

Последние записи
- Автоматическое уничтожение объектов
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
29th
Сен
 Разработчик интерфейс пользователи. Часть 2
Разработчик интерфейс пользователи. Часть 2
![]()
По своей работе я оказался в роли разработчика программы, работающей с базой данных. Самое основное в этом процессе — быстрый ввод информации в программу. Форма для ввода данных была создана еще до меня, и пользователи не один год работали с нею. Однажды, по стечению обстоятельств, мне пришлось сменить профиль и перейти из роли разработчика в роль пользователя.
Продолжение. Начало цикла смотрите в предыдущем номере журнала…
Александр Демьяненко
by Grenles GRENLES@yandex.ru
Лишние мелкие движения
Одно дело, когда ты пишешь код и в течение нескольких минут его тестируешь, и совсем другое, когда ты работаешь с ним. Повторюсь и поставлю акцент на слово «работать». Эти процессы весьма разнятся. Когда пишешь код — ты решаешь задачи реализации. Когда работаешь с исполняемым кодом — решаешь задачи эксплуатации. И вот при эксплуатации, как всегда и бывает, возникает множество вопросов и нюансов — тех самых, которые так не любят доделывать разработчики, считая этот процесс бесконечным и ненужным. Число исписанных страниц с замечаниями в моем блокноте каждый день росло. Не скажу, что я исправил все ошибки и неточности, — до сих пор мой список еще не исчерпан, и тому есть разные причины. Однако эту ошибку — на мой взгляд, неудобную, — я исправил. Вполне допускаю, что найдутся пользователи, которых устраивает старый вариант реализации ввода данных, но мне кажется новый вариант лучшим.
****** Самое главное для хорошего разработчика — уметь признать и исправить собственные ошибки. Впрочем, это умение не помешает любому человеку…
Итак, вернусь к собственному примеру (см. Рис. 1):
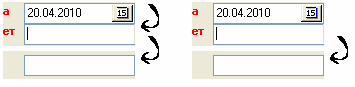
Рис. 1. Часть формы ввода информации в базу данных
Обычный процесс ввода информации идет так: ввод даты, лицевого счета, данных — и дальше все по кругу. Где же неудобство? На первый взгляд, его тут вовсе нет. Секрет кроется в исходных данных. Дело в том, что дата изменяется только от листа к листу с данными; в пределах одного листа дата неизменна. Вот и выходит, что операция ввода даты в пределах одного листа — лишняя. Если на листе 30 записей, то надо выполнить, условно говоря, 3х30 действий. Выкинув цикличный ввод даты, число действий можно сократить до 2х20+1 (первоначальный ввод даты). Есть два решения этой проблемы. Первый — каждый раз оставлять дату неизменной; тогда при получении фокуса ввода в поле даты пользователь должен нажимать какую-либо клавишу, чтобы пропустить ввод даты. Это чуть лучше, но не избавляет от лишних действий. Второй способ — единожды дать пользователю ввести дату, а потом автоматически переключать фокус ввода только между полями лицевого счета и данных. При необходимости сменить дату пользователь может воспользоваться или мышью,
или специальным сочетанием клавиш.
Кажется, это все мелочи. Но наша жизнь как раз и складывается из разных мелочей, а если их предусмотреть и учесть, то пользователю будет удобно и приятно, да и ваш статус в их глазах заметно вырастет.
Проблема безусловной интерпретации данных
Всем известен Microsoft Excel, входящий в состав Microsoft Office. Ни для кого не является секретом, что эта программа стала де-факто основным средством ведения учета и документооборота в различных компаниях и фирмах. Укажу на одно неудобство, заложенное в эту программу, которое меня раздражает тем, что никто не удосужился спросить, а надо ли мне это. Не буду стопроцентно утверждать, но та же проблема есть и в Open Office, который является бесплатной альтернативой платному продукту от Microsoft.
У компании Microsoft есть одно решение в части интерпретации вводимых данных. Думаю, многие сталкивались с ситуацией, когда при вводе данных в ячейку вида «9/12» или «9-12» программа Excel автоматически переводит эти данные в формат даты (см. Рис. 2). Раздражает отсутствие вариантов: перевод происходит автоматически (о том, как это исключить, напишу ниже). За меня кто-то решил, что надо поступать только так, а не иначе. Честно скажу: я пытался найти опцию в настройках, как-то разрешающую это действие, и не нашел.
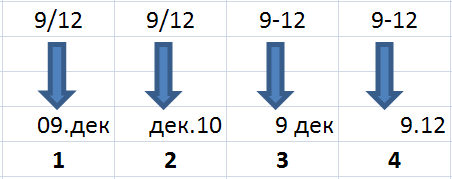
Рис. 2. Интерпретация данных MS Excel до и после ввода
В зависимости от настроек предпочтений результат отображения даты может быть различным, как это и показано на Рис. 2. Для случаев 1, 2, 3 явно видно, что программа интерпретировала данные как дату. При высоком темпе работы, усталости оператора, большом объеме данных эту «ошибку» можно запросто пропустить. В дальнейшем она может вызвать совершенно непредсказуемые неприятности при обработке данных, например, потерю точности, если предположить, что данные мог вводить один человек, а использовать их — другой. У второго человека может не быть информации, что «9 декабря» — это не дата, а «9/12». В случае 4 на Рис. 2 (скажу сразу: я сделал его искусственно, но такой вариант возможен), кажется, все в том же виде, как и введено, и такую ситуацию тем более можно пропустить. На самом же деле «9.12» — это не число, а дата «9.12.2010», просто в этом формате на экране год не отображается.
Допустим, что пользователь заметил ошибку и решил ее исправить. Пользователь у нас все-таки человек умный и не один год работает за компьютером, то есть не «чайник» и не совсем уж глуп — он некий «середнячок», имеющий навыки и опыт. Поэтому он решил сделать обратную операцию — «вернуть формат». Что он увидит, думаю, опытные пользователи и программисты догадаются: вовсе не то, что хотел увидеть в результате (см. Рис. 3):
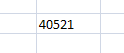
Рис. 3. Итог попытки «вернуть формат назад»
Как видно, пользователь получил странное число «40521», а не «9/12» как бы ему того ни хотелось. Почему? Программисты знают ответ: а потому, что кто-то за нас при разработке программы решил, что это число дней, прошедшее с даты «01.01.1900». С точки зрения такой логики, программа сделала все верно и сделала из даты — число. Но только тут кроется еще одно умолчание, которое и ошибкой не назовешь, но в данном случае — это ошибка, так как ожидания пользователя естественным образом обманывает.
Самое интересное во всей этой ситуации с превращениями, что «9/12» и не число, и не дата, а ТЕКСТ (!). В данном случае есть как минимум два выхода из этой ситуации: либо задавать пользователю вопрос: «Интерпретировать данный текст как дату?», либо где-то в настройках программы сделать «флажок», разрешающий эту операцию.
Ручное решение данной проблемы таково: сделать ячейки, куда предполагается ввод данных подобного вида заранее «текстового» формата. Как известно, «текстовый» формат Excel никак не интерпретирует. Сложность может возникнуть в том случае, когда заранее неизвестно, в какую ячейку могут быть введены данные подобного вида. Если сделать все ячейки «тестом», то это плохо для данных формата «числовой», так как ни одна математическая операция их не воспримет как число, а выдаст ошибку.
Казалось бы, одно удобство, а столько сложностей! Не открою никакого секрета и в этот раз, если скажу, что большинство программ в качестве промежуточного формата для обмена данными использует формат файла MS Excel. Разработчики, зная такую особенность этой программы, заранее делают все ячейки текстового вида (правда, это делают грамотные и уважающие пользователя разработчики, некоторые забывают) и уже потом выгружают данные в файл. Точность данных сохраняется, но удобства не прибавляется. И к тому же возникает задача преобразовать формат ячейки «текстовый» в формат ячейки «числовой» для данных, являющихся числами, чтобы дать возможность пользователю выполнять математические операции над числами. В итоге безусловное «удобство» оказывается источником множества лишних действий.
Интерпретация как таковая
Обобщу проблему интерпретации, но перед этим скажу, как она касается интерфейса. Известно, что человек не менее 80% информации воспринимает с помощью зрения. Таким образом, мы сначала видим что-то, а потом неосознанно запускается процесс сопоставления увиденного с чем-то ранее известным. В случае, когда подсознательно сопоставить не получается, запускается процесс осознанного сопоставления, или, иначе говоря, — логической интерпретации данных. Значит, то, что нам покажут и что мы увидим, весьма важно, а это как раз и есть интерфейс.
Возьмем текст «14-12-10». Что это такое? Мне кажется, большинство ответит: «это дата 14 декабря 2010 года». А почему? Например, потому, что выше я вел речь о дате и в нашей кратковременной памяти остался контекст, в котором ключевым словом было «дата». А так как другого контекста нет, то мозг его автоматически распространил на новые увиденные данные.
Итак, воспринимаемая информация сильно зависит от того, в контексте какой информации мы ее узнаем. Но ведь эти цифры могут являться номером телефона, кодом для сейфа, частью ряда убывающей арифметической последовательности. Интерпретаций можно придумать множество.
Вернемся к обсуждению примера с датой. Я немного подкорректирую цифры, чтобы было «удобно» поиграть ими: заменю первую «1» на «0». Итак, имеем дату «04-12-10». Применительно к компьютерной технике задам другой вопрос: «Что это за дата?». На первый взгляд, это «4 декабря 2010». Но ведь может быть и «10 декабря 2004 года». Ответ зависит от того, как в программе заложена интерпретация входных данных. Есть несколько нотаций даты, при этом «число-месяц-год» могут меняться местами как угодно. Мало того, если поглядеть представления, какие нам предлагают различные программы, то задача интерпретации данных без контекста вообще не решаема. Приведу всего лишь два формата, в котором все представлено двумя числами.
- ДД.ММ.ГГ
- ГГ.ДД.ММ
Может быть «день-месяц-год», а может быть и «год-день-месяц». Хотя в большинстве случаев принята нотация «день-месяц-год», возможны разные варианты.
Пользователь привык к тому, к чему его когда-то «приучили», и не обязательно вы. Вас тоже к чему-то когда-то кто-то приучил, да еще так, что некоторые вещи вы считаете безусловными и сами собой разумеющимися.
Как дополнительную информацию полностью процитирую источник [12]*******
******* «Приведу реальный пример, как рекламный бюджет выкидывается псу под хвост (нам этот случай рассказывали на семинаре московские рекламисты). Крупная компания-производитель зубной пасты решила выйти на рынок в арабские страны и дала задание агентству найти самый эффективный рекламный ход из уже запущенных, чтобы затраты были по минимуму. Агентство выдало грамотное обоснование: по всей Европе стоят рекламные щиты, на которых нет ни одного слова. Значит, ничего переделывать не надо, а надо просто заказать их побольше и поставить в арабских странах. Компания идею одобрила. На эти цели было выделено около миллиона долларов. Что из себя представлял рекламный щит? Всего три фотографии: на первой молодой парень улыбается желтыми зубами, на второй — чистит зубы, на третьей — улыбка белоснежная. И все это на фоне рекламируемой зубной пасты. Установили щиты в арабских странах. Продаж — ноль! Заказали исследование компании по мониторингу — почему нет продаж. Ответ был быстр: рекламные щиты не возымели своего
действия потому, что в арабских странах читают справа налево…»
Думаю, смысл всего сказанного достаточно прозрачен.
******* Приучая пользователя к чему-либо, подумайте, что он сам об этом думает.
Стандартные сообщения об ошибках. Это…
Прошли те времена, когда каждый придумывал свои форматы, методы сопряжения, способы обмена и решал вопросы совместимости своих данных с данными других коллег. Все эти сложности решила стандартизация.
Стандартизация — это способ согласованного взаимодействия разработчиков между собой. В большинстве случае это очень хорошо. Но, если задуматься, это же одновременно и источник различных проблем. Почти всегда и все отступают и отклоняются от стандартов в угоду различным причинам. И, как часто это бывает, о том, что было отступление от стандарта, либо умалчивают, либо забывают сообщить (что, по сути, одно и то же).
Долго думал, какой же пример привести, чтобы он был понятным и наглядным. Были соображения сравнить две версии MS Office 2003 и MS Office 2007 в плане значительной смены интерфейса и появления новых элементов. В определенной степени этот пример подходит под заданную тему «стандарты», но все же не нагляден. А кто сказал, что отображение элементов интерфейса в одной программе есть стандарт и остается неизменным много лет подряд? Пожалуй, так же подумали разработчики MS Office — и кардинально изменили интерфейс своих приложений.
Были мысли поговорить о цветовых схемах различных программ, но это тоже не в тему. Во-первых, если разобраться, то практически любой уважающий себя разработчик дает возможность пользователю сменить «скин» («оболочку», внешний вид) своей программы, в том числе шрифты и цвета отображаемых элементов. Собственно говоря, идея была раскритиковать программы, где это сделать невозможно, а подбор и сочетание цветов неприятны при использовании программы, но таковых сейчас очень мало или почти нет. Даже на некоторых «продвинутых» сайтах и то есть возможность смены оболочки.
В итоге решил написать вот про что. Как известно, предугадать и исправить все возможные ошибки нереально. В современных языках программирования есть различные средства для выхода из ошибочных ситуаций, которые не были предусмотрены разработчиком. Одно из них — обработка исключений. Это хорошее средство, шаг навстречу пользователю. Даже если разработчик забыл где-то вставить отработку возможной ошибки, за него это сделает операционная система. Но в данном случае речь немного о другом. Точнее сказать, взгляд под другим углом зрения. Обработчик ошибочной ситуации выводит на экран сообщение об ошибке, в котором указывается какая-то информация об ошибке. То есть отработка ошибочной ситуации «вывод информации» — это уже стандарт. Сложность в другом: каждый делает это по-своему!
Возьмем, например, сеть Интернет. Все пользователи рано или поздно сталкиваются с сообщением об ошибке 404, которое появляется в том случае, когда запрашиваемая страница не найдена. Это логично: когда нет запрашиваемого источника — надо выводить об этом информацию. В Интернете есть даже целый сайт, посвященный тому, что на нем собраны все возможные варианты ответов для пользователя с сообщением об этой ошибке. Пока все верно и правильно.
Теперь рассмотрим программу (даже неважно, какую именно), в которой может возникнуть любая ошибка. Как известно, в исключительной ситуации пользователю будет выдано сообщение об ошибке. В лучшем случае будет указан номер ошибки и поясняющий текст, в худшем — просто номер ошибки, а там — догадывайся сам, как хочешь. Пока все вписывается в стандарт — пользователь информируется.
Ошибка в этом случае совершенно другая, и заключается она как раз в том, что пользователь информируется об ошибке. Это стандартно и признак хорошего тона — информировать об ошибке, но, давайте перейдем на сторону пользователя. Мне сообщили об ошибке, написали ее номер и текст. И что мне делать дальше? Закрыть сообщение и аварийно завершить программу. При повторном выполнении тех же действий снова случится та же ошибка. А мне, как пользователю, необходимо выполнить некоторые действия с этой программой, но разработчик не дает мне такой возможности.
С моей, пользовательской, точки зрения, сообщение об ошибке означает то, что мне в красивой форме говорится о том, что я глуп. А если подумать еще чуть-чуть, мне это ни о чем не говорит, кроме того, что разработчик не захотел позаботиться обо мне. Какое мне дело, что произошло деление на ноль, или переполнение стека, или страница не найдена? Мне нужен конечный результат, которого я хочу достичь, используя предлагаемые разработчиком средства, а сообщения об ошибке мне только мешают, обрывая мой путь к достижению цели.
Если задуматься над этой задачей, то решение может быть таким. Конечно же, есть ошибки, которые просто неизбежны, фатальны, и ничего с ними нельзя сделать. Отказ оборудования, отсутствие страницы на сайте, сбой локальной сети и прочее — эти причины предвидеть сложно. Но нужно постараться сделать так, чтобы у программного продукта было предусмотрено свое решение этих проблем, помимо стандартного сообщения об ошибке.
При отсутствии страницы на сайте можно посоветовать пользователю перейти на другие страницы или предложить другой способ поиска нужной информации. А если серьезно, то на сайтах не должно быть устаревших и отсутствующих страниц.
Если это программа, то, например, обрыв сетевого соединения не должен вызывать потерю данных, особенно если идет закачка из Сети большого по объему файла. Кстати, до сих пор этой болезнью болеет Internet Explorer — при обрыве соединения или таймауте (времени, в течение которого источник не отвечает), при повторной попытке файл начинает закачиваться сначала, а не с места обрыва. Наверное, в том числе и это стало одной из причин появления программ-загрузчиков информации из Сети. В FireFox такой проблемы нет, браузер при обрыве соединения предлагает докачать по возможности файл. То есть разработчик должен предусмотреть не просто вывод «сообщение об ошибке», а реакцию, действие в результате этой ошибки.
Кстати, еще одна смешная ошибка, которую выдает операционная система, — «программа выполнила недопустимую операцию и будет закрыта». Если вдуматься, абсолютно бессмысленное сообщение. Во-первых, я даже и не предполагал, что программа выполняет какую-то операцию, тем более кем-то и зачем-то недопустимую. Не буду рассуждать долго на эту тему********, так как мне могут возразить, что если разрешить дальнейшее выполнение этой программы, то это приведет к потере информационной безопасности и вообще краху системы в целом.
******** В данном случае просто приведу конкретный пример. Internet Explorer вдруг перестал запускаться, и операционная система постоянно, через некоторое время после запуска, закрывала программу с сообщением о страшной ошибке с недопустимой операцией. Некоторое время я ломал голову — в чем дело? Даже по глупости переустанавливал программу. Как ни странно — не помогло. Потом я решил сделать вот что. Программа при запуске показывает рамку окна запускаемой формы с пустой внутренней областью, и только потом появляется все внутреннее наполнение окна. В момент, пока это наполнение не появилось, я, нажав правую кнопку мышки, вызвал контекстное меню и стал отключать установленные дополнительные панели. Не спорю, что есть другие способы решения этой проблемы. Я выбрал именно такой; пожалуй, средний пользователь сделал бы так же. Наконец, отключив какую-то панель, я увидел, что приложение замечательн
о запустилось и заработало без ошибок, как и раньше.
В итоге у меня возник вопрос: почему во многих программах, кроме операционной системы, не предусмотрен запуск в «безопасном режиме», который гарантированно и железно работает? А вместо этого выдается стандартное сообщение об ошибке? По крайней мере, это можно решить так: фиксировать число запусков и закрытий самым первым действием при запуске. Если это число не совпадает какое-то число раз (не исключен случай принудительного закрытия программы из диспетчера задач), то запускать программу в «безопасном режиме» и пытаться искать причину «поломки».
Итак, думаю, понятно, что просто сообщить о собственно ошибке пользователю — это ничего не сделать. Гораздо лучше сделать и ничего об этом не говорить, а молча про себя улыбнуться и подумать: «Какой я молодец!»
Заключение
Разговор об интерфейсе я только начал. И только этой одной статьей я не ограничусь, тем более что я больше не сказал, чем сказал, а объем получился большим. Что сказать и написать, у меня еще найдется. Конечно же, огромную помощь в написании статьи я получаю из книг и Интернета. По возможности, я указываю оригинальные источники, тем не менее стараюсь пересказывать своими словами ту информацию, которую узнал, чтобы это не было глупым плагиатом. До встречи в следующих статьях!
С уважением, Александр Демьяненко.
Ресурсы
- Об оформлении программной документации
http://www.raai.org/about/persons/karpov/pages - ГОСТ 19.102-77. Стадии разработки http://www.nist.ru/hr/doc/gost/19102-77.htm
- Студия Артемия Лебедева. Создание интерфейса навигатора «Штурман» http://www.artlebedev.ru/everything/shturmann/
- Этот мерзкий, неудобный, противоестественный оконный интерфейс http://epikoiros.narod.ru/public/antiwind.htm
- Обзор эргономических проблем и недостатков пользовательского интерфейса ПО бухгалтерского учета на примере 1С:Предприятие 7.5 http://www.usability.ru/
Статья из шестого выпуска журнала «ПРОграммист».
Обсудить на форуме – Разработчик интерфейс пользователи. Часть 2
23rd
Сен
Программы для самых маленьких
Компьютер в настоящее время для большинства уже перестал быть чем-то диковинным. Он используется и для развлечений, и для работы, а среди его пользователей школьники и студенты, любители и профессионалы, люди разных возрастов и профессий. Идея использовать компьютер, а точнее компьютерные программы для обучения и развития, естественно, родилась и реализуется уже давно. И вот, видя, с каким интересом мой маленький внук (а было ему тогда всего лишь 3,5 годика) наблюдает, как я работаю за компьютером, и как он старается тоже подвигать мышкой или понажимать клавиши, я понял: пора использовать его интерес для развития. Первым делом, конечно, поискал в Интернете программы, обучающие ребенка счету, рисованию и раскраске простеньких рисунков, знакомству с азбукой. Увы, результат оказался плачевным. Большинство программ, найденных мной в Интернете, или платные, или настолько сложные для ребенка, что и взрослому не всегда удается разобраться, как ею пользоваться. Так и появилась идея самому создать развивающие программы для маленьких с учетом интересов и способностей самого ребенка. Вскоре появились красочные программы “Раскраска” и “Азбука”, очень понравившиеся малышу. Яркие рисунки с любимыми игрушками и персонажами сказок и мультфильмов, простота управления программой – все это привлекает ребенка, прививая ему первые навыки координации движений, правильного выбора действий.
Владимир Дегтярь
by DeKot degvv@mail.ru
Целью данной статьи является помощь начинающим программистам в создании полноценных программ для маленьких детей. Вы можете просто скачать из приложения к журналу файлы *.exe (не забыв про ресурсы программы – папку Image с рисунками) и предложить поиграть своим маленьким пользователям.
В данной статье рассмотрим создание двух небольших программ, которые наверняка понравятся малышам. Думаю, что тем, кто хоть немного знаком с компьютером (тем более с программированием), не составит большого труда заменить или добавить рисунки, более подходящие для конкретного ребенка.
Программа “Раскраска”
Программа* представляет из себя, в прямом смысле, обычную раскраску, где ребенок выбирает понравившийся рисунок и раскрашивает его выбранными им же цветами.
* Комментарий автора.
Сразу отмечу, что данная программа обсуждалась на форуме http://programmersforum.ru/showthread.php?t=80497&highlight=%D0%E0%F1%EA%F0%E0%F1%EA%E0. Форумчанин raxp устранил некоторые ошибки и добавил ряд красивых рисунков, а mutabor заменил стандартный курсор на симпатичную кисточку.
Прежде чем приступить к самому процессу программирования, определимся со структурой программы. А именно, что же мы хотим получить от программы:
- Все действия будем производить на форме, точнее на канве формы. Следовательно, будем использовать в программе свойства и методы работы с канвой формы – вывод рисунков на форму (методы Draw, StretchDraw), заливку области канвы цветом (свойства кисти Brush.Color, метод заливки FloodFill и т. п.).
- Нам понадобятся рисунки для раскраски. При этом каждый рисунок будет иметь два вида. Один – это полноцветный рисунок, используемый для выбора и для подсказки (чтобы ребенок видел, каким цветом закрашивать фрагменты рисунка). Второй – непосредственно сам выбранный рисунок для раскраски в виде контуров фрагментов рисунка. Все контуры должны образовывать замкнутую область.
- К выбору рисунков следует подходить индивидуально для каждого ребенка. Кому-то нравятся машинки, самолеты, кораблики, кому-то – персонажи сказок и мультфильмов. Самым маленьким вполне достаточно простейших рисунков – солнышка, шарика, звездочки и т. п. Множество рисунков можно найти в Интернете. Это и готовые рисунки для раскрасок, и просто красочные картинки с различными персонажами.
- Еще нам потребуется набор палитры цветов. Естественно, что применение, скажем, стандартного компонента выбора палитры цветов вряд ли будет интересно для ребенка. Куда привлекательней, если он будет выбирать краску из разноцветных ведерочек.
Все действия в программе производим при помощи мыши – курсором, а затем кнопкой мыши выбираем или меняем рисунок, цвет заливки, закрашиваемую область рисунка. Вместо стандартного системного курсора будем использовать самодельный в виде кисточки.
* Комментарий автора.
Казалось бы, детской ручке тяжело манипулировать мышкой (даже если подобрать мышку самых маленьких размеров). Однако мой внук быстро сообразил, что удобно передвигать мышку и управлять курсором одной рукой, а второй нажимать кнопку мыши в нужном месте.
Вот, в принципе, и все основные пункты структуры программы. Итак, начнем постепенно создавать саму программу…
Предварительно следует подобрать рисунки для раскраски. Для получения из цветного рисунка контурного для раскрашивания можно применить простой способ. Откройте цветной рисунок в графическом редакторе Paint, а затем сохраните его как черно-белый рисунок. При необходимости можно залить области рисунка белым цветом и подправить контурные линии, чтобы получить замкнутые области. Все рисунки храним в папке Image в файлах формата bmp, которую расположим в папке с проектом. Для выбора рисунка выводим на форму одновременно 12 рисунков. При смене рисунков выводим следующую группу из 12 рисунков. При этом совсем необязательно, чтобы размеры рисунков были одинаковыми. При выводе рисунков на форму будем подгонять размер рисунка до необходимого. Файлам цветных рисунков, для удобства обработки в коде программы, присвоим цифровые имена. Для первой группы цветных рисунков – 1.bmp… 12.bmp, для второй – 21.bmp… 32.bmp, для следующей – 41.bmp… 52.bmp и т. д.
Файлы черно-белых рисунков для раскрашивания соответственно имеют имена р1.bmp… р12.bmp, р21.bmp… р32.bmp, р41.bmp… р52.bmp. Здесь же находятся еще два вспомогательных файла – рисунок пока пустого ведерка для краски col.bmp и изображение курсора в виде кисточки brush.bmp.

Рис. 1. Окно программы “Раскраска”
Окно программы состоит из трех частей (см. рисунок 1):
- Область выбора рисунка. Здесь расположены 12 цветных рисунков (размером 100х100 пикселей) для выбора и кнопка смены рисунков (в виде зеленого треугольника).
- Область выбора цвета – 15 разноцветных ведерок с красками.
- Область выбранного рисунка для раскраски. Здесь выводится выбранный рисунок (размером 600х600 пикселей).
Определимся, какие процедуры нам понадобятся для реализации программы. Так как все манипуляции в программе осуществляются при помощи мыши, будем использовать стандартные обработчики FormMouseDown() и FormMouseMove(), а также процедуру обработчика событий FormClick(). Вывод всех рисунков, а также курсора в виде кисточки будем производить в стандартных процедурах для окна формы FormShow() и FormPaint(). Еще две стандартные процедуры: FormCreate() используется для инициализации приложения после запуска, SetBrushColor – для окрашивания кисточки-курсора в выбранный цвет.
Две процедуры мы создадим сами. Одна из них – процедура выбора рисунка SelPicture для считывания цветных рисунков из файлов папки Image. Данная процедура вызывается при запуске (инициализации) приложения и каждый раз при смене рисунков выбора (когда нажимается треугольная кнопка смены рисунков). Вторая – процедура выбора области окна программы SelRegion. В зависимости от того, в какой области окна мы нажмем кнопку мыши, происходит одно из четырех событий:
- Выбор рисунка для закрашивания.
- Смена блока из 12 рисунков для выбора.
- Выбор цвета для закрашивания.
- Сама процедура закрашивания фрагментов выбранного рисунка.
В качестве параметра в процедуру SelRegion при нажатии кнопки мыши передаются координаты курсора мыши. Определимся с необходимыми нам переменными…
Так как все необходимые рисунки находятся в виде файлов, то будем по необходимости загружать их в объекты типа TbitMap: BufCol – изображения ведерка с краской, MyBrush – курсор-кисточка, Buffer – буфер для загрузки всех изображений, кроме курсора, и BufWin – буфер окна программы, из которого все изображения выводятся на форму.
Значения цветов будем хранить в одномерном массиве mas_col. Также нам понадобятся координаты курсора в момент нажатия кнопки мыши (xm и ym) и еще одна переменная типа byte – page. По ней будем определять имена файлов цветных рисунков при смене блоков рисунков (по 12 шт.). Все это переменные глобального типа (см. код ниже).
var
Form1: TForm1;
BufCol: TBitMap; // буфер загрузки ведерка с краской
MyBrush: TBitmap; // буфер загрузки курсора-кисточки
Buffer: TBitmap; // буфер загрузки всех компонентов, кроме кисточки
BufWin: TBitmap; // общий буфер вывода окна программы на форму
xm,ym: integer; // координаты курсора мыши
mas_col: array
[0..14] of integer; // массив палитры цветов
page: byte; // страница блока из 12 рисунков
Form1: TForm1;
BufCol: TBitMap; // буфер загрузки ведерка с краской
MyBrush: TBitmap; // буфер загрузки курсора-кисточки
Buffer: TBitmap; // буфер загрузки всех компонентов, кроме кисточки
BufWin: TBitmap; // общий буфер вывода окна программы на форму
xm,ym: integer; // координаты курсора мыши
mas_col: array
[0..14] of integer; // массив палитры цветов
page: byte; // страница блока из 12 рисунков
Необходимые локальные переменные будем рассматривать по ходу описания кода приложения. Сначала изучим процедуры выборов рисунка и области окна приложения.
1. Выбор рисунков SelPicture
procedure SelPicture; // выбор рисунка
var i: byte; // переменная цикла
BufPic: TBitMap; // буфер загрузки цветных рисунков
x,y: integer; // координаты рисунков на канве буфера
begin
BufPic:=TBitmap.
Create; // создаем буфер
x:= 10; y:= 20; // координаты первого из 12 рисунков
for i:= 1 to 12 do // цикл загрузки рисунков
begin
BufPic.LoadFromFile(
‘Image\’ + IntToStr(i+page) + ‘.bmp’);
Buffer.Canvas.StretchDraw(bounds(x,y,100,100),BufPic); // вывод на канву Buffer
x:= x + 105;
if x > 115
then begin x:= 10; y:= y + 105; end;
end;
BufPic.Free; // освобождаем память
end;
var i: byte; // переменная цикла
BufPic: TBitMap; // буфер загрузки цветных рисунков
x,y: integer; // координаты рисунков на канве буфера
begin
BufPic:=TBitmap.
Create; // создаем буфер
x:= 10; y:= 20; // координаты первого из 12 рисунков
for i:= 1 to 12 do // цикл загрузки рисунков
begin
BufPic.LoadFromFile(
‘Image\’ + IntToStr(i+page) + ‘.bmp’);
Buffer.Canvas.StretchDraw(bounds(x,y,100,100),BufPic); // вывод на канву Buffer
x:= x + 105;
if x > 115
then begin x:= 10; y:= y + 105; end;
end;
BufPic.Free; // освобождаем память
end;
В буфер BufPic типа TBitMap в цикле загружаем из файлов 12 цветных рисунков и помещаем на канву основного буфера Buffer, приводя к размеру 100х100 пикселей каждый. Имя файла определяется значением переменной цикла и значением страницы блоков из 12 рисунков: (i + page).bmp. Значение переменной page при запуске приложения равно нулю. При нажатии кнопки смены рисунков значение page увеличивается на 20 и при значениях >40 опять принимает значение, равное 0 (организовано в процедуре выбора области окна приложения).
2. Выбор области окна приложения
Процедура SelRegion вызывается по событию OnClick на форме, если мы нажимаем кнопку мыши в области выбора рисунка или в области выбора цвета (см. Рис. 1). В зависимости от координат курсора в момент нажатия кнопки мыши происходит следующее:
- “Клик” по кнопке выбора рисунков – изменяется значение переменной page ( 0 – 20 – 40 – 0 – ) и вызывается процедура SelPicture для загрузки других 12 рисунков;
- “Клик” по одному из цветных рисунков – определяется имя файла рисунка для раскраски по локальной переменной num, загружаем файл в буфер рисунка BufPic, а затем переносим в основной буфер Buffer (размер рисунка 600х600 пикселей) в область раскраски.
- “Клик” по любому из цветных ведерок – происходит выбор цвета, и цвет передается на канву основного буфера Buffer и на канву формы.
Теперь рассмотрим работу программы. При запуске приложения в процедуре FormCreate происходит инициализация:
- создаются объекты типа TBitMap для загрузки графических изображений;
- рисунки ведерка и курсора-кисточки загружаются из файлов в соответствующие буферы BufCol и MyBrush;
- заполняем массив mas_col значениями цветов.
В процедуре FormShow() присваиваются атрибуты основным буферам Buffer и BufWin – размеры, равные размерам клиентской области формы, и цвет канвы. Здесь же выводим на канву буфера Buffer 15 цветных ведерок для выбора цвета, цветные рисунки выбора, затем рисуем кнопку смены рисунков и прямоугольник области рисунка для раскрашивания.
В процедуре FormPaint() считываем координаты курсора (GetCursorPos(P: TPoint)) в пределах клиентской области формы, содержимое буфера Buffer копируем в буфер окна BufWin и в него же добавляем изображение курсора-кисточки. Затем содержимое BufWin выводим на форму. Далее управление программой осуществляет пользователь с помощью мыши. При перемещении мыши обрабатывается событие FormMouseMove(), в буфер окна BufWin копируется содержание основного буфера Buffer и накладывается новое положение курсора-кисточки, а затем все это выводится на форму.
При нажатии кнопки мыши вызываются два обработчика события – FormMouseDown(), в котором переменным xm и ym присваиваются значения координат курсора, и FormClick(), в котором, если курсор находится в области окна для раскрашивания рисунка, происходит заливка замкнутой области, где находится курсор, выбранным ранее цветом (метод FloodFill). При нахождении курсора в любой другой области окна и нажатии кнопки мыши вызывается процедура SelRegion, работу которой мы уже рассмотрели выше. При этом координаты мыши передаются в процедуру SelRegion (xm,ym) в качестве параметра.
И последняя процедура SetBrushColor(C: Tcolor) устанавливает для курсора-кисточки выбранный цвет. Более подробно весь код приложения можно посмотреть в приложении в файле <Unit1.pas>, который содержит подробные комментарии кода***.
* Комментарий автора.
Считаю, что нет необходимости добавлять в программу какие-либо “красивости” (разве, что добавить звуковое оформление), так как маленькому ребенку в первую очередь интересны предложенные красочные рисунки и простота управления программой.
Программа “Азбука”
Данная программа знакомит ребенка с буквами алфавита, помогая быстрее их запоминать и составлять простые слова. Чтобы понять смысл программы, рассмотрим окно приложения (см. Рис. 2):

Рис. 2. Окно программы “Азбука”
Оно разбито на четыре части:
- Область выбора рисунка (1) – здесь выводятся два рисунка или фотографии знакомых ребенку игрушек или персонажей сказок, мультфильмов, которые можно выбрать, “кликнув” по изображению. Также здесь находятся кнопки (в виде треугольников) смены рисунков или фотографий. Также можно взять фотографии родителей или домашних питомцев.
- Область выбранного рисунка с подписью (2), которая повторяется в поле вывода слова (3) по мере того, как ребенок будет правильно выбирать буквы из алфавита (4) в верхней части окна программы. В программе используются не все буквы алфавита, а только наиболее употребляемые. Кроме того, можно заменить русский алфавит на любой другой национальный (украинский, казахский и т. д.).
Суть программы в том, что после выбора изображения ребенку нужно повторить подпись к выбранному рисунку, нажимая на соответствующие буквы в поле алфавита. При правильном выборе букв слово-подпись повторяется в поле вывода. В качестве подсказки очередная буква подписи к рисунку мигает.
Аналогично предыдущей программе сначала опишем ее структуру и особенности.
- Все действия программы производим на канве формы.
- В папке Image проекта храним набор рисунков и фотографий, которые по мере необходимости выводим на форму.
- Все манипуляции в программе осуществляются мышью.
Процедуры для реализации программы: аналогично предыдущей программе будем использовать стандартные обработчики FormMouseDown() для получения координат курсора мыши, а также процедуру обработчика событий FormClick(), в которой обрабатываем все манипуляции мышкой в окне формы. Стандартная процедура FormCreate() используется для инициализации приложения после запуска, а в процедуре FormPaint(). выводим все необходимые изображения на форму. В обработчике таймера Timer1.Timer() организуем подсказку в виде мигания очередной буквы в слове-подписи. Кроме этих стандартных процедур, напишем еще две. SelAlfavit – процедура выбора буквы в поле алфавита. В качестве параметров в процедуру передаются координаты курсора, и по ним из алфавита выбирается буква. Если выбранная буква совпадает с очередной буквой подписи (для подсказки ребенку она мигает), то выбранная буква выводится в поле вывода слова. В процедуре SelFoto производится выбор рисунка или фото и вывод его
изображения на форму.
Заключение
Программа настолько проста, что нет смысла подробно рассматривать каждую процедуру. Весь код программы с подробными комментариями смотрите в файле Unit1.pas в виде ресурсов в теме “Журнал клуба программистов. Шестой выпуск” или непосредственно в архиве с журналом.
**** Комментарий редакции.
Как известно, готовность ребенка к школе определяется комплексом его общей интеллектуальной, психологической и физической подготовки. Причем, психологическая – одна из самых трудных, так как она не возникает сама по себе и требует особого внимания родителей. В чем она проявляется? Все просто как дважды-два и через эти проблемы каждый раз проходят и родители и преподаватели и сам ребенок. Это и отсутствие сосредоточенности ребенка на предмете и личной инициативы, частое отвлечение внимания. Быть готовым к школе – это не только уметь читать, писать и считать. Это прежде всего, готовность всему этому учиться.
Как известно, готовность ребенка к школе определяется комплексом его общей интеллектуальной, психологической и физической подготовки. Причем, психологическая – одна из самых трудных, так как она не возникает сама по себе и требует особого внимания родителей. В чем она проявляется? Все просто как дважды-два и через эти проблемы каждый раз проходят и родители и преподаватели и сам ребенок. Это и отсутствие сосредоточенности ребенка на предмете и личной инициативы, частое отвлечение внимания. Быть готовым к школе – это не только уметь читать, писать и считать. Это прежде всего, готовность всему этому учиться.
Для детей дошкольного возраста очень важна усидчивость и способность доводить дело до конечной цели. В этом плане хорошо помогают разнообразные настольные игры, вроде конструктора или лепки поделок из пластилина или глины, игры на счет, используя аппликации, палочки и тому подобные. Что примечательно, эти же игры помогают развивать и мелкую моторику пальцев.
Сегодня, в свете огромного скачка вперед в информационных технологиях, компьютер есть практически в каждой семье. И нельзя отрицать тот факт, что использование его на школьных занятиях практикуется уже повсеместно. Так почему-бы не познакомить ребенка с чудом двадцатого века раньше и дать возможность заранее адаптироваться к школьным трудностям. Также не будем забывать про акселерацию детей.
Конечно же, все это должно быть в форме игры и обязательно под присмотром старших. Для развития мелкой моторики малыша не нужно дорогих игрушек и особого подхода. Достаточно поиграть в:
1) пальчиковый театр;
2) электронную раскраску или говорящий алфавит.
Именно, о них и шла речь в представленном материале. Мы не предлагаем панацею, а лишь показываем, что такая область как программирование полезна и в детском творчестве. Примечательно, что этот номер вышел как раз в начале учебного года. Надеемся, статья нашего постоянного автора Владимира Дегтяря поможет вам в игровой форме занять ваших малышей, а вам самим подарить несколько свободных минут. Удачи!
Статья из шестого выпуска журнала “ПРОграммист”.
23rd
Компилятор домашнего приготовления. Часть 1
Почему мне пришла в голову идея разработать собственный компилятор? Однажды мне на глаза попалась книга, где описывались примеры проектирования в AutoCAD на встроенном в него языке AutoLISP. Я захотел c ними разобраться, но прежде меня заинтересовал сам ЛИСП. “Неплохо бы поближе познакомиться с ним”, – подумал я и начал подыскивать литературу и среду разработки. С литературой все оказалось просто – по ЛИСПу ее море в Интернете. Достаточно зайти на портал [1]. Дело оставалось за малым – найти хорошую среду программирования, и вот тут-то начались трудности. Компиляторов под ЛИСП тоже немало, но все они оказались мне малопонятны. Ни один пример из Вики, по разным причинам, не отработал нормально в скачанных мною компиляторах. Собственно, серьезно я с ними не разбирался, но, увы, во многих не нашел как скомпилировать EXE-файл. Самое интересное, что компиляторы эти были собраны разными людьми практически в домашних условиях…
Виталий Белик
by Stilet
И мне пришла в голову мысль: а почему бы не попробовать самому написать свой компилятор или, основываясь на каком-либо диалекте какого-либо языка, свой собственный язык программирования? К тому же на форумах я часто видел темы, где слезно жаловались на тиранов-преподавателей, поставивших задачу написания курсовой – компилятора или эвалюатора (программы, вычисляющей введенное в виде строки выражение). Мне стало еще интереснее: а что если простому студенту, не искушенному книгами Вирта или Страуструпа, написать такую программу? Появился мотив.
In the Beginning
Итак, начнем. Прежде всего, нужно поставить задачу хотя бы на первом этапе. Задача будет банальная: доказать самому себе, что написание компилятора не такой уж сложный и страшный процесс. И что мы, хитрые и смекалистые, способны родить в муках собственного творчества шедевр, который, возможно, полюбится массам. Да и вообще: приятно писать программы на собственном языке, не так ли?
Что ж, цель поставлена. Теперь самое время определиться со следующими пунктами:
- Под какую платформу будет компилировать код программа?
- На каком языке будет код, переводимый в машинный язык?
- На чем будем писать сам компилятор?
Первый пункт достаточно важен, ибо широкое разнообразие операционных систем (даже три монстра – Windows, Linux и MacOS) уже путают все карты. Их исполняемые файлы по-разному устроены, так что нам, простым смертным, придется выбрать из этой “кагалы” одну операционную систему и, соответственно, ее формат исполняемых файлов. Я предлагаю начать с Windows, просто потому, что мне нравится эта операционная система более других. Это не значит, что я терпеть не могу Linux, просто я его не очень хорошо знаю, а такие начинания лучше делать по максимуму, зная систему, для которой проектируешь.
Два остальных пункта уже не так важны. В конце концов, можно придумать свой собственный диалект языка. Я предлагаю взять один из старейших языков программирования – LISP. Из всех языков, что я знаю, он мне кажется более простым по синтаксису, более атомарным, ибо в нем каждая операция берется в скобочки; таким образом, к нему проще написать анализатор. С выбором, на чем писать, еще проще: писать нужно на том языке, который лучше всего знаешь. Мне ближе паскалевидные языки, я хорошо знаю Delphi, поэтому в своей разработке я избираю именно его, хотя никто не мешает сделать то же самое на Си. Оба языка прекрасно подходят для написания такого рода программ. Я не беру в расчет Ассемблер потому, что его диалект приближен к машинному языку, а не к человеческому.
To Shopping
Выяснив платформу, для которой будем писать компилятор (я имею в виду Win32), подберем все необходимое для комфортной работы. Давайте составим список, что же нам пригодится в наших изысканиях.
Для начала нам просто крайне необходимо выяснить, как же все-таки компиляторы генерируют исполняемые EXE-файлы под Windows. Для этого стоит почитать немного об устройстве этих “экзэшек”, как их часто называют, покопаться в их “кишках”. В этом могут помочь современные отладчики и дизассемблеры, способные показать, из чего состоит “экзэшка”. Я знаю два, на мой взгляд, лучших инструмента: OllyDebugger (он же “Оля”) и The Interactive Disassembler (в простонародье зовущийся IDA).
Оба инструмента можно достать на их официальных сайтах http://www.ollydbg.de/ и http://www.hex-rays.com/idapro. Они помогут нам заглянуть в святая святых – храм, почитаемый загрузчиком исполнимых файлов, – и посмотреть, каков интерьер этого храма, дабы загрузчик наших экзэшек чувствовал себя в нем так же комфортно, как “ковбой в подгузниках Хаггис”.
Также нам понадобится какая-нибудь экзэшка в качестве жертвы, которую мы будем препарировать этими скальпелями-дизассемблерами. Здесь все сложнее. Дело в том, что благородные компиляторы имеют дурную привычку пихать в экзэшник, помимо необходимого для работы кода, всякую всячину, зачастую ненужную. Это, конечно, не мусор, но без него вполне можно обойтись, а вот для нашего исследования внутренностей экзэшек он может стать серьезной помехой. Мы ведь не Ричарды Столлманы и искусством реверсинга в совершенстве не владеем. Поэтому нам лучше было бы найти такую программу, которая содержала бы в себе как можно меньше откомпилированного кода, дабы не отвлекаться на него. В этом нам может помочь компилятор Ассемблера для Windows. Я знаю два неплохих компилятора: Macro Assembler (он же MASM) и Flat Assembler (он же FASM). Я лично предпочитаю второй – у него меньше мороки при компилировании программы, есть собственный редактор, в отличие от MASM компиляция проходит нажатием одной-единственной кнопки. Для MASM разработаны среды проектирования, например MASM Builder. Это достаточно неплохой визуальный инструмент, где на форму можно кидать компоненты по типу Delphi или Visual Studio, но, увы, не лишенный багов. Поэтому воспользуемся FASM. Скачать его можно везде, это свободно распространяемый инструмент. Ну и, конечно, не забудем о среде, на которой и будет написан наш компилятор. Я уже сказал, что это будет Delphi. Если хотите конкретнее – Delphi 6.
The Theory and Researching
Прежде чем приступить к написанию компилятора, неплохо бы узнать, что это за формат “экзэшка” такой. Согласно [2], Windows использует некий PE-формат. Это расширение ранее применявшегося в MS-DOS, так называемого MZ формата [3]. Сам чистый MZ-формат простой и незатейливый – это 32 байта (в минимальном виде, если верить FASM; Турбо Паскаль может побольше запросить), где содержится описание для DOS-загрузчика. В Windows его решили оставить, видимо, для совместимости со старыми программами. Вообще, если честно, размер DOS-заголовка может варьироваться в зависимости от того, что после этих 28 байт напихает компилятор. Это может быть самая разнообразная информация, например для операционок, которые не смогли бы использовать скомпилированный DOS или Windows-экзэшник, представленная в качестве машинного кода, который прерываниями BIOS выводит на экран надпись типа “Эта программа не может быть запущена…”. Кстати, сегодняшние компиляторы поступают так же.
Давайте посмотрим на это чудо техники, воспользовавшись простенькой программой, написанной на чистом Ассемблере FASM (см. Рис. 1):
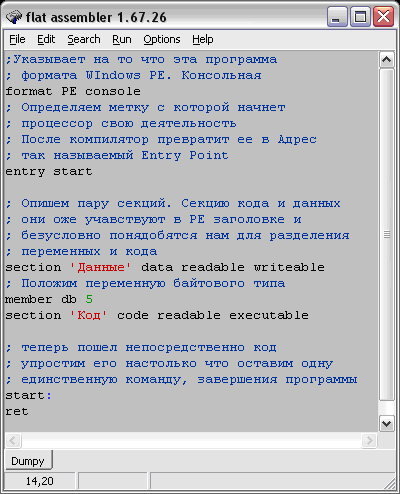
Рис. 1. Исходник для препарирования
Сохраним файл под неким именем, например Dumpy. Нажмем F9 или выберем в меню пункт RUN. В той же папке будет создан EXE-файл. Это и будет наша жертва, которую мы будем препарировать. Теперь ничто не мешает нам посмотреть: “из чего же, из чего же сделаны наши девчонки?”.
Запустим OllyDebuger. Откроем в “Оле” наш экзэшник. Поскольку фактически кода в нем нет, нас будет интересовать его устройство, его структура. В меню View есть пункт Memory, после выбора которого “Оля” любезно покажет структуру загруженного файла (см. Рис. 2):
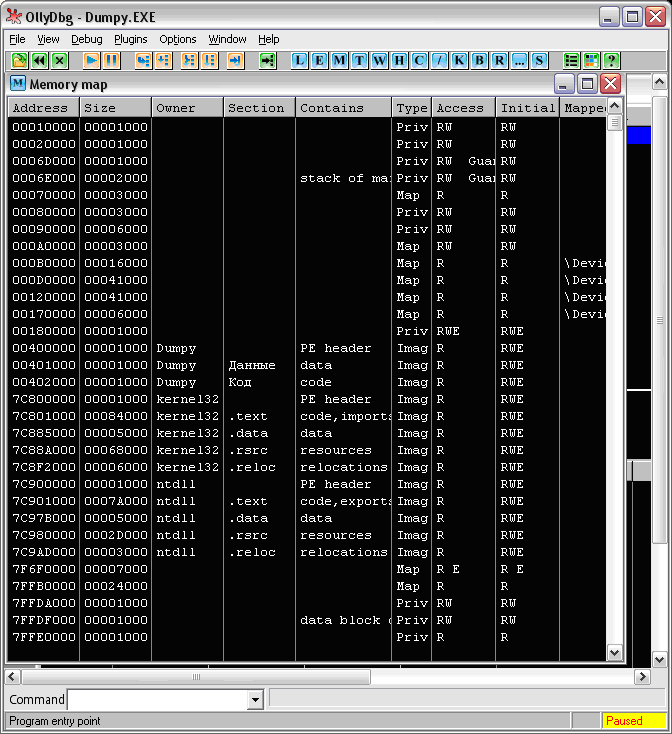
Рис. 2. Карта памяти Dumpy
Это не только сам файл, но и все, что было загружено и применено вместе с ним, библиотеки, ресурсы программы и библиотек, стек и прочее, разбитое на блоки, называемые секциями. Из всего этого нас будут интересовать три секции, владелец которых Dumpy, – это непосредственно содержимое загруженного файла.
Собственно, эти секции были описаны нами в исходнике, я не зря назвал их по-русски (ведь операционной системе все равно, как названы секции, главное – их имена должны укладываться точь-в-точь в 8 байт. Это придется учесть обязательно).
Заглянем в первую секцию PE Header. Сразу же можем увидеть (см. Рис. 3), что умная “Оля” подсказывает нам, какие поля* у этой структуры:
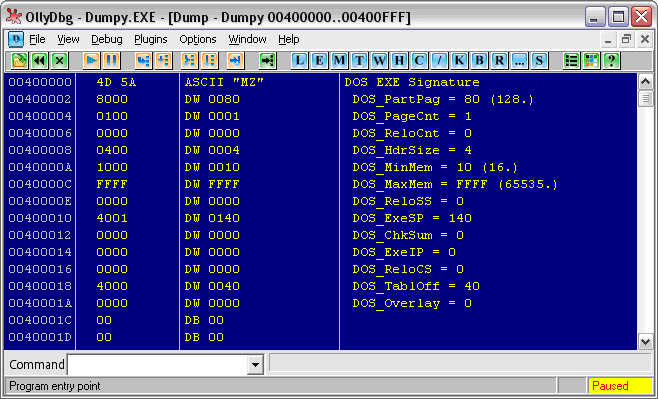
Рис. 3. MZ-заголовок
* Комментарий автора.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Последнее поле, которое для нас важно, находится по смещению 3Ch от начала файла (см. Рис. 4):
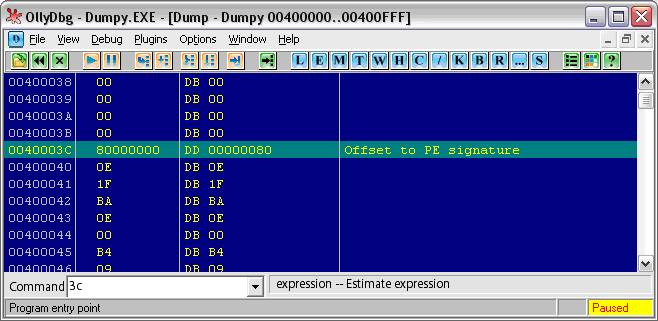
Рис. 4. Смещение на PE-заголовок
Это поле – точка начала РЕ-заголовка. В Windows, в отличие от MS-DOS, MZ-заголовок заканчивается именно на отметке 40**, что соответствует 64 байтам. При написании компилятора будем соблюдать это правило неукоснительно.
* Комментарий автора.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Что ж, перейдем непосредственно к PE-заголовку (см. Рис. 5). Как показывает “Оля”, нам нужно перейти на 80-й байт. Да, чуть не забыл. Все числа адресации указываются в 16-тиричной системе счисления. Для этого после чисел ставится латинская буква “H”. “Оля” не показывает ее, принимая эту систему по умолчанию для адресации. Это нужно учесть, чтобы не запутаться в исследованиях. Фактически 80h – это 128-й байт.
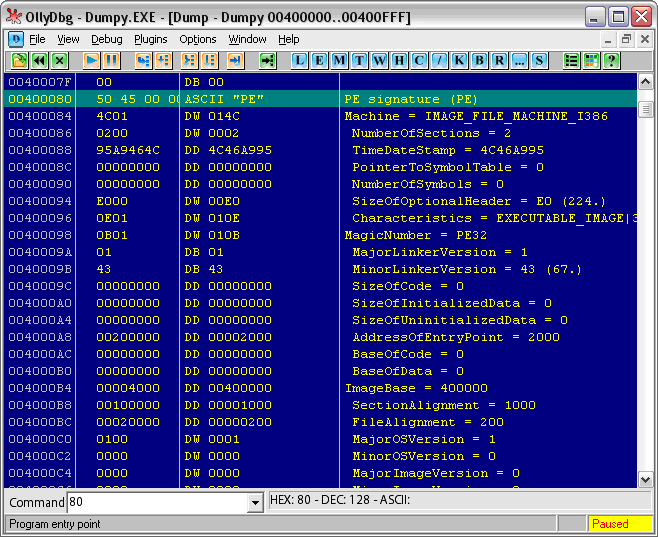
Рис. 5. Начало РЕ-заголовка
Вот она, святая обитель характеристик экзэшника. Именно этой информацией пользуется загрузчик Windows, чтобы расположить файл в памяти и выделить ему необходимую память для нужд. Вообще, считается, что этот формат хорошо описан в литературе. Достаточно выйти через Википедию по ссылкам в ее статьях [4] или банально забить в поисковик фразу вроде “ФОРМАТ ИСПОЛНЯЕМЫХ ФАЙЛОВ PortableExecutables (PE)”, как сразу же можно найти кучу описаний. Поэтому я поясню только основные его поля, которые нам понадобятся непосредственно для написания компилятора…
Прежде всего, это PE Signature – 4-хбайтовое поле. В разной литературе оно воспринимается по-разному. Иногда к нему приплюсовывают еще поле Machine, оговариваясь, чтобы выравнять до 8 байт. Мы же, как любители исследовать, доверимся “Оле” с “Идой” и будем разбирать поля непосредственно по их подсказкам. Это поле содержит две латинские буквы верхнего регистра “PE”, как бы намекая нам, что это Portable Executable-формат.
Следующее за ним поле указывает, для какого семейства процессоров пригоден данный код. Всего их, как показывает литература, 7 видов:
0000h __unknown
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
Думаю, нам стоит выбрать из всего этого второй вид – 80386. Кстати, наблюдательные личности могли заметить, что в компиляторах Ассемблера есть директива, указывающая, какое семейство процессора использовать, как, например, в MASM (см. Рис. 6):
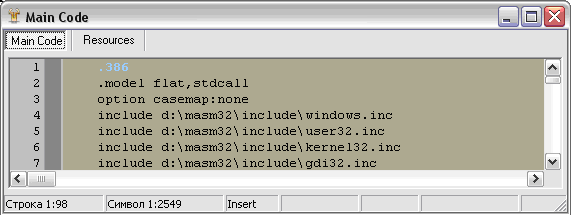
Рис. 6. Указание семейства процессоров в МАСМ
386 как раз и говорит о том, что в этом поле будет стоять значение 014Ch***.
* Комментарий автора.
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Следующее важное для нас поле – NumberOfSections. Это количество секций без учета PE-секции. Имеются в виду только те секции, которые принадлежат файлу (в карте памяти их владелец – Dumpy). В нашем случае это “Данные” и “код”.
Следующее поле хоть и не столь важно, но я его опишу. Это TimeDateStamp – поле, где хранится дата и время компиляции. Вообще, я его проигнорирую, не суть важно сейчас, когда был скомпилирован файл. Впрочем, если кому захочется помещать туда время, то флаг в руки.
Сразу хочу предупредить, что меня как исследователя не интересовали поля с нулевыми значениями. На данном этапе они действительно неважны, поэтому в компиляторе их и нужно будет занулить.
Следующее важное поле – SizeOfOptionalHeader. Оно содержит число, указывающее, сколько байт осталось до начала описания секций. В принципе, нас будет устраивать число 0Eh (224 байта).
Далее идет поле “характеристики экзэшника”. Мы и его будем считать константным:
Characteristics (EXECUTABLE_IMAGE|32BIT_MACHINE|LINE_NUMS_STRIPPED|LOCAL_SYMS_STRIPPED)
И равно оно 010Eh. На этом поле заканчивается так называемый “файловый заголовок” и начинается “Опциональный”.
Следующее поле – MagicNumber. Это тоже константа. Так называемое магическое число. Если честно, я не очень понял, для чего оно служит, в разных источниках это поле преподносится по-разному, но все хором ссылаются на знаменитый дизассемблер HIEW, в котором якобы впервые появилось описание этого поля именно в таком виде. Примем на веру.
Следующие два поля, хоть и не нулевые, но нам малоинтересны. Это: MajorLinkerVersion и MinorLinkerVersion. Это два байта версии компилятора. Угадайте, что я туда поставил?
Следующее важное поле – AddressOfEntryPoint. Важность этого поля в том, что оно указывает на адрес, с которого начинается первая команда, – с нее процессор начнет выполнение. Дело в том, что на этапе компиляции значение этого поля не сразу известно. Ее формула достаточно проста. Сначала указывается адрес первой секции плюс ее размер. К ней плюсуются размеры остальных секций до секции, считаемой секцией кода. Например, в нашей жертве это выглядит так (см. Рис. 7):
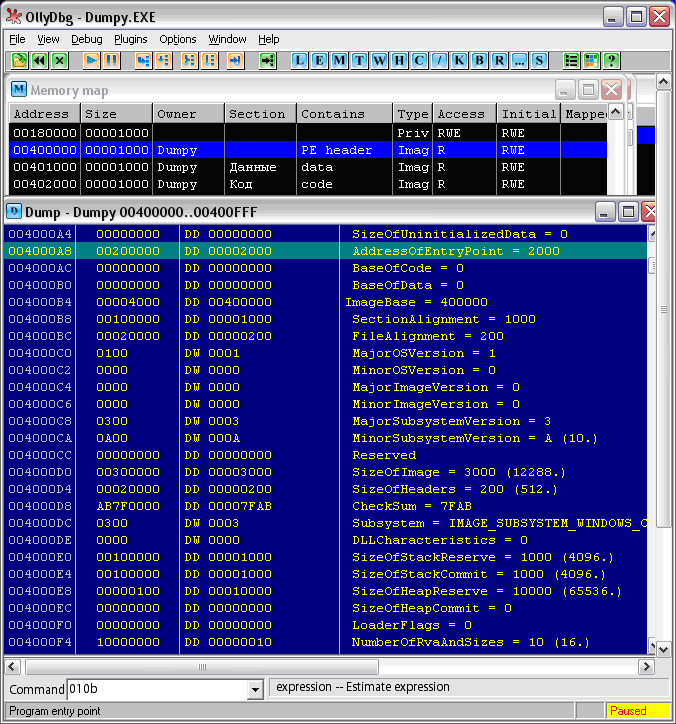
Рис. 7. Расчет точки входа
Здесь секция кода вторая по счету, значит, Адрес точки входа равен размеру секции “Данные” плюс ее начало и равен 2000. К этому еще пририсовывается базовый адрес, в который загрузчик “сажает” файл, но он в вычислении для нашего компилятора не участвует. Поэтому в жертве точка входа имеет значение 2000.
Следующее поле – ImageBase. Это поле я приму как константу, хотя и не оговаривается ее однозначное значение. Это значение указывает адрес, с которого загрузчик поместит файл в память. Оно должно нацело делиться на 64000. В общем, необязательно указывать именно 400000h, можно и другой адрес. Уже не помню, где я слышал, что загрузчик может на свое усмотрение поменять это число, если вдруг в тот участок памяти нельзя будет загружать, но не будем это проверять, а примем на веру как константу =400000h.
Следующая важная константа – SectionAlignment. Это значение говорит о размере секций после загрузки. Принцип прост: каждая секция (имеется в виду ее реализация) дополняется загрузчиком пустыми байтами до числа, указанного в этом поле. Это так называемое выравнивание секций. Тут уж хороший компилятор должен думать самостоятельно, какой размер секций ему взять, чтобы все переменные (или сам код), которые в коде используются, поместились без проблем. Согласно спецификации, это число должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). В принципе, пока что для простенького компилятора можно принять это значение как константу. Нас вполне устроит среднее значение 1000h (4096 байт – не правда ли, расточительный мусор? На этом весь Windows построен – живет на широкую ногу, память экономить не умеет).
Далее следует поле FileAlignment. Это тоже хитрое поле. Оно содержит значение, сколько байт нужно дописать в конец каждой секции в сам файл, т. е. выравнивание секции, но уже в файле. Это значение тоже должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). Неплохо бы рассчитывать функцией это поле в зависимости от размеров, данных в секции.
Следующие поля – MajorSubsystemVersion и MinorSubsystemVersion – примем на веру как константы. 3h и Аh соответственно. Это версия операционной системы, под которую рассчитывается данная компиляция****.
* Комментарий автора.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Далее из значимых следует SizeOfImage. Это размер всего заголовка, включая размер описания всех секций. Фактически это сумма PE-заголовка плюс его выравнивание, плюс сумма всех секций, учитывая их выравнивание. Ее тоже придется рассчитывать.
Следующее поле – SizeOfHeaders (pазмеp файла минус суммарный pазмеp описания всех секций в файле). В нашем случае это 1536-512 * 2=200h (512 байт). Однако РЕ тоже выравнен! Это поле тоже нужно будет рассчитывать.
Далее следует не менее коварное поле – CheckSum. Это CRC сумма файла. Ужас… Мы еще файл не создали, а нам уже нужно ее посчитать (опять-таки вспоминается Микрософт злым громким словом). Впрочем, и тут можно вывернуться. В Win API предусмотрена функция расчета CRC для области данных в памяти, проще говоря, массива байт – CheckSumMappedFile. Можно ей скормить наш эмбрион файла. Причем веселье в том, что эта операция должна быть самой последней до непосредственной записи в файл. Однако, как показывает практика, Windows глубоко наплевать на это поле, так что мы вполне можем не морочить себе голову этим расчетом (согласитесь, держать в файле поле, которое никому не нужно, да еще и напрягать нас лишним расчетом – это глупо, но, увы, в этом изюминка политики Микрософта. Складывается впечатление, что программисты, писавшие Windows, никак не согласовывали между собой стратегию. Спонтанно писали. Импровизировали).
Следующее поле – Subsystem. Может иметь следующие значения*****:
- IMAGE_SUBSYSTEM_WINDOWS_CUI=3. Это говорит о том, что наш откомпилированный экзэшник является консольной программой.
- IMAGE_SUBSYSTEM_WINDOWS_GUI=4. Это говорит о том, что экзэшник может создавать окна и оперировать сообщениями.
* Комментарий автора.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Вот, собственно, и все важные для нас параметры. Остальные можно оставить константно, как показывает “Оля”:
DLLCharacteristics = 0
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
И остаток забить нулями (посмотрите в “Оле” до начала секций, какие там еще параметры). О них можно почитать подробнее по ссылкам, которые я привел.
После идет описание секций. Каждое описание занимает 32 байта. Давайте взглянем на них (Рис. 8):
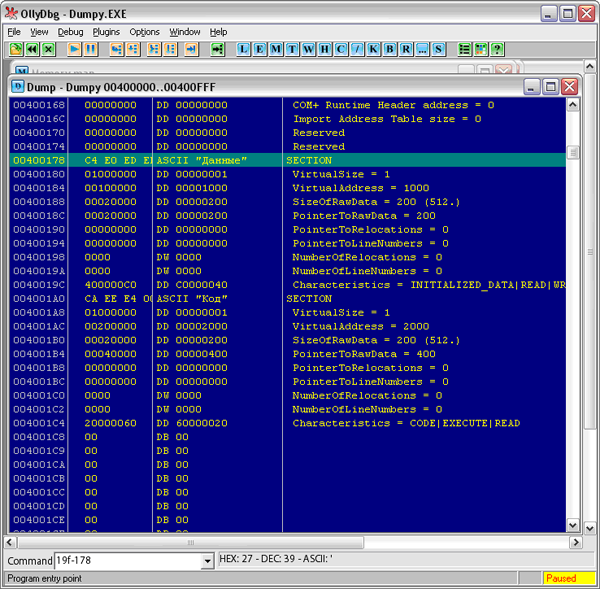
Рис. 8. Описание секций
В начале секции идет ее имя (8 байт), после этого поле – VirtualSize, описывает (я процитирую из уроков Iczeliona) “RVA-секции. PE-загpузчик использует значение в этом поле, когда мэппиpует секцию в память. То есть, если значение в этом поле pавняется 1000h и файл загpужен в 400000h, секция будет загpужена в 401000h”.
Однако “Оля” почему-то показывает для обеих секций одно и то же значение 9. Что это? Я не понял, почему так. Пока оставим это как данное. Вдруг в будущем разберемся.
Далее следует VirtualAddres, который указывает, с какого адреса плюс ImageBase будет начинаться в памяти секция – это важное поле, именно оно станет для нашего компилятора базой для расчета адреса к переменной. Собственно, адрес этот напрямую зависит от размера секции. Следующий параметр PointerToRawData – это смещение на начало секции в скомпилированном файле. Как я понял, этот параметр компиляторы любят подводить под FileAlignment. И последнее – поле Characteristics. Сюда прописывается доступ к секции. В нашем случае для секции кода оно будет равным 60000020=CODE|EXECUTE|READ, а для секции данных C0000040=INITIALIZED_DATA |READ|WRITE.
Вот и все. Закончилось описание заголовка. Далее он выравнивается нулями до 4095 байт (с этим числом связан один прикол). В файле мы его будем дополнять до FileAlignment (в нашем случае до 200h).
Hello world. Hey! Is There Anybody Out There?
Вот мы и прошлись по кишкам нашей жертвы – экзэшника. Напоследок попробуем на скорую руку закрутить простейший компилятор для DOS-системы без PE-заголовка. Для этого подойдут инструменты, которые так почему-то любят преподавать до сих пор.
Я говорю о классическом Паскале. Итак, предположим, злобный преподаватель поставил задачу: написать компилятор программы вывода на экран некой строки, которую мы опишем для компилятора, введя ее ручками (см. листинг 1):
var header,commands,s:string;
e,i:integer;
f:file;
begin
e,i:integer;
f:file;
begin
{Это MZ-заголовок}
header:=#$4D#$5A#$3E#$00#$01#$00#$
00#$00#$02#$00#$00#$01#$FF#$FF#$02#$00#$00;
header:=header+#$10#$00#$00#
$00#$00#$00#$00#$1C#$00#$00#$00#$00#$00#$00#$00;
writeln(
‘give me welcome ![]() ’);readln(s);
’);readln(s);
{Поскольку у нас все в одном сегменте, и код и данные, лежащие непосредственно в конце кода, нужно, чтобы регистр, содержащий базу данных, указывал на код. Предположим, мы будем считать, что и сам код представляет из себя данные. Для этого поместим в стек адрес сегмента кода}
{*******************************************************************************************}
Commands:=#$0E; { push cs}
{и внесем из стека этот адрес в регистр сегмента данных}
Commands:=Commands+#$1F; { pop ds}
Commands:=Commands+#$B4#$09; { mov ah, 9 – Вызовем функцию вывода строки на экран}
{Передадим в регистр DX-адрес на строку. Поскольку пока что строка у нас не определена, передадим туда нули, а позже подкорректируем это место}
Commands:=Commands+#$BA#$
00#$00; { mov dx, }
{Запомним место, которое нужно будет скорректировать. Этим приемом я буду пользоваться, чтобы расставить адреса в коде, который обращается к переменным}
e:=length(commands)-1;
{Выведем на экран строку}
Commands:=Commands+#$CD#$21;
{ int 21h ; DOS – PRINT STRING}
{подождем, пока пользователь не нажмет любую клавишу}
Commands:=Commands+#$B4#$01; { mov ah, 1}
Commands:=Commands+#$CD#$21; { int 21h ; DOS – KEYBOARD INPUT}
{После чего корректно завершим программу средствами DOS}
Commands:=Commands+#$B4#$4C; { mov ah, 4Ch}
Commands:=Commands+#$CD#$21; {int 21h ; DOS – 2+ – QUIT WITH EXIT CODE (EXIT)}
Commands:=Commands+#$C3; {retn}
{*******************************************************************************************}
{Теперь будем править адреса, обращающиеся к переменной. Поскольку само значение переменной у нас после всего кода (и переменная) одно, мы получим длину уже имеющегося кода – это и будет смещение на начало переменной}
i:=length(commands);
{В запомненное место, куда нужно править, запишем в обратном порядке это смещение}
commands[e]:=chr(lo
(i));
commands[e+1]:=chr(hi(i));
{Учтем, что в DOS есть маленький атавизм – строки там должны завершаться символом $. По крайней мере, для этой функции.}
commands:=commands+s+‘$’;
{не забудем дописать в начало заголовок}
commands:=header+commands;
{Теперь скорректируем поле DOS_PartPag. Для DOS-программ оно указывает на общий размер файла. Честно говоря, я не знаю, зачем это было нужно авторам, может быть, когда они изобретали это, еще не было возможности получать размер файла из FAT. Опять-таки запишем в обратном порядке}
i:=length(commands);
commands[3]:=chr(lo(i))
;
commands[4]:=chr(hi(i));
{Ну, и кульминация этого апофигея – запись скомпилированного массива байт в файл. Все заметили, что я воспользовался типом String, – он в паскалевских языках был изначально развит наиудобнейшим образом}
Assign(f,‘File.exe’);rewrite(f);
BlockWrite(f,commands[1],length(commands), e);
Close(f);
end.
Не удивляет, что программа получилась небольшой? Почему-то преподаватели, дающие такое задание, уверены, что студент завалится. Думаю, такие преподаватели сами не смогли бы написать компилятор. А студенты смогут, ибо, как видим, самая большая сложность – это найти нужные машинные коды для решения задачи. А уж скомпилировать их в код, подкорректировать заголовок и расставить адреса переменных – задача второстепенной сложности. В изучении ассемблерных команд поможет любая книга по Ассемблеру. Например, книга Абеля “Ассемблер для IBM PC”. Еще неплохая книга есть у Питера Нортона, где он приводит список функций DOS и BIOS.
Впрочем, можно и банальнее. Наберите в поисковике фразу “команды ассемблера описание”. Первая же ссылка выведет нас на что-нибудь вроде [5] или [6], где описаны команды Ассемблера. Например, если преподаватель задал задачку написать компилятор сложения двух чисел, то наши действия будут следующими:
- Выясняем, какая команда складывает числа. Для этого заглянем в книгу того же Абеля, где дается такой пример:
сложение содержимого
ADD AX,25 ;Прибавить 25
ADD AX,25H ;Прибавить 37 - Значит, нам нужна команда ADD. Теперь определимся: нам же нужно сложить две переменные, а это ячейки памяти; эта команда не умеет складывать сразу из переменной в переменную, для нее нужно сначала слагаемое поместить в регистр (AX для этого лучше подходит), а уж потом суммировать в него. Для помещения из памяти в регистр (согласно тому же Абелю) нужна команда
mov [адрес], ax
- Таким образом, инструкции будут выглядеть так:
mov [Адрес первой переменной], ax
add [Адрес второй переменной], ax - Теперь нужно определиться с кодами этих команд. В комплекте с MASM идет хелп, где описаны команды и их опкоды (машинные коды, операционные коды). Вот, например, как выглядит опкод команды MOV из переменной:
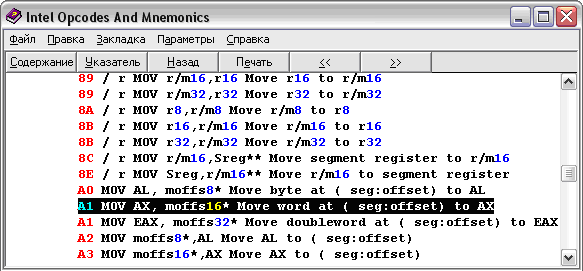
Рис. 9. Опкоды MOV
Видим (см. Рис. 9), что его опкод A1 (тут тоже любят 16-тиричность). Таким образом, выяснив все коды, можно написать компилятор что-то вроде этого (см. листинг 2):
Commands:= Commands+#$A1#$00#$00; { mov [Из памяти] в AX}
aPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной a}
Commands:= Commands+#$03#$06#$00#$00;
{ $03 – Это опкод команды ADD $06 – Это номер регистра AX}
bPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной b}
Commands:= Commands+#$A3#$00#$00; { mov из AX в переменку b}
b2Pos:= Length(Commands)-1;
{Запомним позицию для корректировки для переменной b}А далее, в конце, скорректируем эти позиции (см. листинг 3):
commands:= commands+#$01#$00; {Это переменка a, ее значение}
i:= length(commands);
commands[aPos]:= chr(lo(i)); {Не забудем, что адреса в перевернутом виде}
commands[
aPos+1]:= chr(hi(i)); {Поэтому сначала запишем младший байт}
commands:= commands+#$02#$00; {Это переменка b, ее значение}
i:= length(commands);
commands[bPos]:= chr
(lo(i)); {Поскольку переменка b фигурирует в коде}
commands[bPos+1]:= chr(hi(i)); {дважды придется корректировать ее}
commands[b2Pos]:= chr
span style=”color: #66cc66;”>(lo(i));
commands[b2Pos+1]:= chr(hi(i));Запустим компилятор, он скомпилирует экзэшник, который посмотрим в “Иде” (см. Рис. 10):
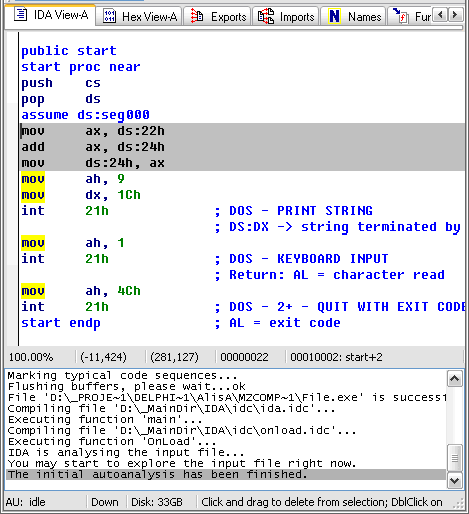
Рис. 10. Реверсинг нашего кода
Все верно, в регистр пошло значение одной переменной, сложилось со второй и во вторую же записалось. Это эквивалентно паскалевскому b:=b+a;
* Комментарий автора.
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
commands:=commands+#$01#$00; {Вот сюда вместо этих циферок}.
Post Scriptum
Ну как, студенты, воспряли духом? Теперь понятен смысл, куда двигаться в случае столкновения с такими задачами? Это вряд ли потянет на курсовую, но вполне подойдет для простенькой контрольной. А вот следующая задача – написать транслятор – уже действительно тянет даже на хороший диплом, так что пока переварим все то, что выше, а в следующий раз попробуем приготовить основное ядро компилятора, дабы потом уже делать упор на сам код программы.
The Чтиво
- Ресурс Википедии по языку LISP http://ru.wikipedia.org/wiki/Lisp
- Ресурс Википедии по формату PE http://ru.wikipedia.org/wiki/PE
- Ресурс Википедии по формату MZ http://ru.wikipedia.org/wiki/MZ_(формат)
- Micheal J. O’Leary (Microsoft). The portable executable format http://www.nikse.dk/petxt.html
- Описание простейших команд Ассемблера http://students.uni-vologda.ac.ru/pages/it10/2.php
- Питер Абель. Ассемблер и программирование для IBM PC. – British Columbia Institute of Technology
Статья из шестого выпуска журнала “ПРОграммист”.
Обсудить на форуме — Компилятор домашнего приготовления. Часть 1
21st
Сен
О правильном составлении ТЗ. Часть 1
Рано или поздно в жизни программиста появляется заказчик с неким проектом. Разработчик берется за этот проект, но результатом каждой последующей встречи с заказчиком становится появление новых функциональных и нефункциональных требований, в то время как сроки сдачи и бюджет остаются прежними, таким образом, все наваливается снежным комом, и в итоге наступает коллапс. Для того, чтобы такая скверная ситуация не наступила, с заказчиком нужно договориться еще на берегу. Но нельзя полагаться на какие-то словесные договоренности и т. п.: мы должны максимальн
о себя обезопасить. Разрабатывая программу, мы преследуем определенную цель, ставим перед собой определенные задачи. Успех нашего дела во многом зависит от того, насколько наша цель будет четкой и ясной. Знакомясь с выполненной работой, заказчик, естественно, будет анализировать, выполнили ли мы поставленные задачи, поэтому все они должны быть четко сформулированы, описаны и согласованы с ним. Вот тут нам на помощь и приходит ТЗ.
Дарья Устюгова
by Sparky
Введение
В цикле статей, основываясь на своем опыте и на опыте других, я попробую рассказать, что такое ТЗ, зачем оно нам нужно, из чего состоит, как его написать и оформить, какие подводные камни можно обойти, написав грамотное ТЗ. В первой статье я постараюсь объяснить, зачем ТЗ используется, в чем его плюсы, кто его должен писать, и приведу примерное содержание ТЗ.
Техническое задание. Что это и зачем оно нам?
Начнем мы с определения: техническое задание (ТЗ) – точная формулировка задачи. Можно даже сказать, что ТЗ всему голова. Многие слышали о таком понятии, как жизненный цикл программного обеспечения (ПО); для тех, кто не слышал, а быть может, просто забыл, напомню: жизненный цикл ПО – системы процедур, правил и инструментальных средств, используемых для разработки и поддержания работоспособности программной системы. Жизненный цикл включает в себя этапы создания программы. Существует множество версий: по Глассу, по ГОСТ ЕСПД, по Майерсу. Все эти версии
1st
Сен
СТАТЬЯ 2. ХОСТИНГ И ДОМЕННОЕ ИМЯ
В этой статье мне бы хотелось осветить проблему хостинга сайта (места на сервере), а также выбора доменного имени (адреса вашего сайта). О том, как выбирать хостинг, о платном и бесплатном хостинге, о критериях выбора хостинга, а также о доменных именах второго и третьего уровня и их выборе вы сможете прочитать в данной статье.
Итак, во-первых, необходимо выяснить, что же такое хостинг и зачем он нужен. Хост — сервер, на котором будет храниться ваш сайт и этот сервер выдает страницы при запросе их пользователем. Свои услуги хостинга предлагают многие компании сегодня. Но хостом может стать любой компьютер, подключенный в сети. Но в этом случае все зависит от того, каким образом ваш компьютер подключен к всемирной паутине и какая при этом скорость передачи. В то же время ваш компьютер должен быть всегда включен и подключен к сети. Такой способ «самохостинга» очень трудный и доставляет много хлопот. И именно для того, чтобы облегчить размещение сайтов существуют хостинг-провайдеры. Каждый хостинг-провайдер имеет свои базы данных, в которых хранятся материалы сайтов, которыми они предоставляют свои услуги. В зависимости от способа хранения сервера бывают хорошие и не очень. Конечно, хостинг — дело не бесплатное, у каждой такой компании свои услуги на хостинг и в то же время свои уникальные предложения. Поэтому у начинающих веб-мастеров возникают проблемы и трудности в вопросе выбора хостин-провайдера. Я советую выбирать те компании, которые работают на рынке уже много времени и клиенты которой довольны работой своего хостинг-провайдера. Не надо попадаться на уловки и предложения о хостинге по низкой цене. Вы воспользуетесь таким предложением, а посетители вашего сайта будут очень недовольны маленькой скоростью передачи (скорость передачи также зависит и от сервера), а также проблемами с доступом. Такие компании в чем-то отказывают своим клиентам, но не говорят об этом. Да и сами клиенты не понимают, что их обманывают. Сервера же, которые работают на рынке и предоставляют свои услуги не первый год имеют какой-то опыт и у них перебоев в работе не будет. Такие компании очень надежны, поэтому их цена и может быть выше цен конкурентов.
Узнать о компаниях, предоставляющих хостинг и стать их клиентом можно просто набрав «Хостинг» в какой-нибудь поисковой системы. Отнеситесь к выбору своего хостинг-провайдера необходимо серьезно и выбрать его только подумав и обдумав все.
Надо сказать еще и о такой вещи, как бесплатный хостинг. Мы все знаем, что сайтов на бесплатном хостинге очень много и их почти никто не посещает. Бесплатный хостинг очень не надежен и опытные пользователи интернет не посещают такие сайты. Также обычно бывает так, что компании, предоставляющие бесплатный хостинг предоставляют и бесплатное доменное имя 3-го уровня (например, my.site.com). Я не советую вам обзаводиться сайтом на бесплатном хостинге. Лучше немного вложить в развитие своего сайта, если вы хотите что-то заработать. Бесплатный хостинг подходит домашним страничкам. Как правило домашние странички просто знакомят посетителей с хозяевами этих страничек, поэтому как бесплатный хостинг, так и доменное имя 3-го уровня подходят домашним страничкам.
Итак, доменное имя, что это такое и как его выбрать? Существуют доменные имена первого уровня, например .ru , .com , .net и т.д. У каждой страны имеется свой домен, например у России это .ru, у Китая это .cn, а у Германии .de . Также существуют международные домены, такие как .com, .biz, .info, .org, .net и т.д. «Простым сайтовладельцам» предлагается регистрация доменного имени второго уровня (sitename.ru). Регистрация такого домена возможна в любой доменной зоне, но лучше выбирать тот домен, под который подойдет тематика сайта, например для сайта организации подойдет домен .org, для «бизнес-сайта» подойдет .biz, а для сайта направленного на российскую аудиторию .ru. Адрес сайта уже говорит о его содержании, поэтому необходимо выбирать то, что вам подойдет. Доменное имя должно быть легким, запоминающимся, звучным, интересным одновременно. Подобрать подходящий адрес для своего сайта совсем не просто и это сложно сделать за одну минуту или даже за один день. Многие доменные имена уже заняты и бывает трудно подобрать незанятое и подходящее одновременно. Но если у вас есть цель найти подходящее имя, вы обязательно найдете его. Некоторые доменные имена куплены для продажи за большие деньги, все дело именно в популярности слова. Например, домен Internet.ru настолько прост и легок, что пользователь может прийти на этот сайт даже просто набрав адрес в окне браузера, не подозревая о существовании сайта с таки адресом. А вот адрес mybb.ru никто не наберет просто так. Я советую вам выбирать имя без чисел в нем, вез неизвестных и придуманных слов, а также не выбирать слишком сложные для запоминания слова, выберите слово, которое часто встречается в быту (конечно, сегодня такой домен застать не занятым трудно, но все же возможно).
Доменные имена регистрируют те же компании, предоставляющие хостинг или же отдельно взятые регистры. Доменные имена 3-го уровня я не советую никому. Один домен второго уровня равен 10 доменам третьего уровня, вместе взятым по интересу к нему, а также по ТИЦ (индексу цитирования, по которому поисковая машина выдает результаты).
Наконец, после выбора доменного имени и хостинговой компании можно приступить к созданию самого сайта…
1st
СТАТЬЯ 3. СОЗДАНИЕ И УПРАВЛЕНИЕ САЙТОМ
В этой статье я попробую рассказать вам о способах создания и управления собственный сайтом. Создать сайт можно очень разными способами, я расскажу вам о самых популярных и удобных. А управлять сайтом можно также самыми разнообразными способами. Прочитав эту статью вы сможете выбрать тот способ управления сайтом, который подойдет именно вам.
Создать страницы своего сайта можно как в простой программе, так и в сложном редакторе. Конечно, самым привлекающим в программе является его просто и в то же время функциональность. Если вы не знаете о языках программирования (языки Веб-программирования станут темой одной из следующих статей из этой серии), вам наверно необходимо что-нибудь простое. Если же у вас есть какой-то опыт, и вы знаете хотя бы основы языка, то вам будет и удобнее с редактором страниц. Но в то же время, существуют программы, которые будут полезны и необходимы, как начинающим Веб-мастерам, так и опытным. Такими программами для меня являются Microsoft Office FrontPage, Macromedia HomeSite и другие .С этой программой очень удобно. Но появляются новые и даже лучшие программы, среди которых также может быть много полезного. Вообще, если зайти в ближайший компьютерный магазин и купить один из дисков о создании сайтов (а таких очень много) то и там вы найдете что-нибудь подходящее себе. В подобных программах вам необходимо только разобраться, знаний в языке программирования даже не требуется.
1st
КОНТАКТЫ
КОНТАКТЫ
написать в » клуб программистов «
Не забудьте указать в «Дополнительных настройках» e-mail администратора.
Указанный e-mail: admin@programmersclub.ru
Указанный e-mail: admin@programmersclub.ru
заявка на публикацию программы, статьи
Не забудьте указать в «Дополнительных настройках» e-mail администратора.
Указанный e-mail: admin@programmersclub.ru
Указанный e-mail: admin@programmersclub.ru
1st
КЛУБ
В мае был запущен блог программистов
Теперь участники нашего клуба могут самостоятельно публиковать статьи. Для публикации статей и новостей нужно быть постоянным участникомФорума , зарегистрироваться в блоге, получить права редактора.
В блоге только авторские статьи, вы всегда сможете получить комментарии от автора.
Участники клуба программистов
Все статьи — это лишь мнение и опыт их авторов. Мнение администратора и авторов статей могут не совпадать. Хотя все статьи проходят проверку администратором, проводится необходимая правка.
Администратор оставляет за собой право высказать мнение о статье, также возможна публикация мнений других участников клуба.
1st
Extended- Тип
Extended
Тип с плавающей запятой с наивысшей емкостью и точностью
Описание:
Тип Extended — это тип с плавающей запятой, используемый в случаях, когда требуется наибольшая экспонента и/или значащие разряды.
Он поддерживает около 19 значащих разрядов в диапазоне от 3.37 x 10-4932 до 1.18 x 104932.
Пример кода:
var
account1, account2, account3, account4 : Extended;
begin
account1 := 0.1234567890123456789; // 20 decimal places
account2 := 3.37E-4932; // Lowest exponent value
account3 := 1.18E4932; // Highest exponent value
account4 := 1.19E4932; // Treated as infinite
account1, account2, account3, account4 : Extended;
begin
account1 := 0.1234567890123456789; // 20 decimal places
account2 := 3.37E-4932; // Lowest exponent value
account3 := 1.18E4932; // Highest exponent value
account4 := 1.19E4932; // Treated as infinite
ShowMessage(‘Account1 = ‘+FloatToStrF(account1, ffGeneral, 22, 20));
ShowMessage(‘Account2 = ‘+FloatToStr(account2));
ShowMessage(‘Account3 = ‘+FloatToStr(account3));
ShowMessage(‘Account4 = ‘+FloatToStr(account4));
end;
Результат выполнения:
Account1 = 0.123456789012345679
Account2 = 3.37E-4932
Account3 = 1.18E4932
Account4 = INF
Account2 = 3.37E-4932
Account3 = 1.18E4932
Account4 = INF
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
29th
Авг
УРОКИ FLASH MX 2004
<<< Назад Flash MX 2004 Упражнение 1
Flash MX 2004. Упражнение 2
Создание плывущего корабля.
Для создания плывущего кораблика мы будет пользоваться только инструментами Macromedia Flash MX 2004.
 |
Для прорисовки прямых линий необходимо использовать инструмент line tool. Линиями мы прорисовываем корпус и мачту, на которой будет расположен парус. |
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
