

Последние записи
- Автоматическое уничтожение объектов
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
25th
Авг
 ОТСОРТИРОВАТЬ ЭЛЕМЕНТЫ МАТРИЦЫ ПО УБЫВАНИЮ
ОТСОРТИРОВАТЬ ЭЛЕМЕНТЫ МАТРИЦЫ ПО УБЫВАНИЮ
Организовать заполнение двумерного массива целыми числами случайным образом используя функцию RAndom. Отсортировать элементы матрицы по убыванию. Вывести на экран массив до и после изменения.
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
УРОК 28. ЧАСТНЫЕ ЭЛЕМЕНТЫ И ДРУЗЬЯ
Как вы уже знаете, ваши программы могут обращаться к частным (private) элементам класса только с помощью функций-элементов этого же класса. Используя частные элементы класса вместо общих во всех ситуациях, где это только возможно, вы уменьшаете возможность программы испортить значения элементов класса, так как программа может обращаться к таким элементам только через интерфейсные функции (которые управляют доступом к частным элементам). Однако в зависимости от использования объектов вашей программы, иногда вы можете существенно увеличить производительность позволяя одному классу напрямую обращаться к частным элементам другого. В этом случае уменьшаются издержки (требуемое время выполнения) на вызов интерфейсных функций. В подобных ситуациях C++ позволяет определить класс в качестве друга (friend} другого класса и разрешает классу-другу доступ к частным элементам этого другого класса. В этом уроке объясняется, как ваши программы могут указать, что два класса являются друзьями. К концу данного урока вы освоите следующие основные концепции:
- Используя ключевое слово friend, класс может сообщить C++, кто является его другом, т. е. другими словами, что другие классы могут обращаться напрямую к его частным элементам.
- Частные элементы класса защищают данные класса, следовательно, вы должны ограничить круг классов-друзей только теми классами, которым действительно необходим прямой доступ к частным элементам искомого класса.
- C++ позволяет ограничить дружественный доступ определенным набором функций.
Частные (private) элементы позволяют вам защищать классы и уменьшить вероятность ошибок. Таким образом, вы должны ограничить использование классов-друзей настолько, насколько это возможно. Иногда программа напрямую может изменить значения элементов класса, это увеличивает вероятность появления ошибок.
ОПРЕДЕЛЕНИЕ ДРУЗЕЙ КЛАССА
C++ позволяет друзьям определенного класса обращаться к частным элементам этого класса. Чтобы указать C++, что один класс является другом (friend) другого класса, вы просто помещаете ключевое слово friend и имя соответствующего класса-друга внутрь определения этого другого класса. Например, приведенный ниже класс book объявляет класс librarian своим другом. Поэтому объекты класса librarian могут напрямую обращаться к частным элементам класса book, используя оператор точку:
class book
{
public:
book (char *, char *, char *);
void show_book(void);
friend librarian;
private:
char title [64] ;
char author[64];
char catalog[64];
};
Как видите, чтобы указать друга, необходим только один оператор внутри определения класса. Например, следующая программа VIEWBOOK.CPP использует librarian в качестве друга класса book. Следовательно, функции класса librarian могут напрямую обращаться к частным элементам класса book. В данном случае программа использует функцию change_catalog класса librarian для изменения номера карточки каталога определенной книги:
#include <iostream.h>
#include <string.h>
class book
{
public:
book (char *, char *, char *);
void show_book(void);
friend librarian;
private:
char title[64] ;
char author[64];
char catalog[64];
};book::book(char *title, char *author, char •catalog)
{
strcpy(book::title, title);
strcpy(book::author, author) ;
strcpy(book::catalog, catalog);
}void book::show_book(void)
{
cout << «Название: » << title << endl;
cout << «Автор: » << author << endl;
cout << «Каталог: » << catalog << endl;
}class librarian
{
public:
void change_catalog(book *, char *);
char *get_catalog(book);
};void librarian::change_catalog(book *this_book, char *new_catalog)
{
strcpy(this_book->catalog, new_catalog);
}char *librarian: :get__catalog(book this_book)
{
static char catalog[64];
strcpy(catalog, this_book.catalog);
return(catalog) ;
}void main(void)
{
book programming( «Учимся программировать на языке C++», «Jamsa», «P101»);
librarian library;
programming.show_book();
library.change_catalog(&programming, «Легкий C++ 101»);
programming.show_book();
}
Как видите, программа передает объект book в функцию change_catalog класса librarian по адресу. Поскольку эта функция изменяет элемент класса book, программа должна передать параметр по адресу, а затем использовать указатель для обращения к элементу этого класса. Экспериментируйте с данной программой, попробуйте удалить оператор friend из определения класса book. Поскольку класс librarian больше не имеет доступа к частным элементам класса book, компилятор C++ сообщает о синтаксических ошибках при каждой ссылке на частные данные класса book.
О друзьях класса
Обычно единственный способ, с помощью которого ваши программы могут обращаться к частным элементам класса, заключается в использовании интерфейсных функций. В зависимости от использования объектов программы иногда может быть удобным (или более эффективным с точки зрения скорости вычислений) разрешить одному классу обращаться к частным элементам другого. Для этого вы должны информировать компилятор C++, что класс является другом (friend). Компилятор, в свою очередь, позволит классу-другу обращаться к частным элементам требуемого класса. Чтобы объявить класс другом, поместите ключевое слово friend и имя класса-друга в секцию public определения класса, как показано ниже:
class abbott
{
public:
friend costello;
// Общие элементы
private:
// Частные элементы
};Как друзья отличаются от защищенных (protected) элементов
Из урока 26 вы узнали, что в C++ существуют защищенные (protected) элементы класса, что позволяет производным классам обращаться к защищенным элементам базового класса напрямую, используя оператор точку. Помните, что к защищенным элементам класса могут обращаться только те классы, которые являются производными от данного базового класса, другими словами, классы, которые наследуют элементы базового класса (защищенные элементы класса являются как бы частными по отношению к остальным частям программы). Классы-друзья C++ обычно не связаны между собой узами наследования. Единственный способ для таких не связанных между собой классов получить доступ к частным элементам другого класса состоит в том, чтобы этот другой класс информировал компилятор, что данный класс является другом.
ОГРАНИЧЕНИЕ КОЛИЧЕСТВА ДРУЗЕЙ
Как вы только что узнали, если вы объявляете один класс другом другого класса, вы обеспечиваете классу-другу доступ к частным элементам данных этого другого класса. Вы также знаете и то, что чем больше доступа к частным данным класса, тем больше шансов на внесение ошибок в программу. Следовательно, если доступ к частным данным другого класса необходим только нескольким функциям класса, C++ позволяет указать, что только определенные функции дружественного класса будут иметь доступ к частным элементам. Предположим, например, что класс librarian, представленный в предыдущей программе, содержит много разных функций. Однако предположим, что только функциям change_catalog и get_catalog необходим доступ к частным элементам класса book. Внутри определения класса book мы можем ограничить доступ к частным элементам только этими двумя функциями, как показано ниже:
class book
{
public:
book(char *, char *, char *);
void show_book(void);
friend char *librarian::get_catalog(book);
friend void librarian: :change_catalog( book *, char *);
private:
char title[64];
char author[ 64 ];
char catalog[64];
};
Как видите, операторы friend содержат полные прототипы всех дружественных функций, которые могут напрямую обращаться к частным элементам.
О функциях-друзьях
Если ваша программа использует друзей для доступа к частным данным класса, вы можете ограничить количество функций-элементов класса-друга, который может обращаться к частным данным, используя дружественные функции. Для объявления функции-друга укажите ключевое слово friend, за которым следует полный прототип, как показано ниже:
public:
friend class_name::function_name(parameter types);Только функции-элементы, указанные как друзья, могут напрямую обращаться к частным элементам класса, используя оператор точку.
Если ваша программа начинает ссылаться на один класс из другого, вы можете получить синтаксические ошибки, если порядок определения классов неверен. В данном случае определение класса book использует прототипы функций, определенные в классе librarian. Следовательно, определение класса librarian должно предшествовать определению класса book. Однако если вы проанализируете класс librarian, то обнаружите, что он ссылается на класс book:
class librarian
{
public:
void change_catalog(book *, char *);
char *get_catalog(book);
};
Поскольку вы не можете поставить определение класса book перед определением класса librarian, C++ позволяет вам объявить класс book, тем самым сообщая компилятору, что такой класс есть, а позже определить его. Ниже показано, как это сделать:
class book; // объявление класса
Следующая программа LIMITFRI.CPP использует дружественные функции для ограничения доступа класса librarian к частным данным класса book. Обратите внимание на порядок определения классов:
#include <iostream.h>
#include <string.h>
class book;
class librarian
{
public:
void change_catalog(book *, char *);
char *get_catalog(book);
};class book
{
public:
book(char *, char *, char *) ;
void show_book (void);
friend char *librarian::get_catalog(book);
friend void librarian::change_catalog( book *, char *);
private:
char title[64];
char author[64];
char catalog[64];
};book::book(char *title, char *author, char *catalog)
{
strcpy(book::title, title);
strcpy(book::author, author);
strcpy(book::catalog, catalog);
}void book::show_book(void)
{
cout << «Название: » << title << endl;
cout << «Автор: » << author << endl;
cout << «Каталог: » << catalog << endl;
}void librarian::change_catalog(book *this_book, char *new_catalog)
{
strcpy(this_book->catalog, new_catalog) ;
}char *librarian::get_catalog(book this_book)
{
static char catalog[64];
strcpy(catalog, this_book.catalog);
return(catalog) ;
}void main(void)
{
book programming( «Учимся программировать на C++», «Jamsa», «P101»);
librarian library;
programming.show_book();
library.change_catalog(&programming, «Легкий C++ 101»);
programming.show_book();
}
Как видите, программа сначала использует объявление, чтобы сообщить компилятору, что класс book будет определен позже. Поскольку объявление извещает компилятор о классе book, определение класса librarian может ссылаться на класс book, который еще не определен в программе.
Что такое идентификатор класса
Идентификатор представляет собой имя, например имя переменной или класса. Если ваши программы используют дружественные классы, то может случиться, что определение одного класса ссылается на другой класс (его имя или идентификатор), о котором компилятор C++ еще ничего не знает. В таких случаях компилятор C++ будет сообщать о синтаксических ошибках. Чтобы избавиться от ошибок типа «что следует определять сначала», C++ позволяет вам включать в начало исходного текста программы объявление класса, тем самым вводя идентификатор класса:
class class_name;
Эта строка сообщает компилятору, что ваша программа позже определит указанный класс, а пока программе разрешается ссылаться на этот класс.
ЧТО ВАМ НЕОБХОДИМО ЗНАТЬ
В данном уроке вы изучили, как использовать классы-друзья для обращения к частным элементам другого класса напрямую с использованием оператора точки. В уроке 29 вы изучите, как использовать в C++ шаблоны функций для упрощения определения подобных функций. Но прежде чем перейти к уроку 29 убедитесь, что вы освоили следующее:
- Использование в ваших программах на C++ друзей позволяет одному классу обращаться к частным элементам другого класса напрямую, используя оператор точку.
- Для объявления одного класса другом (friend) другого класса вы должны внутри определения этого другого класса указать ключевое слово friend, за которым следует имя первого класса.
- После объявления класса другом по отношению к другому классу, все функции-элементы класса-друга могут обращаться к частным элементам этого другого класса.
- Чтобы ограничить количество дружественных методов, которые могут обращаться к частным данным класса, C++ позволяет указать дружественные функции. Для объявления функции-друга вы должны указать ключевое слово friend, за которым следует прототип функции, которой, собственно, и необходимо обращаться к частным элементам класса.
- При объявлении дружественных функций вы можете получить синтаксические ошибки, если неверен порядок определений классов. Если необходимо сообщить компилятору, что идентификатор представляет имя класса, который программа определит позже, вы можете использовать оператор такого вида class class_name;.
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
ТЕОРЕМА ШЕННОНА
Теорема Шеннона, одна из основных теорем теории информации о передаче сигналов по каналам связи при наличии помех, приводящих к искажениям. Пусть надлежит передать последовательность символов, появляющихся с определёнными вероятностями, причём имеется некоторая вероятность того, что передаваемый символ в процессе передачи будет искажён. Простейший способ, позволяющий надёжно восстановить исходную последовательность по получаемой, состоит в том, чтобы каждый передаваемый символ повторять большое число (N) раз. Однако это приведёт к уменьшению скорости передачи в N раз, т. е. сделает её близкой к нулю. Ш. т. утверждает, что можно указать такое, зависящее только от рассматриваемых вероятностей положительное число v, что при сколько угодно малом e> 0 существуют способы передачи со скоростью v'(v’ < v), сколь угодно близкой к v, дающие возможность восстанавливать исходную последовательность с вероятностью ошибки, меньшей e. В то же время при скорости передачи v’, бо льшей v, это уже невозможно. Упомянутые способы передачи используют надлежащие «помехоустойчивые» коды. Критическая скорость v определяется из соотношения Hv = C, где Н — энтропия источника на символ, С — ёмкость канала в двоичных единицах в секунду.
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
МОЩНЫЙ ИНСТАЛЯТОР
Install Creation System — программа для создания инсталляционных программ средней мощности, включает в себя все возможности для создания инсталляционных программ:
Установка различных версий установки.
Изменение реестра.
Удаление проделанной установки.
Программа удаления будет присутствовать в списке установки и удаления программ в Панели управления.
Установка рисунков на страницы диалога максимально упрощена.
Создание различных версий установки тоже элементарно просто.
Полный набор страниц диалога.
Возможность устанавливать некоторые файлы по абсолютному пути независимо от папки которую выбрал пользователь.
Создание ярлыков возможно везде где вы только захотите.
Присутствуют почти все системные константы, также можно создавать свои константы.
Автор статьи Ahilles
Руслан Аблязов E-mail
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
Создание логотипа для журнала ПРОграммист
Предлагаю здесь выкладывать работы, которые претендуют на то, чтобы стать логотипом журнала ПРОграммист. Я знаю, что здесь есть много креативных людей. Не лучший ли это случай проявить свою фантазию и дизайнерские навыки?
Внимание!
Логотип будет размещаться в левом верхнем углу, там где надпись “ПРОграммист” на каждой странице
Следовательно, исходить нужно из этих предпосылок, т.е. не делать мелких деталей.
Кроме того, нужен логотип-баннер (для обмена ссылками) журнала
Его тоже можно здесь выкладывать.
25th
Операционная система unix, термины и понятия
ОСНОВНЫЕ ПОНЯТИЯ
На первый взгляд UNIX выглядит неоправданно сложной операционной системой. Но под кажущейся сложностью скрывается очень простая и элегантная операционная система. Отдельные детали могут быть сложными, но общие принципы — просты.
Одним из достоинств ОС UNIX является то, что система базируется на небольшом числе интуитивно ясных понятий. Однако, несмотря на простоту этих понятий, к ним нужно привыкнуть. Без этого невозможно понять существо UNIX.
25th
УРОК 14 ИСПОЛЬЗОВАНИЕ ССЫЛОК В C++
Из урока 10 вы узнали, как изменять параметры внутри функции с помощью указателей. Для использования указателей вы должны предварять имена переменных-указателей звездочкой. Использование указателей досталось в «наследство» от языка С. Чтобы упростить процесс изменения параметров, С++ вводит такое понятие как ссылка. Как вы узнаете из этого урока, ссылка представляет собой псевдоним (или второе имя), который ваши программы могут использовать для обращения к переменной. К концу данного урока вы освоите следующие основные концепции:
• Для объявления и инициализации ссылки внутри программы объявите переменную, размещая амперсанд (&) сразу же после типа переменной, и затем используйте оператор присваивания для назначения псевдонима, например int& alias_name = variable’,.
• Ваши программы могут передавать ссылки в функцию в качестве параметров, а функция, в свою очередь, может изменять соответствующее значение параметра, не используя указателей.
• Внутри функции вам следует объявить параметр как ссылку, размещая амперсанд (&) после типа параметра, затем можно изменять значение параметра внутри функции без помощи указателей.Как вы узнаете, использование указателей очень упрощает изменение значений параметров внутри функции.
ССЫЛКА ЯВЛЯЕТСЯ ПСЕВДОНИМОМ
Ссылка C++ позволяет создать псевдоним (или второе имя) для переменных в вашей программе. Для объявления ссылки внутри программы укажите знак амперсанда (&) непосредственно после типа параметра. Объявляя ссылку, вы должны сразу же присвоить ей переменную, для которой эта ссылка будет псевдонимом, как показано ниже:
int& alias_name = variable; //—> Объявление ссылки
После объявления ссылки ваша программа может использовать или переменную , или ссылку:
alias_name = 1001;
variable = 1001;
Следующая программа SHOW_REF.CPP создает ссылку с именемalias_name и присваивает псевдониму переменную number. Далее программа использует как ссылку, так и переменную:
#include <iostream.h>
void main(void)
{
int number = 501;
int& alias_name = number; // Создать ссылку
cout << «Переменная number содержит » << number << endl;
cout << «Псевдоним для number содержит » << alias_name << endl;
alias_name = alias_name + 500;
cout << «Переменная number содержит » << number << endl;
cout << «Псевдоним для number содержит » << alias_name << endl;
}
Как видите, программа прибавляет 500 к ссылке alias_name. В итоге программа прибавляет 500 также и к соответствующей переменнойnumber, для которой ссылка служит псевдонимом или вторым именем. Когда вы откомпилируете и запустите эту программу, на вашем экране появится следующий вывод:
С:\> SHOW_REF <ENTER>
Переменная number содержит 501
Псевдоним для number содержит 501
Переменная number содержит 1001
Псевдоним для number содержит 1001
В общем случае использование ссылки таким образом, как только что было показано, создает трудности для понимания. Однако вы увидите, что использование ссылок значительно упрощает процесс изменения параметров внутри функции.
Объявление ссылкиСсылка C++ представляет собой псевдоним (второе имя), которое ваши программы могут использовать для обращения к переменной. Для объявления ссылки поставьте амперсанд (&) сразу же после типа переменной, а затем укажите имя ссылки, за которым следует знак равенства и имя переменной, для которой ссылка является псевдонимом:
float& salary_alias = salary;
ИСПОЛЬЗОВАНИЕ ССЫЛОК В КАЧЕСТВЕ ПАРАМЕТРОВ
Основное назначение ссылки заключается в упрощении процесса изменения параметров внутри функции. Следующая программа REFERENC.CPP присваивает ссылку с именем number_alias переменнойnumber. Программа передает ссылку на переменную в функциюchange_value, которая присваивает переменной значение 1001:
#include <iostream.h>
void change_value(int &alias)
{
alias = 1001;
}
void main(void)
{
int number;
int& number_alias = number;
change_value(number_alias);
out << «Переменная number содержит » << number << endl;
}
Как вы видите, программа передает ссылку в функцию change_value. Если вы рассмотрите объявление функции, вы обнаружите, что change_valueобъявляет параметр alias как ссылку на значение типа int.
void change_value(int& alias)
Внутри функции change_value можете изменять значение параметра без помощи указателя. В результате звездочка (*) не используется и операция внутри функции становится легче для понимания.
Использование комментариев для объяснения ссылок внутри ваших программБольшинство программистов C++ знакомы с языком программирования С, и они привыкли использовать указатели внутри функции, если необходимо изменить значение параметра. В результате, если такие программисты не видят указатели внутри функций, которые используют ссылки, они могут предположить, что значения параметров не изменяются. Для предотвращения подобных промахов не забывайте размещать несколько комментариев до и внутри функций, которые изменяют параметры с помощью ссылок. В таком случае программисты С лучше поймут работу ваших функций.
Рассмотрим второй пример
В уроке 10 вы использовали следующую функцию для перестановки двух значений с плавающей точкой:
void swap_values(float *a, float *b)
{
float temp;
temp = *a;
*a = *b;
*b = temp;
}
Как видите, функция комбинирует переменные-указатели с переменными-неуказателями. Следующая программа SWAP_REF.CPP использует ссылки на значения с плавающей точкой для упрощения функции:
#include <iostream.h>
void swap_values(float& a, float& b)
{ float temp;
temp = a;
a = b;
b = temp;
}
void main(void)
{ float big = 10000.0;
float small = 0.00001;
float& big_alias = big;
float& small_alias = small;
swap_values(big_alias, small_alias);
cout << «Big содержит » << big << endl;
cout << «Small содержит » << small << endl;
}
Как видите, функцию swap_values сейчас легче понять, однако ваша программа имеет теперь два дополнительных имени (ссылки big_alias и small_alias), за которыми вы должны следить.
ПРАВИЛА РАБОТЫ СО ССЫЛКАМИ
Ссылка не является переменной. Один раз присвоив значение ссылке, вы уже не можете ее изменить. Кроме того в отличие от указателей вы не можете выполнить следующие операции над ссылками:
• Вы не можете получить адрес ссылки, используя оператор адреса C++.
• Вы не можете присвоить ссылке указатель.
• Вы не можете сравнить значения ссылок, используя операторы сравнения C++.• Вы не можете выполнить арифметические операции над ссылкой, например добавить смещение.•Вы не можете изменить ссылку.По мере использования объектно-ориентированного программирования на C++ вы вернетесь к ссылкам.Использование ссылок для изменения параметров функцииИз урока 10 вы узнали, что ваши программы с помощью указателей могут изменять значение параметров внутри функции. Для изменения параметра вы должны передать его адрес в функцию. Чтобы получить адрес параметра, используйте оператор адреса C++ (&). В свою очередь функция использует переменные-указатели (которые хранят адрес памяти). Для объявления переменной-указателя внутри функции предваряйте имя параметра звездочкой (*). Чтобы изменить или использовать значение параметра внутри функции, предваряйте каждое обращение к имени этого параметра оператором разыменования C++ (*). К сожалению, многие операции внутри функции комбинируют переменные-указатели и переменные-неуказатели.
Ссылки C++ упрощают процесс изменения параметров функции, избавляя от операторов, которые смешивают переменные-указатели и переменные-неуказатели.
ЧТ0 ВАМ НЕОБХОДИМО ЗНАТЬ
Из этого урока вы узнали, как использовать ссылки C++ для создания псевдонима или второго имени переменной. Использование ссылок может упростить функции, изменяющие значения параметров. Из урока 15 вы узнаете, что C++ позволяет вам задавать значения по умолчанию для параметров функции. При вызове функции программа может опускать значения одного или нескольких параметров и функция будет использовать значения по умолчанию. До изучения урока 15 убедитесь, что вы освоили следующие основные концепции:
-
- Ссылка C++ является псевдонимом (или вторым именем) переменной.
- Для объявления ссылки поместите знак амперсанда (&) непосредственно после типа переменной, а затем укажите имя ссылки, за которым следует знак равенства и имя переменной, для которой ссылка является псевдонимом.
- Если вы однажды присвоили ссылке значение, вы не можете его изменить.
- Вам следует помещать несколько комментариев до и внутри функций, которые используют ссылки для изменения значений параметра, чтобы другие программисты, читающие ваш код, сразу обратили, на это внимание.
- Чрезмерное использование ссылок может привести к слишком трудному для понимания программному коду.
Предыдущий урок | Следующий урок
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
УРОК 10 ИЗМЕНЕНИЕ ЗНАЧЕНИЙ ПАРАМЕТРОВ
Из урока 9 вы узнали, как разделить ваши программы на небольшие легко управляемые части, называемые функциями. Как вы уже знаете, программы могут передавать информацию (параметры) функциям. Представленные в уроке 9 программы использовали или выводили значения параметров, но не меняли их. Из этого урока вы узнаете, как изменить значение параметра в функции. Вы обнаружите, что для изменения параметров в функции фактически требуется больше шагов, чем можно предположить. Однако этот урок обучит вас всем шагам, которые необходимо знать. К концу данного урока вы освоите следующие основные концепции:
• Если функция не использует указатели или ссылки, она не может изменить значение параметра.
• Для изменения значения параметра функция должна знать адрес параметра в памяти.
• Оператор адреса C++ (&) позволяет вашей программе определить адрес переменной в памяти.
• Когда ваша программа узнает адрес памяти, она сможет использовать операцию разыменования C++ (*) для определения значения, хранимого по данному адресу.
• Если программе нужно изменить значение параметров функции, программа передает в функцию адрес параметра.
Изменение значения параметра функции представляет собой обычную операцию. Экспериментируйте с программами, представленными в этом уроке, чтобы убедиться, что вы полностью освоили этот процесс.
25th
УРОК 33. ДОПОЛНИТЕЛЬНЫЕ ВОЗМОЖНОСТИ CIN И COUT
На всем протяжении этой книги вы использовали выходной поток cout для вывода информации на экран дисплея. Аналогично, многие из ваших программ использовали входной поток cin для чтения информации с клавиатуры. Оказывается, cin и cout представляют собой классовые объекты, определяемые и создаваемые с помощью заголовочного файлаiostream.h. Как объекты cin и cout поддерживают различные операторы и операции. Из данного урока вы узнаете, как расширить возможности ввода и вывода, используя функции, встроенные в классы cin и cout. К концу этого урока вы освоите следующие основные концепции:
- Заголовочный файл iostream.h содержит определения классов, которые вы можете проанализировать, чтобы лучше понять потоковый ввод/вывод.
- Используя метод cout.width, ваши программы могут управлять шириной вывода.
- Используя метод cout.fill, ваши программы могут заменить пустые выходные символы (табуляцию и пробелы) некоторым определенным символом.
- Для управления количеством цифр, выводимых выходным потокомcout для значений с плавающей точкой, ваши программы могут использовать метод cout.setprecision.
- Для вывода и ввода по одному символу за один раз ваши программы могут использовать потоковые методы cout.put и cin.get.
- Используя метод cin.getline, ваши программы могут вводить целую строку за один раз.
Почти любая создаваемая вами на C++ программа будет использовать cout или cin для выполнения операций В/В (ввода/вывода). Выберите время для экспериментов с программами из этого урока.
25th
Делаем динамические тени на OPENGL. Часть 1
![]()
Здравствуйте. В этой статье я хочу рассмотреть создание движка динамического освещения с помощью графической библиотеки OpenGL. Писаться движок будет на Delphi, но это не мешает переписать его на любой другой язык, так как главное, рассматриваемое в статье, это алгоритмы…
Вадим Буренков
vadim_burenkov@mail.ru
Чтобы не тратить время на инициализацию OpenGL и избежать других проблем (например, с настройкой таймеров и рендера в текстуру) я буду использовать движок ZenGL [1]. Впрочем, от него нам многого не понадобится. Итак, приступим…
Инициализация OpenGL в ZenGL
Первым делом качаем ZenGL и создаем в нем простейшее приложение (вы можете найти его в папке LightEngine ресурсов статьи, там же вы найдете ZenGL):
код:
program LightEngine;
uses
zgl_main,
zgl_screen,
zgl_window,
zgl_timers,
zgl_textures,
zgl_textures_jpg,
zgl_sprite_2d,
zgl_mouse,
zgl_keyboard,
zgl_utils;
var
BackTex:zglPTexture; // текстура фона
bTiles:zglTTiles2D; // параметры тайлинга
uses
zgl_main,
zgl_screen,
zgl_window,
zgl_timers,
zgl_textures,
zgl_textures_jpg,
zgl_sprite_2d,
zgl_mouse,
zgl_keyboard,
zgl_utils;
var
BackTex:zglPTexture; // текстура фона
bTiles:zglTTiles2D; // параметры тайлинга
procedure Init;
var n,j:integer;
begin
// отключаем очищение буфера
zgl_disable(COLOR_BUFFER_CLEAR );
// Тут можно выполнять загрузку основных ресурсов
// загрузка текстуры и настройка тайлинга
BackTex:=tex_LoadFromFile( ‘Back.jpg’,0,TEX_DEFAULT_2D);
// параметры тайлов фона
bTiles.Count.X:=7;
bTiles.Count.Y:=5;
bTiles.Size.W:=128;
bTiles.Size.H:=128;
SetLength(bTiles.Tiles,7,5);
&nfor fto=0 to 4 do
&nbsforbsp;&ntob>for j:=0 to 6 do bTiles.Tiles[j,n]:=1;
end;
procedure Draw;
begin
// Тут «рисуем» что угодно 
tiles2d_Draw(BackTex,0,0,BTiles); // отрисовка фона
end;
procedure Update;
begin
// Тут выполняется обработка данных
if key_Press( K_ESCAPE ) then zgl_Exit;
// обновление клавиш
key_ClearState;
Mouse_ClearState;
end;
procedure Timer;
begin
// Будем в заголовке показывать количество кадров в секунду
wnd_SetCaption( ‘LightEngine [ FPS: ‘ + u_IntToStr( zgl_Get(
SYS_FPS ) ) + ‘ ]’ );
end;
procedure Quit;
begin
// Тут выполняется очищение данных
end;
Begin
// Создаем таймер с интервалом 1000мс.
timer_Add( @Timer, 1000 );
// Создаем таймер с интервалом 10мс.
timer_Add( @Update, 10 );
// Регистрируем процедуру, что выполнится сразу после
// инициализации ZenGL
zgl_Reg( SYS_LOAD, @Init );
// Регистрируем процедуру, где будет происходить рендер
zgl_Reg( SYS_DRAW, @Draw );
// Регистрируем процедуру, которая выполнится после завершения
// работы ZenGL
zgl_Reg( SYS_EXIT, @Quit );
// Устанавливаем заголовок окна
// Разрешаем курсор мыши
wnd_ShowCursor( TRUE );
// Указываем первоначальные настройки
scr_SetOptions( 800, 600, REFRESH_MAXIMUM, FALSE, FALSE );
// Инициализируем ZenGL
zgl_Init;
End.
При инициализации мы указываем процедуры в которых будут производится различные действия (инициализация/обработка/очищение) а также параметры окна.
В инициализации загружается текстура и настраивается тайлинг (количество и размер настроен так, чтобы текстура закрывала весь экран). В обработке обновляются состояния мыши и клавиатуры, а также стоит проверка на нажатие ESC. Процедура очищения пока пуста, так как ресурсы движка очищаются самостоятельно.
Другие непонятные процедуры можно посмотреть в справке, которая находится в папке doc движка. Чтобы при компиляции не возникло проблем необходимо указать расположение модулей движка в Project->Options- >Directories/Conditionals->SearchPath, а именно папки zengl/src и zengl/src/PasZLib (см. рис.1). Можно скомпилировать проект, увидеть вы должны следующее (см. рис.2).
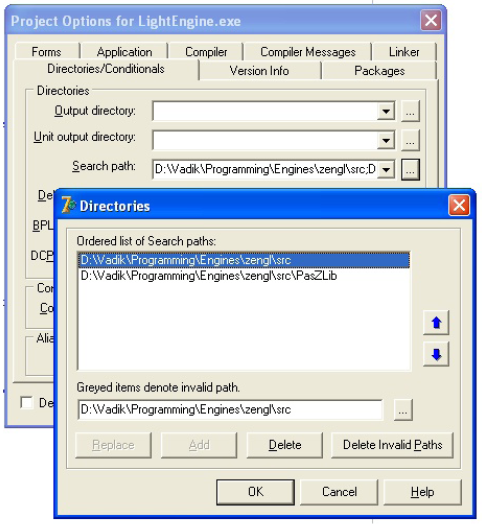
Рис. 1. Пути
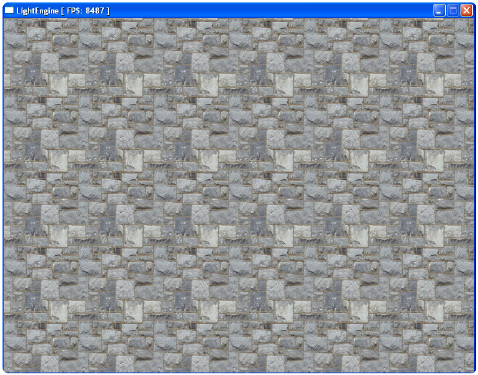
Рис. 2. Тайлинг
Немного теории
Теперь перейдем к теории вопроса. В движке мы должны реализовать два типа – источники света и объекты, которые отбрасывают тени (см. рис.3):

Рис. 3. Тень от объекта
Источник света обладает параметрами:
- положение
- радиус
- цвет
- интенсивность
Все объекты являются невыпуклыми многоугольниками. Они имеют:
- локальные координаты вершин
- мировые координаты вершин
- количество вершин
- положение
- угол поворота
Локальные координаты нужны, так как через положение и угол поворота объекта его можно разворачивать.
Для хранения данных об освещенности нам понадобятся два буфера размером в экран. Первый – альфа буфер. В него выводится круглый источник света (см. рис.4):

Рис. 4. Источник света
После этого альфа буфер рисуется во второй буфер – буфер аккумуляции. При этом используется аддитивный режим блендинга, то есть цвета смешиваются. В буфере мы получаем такую картинку (см. рис.5):

Рис. 5. Смешивание источников света
В нем светлые участки – там где свет, а темные – там где тьма. А теперь мы выводим буфер аккамуляции на экран с блендингом MULT. Получается так, что чем светлее цвет, тем он прозрачнее (см. рис.6):

Рис. 6. Рисование с блендингом MULT
Как же делаются тени от объектов? При выводе источника света в альфа буфер на него рисуется форма тени черным цветом. Получается что от круга света «отрезают» кусок (см. рис.7):

Рис. 7. Форма тени на свете
С помощью такого алгоритма получаются тени любой сложности, причем их количество, как и источников света с объектами неограниченно (см.рис.8).
Да будет свет!
Под следующий код сделаем модуль, который и будет отвечать за тени. Назовем его ZGLShadows.

Рис. 8. Сцена с большим количеством теней
Напишем тип света:
код:
type
PLightSource=^TLightSource;
TLightSource=record
position:leVect; // положение
radius:single; // радиус
color:TColorRGB; // цвет
intensivity:single; // интенсивность cвета
prev,next:PLightSource;
end;
PLightSource=^TLightSource;
TLightSource=record
position:leVect; // положение
radius:single; // радиус
color:TColorRGB; // цвет
intensivity:single; // интенсивность cвета
prev,next:PLightSource;
end;
Все данные будут храниться в “prev-next” (двухсвязных) списках (см. рис.9):
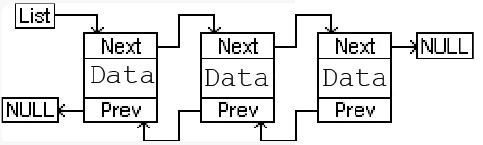
Рис. 9. Списки
Каждый элемент является звеном цепи и имеет указатели на предыдущее и следующее звено. Нам же нужно иметь первый элемент и длину цепи для управления списком:
код:
Var
// Источники света
le_Lights:PLightSource; // список
le_NumLights:integer; // количество
// Источники света
le_Lights:PLightSource; // список
le_NumLights:integer; // количество
Более подробно о такой системе хранения данных можно почитать в Интернете. Как мы видим, у нас появились новые типы данных:
код:
type
TColorRGB=record
r,g,b:single;
end;
TColorRGB=record
r,g,b:single;
end;
Данный тип нужен для хранения цвета в формате rgb, так как его использует OpenGL. ZenGL использует integer для хранения цветов (например $FFFFFF соответствует 1,1,1 в RGB), поэтому нам может понадобится процедура для перевода цвета в RGB:
код:
function IntToRGB(Color:Integer): TColorRGB;
begin
Result.r := ((Color and $FF0000) shr 16) / 255;
Result.g := ((Color and $FF00) shr 8) / 255;
Result.b := (Color and $FF) / 255;
end;
begin
Result.r := ((Color and $FF0000) shr 16) / 255;
Result.g := ((Color and $FF00) shr 8) / 255;
Result.b := (Color and $FF) / 255;
end;
Все координаты будут храниться в типе:
код:
type
leVect=record
x,y:single;
end;
leVect=record
x,y:single;
end;
Подробнее о нем будет написано позже, пока нам понадобится только формирование вектора по x и y:
код:
function le_v(x,y:single):leVect;
begin
result.x:=x;
result.y:=y;
end;
begin
result.x:=x;
result.y:=y;
end;
Перейдем к процедурам управления источниками света:
код:
Function le_CreateLightSource(p:leVect; radius,intensivity:single;
color:TColorRGB):PLightSource;
var t: PLightSource;
begin
new(t);
t.Next:= nil;
t.Prev:= nil;
t.position:=p;
t.radius:=radius;
t.intensivity:=intensivity;
t.color:=color;
t.Next:= le_Lights;
if le_Lights <> nil then le_Lights.Prev:= t;
le_Lights:= t;
Result:= le_Lights;
inc(le_NumLights);
end;
color:TColorRGB):PLightSource;
var t: PLightSource;
begin
new(t);
t.Next:= nil;
t.Prev:= nil;
t.position:=p;
t.radius:=radius;
t.intensivity:=intensivity;
t.color:=color;
t.Next:= le_Lights;
if le_Lights <> nil then le_Lights.Prev:= t;
le_Lights:= t;
Result:= le_Lights;
inc(le_NumLights);
end;
Функция создает источник света в памяти и возвращает указатель на него. Большую часть кода занимает работа со списками.
В следующей процедуре происходит рисование круга света как на рисунке 4. Он рисуется через GL_TRIANGLE_FAN. Первая точка в центре имеет цвет и интенсивность света, далее идут точки по радиусу окружности с нулевым цветом, благодаря чему мы имеем плавный переход цвета:
код:
procedure le_DrawLightSource(t:PLightSource);
var angle:single;
begin
angle:=0;
glBegin(GL_TRIANGLE_FAN);
glColor4f(t.color.r, t.color.g, t.color.b, t.intensivity);
glVertex2f(t.position.x,t.position.y);
glColor4f(0, 0, 0, 0 );
while angle<=Pi*2 do begin
glVertex2f( t.radius*cos(angle) + t.position.x,
t.radius*sin(angle) + t.position.y);
angle:=angle+((PI*2)/le_numSubdivisions);
end;
glVertex2f(t.position.x+t.radius, t.position.y);
glEnd();
end;
var angle:single;
begin
angle:=0;
glBegin(GL_TRIANGLE_FAN);
glColor4f(t.color.r, t.color.g, t.color.b, t.intensivity);
glVertex2f(t.position.x,t.position.y);
glColor4f(0, 0, 0, 0 );
while angle<=Pi*2 do begin
glVertex2f( t.radius*cos(angle) + t.position.x,
t.radius*sin(angle) + t.position.y);
angle:=angle+((PI*2)/le_numSubdivisions);
end;
glVertex2f(t.position.x+t.radius, t.position.y);
glEnd();
end;
Количество треугольников, из которого рисуется круг, задается константой:
код:
const
le_numSubdivisions = 32;
le_numSubdivisions = 32;
Следующая процедура рассчитывает и рисует тень для объектов, но о ней я напишу позже:
код:
procedure le_RenderShadowGeometry(t:PLightSource);
Далее напишем процедуру, которая освобождает память, занятую источником света:
код:
procedure le_FreeLightSource(t:PLightSource);
var DelT: PLightSource;
begin
DelT:= t;
if t.Prev <> nil then t.Prev.Next := t.Next
else le_Lights:= t.Next;
if t.Next <> nil then t.Next.Prev := t.Prev;
Dispose(DelT);
dec(le_NumLights);
t:=nil
end;
var DelT: PLightSource;
begin
DelT:= t;
if t.Prev <> nil then t.Prev.Next := t.Next
else le_Lights:= t.Next;
if t.Next <> nil then t.Next.Prev := t.Prev;
Dispose(DelT);
dec(le_NumLights);
t:=nil
end;
Следующая процедура вспомогательная, она обрабатывает каждый источник света передаваемой в нее процедурой:
код:
procedure le_EachLightSource(p:le_proc);
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do
begin
tNext:= t.Next;
p(t);
t:= tNext;
end;
end;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do
begin
tNext:= t.Next;
p(t);
t:= tNext;
end;
end;
le_proc – тип процедуры:
код:
type
le_proc=procedure(d:Pointer);
le_proc=procedure(d:Pointer);
Например, данная строчка нарисует все источники света:
код:
le_EachLightSource(@le_DrawLightSource);
Хочу заметить, что при попытке передать в le_EachLightSource процедуру очищения возникнет ошибка, связанная с памятью, поэтому для очищения всех источников света напишем отдельную процедуру:
код:
procedure le_FreeAllLightSources;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do begin
tNext:= t.Next;
le_FreeLightSource(t);
t:= tNext;
end;
end;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do begin
tNext:= t.Next;
le_FreeLightSource(t);
t:= tNext;
end;
end;
Заставим это работать
С типом света мы управились, теперь надо заставить его работать. Объявим следующие переменные:
код:
var // Движок
le_AlphaBuffer: zglPRenderTarget; // буфер для света
le_AccBuffer: zglPRenderTarget; // буфер для сложения
// изображений света
le_DarkColor: integer; // цвет тени
le_AlphaBuffer: zglPRenderTarget; // буфер для света
le_AccBuffer: zglPRenderTarget; // буфер для сложения
// изображений света
le_DarkColor: integer; // цвет тени
В этой процедуре инициализируются буферы для рендеринга. К проекту нужно также подключить модули:
- zgl_textures – создание текстуры-буфера
- zgl_render_target – управление рендерингом
- zgl_primitives_2d – очищение рендер target. Хотя можно было бы просто рисовать QUAD на OpenGL.
- zgl_fx – процедуры управления блендингом
- zgl_sprite_2d – рисование текстур
Напишем процедуру инициализации буферов:
код:
procedure le_InitLightEngine(DarkColor:Integer);
begin
le_DarkColor:=DarkColor;
// инициализация буферов
le_AlphaBuffer:=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
le_AccBuffer :=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
end;
begin
le_DarkColor:=DarkColor;
// инициализация буферов
le_AlphaBuffer:=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
le_AccBuffer :=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
end;
le_DarkColor – переменная, которая отвечает за освещенность. К ее смыслу и принципу работы я еще вернусь. Обобщающая процедура полной обработки света:
код:
procedure le_RenderLight(t:PLightSource);
begin
rtarget_Set( le_AlphaBuffer ); // начинаем рендер в буфер
pr2d_Rect(0,0,800,600, 0,255,PR2D_FILL); // очищаем черным
// цветом
le_DrawLightSource(t); // отрисовка источника света
rtarget_Set( nil );
rtarget_Set( le_AccBuffer ); // отрисовка полученного
// изобр-я в буфер аккамуляции
fx_SetBlendMode(FX_BLEND_ADD); // при отрисовке используем
// блендинг для сложения
// интенсивностей источ-в света
ssprite2d_Draw( le_AlphaBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
rtarget_Set( nil );
end;
begin
rtarget_Set( le_AlphaBuffer ); // начинаем рендер в буфер
pr2d_Rect(0,0,800,600, 0,255,PR2D_FILL); // очищаем черным
// цветом
le_DrawLightSource(t); // отрисовка источника света
rtarget_Set( nil );
rtarget_Set( le_AccBuffer ); // отрисовка полученного
// изобр-я в буфер аккамуляции
fx_SetBlendMode(FX_BLEND_ADD); // при отрисовке используем
// блендинг для сложения
// интенсивностей источ-в света
ssprite2d_Draw( le_AlphaBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
rtarget_Set( nil );
end;
И завершающая процедура – вывод буфера с использованием MULT блендинга:
код:
procedure le_FinishRender;
begin
// выводим полученные тени и свет на экран с использованием
// блендинга mult (чем светлее изображение тем прозрачней)
fx_SetBlendMode(FX_BLEND_MULT);
ssprite2d_Draw( le_AccBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
// очищаем буфер для следующего кадра (цветом le_DarkColor!)
rtarget_Set( le_AccBuffer );
pr2d_Rect(0,0,800,600, le_DarkColor,255,PR2D_FILL);
rtarget_Set( nil );
end;
begin
// выводим полученные тени и свет на экран с использованием
// блендинга mult (чем светлее изображение тем прозрачней)
fx_SetBlendMode(FX_BLEND_MULT);
ssprite2d_Draw( le_AccBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
// очищаем буфер для следующего кадра (цветом le_DarkColor!)
rtarget_Set( le_AccBuffer );
pr2d_Rect(0,0,800,600, le_DarkColor,255,PR2D_FILL);
rtarget_Set( nil );
end;
Хочу заметить, что очищение le_AccBuffer проводится цветом le_DarkColor. Следовательно, чем светлее этот цвет тем прозрачнее тени (см. рис.10). На изображении видно, что справа фон просвечивается даже там, где света нет, так как le_DarkColor не черный, а серый ($1f1f1f).

Рис. 10. Различный DarkColor
Все, система света написана. Правда, пока без теней от объектов. Теперь проверим ее в действии.
Добавим переменную под управляемый свет:
код:
var
UserLight:PLightSource; // указатель на управляемый свет
UserLight:PLightSource; // указатель на управляемый свет
Создадим его, и еще 4 света в Init:
код:
le_InitLightEngine(0); // инициализируем световой движок
// загружаем источники света
le_CreateLightSource
(le_v(520,550),400,0.3,IntToRGB($FF00FF));
le_CreateLightSource
(le_v(470,50),250,0.5,IntToRGB($FF0000));
le_CreateLightSource
(le_v(200,300),270,1,IntToRGB($00FF00));
le_CreateLightSource
(le_v(640,270),300,0.8,IntToRGB($FFFFFF));
UserLight:=le_CreateLightSource(le_v(0 ,
0),100,0.8,IntToRGB($FFFFFF));
// загружаем источники света
le_CreateLightSource
(le_v(520,550),400,0.3,IntToRGB($FF00FF));
le_CreateLightSource
(le_v(470,50),250,0.5,IntToRGB($FF0000));
le_CreateLightSource
(le_v(200,300),270,1,IntToRGB($00FF00));
le_CreateLightSource
(le_v(640,270),300,0.8,IntToRGB($FFFFFF));
UserLight:=le_CreateLightSource(le_v(0 ,
0),100,0.8,IntToRGB($FFFFFF));
Теперь в Draw напишем рисование теней:
код:
// обработка всех источников света
le_EachLightSource(@le_RenderLight);
// отрисовка теней
le_FinishRender;
le_EachLightSource(@le_RenderLight);
// отрисовка теней
le_FinishRender;
В Update привяжем UserLight к мышке, сделаем изменение размера при нажатии на кнопки мыши и цвета при нажатии на колесико:
код:
if mouse_Down( M_BLEFT ) then
UserLight.radius:=UserLight.radius+3;
if mouse_Down( M_BRIGHT ) then
if UserLight.radius>0 then
UserLight.radius:=UserLight.radius-3;
if mouse_Click( M_BMIDLE ) then begin
UserLight.color.r:=random(100)/100;
UserLight.color.g:=random(100)/100;
UserLight.color.b:=random(100)/100;
end;
UserLight.radius:=UserLight.radius+3;
if mouse_Down( M_BRIGHT ) then
if UserLight.radius>0 then
UserLight.radius:=UserLight.radius-3;
if mouse_Click( M_BMIDLE ) then begin
UserLight.color.r:=random(100)/100;
UserLight.color.g:=random(100)/100;
UserLight.color.b:=random(100)/100;
end;
И наконец, в Quit очищаем источники света:
код:
le_EachLightSource(@le_FreeLightSource);
Запускаем, любуемся результатом (см. рис.11).

Рис. 11. Результат
Заключение
В следующей части статьи я рассмотрю создание теней от объектов, а также оптимизирую код, чтобы добиться большей производительности. Весь исходный код проекта приложен к журналу «ПРОграммист. Пятый выпуск».
Продолжение следует…
Ресурсы
- Страница разработчика ZenGL http://andrukun.inf.ua/zengl.html
- Михалкович С.С. Основы программирования.
Второй семестр 08-09, 2 часть
Обсудить на форуме – Делаем динамические тени на OPENGL. Часть 1
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
