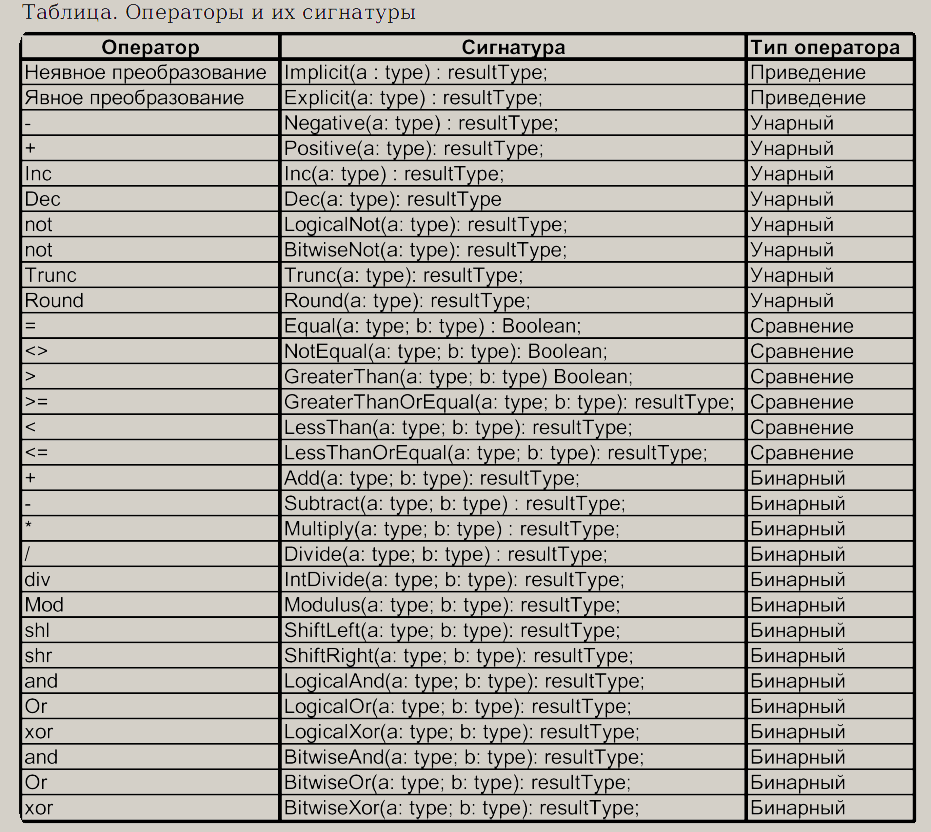
Нужно обратить внимание – TRUNC, ROUND, INC, DEC считаются операторами, а не процедурами и функциями.
Вот пример использования:
TMyClass = class
class operator Add(a, b: TMyClass): TMyClass; // Перегрузка сложение для TMyClass
class operator Subtract(a, b: TMyClass): TMyclass; // Вычитание для TMyClass
class operator Implicit(a: Integer): TMyClass; // Неявное преобразование Integer в TMyClass
class operator Implicit(a: TMyClass): Integer; // Неявное преобразование TMyClass в Integer
class operator Explicit(a: Double): TMyClass; // Явное преобразование Double в TMyClass
end;
// Пример описание сигнатуры Add для перегрузки сложения для типа TMyClass
TMyClass.Add(a, b: TMyClass): TMyClass;
begin
…
end;
var
x, y: TMyClassbegin
x := 12; // Неявное преобразование из Integer
y := x + x; // Вызов TMyClass.Add(a, b: TMyClass): TMyClass
b := b + 100; // Вызов TMyClass.Add(b, TMyClass.Implicit(100))
end;
Подробней о перегрузке операторов можно почитать здесь: http://www.realcoding.net/articles/delphinet-peregruzka-operatorov.html
Помощники класса (Class Helpers)
Интересный механизм (ответ Дельфи на расширители классов в С#), призванный решить некоторые проблемы в обход наследования. Служит для дополнения класса новыми методами и свойствами.
type
TMyClass = class
procedure MyProc;
function MyFunc: Integer;
end;
…
procedure TMyClass.MyProc;
var
X: Integer;
begin
X := MyFunc;
end;
function TMyClass.MyFunc: Integer;
begin
…
end;
…
type
TMyClassHelper = class helper for TMyClass
procedure HelloWorld;
function MyFunc: Integer;
end;
…
procedure TMyClassHelper.HelloWorld;
begin
WriteLn(Self.ClassName); // Здесь будет возвращен тип TMyClass, а не TMyClassHelper
end;
function TMyClassHelper.MyFunc: Integer;
begin
…
end;
…
var
X: TMyClass;
Begin
X := TMyClass.Create;
X.MyProc; // Вызов TMyClass.MyProc
X.HelloWorld; // Вызов TMyClassHelper.HelloWorld
X.MyFunc; // Вызов TMyClassHelper.MyFunc
end;
По сути, вариация на тему множественного наследования, но есть одна особенность – помощники класса позволяют дополнять любой существующий класс, без создания нового. Обратите внимание, что механизм помощника класса не использует явного упоминания Self при обращении к полям класса (помогаемого класса). То есть, HelloWorld имеет право обращаться к полям TMyClass (просто в нашем примере их нет). Аналогично TMyClass также имеет доступ к полям TMyClassHelper (в случае, если класс и его помощник объявлены в одном модуле).
С практической точки зрения удобный механизм, кроме одной детали – класс должен иметь только одного помощника, имеет ли он помощника проверить во время выполнения программы нельзя. Если в классе имеется несколько помощников (неважно в каком юните, лишь бы он видел класс), считаться рабочим будет только самый последний из объявленных. Это значит, что если TMyClass уже имел помощника, то будут доступны методы именно TMyClassHelper, поскольку именно он объявлен последним. Таким образом, в лучшем случае, два и более помощника для одного класса вызовут ошибку компиляции, в худшем трудно отлавливаемую ошибку, жалобы программиста на багги в IDE и компиляторе и много потерянного времени. Чем сложней проект, тем трудней будет установить причину ошибки.
С теоретической точки зрения механизм противоречивый – он увеличивает сцепляемость объектов и юнитов между собой. Перед использованием помощника, я должен проверить все модули, из которых доступен данный класс на предмет проверки существования такого помощника (представьте большой проект). Это нарушает принципы инкапсуляции – если раньше перед использованием класса нужно было знать только его интерфейс, то теперь для использования помощников, я должен отслеживать существование класса во всех модулях, где имеется доступ к данному классу. С этого момента механизм интерфейсов уже не играет особой роли, поскольку, обращаясь к объекту какого-либо класса, всегда можно обнаружить такой букет неизвестных методов, что интерфейсная часть класса становится даже вредной. Это нарушает принцип сокрытия данных – благодаря помощникам я могу менять работу своих и чужих классов и могу иметь доступ к его полям (в рамках юнита). Кстати, это ограничение на доступ к полям в рамках юнита также сводит на нет многие его плюсы – проще вписать новые методы в сам класс (или наследовать новый), чем создавать путаницу в классе, юните и проекте.
Записи стали объектами
И теперь имеют свои методы, свойства и конструкторы.
type
TMyRecord = record
type
TInnerColorType = Integer;
var
Red: Integer;
class var
Blue: Integer;
procedure printRed();
constructor Create(val: Integer);
property RedProperty: TInnerColorType read Red write Red;
class property BlueProp: TInnerColorType read Blue write Blue;
end;
constructor TMyRecord.Create(val: Integer);
begin
Red := val;
end;
procedure TMyRecord.printRed;
begin
writeln(’Red: ‘, Red);
end;
Но, сокращенная запись по-прежнему разрешена (поэтому старые проекты должны переноситься и с сокращенной формой записей).
Абстрактные классы
type
TAbstractClass = class abstract
procedure SomeProcedure;
end;
Разрешены полностью абстрактные классы (раньше допускались только конкретные методы), содержащие объявления методов для дальнейшего их перекрытия в потомках.
strict private и strict protected
Строгое private – метод или свойство для класса и невидимое никому, вне класса даже в рамках текущего юнита.
Строгое protected – методы в этой секции будут видимы самому классу и его наследникам.
Таким образом, полное объявление выглядит теперь так
type
TKlass = class(TForm)
strict protected
protected
strict private
private
public
published
automated
end;
Не наследуемые классы
По аналогии с С#, в Дельфи 2010 существуют классы от которых дальнейшее наследование невозможно:
type
TAbstractClass = class sealed
procedure SomeProcedure;
end;
Весьма сомнительное удовольствие для рядового разработчика. Никаких реальных преимуществ такой класс не дает. Точные причины создания такого механизма не известны и преимущества от его использования очень призрачны – наследование не разрушает класса предка, поэтому и запечатывать их особой необходимости нет. Считается, что запечатанные классы работают быстрей обычных (сам не проверял) и они применяются для .NET платформы (сугубо в утилитарных целях – не все обертки над низкоуровневыми операциями, такими как WinApi, можно сделать наследуемыми).
Классовые константы (возникло в Delphi ![]()
Классы могут иметь константы – сами классы, а не порождаемые от них объекты.
type
TClassWithConstant = class
public
const SomeConst = ‘This is a class constant’;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
ShowMessage(TClassWithConstant.SomeConst);
end;
Классовые типы (возникло в Delphi ![]()
Класс может теперь содержать описание типа, которое можно использовать только в пределах данного класса.
type
TClassWithClassType = class
private
type
TRecordWithinAClass = record
SomeField: string;
end;
public
class var
RecordWithinAClass: TRecordWithinAClass;
end;
…
procedure TForm1.FormCreate(Sender: TObject);
begin
TClassWithClassType.RecordWithinAClass.SomeField := ‘This is a field of a class type declaration’;
ShowMessage(TClassWithClassType.RecordWithinAClass.SomeField);
end;
Еще одно сомнительное удовольствие. Описание типа это не конкретная структура, зачем прятать его описание в тело класса?
Классовые переменные (возникло в Delphi ![]()
Класс может содержать переменные по аналогии с константами:
Type
X = class (TObject)
Public
Var
Y: Integer;
End;
Пожалуй, единственное, где это может пригодиться это работа с RTTI, вообще классы в Дельфи стали больше напоминать юниты – такие вот юниты внутри юнитов. Обратите внимание, что переменные класса могут находиться в любой секции (секции в данном случае влияют на область видимости данных переменных), тогда как поля класса не могут быть public (в Дельфи 7 могли). Применение статических полей в классе делает Дельфи все более ориентированным в сторону С# (и менее в сторону Паскаля).
Вложенные классы
Теперь классы можно объявлять внутри классов, цель избежать конфликта имен, локализовать все связанные классы между собой:
type
TOuterClass = class
strict private
MyField: Integer;
public
type
TInnerClass = class
public
MyInnerField: Integer;
procedure InnerProc;
end;
procedure OuterProc;
end;
procedure TOuterClass.TInnerClass.InnerProc;
begin
…
end;
Классы все больше перенимают концепцию модулей. Понятно, что данное нововведение дань .Net, но реальной пользы от него опять же не очень много – раньше конфликта имен избегали префиксами A и F, не могу сказать, что новый механизм дал программистам новые возможности. Также как и попытка использовать вложенные классы для складывания всего в одну большую кучу наряду с помощниками классов сильно напоминают лебедь, рак и щуку, растаскивающие Дельфи в разные стороны.
Финальные методы класса
В классах можно создавать виртуальные методы, которые перекрыть нельзя:
TAbstractClass = class abstract
public
procedure Bar; virtual;
end;
TFinalMethodClass = class(TAbstractClass)
public
procedure Bar; override; final;
end;
Переопределить «Bar» уже больше нельзя.
Статические методы класса
У классов могут быть статические методы класса – то есть методы, которые можно вызвать от типа класса. Такие методы не имеют доступа к полям класса (также как и не могут получить Self на конкретный экземпляр данного класса):
type
TMyClass = class
strict private
class var
FX: Integer;
strict protected
// Note: accessors for class properties must be declared class static.
class function GetX: Integer; static;
class procedure SetX(val: Integer); static;
public
class property X: Integer read GetX write SetX;
class procedure StatProc(s: String); static;
end;
TMyClass.X := 17;
TMyClass.StatProc(’Hello’);
Здесь же представлен пример организации свойств классов. Их использование полностью аналогично использованию переменных и констант класса.
for-element-in-collection
Теперь компилятор способен распознавать итерации в контейнерах:
for Element in ArrayExpr do Stmt;
for Element in StringExpr do Stmt;
for Element in SetExpr do Stmt;
for Element in CollectionExpr do Stmt;
Вот развернутый пример:
var
A: Array [1..6] of String;
I: String;
….
for i in A do
begin
Memo1.Lines.Add(i);
end;
Обратите внимание, что I имеет тип String это не индекс массива, а конкретные значения, которые будут получаться из массива. Кое-где конечно автоматизирует, но представьте, что мне нужно написать некий метод, в котором происходит копирование одного массива в другой. Использовать все равно придется стандартный цикл for, либо писать еще один метод – добавление элемента в массив.
Динамическая инициализация массивов
Теперь массивы получили свои конструкторы:
Type
TMas = Array of String;
Var
Mas: TMas;
Mas := TMas.Create(‘Hello’, ’World’, ’!’);
Я, конечно, не против «Create» как конструктора по умолчанию, но уже сейчас из-за отсутствия внятной русскоязычной литературы по данной теме встречаются статьи, в которых авторитетные господа пишут, что конструктор обязательно должен называться Create (речь идет не только о массивах, но также о записях и конструкторах класса). Так вот конструктор должен называться Create только для массивов. Для всех остальных имя конструктора не обязательно должно быть Create (но желательно, особенно для классов).
Дженерики
Шаблоны, они и в С++ шаблоны. Считается что первые шаблоны возникли в С++, но вообще-то они пришли из функционального программирования и правильное их название параметрический полиморфизм. Явление, когда компилятор сам вырабатывает соответствующие варианты кода на основании обобщенного алгоритма:
TList<T> = class
private
FItems: array of T;
FCount: Integer;
procedure Grow(ACapacity: Integer);
function GetItem(AIndex: Integer): T;
procedure SetItem(AIndex: Integer; AValue: T);
public
procedure Add(const AItem: T);
procedure AddRange(const AItems: array of T);
procedure RemoveAt(AIndex: Integer);
procedure Clear;
property Item[AIndex: Integer]: T read GetItem write SetItem; default;
property Count: Integer read FCount;
end;
Вот пример списка содержащего произвольные (но однотипные элементы). Тип элементов определяется на момент объявления переменной:
ilist: TList<Integer>;
То есть мы создали список целых чисел (а можно, к примеру, список строк). Дженерики удобно использовать применительно к алгоритмам контейнеров данных и комбинаторным алгоритмам. Конкретные реализации алгоритмов можно посмотреть в модуле Generics.Collections, где есть TArray, TList, TStack, TQueue, TDictionary, TObjectList, TObjectQueue, TObjectStack, TObjectDictionary и TEnumerator, способные работать с разными типами данных.
Также необходимо отметить особенность дженериков (и шаблонов в С++) – обобщенные алгоритмы экономят время программиста, сокращая только его код, но для каждого типа (для каждой комбинации типов) всегда генерируется новая версия алгоритма (поэтому размер скомпилированных программ увеличивается).
Заключение
Большинство механизмов представленных здесь:
. обеспечивают совместимость с .NET
. дань моде
. попытка угнаться за Microsoft Visual Studio
Язык не содержит принципиальных отличий и мощных механизмов, которые действительно были бы востребованы именно программистами на языке Дельфи. Все нововведения навязаны, искусственны и не всегда соответствуют концепциям ООП. Большое количество противоречивых инструментов может только запутать программистов и в течение ближайших лет можно ожидать некоторого количества критических статей в адрес языка программирования Дельфи.
Комментарий автора
Личные впечатления о среде сложились следующие: сплошные недоделки (да и в 2009-м не лучше), ждать следующую версию наверно не стоит. FrameWork идет в комплекте, ничего доустанавливать не надо. Несмотря на заявленные требования не ниже 1 гигабайта ОЗУ, у меня и при 512-ти с тормозами, но работает.
Ресурсы
. Хроники «айтишника» http://skiminog.livejournal.com/33610.html
. Общество разработчиков Embecadero http://edn.embarcadero.com
. Углубленный материал по перегрузке операторов в Дельфи http://www.realcoding.net/articles/delphinet-peregruzka-operatorov.html.
. Онлайн-перевод англоязычных материалов статьи http://www.translate.ru
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
29th
Апр
Рабство программистов
Статья посвящена стереотипному мышлению о высокой эффективности имеющихся механизмов ООП. Для программистов использующих ООП языки. Цель статьи дать углубленное представление о базовых концепциях объектно-ориентированного программирования.
Рабство программистов
ООПрограммист – рядовой муравей, увеличивающий всемирную энтропию путем написания никому не нужного кода
http://absurdopedia.wikia.com/wiki/ООП
Атор Utkin
Каждый из тех, кто знаком с принципами ООП, прекрасно знает о тех преимуществах, удобствах и больших плюсах, которые оно представляет программистам. Но так ли это на самом деле? Все познается в сравнении, преимущества по сравнению с чем?
Что такое ООП?
Да, что такое ООП? Несмотря на значительное время существования данной концепции точного определения ООП не существует и по сей день. Есть определения ООП в рамках конкретных языков программирования, но все они различны, имеют свою терминологию, механизмы использования, особенности реализации и т.д. Любой учебник по ООП даст Вам либо определение в привязке к языку программирования, либо весьма туманное объяснение или же вовсе, с места в карьер, речь пойдет о принципах, определениях класса и объекта и т.д.
Не имея точного определения обучаемый, словно Алиса проваливается в кроличью нору нового для него мира. Особенно остро это ощущается, если уже имел навыки программирования. Но ощущения субъективны, рассмотрим основные концепции ООП под другим углом зрения.
Базовые понятия ООП
Их все знают, это:
. инкапсуляция
. наследование
. полиморфизм
Сейчас также добавляют еще понятие абстракции данных. Рассмотрим их всех по порядку…
Инкапсуляция – это принцип, согласно которому любой класс должен рассматриваться как чёрный ящик — пользователь класса должен видеть и использовать только интерфейсную часть класса (т. е. список декларируемых свойств и методов класса) и не вникать в его внутреннюю реализацию. Поэтому данные принято инкапсулировать в классе таким образом, чтобы доступ к ним по чтению или записи осуществлялся не напрямую, а с помощью методов. Принцип инкапсуляции (теоретически) позволяет минимизировать число связей между классами и, соответственно, упростить независимую реализацию и модификацию классов (определение взято из Википедии http://ru.wikipedia.org/wiki/Объектно-ориентированное_программирование).
Но, инкапсуляция не ноу-хау ООП, она существовала и ранее – это обычное описание функций и процедур. Пример на Паскале:
Function Sum (a, b: Integer): Integer;
Begin
Result := a+b
End;
Чтобы использовать функцию мне не обязательно знать, как она устроена (и в ряде случаев такое знание даже противопоказано), достаточно лишь описание интерфейса Function Sum (a, b: Integer): Integer; Я должен знать, что имя функции Sum, она принимает два параметра типа Integer (важен также порядок их следования), возвращает также Integer, а вот каким образом проводится сложение это уже совершенно безразлично. Еще пример:
Type
TMas = record
Data: Array of Integer;
Count: Integer;
End;
Procedure Sort (var Mas: TMas);
Теперь чтобы отсортировать такой вот массив, мне не нужно знать, как он устроен, сколько в нем элементов и т.д. Я просто передам его процедуре Sort.
Так чем же примечательна инкапсуляция? Справедливости ради, надо отметить, что инкапсуляция как описание указанного выше явления получило признание только в ООП. Потому что такое определение там является одним из главных особенностей построения программ. Никаких преимуществ, в сравнении с теми же структурным или функциональным программированиями, инкапсуляция в ООП не несет.
Однако на этом инкапсуляция не заканчивается:
Сокрытие данных (взят из книги Тимоти Бадд «ООП в действии») – неотделимая часть ООП, управляющая областями видимости. Является логическим продолжением инкапсуляции. Целью сокрытия является невозможность для пользователя узнать или испортить внутреннее состояние объекта. Но это тоже существует в структурном программировании:
Function fact(x: integer): integer;
var
i, n: Integer;
begin
n:=1;
for i:=1 to x do
begin
n:=n*i;
end;
fact:=n;
end;
Разве я могу получить доступ к i и n не в рамках данной функции? Также стоит еще раз внимательно почитать определение – невозможность для пользователя. Если речь идет о программисте, то он испортить может все и вся и никакое сокрытие данных Вам не поможет, по одной простой причине – раз имеются данные, то также и имеются некоторые механизмы для их использования. Поэтому область видимости не защищает данные от ошибок в методах данного класса. Пример на Дельфи:
Type
MyClass = class (TObject)
Protected
MyData: TStringList;
Private
Public
Constructor Create;
Destructor Destroy;
End;
Constructor MyClass.Create;
Begin
Inherited Create
End;
Destructor MyClass.Destroy;
Begin
Inherited Destroy
End;
Опытный программист уже догадался, о чем идет речь – любое обращение к MyData вызовет ошибку, поскольку перед использованием такие объекты нуждаются в инициализации (между прочим одна из распространенных ошибок начинающих программистов). Так что же дают игры с областями видимости?
Если же говорить о методах других объектов, то доступа к MyData они не получат, но согласно принципам ООП они и не должны его получать. Иными словами MyData никогда не должен находиться в секции Public (кстати, Дельфи это позволяет). Доступ к полям класса всегда должен осуществляться через методы либо свойства.
То есть здесь должна быть аналогия с функциями и процедурами структурного программирования – объявление структур данных должно осуществляться аналогично секции var. Это очень важный момент – сокрытие данных в рамках ООП предназначено для программирования программиста, а не реализации алгоритма. Я говорю о сокрытии данных, потому что я боюсь допустить ошибку, которая в рамках структурного программирования не может возникнуть в принципе. Компилятору безразлично, в какой секции находится поле, он выдаст код в любом случае (речь идет о Дельфи версии 7), все ограничения видимости введены для программиста.
Если Вы думаете, что в С++ это невозможно, то сильно ошибаетесь и виной тому указатели (а в С++ указатели не менее важный механизм, нежели механизмы ООП). Имея указатель на класс, можно не только прочесть его приватные поля, но и модифицировать их.
Class Sneaky
{
private:
int safe;
public:
// инициализировать поле safe значением 10
Sneaky () { safe = 10; }
Int &sorry() { return safe; }
}
И далее:
Sneaky x;
x.sorry () = 17;
Инкапсуляция тесно связана с таким понятием как абстрагирование. Это придание объекту характеристик, которые отличают его от всех других объектов, четко определяя его концептуальные границы. Основная идея состоит в том, чтобы отделить способ использования составных объектов данных от деталей их реализации в виде более простых объектов. И здесь снова модули и структуры решают эту задачу без участия ООП – интерфейсы функций, процедур и модулей могут полностью скрывать внутреннее представление по реализации тех или иных задач. Сомневаетесь? Вот пример взаимодействия модулей (Дельфи). Поместите на форму одну кнопку:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, Unit2, StdCtrls;
type
TForm1 = class(TForm)
Button1: TButton;
procedure Button1Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.Button1Click(Sender: TObject);
begin
AddX();
Button1.Caption:=IntToStr(GetX());
end;
////////////////////////////////////////////////////////////////////////////////
procedure TForm1.FormCreate(Sender: TObject);
begin
Init();
end;
////////////////////////////////////////////////////////////////////////////////
end.
И подключите второй модуль:
unit Unit2;
interface
procedure Init();
procedure AddX();
function GetX(): Integer;
implementation
var
x: Integer;
procedure Init();
begin
x:=0;
end;
////////////////////////////////////////////////////////////////////////////////
procedure AddX();
begin
x:=x+1;
end;
////////////////////////////////////////////////////////////////////////////////
function GetX(): Integer;
begin
result:=x;
end;
////////////////////////////////////////////////////////////////////////////////
end.
Выполните программу, понажимайте на кнопку. Теперь попробуйте получить доступ к Х без использования функций и процедур из Unit2. Модуль хранит в себе данные, скрывает их представление и ограничивает к ним доступ. При этом в Unit2 нет и намека на класс (и не думайте, что Вы сможете прочесть или изменить Х обычными процедурами и функциями Unit1 (не из формы)).
Наследование
один из четырёх важнейших механизмов объектно-ориентированного программирования, позволяющий описать новый класс на основе уже существующего (родительского), при этом свойства и функциональность родительского класса заимствуются новым классом. Не то чтобы я не согласен с таким определением, но давайте посмотрим очередной пример:
Type
TMas = record
Data: Array of Integer;
Count: Integer;
End;
Type
TGroupMas = record
Data: Array of TMas;
Count: Integer;
End;
Procedure Sort (var Mas: TMas);
Разве для построения TGroupMas я не опираюсь на TMas? Я ведь мог написать определение TGroupMas с нуля, но в моем случае каждый элемент массива Data структуры TGroupMas является ни кем иным как TMas. Более того, мне ничего не стоит написать процедуру сортировки указанного элемента TGroupMas. Все что требуется это лишь правильно передать параметры процедуре Sort.
Таким образом, я описываю новую структуру TGroupMas данных на основании существующей TMas и я мог создать процедуру сортировки элемента массива на основании Sort:
Procedure SortItem (var GropuMas: TGroupMas; Index: Integer);
Begin
Sort (GroupMas.Data[Index]);
End;
При этом согласно определению наследования, я заимствую все свойства TMas и функциональность Sort; и все это в рамках структурного программирования, никакого ООП для этого не требуется. Вот пример, который часто любят давать в учебниках ООП (язык программирования Дельфи):
Type
TMaterial = record
Massa: Integer;
End;
Type
TAnimal = record
Material: TMaterial;
Sort: String;
End;
Type
TMamal = record
Animal: TAnimal;
Family: String;
End;
Type
THuman = record
Mamal: TMamal;
Race: String;
Floor: String;
Name: String;
Family: String;
End;
Type
TProgrammer = record
Human: THuman;
Sertificate: String;
End;
Type
TProgrammer_of_Pascal = record
Programmer: TProgrammer;
IDE: String;
End;
И пусть в меня «кинут камнем», если программист в данной иерархии не является млекопитающим и не обладает его свойствами (имеет массу, принадлежит к определенному виду).
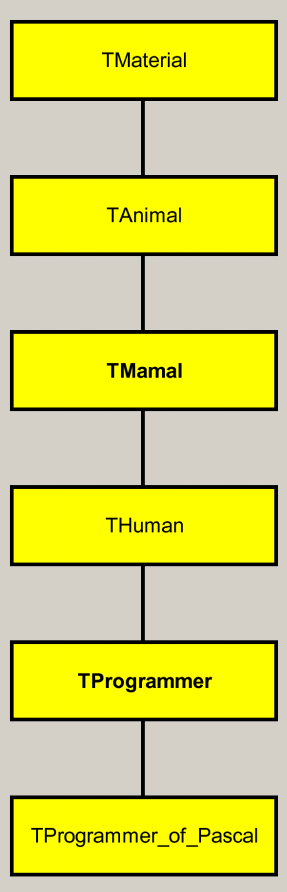
Для использования механизма наследования не требуется использование объектно-ориентированного программирования. Достаточно, чтобы язык имел возможность организации структур данных определяемых программистом.
Множественное наследование полностью аналогично – я могу определить новую структуру – цвет глаз и включить ее в TMamal и тогда программист обретет новые свойства. Кстати, множественное наследование одна из самых известных мозолей ООП, но именно поэтому о ней мы больше упоминать не будем. Цель данной статьи как раз показать те, моменты, о которых говорить не любят.
Полиморфизм
взаимозаменяемость объектов с одинаковым интерфейсом. Язык программирования поддерживает полиморфизм, если классы с одинаковой спецификацией могут иметь различную реализацию — например, реализация класса может быть изменена в процессе наследования. Кратко смысл полиморфизма можно выразить фразой: «Один интерфейс, множество реализаций».
Можно сказать, что полиморфизм одна из самых загадочных концепций ООП. Итак, в некотором роде полиморфизм тесно связан с наследованием. Вы получаете некоторые методы от родительского класса и можете переопределить их функциональность. Адекватного механизма в структурном программировании не существует, но какие собственно выгоды дает полиморфизм? Итак, это выглядит следующим образом – некий класс (допустим программист) имеет в своем составе метод (допустим, пить чай). Программист на Яве переопределяет метод и пьет чай марки Ява под именем метода пить чай. То есть мы подразумеваем, что когда программист на Ява пьют чай, то он пьет чай марки Ява. Стандартно, формально, но теперь вопрос, какие в этом плюсы?
. уменьшение сложности программ;
. позволяет повторно использовать один и тот же код;
. позволяет использовать в потомках одинаковые имена методов для решения схожих задач.
Не густо, ну что, рассмотрим каждый пункт:
0 – честно говоря, так и не увидел, в чем это выражается (хотя упоминается об этом практически везде), концепция структур и модулей достаточна для решения всех задач, которые могут быть решены полиморфизмом. С другой стороны, многочисленные одноименные методы усложняют программу. Результатом полиморфизма являются объекты, которые имеют и одноименные методы и могут работать с разными типами данных. Использование одноименных методов в таком случае не так тривиально, как хотелось бы. Пришлось срочно создавать новую концепцию (вернее сказать, воровать концепцию, поскольку ООП суть ряда заимствований от других парадигм) – RTTI. Проще всего ее можно представить как информацию о типе объекта во время выполнения программы. То есть перед запуском нужного метода используется явное определение того типа данных, с которым предстоит работать. Обычно такая ситуация возникает только в сложных программных объектах, но и полиморфизм в объектах с несложным поведением не имеет смысла и может быть заменен даже обычными операторами селекторами (например case в Дельфи) и введением дополнительных переменных. Более того, RTTI перечеркивает абстрагирование – для решения задачи динамически знать тип данных противопоказано, это увеличивает сцепляемость объектов – их сложней заменять, переносить, модернизировать. RTTI также уменьшает такую возможность полиморфизма, как использование обобщенных алгоритмов (о параметризации речь ниже).
1 – об этом уже упоминалось:
Procedure SortItem (var GropuMas: TGroupMas; Index: Integer);
Begin
Sort (GroupMas.Data[Index]);
End;
Я же не пишу функцию сортировки снова, просто передаю ей нужные параметры. На лицо явное использование уже существующего ранее кода и совершенно без единого класса, поэтому никакого преимущества в сравнении скажем с функциональным программированием здесь нет. Если же речь идет о параметризации, то с каждым новым набором параметров генерируется новая версия этой же функции, поэтому код в таком случае используется не повторно, а каждый раз новый.
2 – Я тоже могу написать кучу модулей для решения каждой задачи (все равно в классах каждое решение надо описывать явно) и вызывать их одноименные функции также через точечный синтаксис (в Дельфи), только в обратном порядке – имя_функции.имя_модуля. И я бы не сказал, что сильно путаюсь в программе, если однотипные действия названы по-разному (причем без разницы два у меня метода или десяток). Если имеется достаточно полное описание методов (те самые интерфейсы, которые ООП также считает своим достижением), и они имеют осмысленные имена, то никаких проблем между вызовом метода ProgrammTea и ProgrammJavaTea не возникает. ООП полностью игнорирует такие подходы как правильное оформление кода и правила именования объектов (хотя в нем же использование одноименных методов считается плюсом).
Организация тысячи то же что и организация одного. Это вопрос организации (Конфуций).
Кроме того, я не считаю, что выбор нужного метода осуществляется компилятором – все действия жестко прописаны в каждом классе, а поскольку любой класс является еще и типом, то он ничего не выбирает, выбирает программист в каком классе, какой чай должен пить объект-программист на этапе переопределения родительского метода. Вот я бы задал список методов вообще без привязки к конкретному классу, просто как набор функций и процедур в отдельном модуле, а уж компилятор сам вызывал бы соответствующий метод, тогда я бы согласился с этим утверждением на все 100. Далее в современные библиотеки классов, обычно содержат более 100 классов, которые могут содержать десятки методов, и все их держать в голове никакой полиморфизм еще никогда не помогал… Без разницы сколько мне надо знать 1000 методов или 10 000, все равно их все помнить в любой момент времени нет необходимости.
Что касается параметризации это действительно мощный механизм, но с теми же симптомами – это не универсальный рецепт, то есть имеет смысл его применять только в ряде случаев (часть из которых может быть решена комбинаторными алгоритмами) и преимущественно к простым типам. Вот пример алгоритма (С++):
// Описание шаблонной функции
template <typename T> T max(T x, T y)
{
if (x < y)
return y;
else
return x;
}
Не трудно догадаться, что она возвращает максимальный элемент из двух указанных, но только в том случае, если программист сможет описать строгое и однозначное сравнение объектов, то есть удобно для типов, которые по умолчанию поддерживаются транслятором. Для сложных типов, определяемых программистом параметризация не дает никаких преимуществ в сравнении с традиционными подходами. Весьма проблематична параметризация, когда в качестве типа выступают объекты классов, хотя, казалось бы, их строгая иерархия, наследование полей и полиморфизм должны как раз способствовать написанию обобщенных алгоритмов для работы с такими типами. Да это возможно, но требует тщательного продумывания иерархии и написание индивидуальных методов для каждого класса может оказаться предпочтительней.… Здесь решение аналогично RTTI, но проблема не в ООП, это попытка перешагнуть через строгое ограничение типов (наряду с типом Variant в Дельфи). Можно провести следующую аналогию – сначала перед бегуном понаставили барьеров и сказали, что теперь он будет учувствовать в беге с препятствиями, а потом пытаются научить его прыгать, выдают ему специальные кроссовки, рекомендуют методики тренировки…
Также не все гладко с перегрузкой операторов – трансляторы языков программирования часто не могут предоставить нужные средства идентификации перегруженных операторов (а те, что могут, сложны и не так эффективны, порождают большой и медлительный код), что вызывает двусмысленность в толковании всего выражения. Самый простой пример операция – (вычитание), дело в том, что она существует как минимум в двух видах это унарная операция и бинарная — -х и х-y (а в некоторых языках есть еще ее различные формы – инфиксная, постфиксная и т.д.). Далее, необходимо определить приоритет операции, скажем, для строк определение подобных операций может быть не так очевидно, как для чисел. Не думайте что сложение в этом случае лучше. Например, сложение строк x + y не эквивалентно y + x.
Также перегрузке свойственны общие беды полиморфизма – она не является обязательным элементом программирования (это значит, что нет алгоритмов, которые невозможно реализовать без использования перегрузки), и может привести к обратному результату – не упрощению, а усложнению программы. Подобно механизму RTTI перегрузка увеличивает связность кода – для понимания работы перегруженного оператора требуется знать тип объекта (или требуется его уточнение для понимания программистом) используемого в конкретной строке кода, отсюда всякие болячки – уменьшение переносимости, сложности при модификации отдельных объектов и т.д.
Это еще один пример, когда не программист создает алгоритм, а язык программирует программиста – Вы должны следовать этому принципу, так как это приносит некоторые удобства, но при этом все умалчивают о том, что это не гарантия преодоления нарастающей сложности программ (и более того, такой механизм сам может являться источником усложнения программы). И еще один момент – полиморфизм не обязательная черта ООП. Это значит, что если Вы напишите программу, использующую классы и объекты, но не использующую полиморфизм, то это все равно будет ООП. Кроме того, если Вам не хочется отказываться от полиморфизма, его можно имитировать в рамках модулей (юнитов) программ.
Что еще, не так как надо
ООП «вещь в себе», и оно не вписывается в ряд задач – например механизм подключения DLL. Да, функция или процедура возвращает значение, но какого типа? Это отследить невозможно (и RTTI Вам не помощник). ООП очень плохо подходит для парсинга структурированных текстов (например, программ) в сравнении с функциональным программированием. ООП не дружит с рекурсией (не то чтобы она там не возможна, просто не эффективна в сравнении с тем же функциональным программированием), которая позволяет упростить представление многих задач. Также нужно учитывать, что программа, составленная без ООП, как правило, быстрей, чем с ним. ООП официально не поддерживает концепцию ленивых вычислений (вообще это черта языков функционального программирования) – потенциальное увеличение производительности, упрощение решения ряда задач.
Итоги
Данная статья вовсе не призывает отказываться от принципов ООП, задача дать более полное представление об некоторых аспектах ООП. Без понимания этих моментов программисты уверены, что ООП существенный шаг вперед (на самом деле существенный шаг вперед – обширные библиотеки, которые в свете новых веяний написаны в стиле ООП), хотя возможно, всего лишь шаг в сторону…
Возьмите параметризацию – не стоит возлагать на нее большие надежды, она существует уже давно в том или ином виде в функциональном программировании (как и весь полиморфизм во всех его проявлениях) и пока не принесла кардинальных изменений в деле создания программ.
Список использованной литературы
. Тимоти Бадд. Объектно-ориентированное программирование в действии. – С.Петербург, Питер, перевод
по лицензии издательства Addison Wesley, 1997
. Г. Шилдт. Теория и практика С++. – С.Петербург, БХВ-Петербург, 2001
. Раздел википедии http://ru.wikipedia.org/wiki/Объектно-ориентированное_программирование
. Раздел абсурдопедии http://absurdopedia.wikia.com/wiki/ООП
. Э. Хювенен, И. Сеппянен. Мир Лиспа. – М., перевод с финского изд.Мир, в 2-х томах, 1990
. Ф. Брукс. Серебряной пули не существует. – М., Символ-Плюс, 1995, юбилейное издание первой книги
1987 года, перевод по лицензии издательства Addison Wesley
Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
25th
Апр
Как работать с графикой на канве в среде Дельфи. Урок 1–2
Понятия и методы работы с графикой в среде Дельфи для начинающих (полезно для создающих первые игры). Все сопровождается подробными примерами «космической стрелялки»…
Как работать с графикой на канве в среде Дельфи. Урок 1–2
Владимир Дегтярь
DeKot degvv@mail.ru
Графика в Delphi (немного теории). Урок 1
Операционная среда WINDOWS является графической средой и для вывода графической информации на экран или принтер использует функции GDI (Graphics Devices Interface – Интерфейс графических устройств). GDI – функции являются аппаратно–независимыми, поэтому взаимодействие приложений (в том числе и созданных в среде Delphi) с аппаратными устройствами компьютера осуществляются через драйвера устройств и через специальную структуру данных – называемой контекстом отображения (дисплейный контекст – DC (Display Context)). Контекст отображения содержит основные характеристики устройств вывода графической информации, а также инструменты для рисования (шрифт, перо и кисть).
Система Delphi предлагает специальные классы, упрощающие использование графических средств:
- TCanvas – для контекста отображения
- TFont – для шрифта
- TPen – для пера
- TBrush – для кисти
Связанные с этими классами объекты получают соответствующие свойства – canvas, font, pen, brush, которые уже как объекты, в свою очередь, имеют ряд своих свойств.
Для работы с рисунками или изображениями Delphi предлагает классы: TGraphic, TPicture, TImage, TBitMap, TJpegImage, TShape, TIcon, TMetaFile и др. Основной класс для связанных с рисованием графических операций – это TCanvas. С помощью его свойств и методов можно рисовать на поверхности визуальных объектов, которые включают в себя этот класс и имеют свойство сanvas. Для выполнения различных графических операций используются типы TPoint и TRect, описываемые следующим образом (см. листинг 1):
ЛИСТИНГ–1
…
TPoint = record // задание координат точки
X : LongInt;
Y : LongInt;
TRect = record // определение прямоугольной области
Left : Integer;
Top : Integer;
Right : Integer;
Bottom : Integer;
…
или
…
TRect = record // определение прямоугольной области
TopLeft : TPoint;
BottomRight : TPoint;
…
также
…
TRect := Bounds ( X,Y, Width, Height : Integer );
X, Y – координаты левого верхнего угла области ;
Width, Height – ширина и высота прямоугольной области;
Одним из основных объектов для рисования является – поверхность рисования (она же холст или канва) – объект класса TCanvas. У холста есть ряд свойств и методов для отображения графической информации, перемещения графических объектов по поверхности рисования, копирования изображений и/или их отдельных областей, вывода текстовой информации.
Наиболее частыми применяемыми методами отображения (вывода) графики являются:
- Canvas < рисование геометрических фигур (примитивы) > Arc ( дуга), Pie ( сектор), Ellipse ( эллипс,
круг), Rectangle (прямоугольник) и другие
- Canvas.Draw – вывод графической информации
- Canvas.StretchDraw – вывод графической информации с изменением масштаба
- Canvas.CopyRect – копирование графической области
- Canvas. TextOut – вывод текстовой информации
Кроме этого еще используются методы загрузки графических объектов из файлов, из других компонентов или объектов.
Самое простое приложение с выводом графики. Урок 2
Создадим новый проект в среде Delphi «File => New => Application» (при запуске Delphi новый проект создается автоматически). Cразу же сохраним проект – File => SaveAll. На первый запрос – сохраняем модуль под именем предложенным Delphi – Unit 1. По второму запросу изменим имя проекта с Project 1 на Lesson 1. Delphi в новом проекте создает объект Form1 и в редакторе кода модуля Unit 1 появляется заготовка кода (см. рис.1):
Рис. 1 Создаем новый проект.
В Object Inspector в свойствах формы Form1 изменим заголовок Caption на «Урок по графике №1» и выставим размеры окна формы: Top (100*), Left (230), Width (700), Height (575), ClientWidth (700), ClientHeight (540).
* почему именно эти цифры разберем позже
Теперь с помощью методов графических примитивов нарисуем, что–либо на форме. В Object Inspector перейдем на вкладку Events (События) и «кликнем» дважды по событию OnPaint(). В редакторе кода появится шаблон процедуры обработчика события On Paint (см. рис.2):
Рис. 2. Создание обработчика OnPaint()
Теперь запишем в этой процедуре следующий код (см. листинг 2):
ЛИСТИНГ–2
…
with form1.canvas do begin
pen.color:= clred; // цвет пера
rectangle(350, 50, 550, 100); // рисуем прямоугольник с координатами
// верхнего левого угла
// x1=350, y1=50 и правого нижнего x2=550, y2=100
pen.color:= clgreen;
pen.width:= 4; // ширина пера
brush.color:= clskyblue; // цвет заполнения фигуры
ellipse(60, 100, 250, 400) // эллипс, вписанный в прямоугольник
end;
Запустите проект (Run или F9 ) и посмотрите результат. Конечно, это слишком простой проект, поэтому усложним нашу задачу с использованием рисунков находящихся в файлах (формат файлов .bmp). Графические файлы, которые нам понадобятся для последующих проектов, находятся в папке data в соответствующих папках проектов (см. ресурсы к статье).
Далее, выведем на форму изображение звездолета (файл ‘ship1.bmp’ ) на фоне звездного неба (файл ‘star1.bmp’ ). В файле ‘ship1’ два изображения звездолета (спрайты – они нам понадобятся для организации движения звездолета), файл ‘star1’ используется для создания фона и имеет размер 700 х 540 (под эти размеры и установлены размеры окна формы через Object Inspector). Нам также понадобятся объекты типа TBitMap: BufFon (буфер для загрузки фона из файла ‘star1.bmp’ ), BufSpr (буфер для загрузки спрайтов из файла ‘ship1.bmp’ ), BufPic (буфер для загрузки рисунка одного из спрайтов из BufSpr), Buffer (общий буфер для объединения всех рисунков с последующим выводом на форму).
Размеры BufFon и BufSpr устанавливаются в соответствии с размерами изображений при загрузке. Размер общего буфера Buffer устанавливаем равным BufFon, а размер BufPic – равен размеру одного спрайта, что в общем случае определяется следующим образом:
BufPic.Width := round ( BufSpr.Width / n );
BufPic.Height:= round ( BufSpr.Height / m );
где n – кол–во спрайтов в горизонтальном ряду изображений в файле ‘sprite’,
m – кол–во рядов с изображением спрайтов в файле.
Инициализацию буферов проведем в процедуре OnCreate() формы (см. рис.3):
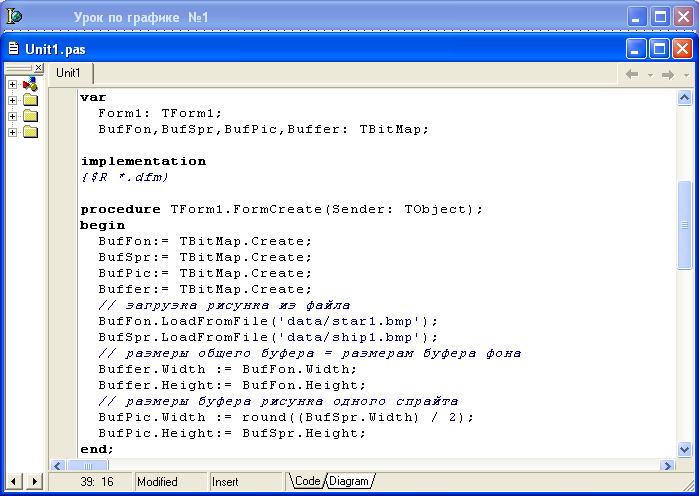
Рис. 3. Инициализация буферов
Для вывода одного спрайта через BufPic** создаем процедуру копирования спрайта из BufSpr в BufPic методом CopyRect (см. листинг 3):
ЛИСТИНГ–2
…
procedure DrawShip1 ( i: byte); // загрузка одного спрайта в буфер рисунка
begin
BufPic.Canvas.CopyRect(bounds(0, 0, BufPic.Width, BufPic.Height),
BufSpr.Canvas,bounds( i * 66, 0, BufPic.Width,
BufPic.Height));
end;
** на Canvas BufPic в область с координатами левого верхнего угла X= 0 и Y = 0, шириной и высотой соответствующие размерам буфера BufPic копируем изображение спрайта из области с область с координатами левого верхнего угла X= i * 66 и Y = 0, шириной и высотой соответствующие размерам буфера BufPic. В координате Х цифра 66 соответствует ширине одного спрайта. В переменной i передается номер спрайта (0 – 1-й, 1 – 2-й).
Вывод изображений производим аналогично предыдущему примеру (рисование прямоугольника и эллипса) в процедуре OnPaint(). Необходимо ввести переменные xs1 и ys1 (координаты вывода звездолета). Процедура DrawShip1(0) c параметром 0 выводит первый спрайт в буфер рисунка BufPic. Далее выводим фон и спрайт на канву дополнительного буфера Buffer и затем из него выводим все на форму. Удалите из процедуры код предыдущего примера и вставьте следующий (см. листинг 3):
ЛИСТИНГ–3
…
procedure DrawShip1 (i: byte); // загрузка одного спрайта в буфер рисунка
begin
BufPic.Canvas.CopyRect(bounds(0, 0, BufPic.Width, BufPic.Height),
BufSpr.Canvas, bounds(i * 66, 0, BufPic.Width,
BufPic.Height));
end;
procedure Tform1.FormPaint(sender: tobject);
var xs1, ys1: integer; // координаты звездолета SHIP1
begin
xs1:= 250; ys1:= 466;
DrawShip1(0);
Buffer.canvas.draw(0, 0, BufFon); // выводим фон в общий буфер
Buffer.canvas.draw(xs1, ys1, BufPic); // выводим рисунок спрайта поверх
// фона в общий
Buffer.canvas.draw(0, 0, Buffer); // вывод обеих рисунков (общего буфера)
// на форму
end;
После запуска проекта и компиляции получаем следующую картинку (см. рис.4):
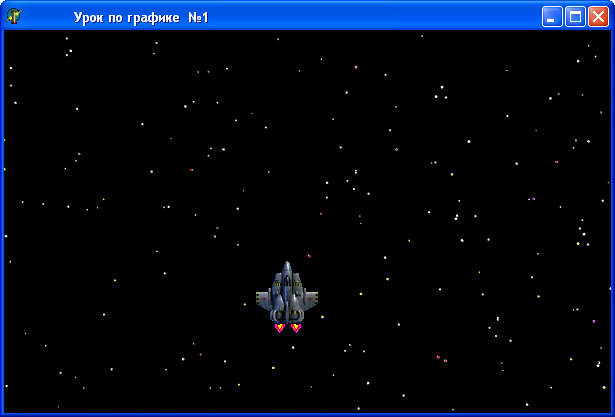
Рис. 4. Тестовый проект звездолета
Заключение
Мы получили статическое изображение и теперь в последующих уроках создадим движущиеся графические объекты. Но для начала познакомимся с основными принципами получения «эффекта» движения объектов (папка Lesson1***).
*** Перед запуском в среде Дельфи скопируйте в папку с проектом папку data с графическими файлами.
Можно использовать Уроки в любых некоммерческих целях с указанием автора и ссылкой на
По всем вопросам обращайтесь на форум www.programmersforum.ru или на E-mail.
Рассматриваемые в данной статье проекты полностью приведены в ресурсах к статье на http://www.programmersforum.ru в разделе «Журнал клуба программистов. Первый выпуск».
Статья из первого выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Как работать с графикой на канве в среде Дельфи. Урок 1–2
25th
Быстрое преобразование Фурье. Практика использования. Часть 2
Традиционно, измерительный прибор представляет собой автономное специализированное устройство, к которому подключаются анализируемые входные сигналы и на выходе которого имеется некий результат. Причем внутренняя архитектура остается неизменной, в отличие от виртуальных приборов. И если для изменения функциональности в первом, требуется существенная переработка схемы и конструкции, то для вторых достаточно изменить программу. Продолжая наш цикл по практике использования быстрого преобразования Фурье [1], сегодня мы с вами научим наш виртуальный прибор работать не только с низкочастотной частью диапазона и аудиоустройствами, но и с высокоскоростной платой сбора данных и для удобства принимать команды управления основными режимами программы с пульта… Данная статья рассчитана в помощь программистам и инженерам-разработчикам в области цифровой обработки сигналов (DSP).
Быстрое преобразование Фурье. Практика использования. Часть 2
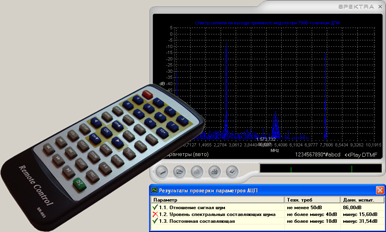
Рис 1. Виртуальный прибор.
DSP – (Digital Signal Processing) преобразование сигналов, представленных в цифровой форме
АЦП – аналого–цифровой преобразователь
Зоны Найквиста – зеркальные отображения спектра при использовании частот выше половины частоты дискретизации (частоты Найквиста)
БПФ/ДПФ – быстрое / дискретное преобразование Фурье.
Зачем-же все это нужно? Как мы уже знаем, виртуальные приборы (ВП) благодаря гибкости в их построении все больше вытесняют дорогостоящие автономные аппаратные решения, таких как осциллографы, спектроанализаторы и др. При этом пользователь не ограничен в выборе средств для анализа и обработки информации, что сводится лишь к изменению программного обеспечения. Приведем пример: вы купили «имиджевый» осциллограф, используете его до поры до времени… и вот настает момент, когда меняется задача и вам понадобился анализ спектра АЦП. Снова затраты? Рассмотрим подробнее…
Краткий экскурс…
В настоящее время основополагающим принципом цифровой обработки сигналов (ЦОС) является преобразование аналогового сигнала в цифровой на промежуточной частоте (перенос спектра). Это позволяет исключить такие недостатки аналогового способа формирования квадратурных сигналов, как: невысокие стабильность и нелинейность, неидентичность каналов, смещение фазы и трудности последующей фильтрации. Кроме того, это несколько снижает жесткие требования к элементной базе по частотным характеристикам. Но правило остается, чем выше быстродействие аппаратной логики, тем больший диапазон наблюдения можно охватить, не прибегая к различного рода программным ухищрениям и ограничениям при выборе частот преобразования по зонам Найквиста, дискретности, тактовой частоты и даже питания и многое–многое другое.
Промышленные платы Hammerhead от Bittware с успехом справляются с этими условиями. Аппаратную часть виртуального оборудования подключают к промышленному компьютеру, как правило, через шины USB или PCI. Первый вариант не требует вскрытия компьютера, а второй дает обмен на порядок быстрее (спецификация USB3.0 увы пока редко встречается). Задача верхнего уровня сводится к окончательному анализу полученных данных с сочетанием сервисного удобства персонального компьютера (ПК). Кроме того, можно выделить лишь небольшое количество фирм, производящих комплекты для создания виртуального оборудования для работы с DSP в области ВЧ/СВЧ. Наиболее крупные из них – Analog Devices, Bittware, Kontron, National Instruments и Texas Instruments.
Аппаратная часть. Краткое описание объекта
Аппаратной основой (см. рис.2-3) виртуального прибора служит 8–ми слотовое шасси VD3U от компании Kontron [2] с промышленным контроллером CP–306, с установленными периферийными cPCI (Compact PCI) платами Hammerhead фирмы Bittware формата 3U* с четырьмя сигнальными процессорами SHARC ADSP–21160 от Analog Devices. Платы обеспечивают прием и обработку в реальном времени (единицы микросекунд) данных от 4–х каналов АЦП с частотой выборки 32 МГц каждый. Питание обеспечивает встроенный в шасси источник +3.3V/+5V/+12V/–12V. Обмен данными осуществляется по PCI шине. Программная оболочка виртуального прибора в комплексе с аппаратной служит для оценки работоспособности, уровня шумов, джиттера, динамического диапазона модулей АЦП.
* 1U – принятая высота корпуса 44 мм

Рис. 2. Тестовое шасси от Kontron

Рис. 3. Промышленная DSP плата Hammerhead
Предпосылки реализации ПО
Как же получить данные с DSP платы? Все достаточно просто. Для доступа к периферии производитель предоставляет набор драйверов и библиотеку <Hil.dll> или <Hil32v60.dll> в зависимости от версии, подробное описание API которой вы можете узнать в документации [2, 3], а полный список экспортируемых функций вы можете просмотреть в модуле <dsp.pas> (см. ресурсы к статье). Нам-же понадобятся следующие:
- dsp21k_open_by_id() – массив указателей на область памяти каждого процессора
- dsp21k_reset_bd() – реинициализация программы в процессоре
- dsp21k_load_exe() – загрузка прошивки в процессор
- dsp21k_start() – старт программы в процессоре
- dsp21k_dl_int() – запись значения в область памяти процессора
- dsp21k_ul_int() – считывание значения с области памяти процессора
- dsp21k_ul_32s() – считывание значения с области памяти процессора (32 бит)
В основу работы программы положен все тот-же алгоритм быстрого преобразования Фурье (БПФ), применяемый к полученным отсчетам сигнала на нижнем уровне и переданными для обработки наверх.
Таким образом, уже можем определить основные требования к нашему виртуальному прибору:
- возможность загрузки прошивки в сигнальные процессоры платы Hammerhead
- визуализация первичных отсчетов, полученных промышленной платой с модуля АЦП
- построение спектра (БПФ/ДПФ) в реальном времени и с возможностью сохранения дампов
- возможность распечатки отображаемых (сохраненных) данных
- управление основными режимами с пульта ДУ
Практика. Разработка ПО и средства отладки
Итак, приступим к основной задаче. Для работы нам понадобится следующее:
- IDE среда разработки Borland Delphi 5–7 (использована для разработки ПО верхнего уровня)
- промышленная плата Hammerhead и модулем АЦП
- генератор сигналов типа Г4–301 или любой другой до 100 МГц
- USB приемник дистанционного управления из материала [4] (см. рис.4)

Рис. 4. USB.IR приемник
- любой ИК пульт дистанционного управления для тестирования
Работа с DSP платой
Внешний вид программы реализован через скиновую систему, более подробно (см. исходники). Рассмотрим основные ключевые моменты по доступу к данным… Прежде всего, необходимо подключить и проинициализировать библиотеку для работы с драйвером (см. листинг 1):
ЛИСТИНГ–1
получаем доступ к драйверу
…
function LoadMyDll: bool;
var HLib: THandle;
NewLib: Boolean;
begin
result:= false;
Hlib := LoadLibrary(’Hil.dll’); // осуществляем динамическое подключение–
NewLib:= (HLib<>0);
if not NewLib then HLib:= LoadLibrary(’Hil32v60.dll’);
if Hlib = 0 then exit;
dsp21k_open_by_id := GetProcAddress(HLib, ‘dsp21k_open_by_id’);
dsp21k_close := GetProcAddress(HLib, ‘dsp21k_close’);
if NewLib then begin
dsp21k_load_exe := GetProcAddress(HLib, ‘dsp21k_load_exe’);
dsp21k_dl_exe := dsp21k_load_exe;
end else begin
dsp21k_load_exe := GetProcAddress(HLib, ‘dsp21k_dl_exe’);
dsp21k_dl_exe := dsp21k_load_exe;
end;
dsp21k_start := GetProcAddress(HLib, ‘dsp21k_start’);
dsp21k_reset_bd := GetProcAddress(HLib, ‘dsp21k_reset_bd’);
dsp21k_ul_32s := GetProcAddress(HLib, ‘dsp21k_ul_32s’);
dsp21k_dl_int := GetProcAddress(HLib, ‘dsp21k_dl_int’);
dsp21k_ul_int := GetProcAddress(HLib, ‘dsp21k_ul_int’);
dsp21k_proc_running := GetProcAddress(HLib, ‘dsp21k_proc_running’);
if @dsp21k_open_by_id = nil then exit; // обрабатываем исключения–
if @dsp21k_close = nil then exit;
if @dsp21k_dl_exe = nil then exit;
if @dsp21k_start = nil then exit;
if @dsp21k_reset_bd = nil then exit;
if @dsp21k_dl_32s = nil then exit;
if @dsp21k_dl_int = nil then exit;
if @dsp21k_loaded_file = nil then exit;
if @dsp21k_ul_int = nil then exit;
result:= true
end;
После чего, заведем массивы для хранения отсчетов комплексных и квадратурных составляющих сигнала dim[], qcos[], qsin[] и расчетных значений спектра bpf[]. И инициализируем процессорную плату (см. листинг 2):
ЛИСТИНГ–2
инициализируем процессорную плату
…
Dim : array [0..10000] of real;
qcos : array [0..10000] of extended;
qsin : array [0..10000] of extended;
bpf : array [0..20000] of extended;
procedure TForm1.init_adc;
var i,j: integer;
p : pointer;
begin
adr_en_data := $50000; // адрес флага разрешения передачи для нижнего уровня
adr_val_data := $52713; // адрес области памяти с данными
cnt_data := 1000; // кол–во отсчетов
id_mod := 0; // 0 – слот для платы сбора данных
id_proc := 1; // 1 – процессор на плате
try
SetLength(ArrData, cnt_data); // задаем массив для отсчетов
// ===============================================================================
// так как мы заранее не знаем, в каком слоте и в каком процессоре загружена
// прошивка, то “пробегаемся” по всем слотам и процессорам и считываем
// возвращаемый указатель (хэндл)
// в двумерный массив–матрицу indata[][], после чего осуществляем сброс, загрузку
// прошивки и старт процессора на плате Hammerhead
// ===============================================================================
for i:=0 to 63 do //
for j:=1 to 4 do begin
p:= dsp21k_open_by_id(i, j);
if p<>nil then indata.PHandle:= p // просто двумерный
end;
dsp21k_reset_bd(indata[id_mod, id_proc].PHandle); // сброс прошивки
dsp21k_load_exe(indata[id_mod, id_proc].PHandle, ‘data\21160.dxe’);// загрузка
// ELF файла
dsp21k_start(indata[id_mod, id_proc].PHandle); // старт прошивки
sleep(10) // делаем на всяк пожарный задержку–
except show_tn(2, ‘Ошибка доступа. Нет модуля или связи…’,’SPEKTRA’); gl_adc:= false end
end;
Получение квадратур сигнала позволяет судить о фазовых неравномерностях в каналах и позволяет производить более тонкую подстройку модулей АЦП. Теория их формирования выходит за рамки данного материала и вряд–ли заинтересует читателя, поэтому приведем лишь сам код (см. листинг 3):
ЛИСТИНГ–3
вычисление квадратур сигнала
…
procedure quadr(auto:boolean;m:integer;var qcos,qsin:array of extended;var dim:array of real;var quad:integer);
var k1, k2, k3, k4, k5, k6, k7, k8, kcos, ksin,
a, aa, b, bb, c, cc, d, dd, f, vcos, vsin: real;
i: integer;
begin
k1:= 0.1169777; // коэффициенты окна–
k2:= 0.4131758;
k3:= 0.7499999;
k4:= 0.9698463;
k5:= 0.9698463;
k6:= 0.7499999;
k7:= 0.4131758;
k8:= 0.1169777;
kcos:= 4*(k1 – k3 + k5 – k7 – k2 + k4 – k6 + k8);
ksin := 4*(k1 – k3 + k5 – k7 + k2 – k4 + k6 – k8);
randomize;
if auto then // формирование псевдопоследовательности
for i:=0 to m do dim:= trunc((512 * sin((sink * i * pi/2) + pi/4) + random(4)) / 4);
m:= ceil(m/32); // отсчет = 32 бита
quad:= m; // кол–во отсчетов
for i:=1 to m do begin
a:= (dim + dim + dim + dim)*k1;
b:= (dim + dim + dim + dim)*k2;
c:= (dim + dim + dim + dim)*k3;
d:= (dim + dim + dim + dim)*k4;
aa:= (dim + dim + dim + dim)*k1;
bb:= (dim + dim + dim + dim)*k5;
cc:= (dim + dim + dim + dim)*k6;
dd:= (dim + dim + dim + dim)*k7;
f := a – c + aa – cc;
vcos := f – b + d – bb + dd;
vsin := f + b – d + bb – dd;
qcos:= vcos + kcos * 10; // Re – действительная часть
qsin := vsin + ksin * 10; // Im – мнимая часть
end
end;
И собственно то, ради чего все задумывалось, выборка данных с нижнего уровня, передача отсчетов в уже знакомую нам процедуру БПФ, поиск максимума и определение среднего уровня шума в полученном спектре (см. листинг 4):
ЛИСТИНГ–4
передача флага разрешения на нижний уровень и синхронное чтение блока данных
…
procedure TForm1.load_adc;
var a : array [1..20000] of double;
b : array [1..20000] of double;
st: array [0..10000] of real;
exp, mant, lab: string;
i, nf, nn, ns, n: integer;
signoise, re, im, l, m, druc, dmax: extended;
begin
series2.Clear; series3.Clear; inwav1.Clear; // очищаем серии при каждой выборке
dsp21k_dl_int(indata[id_mod, id_proc].PHandle, adr_en_data, 1); //set bit enable
// read data
while dsp21k_ul_int(indata[id_mod, id_proc].PHandle, adr_en_data)<>0 do ;
// ожидаем готовности платы
// передаем на нижний уровень указатель на массив ArrData для заполнения–
dsp21k_ul_32s(indata[id_mod, id_proc].PHandle, adr_val_data, cnt_data,
@ArrData[0]);
for i:= 0 to length(ArrData) – 1 do begin
inwav1.add(ArrData);
dim:= ArrData; // заносим значения отсчетов в массив dim[] для
// расчета квадратур
end;
if not gl_viborka then begin // выбор режима визуализации – отсчеты / спектр
series2.Assign(inwav1);
series2.SeriesColor:= clred // fix – цвет серии пропадает
end else begin
// ––––––––––––––––––––––––––––
quadr(false, 999, qcos, qsin, dim, quad);
signoise:= –1000; // fix – задаем минимальный уровень шума
nf:= 999;
ch.Title.Text.Text:= ‘Спектр сигнала на выходе приемного модуля при ‘ +
inttostr(nf–1) + ‘–точечном БПФ’;
nn:= ceil(20000000/nf);
for i:=0 to nf do begin
a:= dim;
b:= 0
end;
re:=0; im:=0;
// ==============================================================================
// получение спектра
// ==============================================================================
fft(a, b, nf, 4, 1);
for i:=1 to nf–1 do begin
st:=sqrt(a*a+b*b); // получаем модуль
if st=0 then st:= 1e–100;
bpf:= 20 * log10(st / nf) // переводим в дБ
end;
m:=0;
for i:=0 to ceil(nf/2–1) do begin
mant:= inttostr(trunc(i*nn/1000000));
ns := trunc((frac(i*nn/1000000))*10000);
exp := inttostr(ns);
if ns<10 then lab:= mant +’ ,’ + ‘000′ + exp;
if (ns<100)and(ns>9) then lab:=mant + ‘,’ + ‘00′ + exp;
if (ns<1000)and(ns>99) then lab:=mant + ‘,’ + ‘0′ + exp;
if ns>1000 then lab:=mant + ‘,’ + exp;
series2.addy(bpf, lab, clblue);
if (series2.YValue > signoise) and (series2.YValue <= 0) then begin
signoise:= series2.YValue;
n:= i
end
end;
// ==============================================================================
// для нормирования по уровню необходимо определить максимум, для этого сканируем
// отсчеты и определяем уровень больший заданного signoise = –1000
// ==============================================================================
signoise:=–1000;
for i:= 10 to nf div 2–5 do begin
if bpf > signoise then begin
signoise:= bpf;
k:= i
end
end;
// ==============================================================================
// поиск среднего шума
// ==============================================================================
nn:= 0;
re := 0;
druc:= –1000;
for i:= 10 to nf div 2–5 do begin
if i < k–10 then begin
re:= re + bpf * bpf;
inc(nn);
if druc < bpf then druc:= bpf
end;
if i > k+10 then begin
re:= re + bpf * bpf;
inc(nn);
if druc < bpf then druc:= bpf
end
end;
re:= –sqrt(re/nn);
// ==============================================================================
// отрисовываем
// ==============================================================================
for i:=0 to ceil(nf/2–1) do series3.Addy(re, ”, clred);
end;
Скомпилировав проект, запустим его на выполнение. Подключив генератор сигналов на вход приемного модуля, подадим тестовый синусоидальный сигнал. В результате уже можем наблюдать отсчеты и при необходимости сами квадратуры (чередующиеся мнимые и действительные составляющие) сигнала (см. рис.5 и 6):
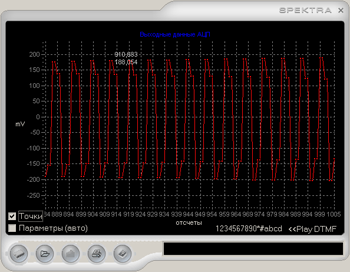
Рис. 5. Отсчеты с АЦП. REAL–TIME
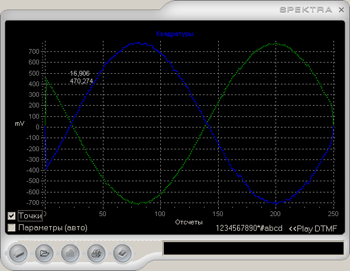
Рис. 6. Квадратуры сигнала с АЦП
Работа с пультом ДУ
Несмотря на то, что данная «фича» не является основной функцией в такого рода программах, а в некоторых случаях и вредной ![]() , но обойти ее стороной никак не могу. Что для этого нужно? Да всего ничего, либо собрать приемник на COM порт и управлять через WinLirc, либо использовать USB.IR приемник, что даст гораздо более стабильные результаты. Было реализовано оба варианта. Чтобы не увеличивать код, сигнатуры нескольких кнопок с ИК пульта были сняты заранее и введены в виде констант. Сама конструкция USB.IR приемника, программа и алгоритм декодирования пакетов были подробно рассмотрены в статье [3], поэтому тут заострять внимание на них не будем и перейдем сразу к коду (см. листинг 5):
, но обойти ее стороной никак не могу. Что для этого нужно? Да всего ничего, либо собрать приемник на COM порт и управлять через WinLirc, либо использовать USB.IR приемник, что даст гораздо более стабильные результаты. Было реализовано оба варианта. Чтобы не увеличивать код, сигнатуры нескольких кнопок с ИК пульта были сняты заранее и введены в виде констант. Сама конструкция USB.IR приемника, программа и алгоритм декодирования пакетов были подробно рассмотрены в статье [3], поэтому тут заострять внимание на них не будем и перейдем сразу к коду (см. листинг 5):
ЛИСТИНГ–5
управление режимами с пульта через приемник USB
…
procedure tform1.ic(i: integer);
begin
case i of // нажатия на кнопки
1: image1.OnClick(nil); // чтение с текущего устройства–
2: image2.OnClick(nil); // загрузить файл WAV/MP3 или потоковые данные (дамп)–
3: image3.OnClick(nil); // переключение режимов ”спектр / отсчеты”–
4: image4.OnClick(nil); // вывод на печать–
5: image5.OnClick(nil); // информация о программе–
6: image6.OnClick(nil) // закрыть программу–
end
end;
// ===============================================================================
// сигнатуры кнопок 1, 2, 3, 4, 5, 6 пульта SR–003
// ===============================================================================
var remote: array[0..5] of string = (
‘12–08–13–07–07–07–13–08–12–08–06–07–06–07–06–08–05–08–06–07–14–07–05–09–05–07–14–06–14–07–12′,
‘13–07–14–07–13–08–05–08–13–07–06–08–13–07–06–07–13–08–06–07–06–07–14–07–06–07–13–08–06–07–12′,
‘13–08–13–07–13–08–13–07–13–07–07–07–06–07–06–08–05–08–06–07–06–07–06–08–06–07–13–08–12–08–11′,
‘13–08–12–08–13–07–13–08–13–08–06–07–13–08–05–08–06–07–06–07–06–07–06–08–05–08–13–07–06–08–14′,
‘13–08–12–07–06–07–06–07–14–08–05–08–05–08–05–08–13–07–06–08–13–07–13–08–06–08–12–07–14–07–12′,
‘14–07–13–07–06–07–06–08–06–07–13–08–13–07–06–08–05–08–06–07–14–07–13–07–13–08–06–07–06–07–12′);
procedure TForm1.tvd3uTimer(Sender: TObject);
var i: integer;
s: string;
j,k,z: smallint;
p: boolean;
begin
if (n5.Checked)and(gl_adc) then load_adc; // визуализация спектра в динамике–
// ===============================================================================
// получение кода кнопки с USB приемника (сигнатуры)
// ===============================================================================
if (GetInfraCode(’ra_usb’) = 1) then Exit;
if DataLength = 0 then Exit;
for i:= 0 to DataLength–1 do begin
s:= s + inttohex(InputInfraData, 2);
if i<> DataLength–1 then s:= s + ‘–’
end;
// ===============================================================================
// проверка сигнатуры с учетом интервала доверия и передача на
// интерпретатор команд
// ===============================================================================
for i:=1 to 6 do
for z:= 0 to DataLength–1 do
if (strtoint(’$’+copy(s,(z*3)+1,2))–dover >=
strtoint(’$’+copy(remote,(z*3)+1,2)))or
(strtoint(’$’+copy(remote,(z*3)+1,2)) <=
strtoint(’$’+copy(s,(z*3)+1,2))+dover) then begin
p:= true;
k:= z
end else begin p:= false; break end;
if p then ic(k)
end;
Осталось проверить работоспособность управления по ИК. Для этого, подключив USB.IR приемник, понажимаем кнопку «2» на пульте, отвечающую за смену режима отображения «спектр / отсчеты» (см. рис.7):
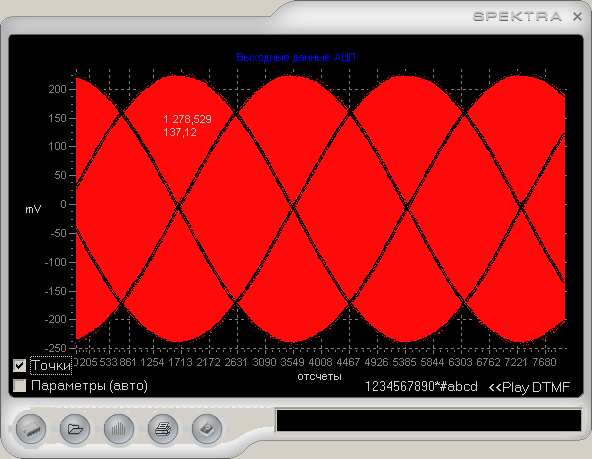
Рис. 7. Отсчеты сигнала с АЦП. REAL–TIME. Переключение режимов с пульта
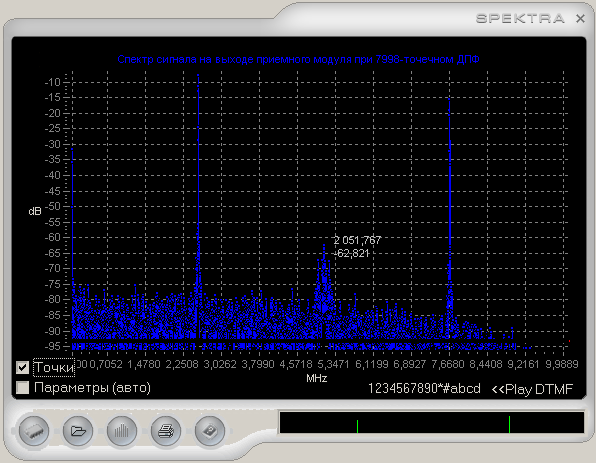
Рис. 8. Спектр сигнала с АЦП. REAL–TIME. Переключение режимов с пульта
Заключение
Рассмотренный виртуальный прибор позволяет сэкономить время и снизить стоимость любой системы сбора и анализа данных с модулей АЦП без привлечения дорогой специализированной аппаратуры, за счет применения гибкого ПО в сочетании с производительностью DSP и простоты «Plug&Play» подключения (cPCI) промышленных плат фирмы Bittware.
Полные исходные тексты и компиляцию виртуального спектроанализатора SPEKTRA (файл fft2.zip) вы можете загрузить на форуме клуба программистов (раздел «Журнал клуба программистов. Первый выпуск») или с сайта автора [5]. Если тема представляет для вас интерес – пишите, задавайте вопросы на форуме http://www.programmersforum.ru
Ресурсы
- С.Бадло. Быстрое преобразование Фурье. Практика использования. – Блог клуба программистов,
05.02.2010 http://pblog.ru/?p=658 и http://www.programmersforum.ru/showthread.php?t=83467
- Data Sheet Kontron Modular Computers GmbH, 2003, ID26799, rev.01
- Practical Design Techniques for Sensor Signal Conditioning, Analog Devices, 1998
- E.Бадло, С.Бадло. USB термометр и дистанционка в одном флаконе. Часть 2. – Радиолюбитель, 2010,
№1, с.48 http://raxp.radioliga.com/cnt/s.php?p=us2.pdf или с форума клуба программистов
http://www.programmersforum.ru/attachment.php?attachmentid=17684&d=1258320468
- Ресурсы и компиляция проекта SPEKTRA http://raxp.radioliga.com/cnt/s.php?p=fft2.zip
Статья из первого выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Быстрое преобразование Фурье. Практика использования. Часть 2
25th
Применение изометрических координат в Delphi
В данной статье рассмотрены методы применения изометрии на канве. Позволяет получить псевдо-эффект 3D на двухмерной плоскости.
Автор: Владимир Дегтярь aka DeKot degvv@mail.ru
Рис. 1 Игровое поле в прямоугольных и изометрических координатах.
1. Построение изометрической матрицы
При создании простых 2D игр (аркады, «стрелялки» и т.п.) обычно для построения игрового поля используется двухмерная матрица с координатами, привязанными к координатам экрана (формы). При этом, направления координат игрового поля и экрана совпадают, и плоскость поля располагается как бы вертикально перед пользователем. Некоторую объемность изображения и эффект перспективы, правда, можно получить за счет манипулирования масштабом графических элементов. Но все это достигается путем значительного усложнения кода программы и требует сложных математических вычислений.
Значительно лучший визуальный эффект можно получить при применении изометрических координат для игрового поля. В этом случае поле для пользователя как бы наклонено под определенными углами по отношению к плоскости, а значит и координатам, экрана. При применении матрицы в изометрических координатах требуется привести координаты ячеек поля и индексы массивов, описывающих такую матрицу к прямоугольным координатам экрана. Для случая, когда матрица игрового поля выполнена в изометрических координатах, можно применить следующие функции для определения индексов массива по координатам формы или же координаты ячеек массива по индексам. Необходимые данные приведены на рисунке 2:
Рис. 2 Необходимые данные.
Думаю понятно, что (см. листинг 1):
ЛИСТИНГ-1
…
mas: array [ 0..m,0..n ] of < тип данных >,
где i — в диапазоне 0 .. m, j — в диапазоне 0..n;
Left, Top – смещение от края формы;
dxc, dyc – шаг координат ячеек матрицы;
dxc := 2 * dyc;
wp, hp – ширина и высота ячейки матрицы в координатах формы;
wp := 2 * dxc; hp := 2 * dyc;
x0 = Left; y0 = Top;
Для определения координат ячейки по индексам (см. листинг 2):
ЛИСТИНГ-2
…
function Kord_X(i , j : byte) : integer;
begin
Result:= ((m + ( j – i)) * dxc ) + Left
end ;
x := Kord_X(i , j);
function Kord_Y(i , j : byte) : integer;
begin
Result := ((i + j) * dyc) + Top
end;
y := Kord_Y(i , j);
Для определения индексов по координатам (см. листинг 3):
ЛИСТИНГ-3
…
function Ind_I (x , y : integer) : integer;
begin
Result := ((m – ((x – Left) div dxc)) + ((y -Top) div dyc)) div 2
end;
i := Ind_I (x , y);
function Ind_J (x , y : integer) : integer;
begin
Result := (((x -Left) div dxc) + (((y -Top) div dyc) – m)) div 2
end;
j := Ind_J (x , y);
При определении координат по курсору мыши , необходимо назначить область “чувствительности” курсора в пределах области , показанной на рисунке оранжевым цветом. Тогда координаты x , y ячейки матрицы по координатам курсора xm , ym определяются следующим образом (см. листинг 4):
ЛИСТИНГ-4
…
procedure TForm1.FormMouseUp (Sender : TObject ; Button : TMouseButton ;
Shift : TShiftState ; xm , ym : Integer) ;
begin
x := ((((xm – Left) + (dxc div 2)) div dxc) * dxc) + Left;
y := ((((ym – Top) + (dyc div 2)) div dyc) * dyc) + Top
end;
2. Графические объекты в изометрических координатах
Для удобства работы с графикой в изометрических координатах следует тщательно подходить к соотношениям размеров объектов и размерами ячеек матрицы. Так, углы расположения матрицы – 27? и 63? указаны не случайно. При работе с пиксельными изображениями форматов BMP, JPG, PNG и аналогичных этот наклон наиболее удобен для отображения различных элементов.
Для движущихся объектов, реализуемых в виде отдельных рисунков или спрайтов следует применять следующие пропорции в размерах: Sprite.Width:= 1 / 3 * wp; Sprite.Height:= 2 / 3 * hp или Sprite.Width:= 2 / 3 * wp; Sprite.Height:= hp.
Здесь: wp и hp — соответственно ширина и высота ячейки матрицы (см. рис.3).
Рис.3 Организация движения спрайта.
При организации движения спрайта приращения по координатам dx и dy должны иметь соотношение 2:1 и соответствовать условию:
N_step = dxc / dx, или N_step = dyc / dy;
Где N_step — количество приращений за один такт (шаг) в цикле или по таймеру ;
dxc , dyc — шаг координат ячеек изометрической матрицы ;
Приведем пример (см. листинг 5):
ЛИСТИНГ-5
…
for i:= 1 to N_step do begin
Sprite(x,y) ; // процедура вывода спрайта на форму в координатах x , y;
x := x + dx ; y := y + dy ;
end;
При выполнении такого условия координаты спрайта всегда после выполнения шага движения попадают в координаты следующей ячейки. При использовании обработчика нажатия клавиш «cтрелки» приращения координат спрайта принимают следующие значения (см. рис.4):
Рис. 4. Приращение координат спрайта
3. Многомерная матрица игрового поля в изометрических координатах.
До сих пор мы рассматривали двухмерную изометрическую матрицу, расположенную в одной плоскости. Для получения реального трехмерного изображения можно применять многомерную матрицу в трех изометрических координатах (см. рис.5):
Рис. 5. Отображение многомерной матрицы в изометрических координатах
Такая матрица описывается следующим массивом (см. листинг 6):
ЛИСТИНГ-6
…
mas_index : array [ 0 .. l , 0 .. m , 0 .. n ] of < тип данных > или…
mas_index [ k , I , j ] ; здесь индекс k находится в диапазоне значений 0..l;
i — 0..m;
j — 0..n;
Работа с такой матрицей в пределах одного слоя аналогична описанию в разделе 1 в соответствии с рисунком 1. Однако при переходе с одного уровня на другой следует учитывать следующие особенности:
- каждый последующий слой в экранных прямоугольных координатах сдвигается на величину dyc
- при организации движения графических объектов приращения координат объекта в экранных
координатах задаются одинаковыми dx := dy и выполняется условие dx * N_step = dxc
В этом случае, при переходах между уровнями (при использовании обработчика клавиш «стрелки») изменения индексов ячеек матрицы следующие (см. таблицу и рисунок 6):
Таблица. Изменения индексов ячеек матрицы

Рис. 6. Визуализация переходов
Далее, после перехода на следующий уровень обработка кода происходит как с двухмерной матрицей с учетом новых индексов в массиве индексов.
Заключение
Пример применения многомерной изометрической матрицы приведен в ресурсах к статье на http://www.programmersforum.ru в разделе «Журнал клуба программистов. Первый выпуск». В следующих уроках мы научимся работать с графикой на канве в среде Дельфи
Статья из первого выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Применение изометрических координат в Delphi
25th
Простейшая программа WinAPI на C++
Многие, кто переходит с «учебного» ДОСовского компилятора вроде Borland C++ на визуальное программирование быстро запутываются в сложных библиотеках типа MFC или VCL, особенно из-за того, что новые создаваемые проекты уже содержат с десяток файлов и сложную структуру классов. Рано или поздно встает вопрос: «…а почему нельзя написать оконную программу с простой линейной структурой, состоящую из одного файла .cpp?» На самом деле можно. Для этого нужно работать с низкоуровневыми функциями операционной системы – API.
Простейшая программа WinAPI на C++
 Дмитрий Федорков
Дмитрий Федорков
dsDante www.programmersforum.ru
Windows API (application programming interfaces) – общее наименование целого набора базовых функций интерфейсов, программирования приложений операционных систем семейств Windows и Windows NT корпорации «Майкрософт». Является самым прямым способом взаимодействия приложений с Windows.
Википедия
Зачем нам вообще API
Все что делает любая программа – делает либо непосредственно с помощью инструкций процессора, либо обращаясь к функциям биоса (хотя их прямые вызовы используются всё реже), либо через системные функции (API). К последним относится: прорисовка окон, получение координат мыши, чтение файлов и т. д.
WinAPI – это основа, в который должен разбираться любой программист, пишущий под Windows, независимо от того, использует ли он библиотеки вроде MFC (Microsoft Visual C++) или VCL (Borland Delphi / C++ Builder). Часто бывает проще написать простенькую программу, состоящую из одного файла, чем настраивать относительно сложный проект, созданный визардами. Я не говорю уже, что программа получается гораздо оптимизированнее (всё-таки низкоуровневое программирование) и в несколько раз меньше. К тому же у них не возникает проблем совместимости, если у конечного пользователя не хватает каких-т
о библиотек, чем иногда грешит MFC.
Наша программа
Напишем простую программу: окно, в нем – синусоида, которая движется влево, как график функции
y = sin (x + t). Если кликнуть мышкой по окну, анимация приостановится, или наоборот продолжится. Чтобы было проще разобраться, я сразу приведу весь исходный код, а потом прокомментирую ключевые места. Попробуйте самостоятельно модифицировать разные части программы, пробуйте оптимизировать мою программу, может вам даже удастся найти ошибки в коде (см. листинг):
ЛИСТИНГ
тестовая программа
…
#define WIN32_LEAN_AND_MEAN
#include <windows.h>
#include <cmath>
LRESULT CALLBACK WindowProc (HWND, UINT, WPARAM, LPARAM);
HDC dc;
int WINAPI WinMain (HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
// Create window
WNDCLASS wc = {0};
wc.style = CS_OWNDC | CS_HREDRAW | CS_VREDRAW;
wc.lpfnWndProc = WindowProc;
wc.hInstance = hInstance;
wc.hCursor = LoadCursor (NULL, IDC_ARROW);
wc.lpszClassName= L”CMyWnd”;
RegisterClass (&wc);
HWND hWnd = CreateWindow (L”CMyWnd”, L”WinMain sample”, WS_OVERLAPPEDWINDOW, CW_USEDEFAULT, 0, 320, 240, NULL, NULL, hInstance, NULL);
dc = GetDC (hWnd);
ShowWindow (hWnd, nCmdShow);
// Message loop (timer, etc)
SetTimer (hWnd, 1, USER_TIMER_MINIMUM, NULL);
MSG msg;
while (GetMessage(&msg,NULL,0,0) > 0)// while not WM_QUIT (0) nor some error (-1)
{
TranslateMessage (&msg);
DispatchMessage (&msg);
}
return msg.wParam;
}
// Message processing function
LRESULT CALLBACK WindowProc (HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam)
{
static bool Move = true;
static int Phase=0, Width, Height;
switch (message)
{
case WM_LBUTTONDOWN:
case WM_RBUTTONDOWN:
Move = !Move;
// no break
case WM_TIMER:
if (Move)
Phase++;
// no break
else
break;
case WM_PAINT:
Rectangle (dc, -1, -1, Width+1, Height+1);
MoveToEx (dc, 0, Height * (0.5 + 0.3*sin(0.1*Phase)), NULL);
for (int i=0; i<Width; i++)
LineTo (dc, i, Height * (0.5 + 0.3*sin(0.1*(i+Phase))) );
break;
case WM_SIZE:
Width = LOWORD(lParam),
Height = HIWORD(lParam);
break;
case WM_KEYDOWN:
if (wParam != VK_ESCAPE)
break;
// else no break
case WM_DESTROY:
PostQuitMessage (0);
}
return DefWindowProc (hWnd, message, wParam, lParam);
}
Обращаю ваше внимание на то, что эта программа писалась под Visual C++. У Билдера может быть проблема из-за заголовка <cmath>, вместо него нужен <math.h>. Для этой программы понадобится пустой проект с единственным файлом .cpp. В Visual Studio в свойствах создаваемого проекта нужно отметить галочку «Empty project». Итак, приступим…
Пройдемся по коду
В программе мы добавляем заголовочный файл <cmath>, который нужен для расчета синусоиды, и <windows.h>, который содержит все функции WinAPI. Строчка #define WIN32_LEAN_AND_MEAN отключает некоторые редко используемые функции и ускоряет компиляцию.
Функцию WindowProc() пока пропустим, оставив на сладкое.
HDC – контекст устройства рисования. Не будем подробно останавливаться на графике – это не основная тема статьи, да и используется не очень часто. Скажу лишь, что эта переменная глобальная, потому что используется в обеих функциях. Надо добавить, что буква ”H” в типе данных WinAPI (в “HDC”) обычно означает ”Handle” (хэндл), т.е. переменную, дающую доступ к самым разным устройствам, объектам и прочим сущностям WinAPI. Хэндл – представляет собой обычный указатель, работа с которым зависит от контекста (от типа переменной). Вообще, хэндлы – сложная тема, без к
оторой тоже поначалу вполне можно обойтись.
Теперь главное (main) – точка входа. В консольных программах функция main может возвращать либо void, либо int, а также может иметь или не иметь аргументы (int argc, char **argv). Итого 4 варианта. В нашем случае используется функция WinMain(), которая может иметь только такой вид, как в примере. Слово WINAPI (которое подменяется препроцессором на __stdcall) означает, что аргументы функции передаются через стек*. Аргумент HINSTANCE hInstance — хэндл текущего процесса, который бывает нужен в некоторых ситуациях. Назначение следующего аргумента HINSTANCE hPrevInstance весьма смутное, известно только, что э
та переменная всегда равна NULL. В исходниках квейка можно даже найти такую строчку: if (hPrevInstance != NULL) return 0.
* подробнее – в учебниках по ассемблеру
Аргумент LPSTR lpCmdLine – командная строка. В отличие от консольного main (int argc, char **argv), эта строка не разделена на отдельные аргументы и включает имя самой программы (что-нибудь типа “C:\WINDOWS\system32\format.com C: \u”). Далее int nCmdShow определяет параметры окна, указанные например, в свойствах ярлыка (это будет нужно при создании окна).
Перейдем, наконец, к выполняемому коду. В первую очередь нам нужно создать окно. Структура WNDCLASS хранит свойства окна, например текст заголовка и значок. 4-ре из 9-ти полей структуры должны быть нулевые, поэтому сразу инициализируем ее нулями. Далее CS_HREDRAW | CS_VREDRAW означает, что окно будет перерисовываться при изменении размера окна. wc.hInstance задаёт текущий процесс (тут-то и понадобился этот аргумент из WinMain). Еще также нужно явно указать мышиный курсор, иначе, если это поле оставить нулевым, курсор не будет меняться, скажем, при переходе с границы окна на са
мо окно (попробуйте сами). wc.lpfnWndProc – это адрес функции, которая будет обрабатывать все события. Такие как нажатие клавиши, движение мыши, перетаскивание окна и т. д. После знака ”=” просто указываем имя нашей функции. Позже мы напишем эту функцию, которая и будет определять реакцию программы на интересующие нас события.
WNDCLASS – это не само окно, а класс (форма), экземпляр которого и будет нашим окном. Но перед созданием окна нужно зарегистрировать в системе этот класс. Задаем его имя в системе CMyWnd и регистрируем класс.
Функция создания окна CreateWindow() достаточно простая и вместо того, чтобы перечислять все ее аргументы, опять сошлюсь на интернет. Кому мало одиннадцати аргументов, могут попробовать функцию CreateWindowEx(). Обратите внимание – все строковые аргументы предваряются буквой L, что означает, что они – юникодовые. Для многих функций WinAPI существует по два варианта: обычный ANSI и юникодовый. Соответственно они имеют суффикс A или W, например CreateWindowA и CreateWindowW. Если вы посмотрите определение функции в <windows.h>, то увидите что-то типа #define CreateWindow
CreateWindowW. Вместо CreateWindow() мы можем явно вызывать CreateWindowA() с обычными строками (без приставки L).
Описание GetDC() и ShowWindow() снова пропущу (кому интересно – тот легко найдет).
Дальше начинается самое интересное – работа с событиями. Для начала создадим таймер, который будет генерировать соответствующее событие 65 раз в секунду (фактически максимальная частота, по крайней мере для Windows XP). Если вместо последнего аргумента SetTimer() написать имя подходящей функции, она будет вызываться вместо генерации события.
Далее идет то, что называется message loop – цикл обработки событий. Мы принимаем событие и обрабатываем его. В нашем случае можно убрать TranslateMessage(&msg), но эта функция понадобится, если на основе этого примера кто-нибудь будет создавать более сложную программу (с обработкой скан-кодов клавиатуры). Если мы получаем событие выхода программы, то GetMessage() возвращает ноль. В случае ошибки возвращается отрицательное значение. В обоих случаях выходим из цикла и возвращаем код выхода программы.
Теперь займемся функцией обработки событий WindowProc(), которую мы оставили на сладкое. Эта функция вызывается при любом событии. Какое именно сейчас у нас событие – определяется аргументом message. Дополнительные параметры (например, координаты мыши в событии “мышь двинулась”) находятся в аргументах wParam и lParam. В зависимости от того, чему равно message, мы совершаем те или иные (или вообще никакие) действия, а потом в любом случае вызываем DefWindowProc, чтобы не блокировать естественные реакции окна на ра
зные события.
Вообще то, что я сделал с оператором switch больше похоже на стиль ассемблера и порицается большинством серьезных разработчиков. Я имею в виду сквозные переходы между case- ми (там, где нет break). Но пример простой, к тому же у меня было настроение “похакерить”, так что не буду лишать вас удовольствия разобраться в этом коде.
Имена констант message говорят сами за себя и уже знакомы тем, кто работал с MFC. При событии WM_PAINT рисуем белый прямоугольник, а на нём — чёрную синусоиду. На каждый WM_TIMER смещаем фазу синусоиды и перерисовываем ее. На клик мыши запускаем или останавливаем движение, при этом, если нажать обе кнопки одновременно, то фаза увеличится ровно на 1, для чего здесь и убран break (см. рисунок). При изменении размера окна мы обновляем переменные Width и Height за счёт того, что в lParam хранятся новые размеры. Всегда нужно вручную обрабатывать собы
25th
Установка отступов для логических блоков программы
Данная статья раскрывает некоторые тонкости алгоритма одного из элементов форматирования исходных текстов программ. Рассчитана на широкий круг программистов и не требует специальных знаний.
Автор: Utkin www.programmersforum.ru
Краткий экскурс…
Прежде всего, как советуют классики, нужно определиться со структурами данных, в которых будет проводиться основная работа по форматированию. Большинство языков программирования имеют поддержку массивов различных типов данных. Поэтому будем представлять входящий текст программы как массив строк. Теперь рассмотрим вопрос о представлении отступа. В зависимости от реализации это может быть задание отступа отрисовки символов в компоненте вывода текста на экран, либо задание символа табуляции (в случае если транслятор позволяет использовать табуляцию в программах), либо просто определенное количество символов пробела в качестве заменителя символа табуляции. Теперь о самих отступах – все, что нам требуется, это либо добавление в начало строки определенного символа (или группы символов, в случае если символ табуляции будет заменен на пробелы), либо передача информации компоненту отрисовки текста программы о величине отступа от левого края для конкретной строки. Важное условие – величина отступа меняется в зависимости от уровня вложенности логических блоков программы.
Еще немного конкретики – нам нужно знать, как в данной программе представляются операторные скобки. Дадим данному понятию свое определение – маркер начала логического блока и маркер конца логического блока. Для нашего алгоритма это просто строка–образец, содержащая в себе операторную скобку.
Также нам нужно где-то помнить текущую величину отступа, в чем она будет выражаться – в пикселях отступа для компонента, число символов табуляции или число символов пробела, зависит только от конкретных реализаций данного алгоритма. Теперь введем также определение шага отступа – то есть, на сколько смещается отступ от левого края в зависимости от уровня вложенности логических блоков программы. Так, в таблице величина отступа для содержимого логического блока будет равна сумме общего отступа и отступа текущего блока, а шаг отступа будет равен отступу текущего блока:
Таблица. Условное представление логических блоков:

В общем, имеющейся информации уже достаточно для построения алгоритма установки отступов для логических блоков программы.
Итак, приступим
Сначала обычно имеет место быть инициализация, то есть создание необходимых структур и установка конкретных значений для величины отступа, шага отступа, маркеров начала и конца логических блоков. Весь алгоритм будет представлять собой один цикл по всем элементам массива строк – хранилище нашего кода программы:
1. Получим очередную строку программы из массива строк.
2. Удалим из левой ее части все пробелы и символы табуляции (если они там имеются).
3. Получим первую лексему языка программирования из нашей строки. Это может быть символ или ключевое слово.
4. Сверим наше слово с маркерами
5. Если слово является маркером начала логического блока, то
5.1. В зависимости от особенностей реализации – добавим в начало строки символы табуляции (или символы пробела) либо передадим информацию в компонент по отрисовке строк программы в соответствии с текущим отступом.
5.2. Увеличим отступ на величину шага отступа.
5.3. Закончим текущую итерацию цикла
6. Если слово является маркером конца логического блока, то
6.1. Если разница между отступом и шагом отступа будет больше или равно нулю, то уменьшим отступ на величину шага отступа.
7. В зависимости от особенностей реализации – добавим в начало строки символы табуляции (или символы пробела) либо передадим информацию в компонент по отрисовке строк программы в соответствии с текущим отступом.
Некоторые комментарии по пунктам алгоритма*
Второй пункт алгоритма нацелен на удаление существовавшего до этого форматирования. Программист или какая–либо другая программа могли использовать другие принципы форматирования кода, и если бы данного пункта не было, то возникла–бы путаница: отступы наложились друг на друга и результат отличался от ожидаемого.
Реализация третьего пункта зависит от конкретного языка программирования программу, на котором предстоит форматировать. Для многих языков программирования лексему можно определить как последовательность символов (или одиночный символ) отделенный от другой лексемы разделителем, в качестве которого могут выступать пробелы, символы табуляции и другие лексемы – спецсимволы, скобки т.д.
Пункты 5 и 6 могут быть изменены в зависимости от языка программирования. Это связано с тем, что некоторые из языков воспринимают регистр введенных лексем, а некоторые его игнорируют. Если программа, которую нужно форматировать составлена на языке программирования не чувствительного к регистру, то перед проверкой первой лексемы на равенство маркерам начала и конца логического блока их необходимо преобразовать к одному регистру.
Пункт 5.3 предназначен для того, чтобы сразу не сдвигался маркер начала логического блока.
Пункт 6.1 нужен для того, чтобы отступ не получил отрицательного значения (не стал выступом). По сути, программа рассматривается как некий поток команд для стека. Итак, перед нами стек – это текущая величина отступа. Каждый маркер начала логического блока увеличивает его на величину шага отступа, а каждый маркер конца логического блока уменьшает его на ту же величину. Т.е. пункт 6.1. ответственен за защиту от опустошения стека: нельзя брать из стека больше, чем там имеется. В тоже время как в самой программе такие ошибки вполне возможны – к примеру, программист при наборе программы мог забыть поставить одну (или несколько) из открывающих операторных скобок.
* такой способ весьма прост, но имеет один недостаток – его нельзя использовать для языков
программирования, в которых отступы влияют на процесс вычисления программы – это Питон,
некоторые версии Хаскела и т.д.
Заключение
Данный алгоритм является только примером способов обработки исходных текстов программ. Как правило, в настоящих средах разработки подобные алгоритмы входят в состав более сложного алгоритма включающего в себя также функции по разделению строки на синтаксические элементы, автозамены, приведение к заданному регистру, удалению лишних пробелов и т.д. В тоже время он дает начальное представление о работе подобных систем в редакторах текста (не обязательно редакторах исходного текста программ).
Реализация рассмотренного алгоритма на Дельфи 7 прилагается в ресурсах к статье на http://www.programmersforum.ru в разделе «Журнал клуба программистов. Первый выпуск».
Статья из первого выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Установка отступов для логических блоков программы
20th
Апр
Детей будут усыплять :)
Деактивацию и перевод в режим сна заигравшихся в видеоигры детей осуществляет устройство PediSedate, путем введения наркоза через гарнитуру.

Статья из второго выпуска “журнала ПРОграммистов”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
