

Последние записи
- Автоматическое уничтожение объектов
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
25th
Авг
 Применение паскаля в геометрии
Применение паскаля в геометрии
Часть 0. Intro.
Еще в самом
детстве, когда я начал изучать Паскаль, я запомнил цитату из детской книжки
примерно такого содержания: «Паскаль — универсальный язык программирования
подходящий для решения самых различных задач». Когда человек впервые
сталкивается с программированием на Паскале, одна из первых его мыслей после
прочтения таких строк будет «А в чем же заключается его универсальность?». На
самом деле я когда более углубленно изучил паскаль решил, что это определение
абсолютно правдивое. И действительно Паскаль можно применить для решения
абсолютно любых задач. В этой статье я расскажу о там как можно использовать
Паскаль для решения геометрических задач. Для примера возьмем задание которое
звучит так: «По координатам точки и вершин треугольника определить, принадлежит
ли точка этому треугольнику».
(читать всё…)
24th
Как в WebBrowser выбрать из списка и нажать на кнопку?
Posted by Chas under Пост-обзор
Нажатие на кнопку:
код:
procedure PSpisokClick;
var HtmlDocument : IHtmlDocument2;
i : integer;
HtmlCollection : IHtmlElementCollection;
HtmlElement : IHtmlElement;
spisok : string;
begin
HtmlDocument := BrowserMain.Document as IHtmlDocument2;
HtmlCollection := HtmlDocument.All;
for i := 0 to HtmlCollection.length – 1 do
begin
if stop = 1 then Exit;
HtmlElement := HtmlCollection.Item(i, 1) as IHtmlElement;
spisok := HtmlElement.InnerText;
Trim(spisok);
if spisok = ‘список’ then
begin
HtmlElement.click;
Exit;
end;
end;
end;
var HtmlDocument : IHtmlDocument2;
i : integer;
HtmlCollection : IHtmlElementCollection;
HtmlElement : IHtmlElement;
spisok : string;
begin
HtmlDocument := BrowserMain.Document as IHtmlDocument2;
HtmlCollection := HtmlDocument.All;
for i := 0 to HtmlCollection.length – 1 do
begin
if stop = 1 then Exit;
HtmlElement := HtmlCollection.Item(i, 1) as IHtmlElement;
spisok := HtmlElement.InnerText;
Trim(spisok);
if spisok = ‘список’ then
begin
HtmlElement.click;
Exit;
end;
end;
end;
выбор из открывающегося списка:
код:
procedure SetFieldValue(theForm: IHTMLFormElement;
const fieldName, newValue: string; const instance: integer);
var
field: IHTMLElement;
inputField: IHTMLInputElement;
selectField: IHTMLSelectElement;
textField: IHTMLTextAreaElement;
begin
field := theForm.Item(fieldName,instance) as IHTMLElement;
if Assigned(field) then
begin
if field.tagName = ‘INPUT’ then
begin
inputField := field as IHTMLInputElement;
if (inputField.type_ ‘radio’) and (inputField.type_ ‘checkbox’)
then inputField.value := newValue
else inputField.checked := (newValue = ‘checked’);
end
else if field.tagName = ‘SELECT’ then
begin
selectField := field as IHTMLSelectElement;
selectField.value := newValue;
end
else if field.tagName = ‘TEXTAREA’ then
begin
textField := field as IHTMLTextAreaElement;
textField.value := newValue;
end;
end;
end;
const fieldName, newValue: string; const instance: integer);
var
field: IHTMLElement;
inputField: IHTMLInputElement;
selectField: IHTMLSelectElement;
textField: IHTMLTextAreaElement;
begin
field := theForm.Item(fieldName,instance) as IHTMLElement;
if Assigned(field) then
begin
if field.tagName = ‘INPUT’ then
begin
inputField := field as IHTMLInputElement;
if (inputField.type_ ‘radio’) and (inputField.type_ ‘checkbox’)
then inputField.value := newValue
else inputField.checked := (newValue = ‘checked’);
end
else if field.tagName = ‘SELECT’ then
begin
selectField := field as IHTMLSelectElement;
selectField.value := newValue;
end
else if field.tagName = ‘TEXTAREA’ then
begin
textField := field as IHTMLTextAreaElement;
textField.value := newValue;
end;
end;
end;
вызов процедуры:
код:
theForm := GetFormByNumber(BrowserMain.Documen t as IHTMLDocument2,0);
SetFieldValue(theForm,’type’,переменная);
SetFieldValue(theForm,’type’,переменная);
23rd
Авг
Получить идентификатор процесса и узнать полуный путь до файла этого процесса. c/c++
Пишу небольшую программу, мне нужно чтобы она искала заданный мною выполняемый процесс. Подскажите какая это функция может сделать, быть может это win api функция?
Sazary:
код:
#include <windows.h>
#include <stdio.h>
#include <TlHelp32.h>
#include <conio.h>
#include <string.h>
#include <psapi.h>
using namespace std;
#include <stdio.h>
#include <TlHelp32.h>
#include <conio.h>
#include <string.h>
#include <psapi.h>
using namespace std;
int main()
{
HANDLE h,hp;
PROCESSENTRY32 pe;
int id;
bool bl,flag=false;
char name[256],str[256];
char path[MAX_PATH];
DWORD dw;
HMODULE hmod;
scanf(”%s”,name);
h = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS|TH32CS_SNAPMODULE,0);
for(bl = Process32First(h, &pe); bl; bl = Process32Next(h, &pe))
{
strcpy(str,pe.szExeFile);
if(strcmp(str,name)==0)
{
printf(”Process found: %s\n”,str);
hp = OpenProcess(PROCESS_QUERY_INFORMATION | PROCESS_VM_READ,false,pe.th32ProcessID);
EnumProcessModules(hp, &hmod,sizeof(hmod),&dw); // получаем первый модуль, связанный с процессом, то есть сам exe-файл
GetModuleFileNameEx(hp, hmod, path, MAX_PATH); // получаем путь к модулю
printf(”path: %s\n”,path);
CloseHandle(hp);
CloseHandle(h);
flag = true;
break;
}
}
CloseHandle(h);
if(!flag) printf(”Process not found”);
getch();
return 0;
}
Нужно прилинковать модуль psapi.
23rd
Как узнать количество строк в memo?
У новичков может возникнуть такой вопрос.
код:
a := Memo1.Lines.Count;// кол-во строк Memo1
Нумерация строк начинается с нуля.
23rd
Определить нажата правая клавиша мыши?
Событие OnMouseDown у формы, проверяя таким макаром:
код:
if Button=mbRight then Form2.ShowModal;
23rd
Как развернуть flash-приложение во весь экран?
Kotofff:
Компонент которым показываешь (проигрываешь) флеш-ролик в программе выравнивай на всю форму, а с самой формой можно так :
код:
procedure TForm1.FormCreate(Sender: TObject);
var
HTaskbar: HWND;
OldVal: LongInt;
begin
try
HTaskBar := FindWindow(’Shell_TrayWnd’, nil);
SystemParametersInfo(97, Word(True), @OldVal, 0);
EnableWindow(HTaskBar, False);
ShowWindow(HTaskbar, SW_HIDE);
finally
with Form1 do
begin
BorderStyle := bsNone;
FormStyle := fsStayOnTop;
Left := 0;
Top := 0;
Height := Screen.Height;
Width := Screen.Width;
end;
end
end;
var
HTaskbar: HWND;
OldVal: LongInt;
begin
try
HTaskBar := FindWindow(’Shell_TrayWnd’, nil);
SystemParametersInfo(97, Word(True), @OldVal, 0);
EnableWindow(HTaskBar, False);
ShowWindow(HTaskbar, SW_HIDE);
finally
with Form1 do
begin
BorderStyle := bsNone;
FormStyle := fsStayOnTop;
Left := 0;
Top := 0;
Height := Screen.Height;
Width := Screen.Width;
end;
end
end;
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);
var
HTaskbar: HWND;
OldVal: LongInt;
begin
HTaskBar := FindWindow(’Shell_TrayWnd’, nil);
SystemParametersInfo(97, Word(False), @OldVal, 0);
EnableWindow(HTaskBar, True);
ShowWindow(HTaskbar, SW_SHOW);
end;
22nd
Авг
Беспроводная сеть масштаба микрорайона. Часть 1

Общаясь с друзьями и знакомыми, работающими в области ИТ, не раз приходилось слышать заявление, что Wi-Fi подходит только для сетей масштаба квартиры или небольшого офиса. В качестве аргументов приводились малая дальность, зависимость от погодных условий, ненадежность оборудования. Примерно такое же мнение бытует о том, что для провайдерских сетей не подходит платформа Windows. Аргументы: высокая ресурсоемкость, ненадежность и вообще неспособность работать в качестве системы биллинга.
Александр
by WildHunter http://airnet.sytes.net

А так ли это? Этот вопрос нас всерьез заинтересовал и подтолкнул к попытке создания беспроводной сети как раз на базе Wi-Fi и Windows. Оговорюсь, что некоторый опыт создания беспроводных сетей у нас уже был, правда, немного другого назначения – корпоративных.
Начали мы естественно с постановки самим себе техзадания:
- Сетевая технология WiFi IEEE 802.11b/g, возможно в будущем 802.11a и 802.11n википедия
- Серверы на базе Windows Server. В качестве основной ОС был выбран Windows Server 2003, как достаточно надежная и неприхотливая система, при этом обеспечивающая нужный функционал википедия
- Максимальная простота развертывания, эксплуатации и администрирования сети.
- Минимальные затраты, поскольку проект некоммерческий и финансирования со стороны не будет, придется обходиться собственными силами и средствами.
- Надежность, производительность и пропускная способность, достаточные для обслуживания городского микрорайона.
Выбор оборудования
Основательно изучив рынок предложений недорогого Wi-Fi оборудования, мы остановили свой выбор на нескольких моделях точек доступа (ТД) от D-Link: DWL-2100AP, DAP-1150 и DAP-1160 http://www.d-link.ru. Основными причинами выбора именно этих точек стали их приемлемая цена, накопленный в России и на Украине большой опыт их эксплуатации, а также наличие большого количества альтернативных прошивок, как от различных производителей оборудования, так и open-source.
Для тестирования было закуплено несколько экземпляров указанных выше точек доступа, а также различных антенн к ним. Началось тестирование в различных режимах, на разных расстояниях, с различными антеннами и прошивками. От «родных» прошивок мы отказались практически сразу, поскольку они рассчитаны как раз на применение в домашних или условиях небольшого офиса, не позволяют менять многие важные параметры (ACK timeout, мощность передатчика, чувствительность приемника и т.д.), а также практически не обеспечивают возможности мониторинга беспроводных соединений.
Точки DWL-2100AP оказались хороши для построения мостов на большие расстояния (до 50 км), но капризными в эксплуатации и несовместимыми со многими другими моделями Wi-Fi устройств. Также у них обнаружилась неприятная проблема: довольно часто при большой нагрузке «слетали» прошивки, а их восстановление оказалось довольно непростой процедурой. В итоге DWL-2100AP была признана нами годной к применению только для организации мостов. Хотя вполне возможно, что нам просто достались неудачные экземпляры.
DAP-1150 – очень простое и надежное устройство, тем не менее отвечающее всем основным критериям хотспота. А с немного доработанной прошивкой от Conceptronic http://www.conceptronic.net эта точка стала практически полностью соответствовать нашим требованиям.

Рис. 1. Точка доступа DAP-1150
Основные характеристики DAP-1150 с прошивкой Conceptronic:
- Стандарты: 802.11b/g, 802.3/802.3u 10Base- T/100Base-TX Ethernet, ANSI/IEEE 802.3 NWay auto-negotiation.
- Интерфейсы: 802.11b/g беспроводная LAN, 1 порт 10/100Base-TX Ethernet LAN
- Диапазон частот: 2.4 – 2.4835 ГГц
- Количество каналов: 13 (ETSI)
- Схемы модуляции:
802.11b: DQPSK, DBPSK, DSSS, CCK
802.11g: BPSK, QPSK, 16QAM, 64QAM, OFDM - Режимы работы: Station – Ad Hoc, Station – Infrastructure, AP, AP Bridge – Point to Point, AP Bridge – Point to MultiPoint, AP Bridge – WDS, Universal Repeater.
- Скорость передачи данных:
802.11g: 6, 9, 12, 18, 24, 36, 48, 54 Мбит/с
802.11b: 1, 2, 5.5, 11 Мбит/с - Чувствительность приемника: до -100dBm
- Выходная мощность передатчика: 20dBm
- Безопасность: WEP, WPA/WPA2, фильтрация МАС-адресов, SSID broadcast disable.
- Дополнительные возможности: IAPP, встроенный Radius-сервер.
DAP-1160 с прошивкой AProuter http://aprouter.com.br превратилась в довольно серьезное устройство с широким функционалом, включающим в себя массу полезных возможностей, от контроля качества WDS- соединений википедия до многофункционального шейпера википедия.

Рис. 2. Точка доступа DAP-1160
Основные характеристики DAP-1160 с прошивкой AProuter:
- Стандарты: 802.11b/g, 802.3/802.3u 10Base- T/100Base-TX Ethernet, ANSI/IEEE 802.3 NWay auto-negotiation.
- Интерфейсы: 802.11b/g беспроводная LAN, 2 порта 10/100Base-TX Ethernet LAN
- Диапазон частот: 2.4 – 2.4835 ГГц
- Количество каналов: 13 (ETSI)
- Схемы модуляции:
802.11b: DQPSK, DBPSK, DSSS, CCK
802.11g: BPSK, QPSK, 16QAM, 64QAM, OFDM - Режимы работы роутера: WISP Client, Bridge, Gateway, Router (WAN Ethernet), Router (WAN Wireless).
- Режимы работы Wireless: Wireless Client, AP, WDS+AP, WDS-Bridge.
- Скорость передачи данных:
802.11g: 6, 9, 12, 18, 24, 36, 48, 54 Мбит/с
802.11b: 1, 2, 5.5, 11 Мбит/с - Чувствительность приемника: до -100dBm
- Выходная мощность передатчика: 20dBm
- Безопасность: WEP, WPA/WPA2, фильтрация МАС-адресов, SSID broadcast disable.
- Дополнительные возможности: IP Aliases, IAPP, Block Relay, Firewall, Traffic Control (шейпер), DDNS, Watchdog.
Антенны ANT24-0700C производства D-Link были выбраны по наилучшему показателю цена/качество в своем классе и из-за небольших размеров:

Рис. 3. Антенна ANT24-0700C
Основные характеристики ANT24-0700C:
- Диапазон частот: 2,4-2,5ГГц
- Сопротивление: 50 Ом
- VSWR: 1.92 (макс.)
- Максимальное усиление: 7dBi
- Допустимая мощность: 1 Вт
- Диаграмма направленности в вертикальной плоскости (Вектор Е): 24 градуса.
- Диаграмма направленности в горизонтальной плоскости (Вектор Н): 360 градусов.
- Разъем: Reverse SMA «мама» (встроенный в антенну), переходник с RP-SMA на RP-TNC (внешний).
- Материал корпуса: ABS, ABS+PC
- Рабочая температура: От -20 до 65 градусов.
Построение сети
После завершения тестирования мы приступили к созданию собственно сети. В качестве базовой была выбрана классическая топология «звезда», центральной точкой которой стала DAP-1160 в режиме Bridge WDS, а «лучами» DAP-1150 в режиме WDS + AP. Использование технологии WDS позволяет получить на каждой точке доступа скорость передачи данных на уровне 1.2-1.4 Мбайт/с, максимальная скорость у клиентов составляет порядка 550-600 кБайт/с. Реальная скорость передачи данных зависит от типа клиентского оборудования и качества беспроводного соединения клиент-ТД, а также от количества клиентов и общей загрузки сети.

Рис. 4. Общая схема сегмента сети
Покрытие каждой ТД составляет (в радиусе, значения указаны при наличии прямой видимости или незначительных препятствий, например деревьев):
- Мобильные устройства (смартфоны, КПК, PSP и т.п.) – до 200м
- Ноутбуки, нетбуки, USB-устройства со встроенными антеннами – до 300м
- Ноутбуки, USB-устройства с внешними (или внутренними дипольными) антеннами – до 1500м
- ТД в режиме клиента с направленными антеннами – до 10км
Установка точек доступа
Естественно, что мы старались устанавливать ТД как можно выше, но не всегда это удается. Кроме того, при установке ТД на самую высокую мачту в округе, есть риск получить прямое попадание в нее молнии, от которого не спасет никакая грозозащита. Поэтому второй фактор, который мы старались учитывать – наличие поблизости громоотводов или более высоких мачт.
Все наши хотспоты стоят на мачтах высотой 4-6 метров, которые расположены на крышах зданий высотой в 5-6 этажей. Рядом есть небольшой массив из 9-этажных зданий, но нам не удалось договориться с местным ОСМД*.
Питание на точки подается по витой паре, обычно из квартир наших клиентов (чтобы избежать бюрократии с ЖЕКами и ОСМД), по этому же кабелю клиенты входят в сеть. Взаимовыгодное сотрудничество: мы получаем место для установки и запитки точки, а клиенты получают VIP-доступ к сети ![]()
* Комментарий автора. Объединение совладельцев многоквартирного дома (ОСМД). Юридическое лицо, созданное владельцами для содействия использованию их собственного имущества и управления, содержания и использования неделимого и общего имущества.
Качество
На следующем скриншоте показаны характеристики соединения с ТД на расстоянии ~1000 метров при прямой видимости (см. рисунок 5):
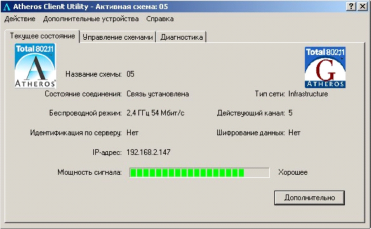
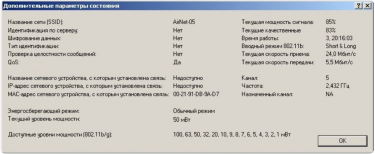
Рис. 5. Качественные характеристики соединения в Atheros Client Utility
ТД: DAP-1150, мощность 20dBm, антенна штыревая 7dBi. Клиент: ноутбук Asus X51RL, WiFi-плата Atheros AR2425, антенна встроенная дипольная 4dBi.
Линк стабильный, текущая скорость линка «гуляет» в пределах 18-36 Мбит/с, это нормально. Скорость загрузки файла с сервера сети держится в пределах 400-500 Кбайт/с. Может показаться, что при средней скорости линка в 24 мегабита это немного, но нужно учитывать особенности технологии Wi-Fi, в которой мегабиты совсем другие, чем в кабельных сетях. Кроме того, режим WDS также вносит свои коррективы, и не в большую сторону. Если вы ожидаете от Wi-Fi волоконно-оптических скоростей, то вам действительно лучше посмотреть в сторону оптики. А Wi-Fi это простая, недорогая, удобная и достаточно качественная связь для всех.
Как это ни странно, но на качество связи почти не влияют погодные условия. Если линк стабилен в хорошую погоду, то он таким и останется в дождь, снег или туман. Возможно, немного снизится скорость, но связь будет. Наш опыт практической эксплуатации показывает следующие результаты: в дождь (даже сильный) или снег уровень сигнала между ТД снижается в среднем всего на 1-4 dBm, туман никакого заметного влияния вообще не оказывает. Замечу, что все точки стоят на примерно одинаковом расстоянии от центральной, которое составляет 800-1200 метров. Для Wi-Fi при прямой видимости это расстояние несерьезное. Так что мнение о влиянии погоды на Wi-Fi сильно преувеличено. Влияние погодных условий становится заметным только на больших расстояниях, от 5 км и более. А вот что действительно отрицательно влияет**: преграды, помехи в эфире, избыточная мощность радиоустройств. Данные факторы обсуждались и не раз, например на http://www.lan23.ru, поэтому подробно мы их здесь рассматривать не будем.
** Комментарий автора. В последнее время технология Wi-Fi в наших краях сделала явный рывок, но непонятно, вперед, назад или «налево». В эфире полный бардак, огромное количество различных устройств, большинство из которых настроены как попало или вообще не настроены. Все это снижает качество связи, а если так и будет продолжаться дальше – связь вообще станет невозможной… Вот какая картина открывается с некоторых наших хотспотов:
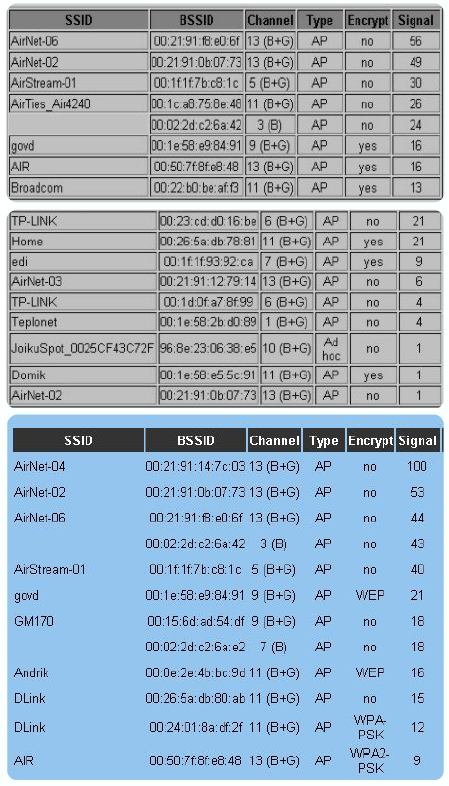
Каждая ТД нормально выдерживает до 20 одновременно работающих клиентов, если нет «тяжелого» трафика, в первую очередь P2P. Если есть, то даже один клиент в состоянии через минуту сделать для всех остальных вход в сеть недоступным, а минуты через 3-5 отправить точку на перезагрузку. ТД почти не критичны к скорости или общему объему трафика, но очень критичны к количеству подключений. Это не значит, что использовать «тяжелый» трафик невозможно. Вполне возможно, если предпринять определенные меры для защиты сети от перегрузок. К таким методам защиты, например, относятся ограничение количества подключений на хост, работа по VPN, а также использование адаптивных шейперов и QoS. Но об этом поговорим в другой раз, так как это более относится к серверным технологиям, а не к Wi- Fi.
Несколько слов о клиентских устройствах
Сейчас на рынке представлена масса самых разнообразных устройств 802.11b/g/n. Из них довольно трудно, но возможно выбрать оптимальный*** вариант. Некоторые устройства, например USB-брелки со встроенной антенной, рассчитаны на работу только внутри помещения и обладают очень ограниченным радиусом действия. Даже одна стена или дерево под окном, для них уже неодолимая преграда.
Другой класс – это устройства с внешними антеннами. Даже со штатными антеннами они показывают неплохую дальность при прямой видимости, а при установке хорошей антенны вполне могут работать на расстояниях, измеряемых километрами. Поэтому при выборе Wi-Fi устройства стоит обратить внимание не только на дизайн, размеры и цену, но в первую очередь – на технические характеристики.
При покупке ноутбука, КПК или любого другого устройства, оснащенного встроенным Wi-Fi, также обязательно интересуйтесь характеристиками Wi- Fi платы, типом и характеристиками встроенной антенны. Зачастую, встроенные платы подходят только для связи внутри комнаты или на расстояниях до 100 метров на открытой местности. Хотя есть и большое количество устройств, оснащенных качественным Wi-Fi и вполне способных поддерживать связь на приличных расстояниях.
Основные характеристики Wi-Fi устройств
- Стандарты, поддерживаемые устройством. От этого зависит универсальность и максимальная скорость передачи данных. В настоящее время в Европе поддерживаются следующие стандарты:
- 802.11b (максимальная скорость 11 Мбит/с)
- 802.11g (максимальная скорость 54 Мбит/с)
- 802.11n (максимальная скорость 150/300 Мбит/с)
- Мощность передатчика и чувствительность приемника. Не стоит чрезмерно увлекаться мощностью, слишком мощный сигнал в городских условиях скорее вреден, так как вызывает многократные отражения и наложения, а также создает массу помех. Да и для здоровья он не очень полезен. На наш взгляд оптимальные значения составляют до 100 мВт (20 dBm) мощности и -95 dBm чувствительности.
- Возможность подключения внешней антенны и характеристики штатной. «Главная часть любого радиоустройства – антенна», это вам скажет любой специалист по любому виду радиосвязи. К Wi-Fi это тоже относится в полной мере. Для нормальной работы (приличной дальности и скорости) любого Wi-Fi-устройства необходима антенна с коэффициентом усиления не менее 4dBi.
- Функционал устройства. К этому относится все, что устройство умеет делать и насколько удобно его использовать. По этому критерию выбор огромный, от самых простых до сложнейших устройств, которые «умнее» вашего компьютера. Главное – достаточно четко представлять, чего вы хотите и сколько вы согласны за это заплатить.
*** Комментарий редакции. Многие задаются вопросом: «Как увеличить дальность связи?». Перво-наперво, при выборе WLAN-аппарата, обратите внимание на то, чтобы выходная мощность была как можно ближе к разрешенной 20 dB. Следующим решающим фактором является чувствительность. У лучших современых аппаратов она находится на уровне -97 dB. Чем выше чувствительность к слабым сигналам, тем выше дальность. Но это палка о двух концах, так как мы не учитываем при этом помеховую обстановку вокруг.
Как влияют эти величины на дальность связи? К примеру, аппарат с мощностью в 20 dB сможет обеспечить в два раза большую дальность приема по сравнению с 14 dB, т.е. разница в 6 dB дает двойной выигрыш. Если к этому прибавить, что аппарат с чувствительностью -97 dB, позволяет получить выигрыш в 4 раза по сравнению с аппаратом, у которого чувствительность равна -76 dB, то общий выигрыш будет 8-ми кратным.
Заключение
Это основные характеристики, но существует еще масса различных тонкостей, специфических моментов и технических особенностей. Рассказать здесь обо всех нереально, поэтому выбор оборудования – совсем непростое дело, в котором не помешает консультация специалиста. Если вы, конечно, сами не являетесь таковым ![]()
Продолжение следует…
Ресурсы
- Сетевая аутентификация на практике http://www.citforum.ru/nets/articles/authentication
- Крупнейший и самый активный сайт рунета по Wi-Fi http://www.lan23.ru/index.html
- Антенны, много антен… хороших и разных http://radiowolna.narod.ru
Статья из пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Беспроводная сеть масштаба микрорайона. Часть 1
21st
Авг
Полупрозрачность в Delphi
И так, как сделать окошко в дельфи прозрачным с красивыми тенями и другой мутью.
Перво наперво, качаем gdiplus.dll (если есть желание) с MS Official Site
Потом смотрим мои (DIB) и не мои (GdiPlus) модули в аттаче.
И так… Подготовим плацдарм для нашего окошка
код:
implementation
const
WndClassName = ‘Trulyalya’;
var
WndClass: TWndClass = (
style: CS_DBLCLKS;
cbClsExtra: 0;
cbWndExtra: 0;
hbrBackground: 0;
lpszMenuName: NIL;
lpszClassName: WndClassName;
);
…
initialization
WndClass.lpfnWndProc := @DefWindowProc; // I hope…
WndClass.hInstance := HInstance;
WndClass.hIcon := LoadIcon(HInstance, ‘MAINICON’);
WndClass.hCursor := LoadCursor(0, IDC_ARROW);
Windows.RegisterClass(WndClass);
finalization
Windows.UnregisterClass(WndClassName, HInstance);
И так у нас есть зарегиный класс, вот ведь счастье ну мы не собираемся на этом останавливаться и пойдем до конца! Теперь давайте создадим окошко
Код:
hWnd := CreateWindowEx(WS_EX_TOOLWINDOW or WS_EX_LAYERED,
WndClass.lpszClassName, NIL, WS_POPUP or WS_VISIBLE, 0, 0, 0, 0, 0, 0, HInstance, NIL);
Думаю то что здесь, понять не составит труда. Теперь стоит понять, что у нас есть окошко со стилем WS_EX_LAYERED и это дает нам по сути установить и отобразить любое 32х битное изображение разумеется в формате ARGB никакие PNG и т.п. на прямую не ставятся. Как же это сделать?
Код:
var
Context: GpGraphics;
Tmp: TDIB;
Image: TDIB;
Rect: TRect;
begin
// Rect := GetWindowRect(); / GetClientRect(); не помню как точно, сами разберетесь
Context: GpGraphics;
Tmp: TDIB;
Image: TDIB;
Rect: TRect;
begin
// Rect := GetWindowRect(); / GetClientRect(); не помню как точно, сами разберетесь
Tmp := TDIB.Create(Rect.right – Rect.left, Rect.bottom – Rect.top); // создаем битмап по размеру окна
Image := TDIB.Create(’my_image.png’); // загрузим какое то изображение
GdipCreateFromHDC(Tmp.DC, Context); // создадим контекст GDI+ c Tmp
GdipSetSmoothingMode(Context, SmoothingModeAntiAlias); // antialias включим
GdipSetCompositingMode(Context, CompositingModeSourceCopy); // рисование с перекрытием
GdipSetInterpolationMode(Context, InterpolationModeHighQualityBicubic); // качественно масштабировать изображения
GdipDrawImageRectRect(Context, Image.Bitmap,
0, 0, Tmp.Width, Tmp.Height, // покрываем все окно
0, 0, Image.Width, Image.Height, // берем все изображение
UnitPixel, NIL, NIL, NIL);
GdipDeleteGraphics(Context);
Image.Free();
И так, мы узнали размер окна, создали битпам для окна, загрузили картинку, связали GDI+ с Tmp и нарисовали с помощью GDI+ нашу картинку, потом все освободили. Теперь у нас есть Tmp на с отрисованной картинкой. Осталось дело за малым, отобразить на окне.
Код:
var
BlendFunc: TBlendFunction;
ZPoint: TPoint;
LeftTop: TPoint;
Size: TSize;
Rect: TRect;
begin
with BlendFunc do
begin
BlendOp := AC_SRC_OVER;
BlendFlags := 0;
AlphaFormat := AC_SRC_ALPHA;
SourceConstantAlpha := 255; // не желательно менять это, да станет прозрачней, но тормаза начнутся, лучше перерисовать сам битмап в более прозрачный.
end;
BlendFunc: TBlendFunction;
ZPoint: TPoint;
LeftTop: TPoint;
Size: TSize;
Rect: TRect;
begin
with BlendFunc do
begin
BlendOp := AC_SRC_OVER;
BlendFlags := 0;
AlphaFormat := AC_SRC_ALPHA;
SourceConstantAlpha := 255; // не желательно менять это, да станет прозрачней, но тормаза начнутся, лучше перерисовать сам битмап в более прозрачный.
end;
// Rect := GetWindowRect(); / GetClientRect(); не помню как точно, сами разберетесь
ZPoint := Point(0, 0);
LeftTop := Point(Rect.left, Rect.top);
Size.cx := Rect.right – Rect.left;
Size.cy := Rect.bottom – Rect.top;
UpdateLayeredWindow(hWnd, 0, @LeftTop, @Size, Tmp.DC, @ZPoint, 0, @BlendFunc, ULW_ALPHA);
Разумеется, не забудьте сделать это Tmp.Free();
Опять такие, это мануалчик, проверять не могу сейчас, да и думаю тут суть ясна, садитесь и пробуйте.
DIB.rar
20th
Авг
Основы неврологии
В последнее время появилось много публикаций на тему нейронных сетей, однако большинство из них научного характера, предназначенные, как правило, для специалистов, пресыщены формулами и абстракциями, не дают четкого представления о предмете. В этой статье мы попытаемся понять основные принципы работы и устройство нейронной сети. Статья, дающая вводные представления о нейронных сетях.
ОСНОВЫ НЕВРОЛОГИИ
by Utkin www.programmersforum.ru
«Настоящий программист должен:
Пройти все уровни Тетриса, пользоваться только своим бубном и написать нейронную сеть»
/ Махабхарата, эпос народов Индии
Нейронные сети – это математические модели биологических нейронных сетей, выраженные как программным, так и аппаратным способами. Поэтому, сначала рассмотрим единицы, из которых состоит биологическая нейронная сеть – нейроны. Нейроны – это специальные биологические клетки, объединенные в нервную систему организма. Это нужно для осуществления нервной деятельности, а именно принятие информации об окружающем мире (и внутреннем состоянии организма), выработка решений и управление исполнительными органами. Нейроны бывают нескольких видов, но мы рассмотрим только один, который для простоты восприятия классифицируем как классический вид нейронов, т.е. тех, что в основном используются в компьютерных моделях. Итак, нейрон представляет собой клетку, имеющую несколько отростков, один из которых является выводом нейрона, а остальные являются его входами. Вывод нейрона называется аксоном, входы – дендритами, а точка соединения аксонов и дендритов называется синапс. Нейроны по своей сути схожи с микропроцессорами (или ядрами процессора) и фактически занимаются обработкой информации, поступающей на их дендриты и выдающие результат на аксон. Практически нейроны работают с электрическими импульсами (только на основе ионов – прямая передача электронов в жидких системах не очень удачная вещь, приводящая обычно к разрушению жидкости либо емкости, в которой данная жидкость находится). Ничего не напоминает? Иными словами, нервная система подавляющего большинства организмов – есть огромная электрическая схема. Один нейрон может соединяться с несколькими тысячами других, что дает высокий параллелизм (именно параллелизм, а не модную многопоточность). Некоторые принципы работы нейронов не установлены (потому что нейроны-то у всех есть, а вот электронный микроскоп не у каждого), однако известно, что существует класс нейронов, использующий две группы входов – возбуждающие и тормозящий. Сигналы на возбуждающих входах заставляют нейрон генерировать сигнал на аксоне, тормозящие соответственно подавляют выходной сигнал. Дендриты имеют порог срабатывания, то есть требуют, чтобы на их вход поступал сигнал определенного уровня, иначе он будет не засчитан, И который может изменяться под воздействием ряда факторов – например попадания определенных веществ, таких как гормоны. Время срабатывания нейронов относительно небольшое: 2-5 мс, Однако более 6 миллиардов нейронных сетей доказали, что с их помощью можно решать довольно-таки сложные задачи, такие как: разум, научно-технический прогресс и создание цивилизаций (наравне с такими задачами как разрушение природы и конкурентных видов, а также активная и очень эффективная внутривидовая борьба). Более того, миллионы лет эволюции убедительно доказывают, что такого быстродействия вполне достаточно для решения задач реального времени. Компьютерные же модели пока, что ушли не так далеко и используются в научных целях (в основном для того, чтобы понять каким же образом 6-ти миллиардам нейронных сетей вообще удалось выработать такую концепцию как нейронные сети).
Анамнез
Несмотря на громкие заявления, реальное использование нейронных сетей на практике ничтожно в сравнении с традиционными алгоритмами. Основная причина – неточное формулирование задач, результаты которых также не очевидны – такие как прогнозирование погоды, биржевые сводки, в общем, все, что сводится к гаданию на кофейной гуще и где нельзя однозначно поймать за руку. Наиболее серьезным является применение нейронных сетей для распознавания образов на базе персептронов (сети, где нейроны сгруппированы в слои), что не удивительно, теоретические предпосылки данных концепций (и персептронов и распознавания образов и распознавания образов на персептронах) были разработаны 60-70-х годах прошлого столетия, примерно в тоже время, когда был создан автомат для автоматического распознавания индексов на почтовых конвертах. В последнее время мощностей обычных компьютеров вполне достаточно для создания полноценных нейронных сетей (чем мы собственно и будем заниматься), что позволяет все чаще применять их на практике (например, интересной темой является использование нейронных сетей для сжатия информации). Следует сразу же предупредить: использование нейронных сетей в задачах, алгоритмы которых легко перенести на языки программирования, в подавляющем большинстве случаев не эффективно (обычно по быстродействию).
Настольная инструкция по приготовлению нейронных сетей
Прежде чем писать программу, имитирующую биологические нейроны, нужно выработать модель. Я предлагаю следующую модель нейрона…
Каждый нейрон имеет 32 входа, из них 16 положительных (считаю, использование термина возбуждающие выходы, здесь использовать не стоит) и 16 отрицательных. Выход соответственно один. Сразу договоримся о терминах – входы будем называть дендритами. Хотя в некоторых литературных источниках используется обозначение синапса, это на самом деле не совсем верно (почему написано выше). Выход также будем называть аксоном. Входы получают сигналы по принципу: есть сигнал / нет сигнала (0/1 или ложь/истина). Сам нейрон будет работать по принципу сумматора – он складывает все сигналы на каждой из групп входов. Соответственно, если число сигналов на положительных входах больше, чем на отрицательных, то нейрон устанавливает сигнал на выходе (аксоне). В обратном случае сигнал с выхода снимается (даже если сумма сигналов на положительных входах равна сумме сигналов на отрицательных).
Для данных нейронов порог срабатывания дендритов будет всегда и для всех одинаковым и равным уровню выходного сигнала. То есть наш нейрон будет работать с логическими величинами, и фактически будет являться предикатом (функцией возвращающей результат логического типа). Здесь по законам жанра научно-популярных статей следует погрузиться в обилие формул и не только математических. Но, как правило, для большинства читателей таких статей они абсолютно бесполезны, поэтому мы приводить их здесь не будем (кому интересно, найдет в прилагаемых источниках).
Почему 32 входа? Это компромисс между производительностью сети и быстродействием компьютера. Зависимость здесь следующая – чем больше выходов имеет нейроны, тем больше вычислительная мощность сети и тем больше вычислительных ресурсов требуется на реализацию.
Сам по себе нейрон устройство узкоспециализированное и его использование не в сети (даже если она и состоит из одного нейрона) является весьма проблематичным занятием, и поэтому далее мы рассмотрим модель нейронной сети.
Итак, помимо самих нейронов, сеть может содержать таблицу входных данных и таблицу выходных данных. Таблица входных данных характеризует информацию, поступающую в нейронную сеть – в биологии ее прототипом являются рецепторы. То есть датчики, с которых берется информация о задаче. Нейроны подключаются входами к таблице входных данных (заодно и к выходам нейронов) и формируют результаты, часть из которых помещаются в таблицу выходных данных. Данные, помещенные в таблицу выходных данных, символизируют решение поставленной задачи. Существует множество вариантов нейронной сети, но наиболее распространены персептроны – нейронные сети, где нейроны объединены в группы (слои). Обычно нейроны одного слоя могут соединяться с выходами нейронов другого, конкретного слоя, но бывают и исключения. В нашем варианте мы будем использовать хаотичное соединение нейронов (здесь имеется ввиду, что если порядок соединения нейронов и существует, то на данный момент он неизвестен), каждый нейрон имеет право быть соединенным с любым объектом нейронной сети, включая и таблицу входных данных, и таблицу выходных данных. Потому что это ближе к реальной биологической модели и строгих доказательств того, что нейроны объединены в группы или слои не обнаружено. Зато обнаружены нейроны – цель которых только передача импульса от входа к выходу, то есть это удлинители, которые соединяют между собой нейроны (те, что не могут быть соединены между собой напрямую ввиду их расположения).
Серьезным недостатком решения задач на нейронных сетях является отсутствие четких условий решения при постановке задачи перед нейронной сетью. Иными словами нельзя точно сказать, сколько нейронов требуется для решения данной задачи или достаточно ли данного числа нейронов для получения положительных результатов. Возможно, при определении конфигурации нейронной сети будет выбрано недостаточной число нейронов и решение задачи никогда не наступит. Существует ряд работ направленных на решение этой проблемы [1-5], однако до успешных результатов пока далеко (опять-таки, несмотря на заверения академиков и обилие формул). Сейчас выбор параметров в основном определяется на основании предыдущих опытов, либо экспериментальным путем. Я же выбрал хаотичную модель по двум причинам. Во-первых, персептроны не способны решать некоторые задачи независимо от числа нейронов в них (это было известно еще в Советском Союзе), а во-вторых, персептроны есть ограниченное подмножество моделей с хаотичным образованием нейронов и при изменении связей можно добиться получения персептрона практически любого типа. А возможность замыкания отдельных входов нейрона на его же выход или на константные сигналы позволяет имитировать дискретные уровни порога срабатывания.
Важной способностью нейронной сети – является возможность ее обучения за счет изменения порогов срабатывания и/или переключения связей между нейронами. Поскольку в нашем случае нейроны имеют одинаковые пороги срабатывания на всех входах и выходах, то обучение нашей модели будет происходить через изменение связей между нейронами. Кстати, на изменениях порога срабатывания есть алгоритмы автоматического обучения нейронных сетей, но опять же все это дело весьма и весьма условно. Потому что обучение возможно также только для некоторых видов задач и потому что такое обучение вырождается в генетический алгоритм, а это уже другая история, хоть и смежная (естественно исследователи не ищут легких путей). Обучение нейронных сетей такого типа производится случайным изменением связей между нейронами (как правило). Происходит это следующим образом. Пусть имеется некоторая задача, заключающаяся в решении некоторой функции f(x). То есть на каждое состояние таблицы входных данных должно быть только одно состояние таблицы выходных данных. Возьмем избитый пример – распознавание образов. Здесь на каждую картинку имеется соответствующая цепочка сигналов. Имеющейся сети дается тестовое задание – серия образов, затем сеть прореживается и получившаяся серия результатов сравнивается с эталонными данными. Если сеть отвечает требованиям задачи, то ее уже можно использовать (чего с первого раза на практике не бывает). Если же нет, то текущая конфигурация запоминается и на ее основе формируется новая сеть путем случайного изменения связи случайного дендрита случайного нейрона. Процесс распознавания повторяется. Теперь уже сравниваются оба результата тестирования: первоначальный и новый, полученный в результате мутации (здесь много биологических терминов). Например, сравнивать можно по проценту правильных результатов в серии распознавания образов. Теперь за основу берется та сеть, в которой процент совпадений больше и процесс повторяется до тех пор, пока результат тестирования не даст полного совпадения с эталоном. Или заранее определенное количество раз, иначе есть вероятность бесконечного процесса обучения. Здесь же нужно сразу определиться какой вариант сети лучше, в случае если оба варианта дают одинаковый процент узнаваний (новый вариант сети предпочтительней).
Подводные камни и течения
А что вообще может решать нейронная сеть? Теоретически даже может решить теорему Ферма. Для этого требуется не так уж много – нейронная сеть с числом нейронов примерно 1012 – 1015 степени, нейроны должны иметь возможность соединяться с несколькими тысячами других (порядка 20000). Если еще не понятно, то это мозг человека – лучшая иллюстрация работы нейронных сетей. На самом деле нейронов требуется еще меньше, потому что значительная их часть требуется на обслуживание и управление полуавтоматическими системами, таких как легкие, мышцы, желудок, саморегуляция и т.д. А также на передачу данных для других групп нейронов в те же самые органы. Плюс обработка огромного количества датчиков. Такую нейронную систему можно считать эталонной, но не идеальной. На ее обучение требуются годы.
На самом деле нейрон очень мощная логическая единица. С помощью нее можно эмулировать, например такие элементы как логическое «И», логическое «ИЛИ» и логическое «НЕ», то есть практически все современные логические операции легко могут быть выражены через нейронные сети. Одной из причин сложности конструирования эффективных сетей является тот факт, что логика на нейронах на порядок мощней обычной логики и всех ее смежных дисциплин, потому-то и выразить ее в рамках стандартной довольно-таки проблемно без привлечения интегралов и прочих трехэтажных формул (включая и логических). Далее с помощью нейронов можно эмулировать и работу сразу сложных блоков, таких как триггеры, счетчики, шифраторы, дешифраторы и т.д. И, наконец, нейронная сеть позволяет эмулировать аналоговые элементы (при наличии творческой жилки у программиста) и сложные схемы (на манер программ Qucs, Electronics Workbench, Microcap и т.д.).
Далее, нейронные сети способные решать задачи даже, если никогда до этого не сталкивались с такими условиями ранее, хаотичные соединения позволяют формировать различные как положительные, так и отрицательные обратные связи, что может порождать решения на грани интуиции. Однако в таких условиях возникает новая проблема – подобно человеку, нейросети способны ошибаться.
Еще одна частая ошибка (наблюдается даже в серьезных трудах) – это временные интервалы функционирования нейрона относительно других в нейронной сети. Представим работу какого-либо нейрона. Итак, он прочитал данные и сформировал новое состояние аксона. В результате какой-либо другой нейрон будет читать уже новое состояние аксона, и работа всей системы в целом будет нарушена (потому как нейрон может обратиться к любому другому нейрону и не факт, что тот уже поменял свое состояние на новое). Проблема усугубляется тем, что новое значение на первом нейроне не всегда влияет на состояние последующих, а только для некоторых дендритов или некоторых состояний системы. Далее существует вероятность, что данный нейрон также изменит свое состояние и т.д. Таким образом, результаты работы могут быть полностью искажены. Отчасти благодаря такой проблеме персептроны и получили такое распространение. В них слои, нейроны и их взаимосвязи организованы в иерархии таким образом, что все нейроны всегда получают новые сигналы, то есть сначала первый слой берет данные из рецепторов, второй слой берет данные из первого слоя и т.д. Но нас это ни как не останавливает, решение этой проблемы снижает быстродействие, но зато позволяет имитировать нейронные сети любой конфигурации. Смысл заключается в кэширование результатов работы нейрона. Иными словами нейрон изменяет (или не изменяет) состояние аксона не сразу, а только после того, как абсолютно все нейроны в сети выполнят свою работу. Только после этого происходит изменение состояния всех нейронов. Это гарантирует, что все нейроны получат достоверные сигналы, и, следовательно, выработают достоверные результаты.
Далее следует правильно трактовать результаты работы. Для простых задач, решение которых однозначно описывается f(x), то есть один параметр и только одно результирующее значение для каждого значения входящего параметра, это самое результирующее значение перестает играть особую роль. Всегда можно написать транслятор результатов, с использованием стандартных средств программирования, в случае если их число не велико. Объясню на примере все того же распознавания образов. Допустим, перед сетью стоит задача распознавания образов букв A, B и С. Результатом должно быть 2 бита (см. таблицу 1 и 2):
Таблица 1. Вариации распознавания
|
Входной образ |
Результат |
|
|
Буква А |
0 |
1 |
|
Буква В |
1 |
0 |
|
Буква С |
1 |
1 |
|
Любое другое изображение |
0 |
0 |
На самом деле это все равно что, вот такая таблица (см. таблицу 2):
Таблица 2. Вариации распознавания
|
Входной образ |
Результат |
|
|
Буква А |
0 |
1 |
|
Буква В |
1 |
1 |
|
Буква С |
1 |
0 |
|
Любое другое изображение |
0 |
0 |
И нет особого смысла мучить сеть мутациями (особенно если она состоит из тысяч нейронов), гораздо быстрей и проще написать транслятор, который брал бы данные из таблицы выходных значений и выдавал требуемый результат (см. рисунок):
|
Таблица входных данных (рецепторы)
|
|
|
|
|
|
Нейроны
|
|
|
|
|
|
Таблица выходных данных
|
|
|
|
|
|
Транслятор результатов
|
|
Рис.1. Алгоритм продвижения данных
Как уже было отмечено ранее, не стоит ожидать сразу ошеломляющей эффективности при использовании нейронных сетей, по разным причинам. Одна из них (необъективная) связана с восприятием самого человека. Как известно, приборы неизбежно вносят свои погрешности в результаты измерений, аналогично и человек при оценке работы нейросети, в большинстве случаев вносит в результаты свои погрешности.
Продолжим с тем-же распознаванием образов. Требуя от сетей четкого и однозначного определения результатов, очень часто человек сам не в состоянии адекватно оценить предлагаемое изображение по ряду причин (это связано не только со зрением). В тоже время человек способен распознать образ даже очень плохого качества, основываясь:
а) на предыдущем опыте – что, как правило, недоступно для нейронных сетей. Иными словами, человек не только обучен узнавать образ, но он может и просто помнить его, что значительно упрощает идентификацию объекта. Нейросетям для запоминания же требуется несколько большее количество нейронов, чем у них есть.
б) на информации, которая недоступна нейронным сетям по условиям задачи. Самый простой пример – это разбор рукописного текста. Чтобы понять все слова совершенно необязательно понимать все буквы – этот эффект давно известен и в частности им пользуются американцы в повседневной речи. Они проглатывают окончания (иногда середину) слов, просто не договаривая их. Также и человек, распознав большинство членов предложения, в состоянии восстановить слово исходя из контекста, а не за счет определения символов слова.
Теперь представим, что у нас уже имеется нейронная сеть (в смысле компьютерная модель). Она способна решать задачи и вроде все отлично, но настоящего исследователя такая позиция нисколько не устраивает – как это работает? Может для решения задачи требуется меньше нейронов? Что будет если отключить вон тот нейрончик? Ведь чем меньше в сети нейронов, тем меньше ресурсов требуется для ее выполнения, а скорость выполнения – один из серьезных недостатков, сдерживающий развитие науки о нейронных сетях.
Заблокировать нейрон можно, если его заставить читать информацию из самого себя (и только из самого себя). Тогда на его аксоне будет пожизненный нуль (напомню, что в хаотичной модели нейронной сети любой нейрон имеет право адресоваться к любому источнику сигнала, включая и самого себя).
Далее анализ, проведенный на базе имитации основных логических элементов, показывает, что нейронные сети более предрасположены к обучению, если помимо изменяемых данных они содержат в себе некоторые константные сигналы (в большинстве случаев достаточно постоянного 1 и постоянного 0). Получить их можно искусственно, например, жестко задать неизменяемое значение в таблице входных сигналов. Ну и нуль всегда можно получить, заблокировав нейрон.
Как это ни странно, но к нейронным сетям можно применять и некоторые стандартные средства отладки. Один из них – контрольные точки. Можно получать данные с одного нейрона и писать их в массив для дальнейшего анализа. Какого? Самый примитивный пример – если нейрон не меняет своего значения на протяжении всей работы нейросети, независимо от входящих параметров, то следует задуматься над этим фактом. Может проще все дендриты, которые подключены к нему, переключить на константные значения в таблице входных значений? Фактически такой нейрон выполняет транспортную функцию – он передает константу (или формирует ее) для тех нейронов, которые подключены к нему. Это актуально для биологических нейронов (не может нейрон из мозга напрямую подключиться к нейрону из копчика), но бессмысленно для нашей сети – каждый нейрон имеет возможность напрямую подключаться к источникам сигнала. Более сложный анализ предусматривает сбор информации и ее сравнение с группой нейронов. Цель – поиск дубликатов, то есть устранение все тех же нейронов, выполняющих транспортную функцию.
Можно также поискать нейроны, выполняющие бесполезную работу. Это нейроны, к которым никто не обращается, то есть ни другие нейроны, ни таблица выходных данных. Соответственно и результаты их работы не нужны. Аналогично можно поступить и со значениями из таблицы входных значений: если к данному элементу никто не обращается, то возможно данный элемент просто не нужен, либо сеть работает неправильно и требуется расширенное тестирование. Задача всех оптимизаций такова, чтобы получить нейронную сеть без элементов, работа которых не влияет на результат работы нейронной сети: кто не работает, тот не должен есть ресурсы компьютера.
Препараты
Здесь мы рассмотрим структуры данных, с помощью которых можно создать нейросеть. Запись будет производиться на языке Дельфи. Однако я постараюсь дать развернутое обоснование выбранных полей, так чтобы нейронную сеть легко можно было организовать и с помощью других языков программирования.
Прежде всего, нам нужна модель нейрона, который будет являться центральным элементом нейронной сети. Итак, предлагаю следующую модель:
type
TNeron = class (TObject)
protected
Akson: Boolean; // Выход нейрона
Akson2: Boolean; // Кэш нейрона
Dendrits: Array [0..31] of Integer; // Входы нейрона (как адрес другого нейрона)
private
public
// Подготовка к работе нейрона
constructor Create;
destructor Destroy; override;
procedure Init(); // Инициализация нейрона
// Организация доступа
procedure SetDendrit(Num, Value: Integer); // Установка связи дендрита
procedure Update(); // Запись данных из кэша
procedure SetAkson2(Value: Boolean); // Запись значения в кэш
function GetAkson(): Boolean; // Чтение аксона
function GetDendrit(Num: Integer): Integer; // Чтение значения дендрита (связи)
end;
Akson – значение логического типа, это выход, откуда будут читаться результаты работы нейрона.
Akson2 – это кэш аксона, предназначен для синхронизации работы нейронной сети.
Dendrites – это массив ссылок на аксоны и другие элементы нейронной сети. Всего их 32 и на данном этапе нет различий между положительными и отрицательными входами (это делается программно). Ссылка представляет собой идентификатор объекта, в качестве которого может выступать:
а) нейрон;
б) элемент таблицы входных данных;
в) элемент таблицы выходных данных.
* Комментарий автора
Обратите внимание, идентификатор является общим для всех элементов (в том смысле, что, используя данный идентификатор, дендрит, может обратиться к любому объекту, включая и свой собственный аксон).
Вообще-то, в нейронной сети каждый тип элементов организован в свои собственные динамические массивы и имеет свой собственный индекс для доступа. Общий же (или абсолютный) идентификатор вычисляется для удобства использования и адресации в тех методах нейронной сети, где это непосредственно требуется. Собственно ничего сложного нет – нейрон, по сути, хранилище данных, не реализована даже функция работы нейрона. Просто потому, что его работа без нейронной сети невозможна. Все методы направлены в основном на чтение/запись полей класса. Вообще реализацию можно было сделать и без класса (даже проще), но потом это отразиться на удобстве дальнейшей модификации нейронной сети. Теперь рассмотрим модель нейронной сети:
type
TNNet=class
protected
// Поля
Data: Array of TNeron; // Нейроны
Count: Integer; // Количество нейронов
TableIn: Array of Boolean; // Рецепторы
CountIn: Integer; // Количество рецпеторов
TableOut: Array of Boolean; // Таблица результатов
TableOut2: Array of Integer; // Ссылки на существующие нейроны, откуда читать сигналы
CountOut: Integer; // Число сигналов в таблице результатов
private
function RunNeron(Neron: Integer): Boolean; // Выполнение указанного нейрона
procedure Updating(); // Перенос сигналов из кэша нейронов на их выходы
Procedure OutPuting(); // Берем все значения для таблицы выходных данных
public
procedure InitNerons(); // Инициализация набора нейрона
procedure InitTablein(); // Инициализация рецепторов
procedure InitTableOut(); // Инициализация таблицы выходных сигналов
constructor Create; overload; // Конструктор нейросети
constructor Create(InTable, Nerons, OutTable: Integer); overload; // Конструктор нейросети
destructor Destroy; override; // Деструктор нейросети
// Работа с рецепторами
procedure SetCountIn(Value: Integer); // Устанавливаем число рецепторов
procedure ClearTableIn(); // Устанавливает все рецепторы в False (гасит сигналы)
function GetCountIn(): Integer; // Возвращает число рецепторов
procedure SetElemIn(Num: Integer; Value: Boolean); // Устанавливает сигнал для указанного рецептора
procedure SetTableIn(Value: Array of Boolean); // Запись сигналов сразу для всех рецепторов
// Работа с таблицей выходных данных
Procedure SetCountOut(Value: Integer); // Устанавливает число элементов таблицы выходных данных
Function GetCountOut(): Integer; // Возвращает число элементов таблицы выходных данных (сигналов)
Function GetValueOut(Num: Integer): Boolean; // Чтение выходного сигнала
Function GetLinkOut(Num: Integer): Integer; // Читаем линк для данной ячейки таблицы выходного сигнала
Procedure SetLinkOut(Num, Value: Integer); // Установка линка на нейрон
Procedure ClearOut(); // Очистка таблицы выходных сигналов (установка в False)
// Работа с нейронами
Procedure SetDendrit(Neron, Num, Value: Integer); // Установка линка
Procedure SetDendrit2(Neron, Num, Value: Integer); // Установка линка (абсолютная адресация в рамках нейросети)
function GetDendrit(Neron, Num: Integer): Integer; // Чтение линка
Procedure Run(); // Выполнение одного шага нейросети
Procedure Run2(Tik: Integer); // Выполним указанное число циклов нейросети
Procedure Run3(); // Минимальный запуск
Procedure SetNeronCount(Value: Integer); // Задаем количсетво нейронов
Procedure Mutation(); // Мутация нейросети (произвольного входа произвольного нейрона)
Procedure Generator(InTable, Nerons, OutTable: Integer); // Формирование сети с заданным количеством нейронов и данных в таблице
end;
Как уже было отмечено ранее, все типы элементов нейросети сгруппированы в рамках своего типа в динамические массивы. Здесь только следует обратить внимание на TableOut2 – эта структура относится к таблице выходных данных и представляет собой ссылки на нейроны, откуда следует читать информацию в элементы таблицы. Все Count’ы в данном случае являются счетчиками числа элементов в массиве. В принципе, число элементов динамического массива можно узнать и в Дельфи, не пользуясь дополнительной переменной. Но наш пример учебный и предназначен для понимания принципов работы нейронной сети. Оптимизацию можно проводить уже после ознакомления с данным примером.
Итак, из полей класса нейронной сети видно, что он также не представляет собой ничего сложного. Теперь немного уделим внимание методам, это поможет понять логику их работы. Сначала рассмотрим методы в секции Private. Это методы для внутреннего пользования, то есть, они поддерживают работу класса, и не должны вызываться извне – это может нарушить нормальную работу нейронной сети.
Сразу возникает вопрос – почему RunNeron есть функция? Она возвращает True (истина), если нейрон может выполнить свою работу (и тогда он ее выполнит). Сделано так специально с расчетом на будущую модификацию сети. Например, в данном классе не реализовано сохранение и чтение нейронной сети во внешний файл. Представьте себе ситуацию, что Вы загрузили поврежденный файл или же во время работы изменили нейронную сеть. Тогда возможно нарушение ее внутренней структуре, что может привести к тому, что дендрит будет ссылаться на нейрон (или на элемент одной из таблицы), которого не существует в данной нейронной сети.
Updating должен выполняться (и выполняется) сразу после выполнения всех нейронов в сети – это процесс обновления сигналов на выходах нейронов. Она переносит значение из Akson2 в Akson в каждом нейроне нейронной сети. Функция RunNeron помещает результат работы нейрона именно в Akson2, что дает возможность другим нейронам получать старые данные и сохраняет целостность и корректность модели.
OutPuting – отвечает за сбор информации в таблицу выходных значений. После обработки всех нейронов осуществляется обновление их выходов (посредством Updating). Затем OutPuting читает информацию из объекта нейронной сети, руководствуясь информацией из TableOut2, и переносит результат в соответствующий элемент таблицы выходных данных.
Большинство остальных методов класса ориентированы на получение данных об объектах нейронной сети, а также на внесение в нее изменений, в том числе и внесение информации о задаче (информация в таблице входных данных). Пожалуй, интерес представляет только Run – выполнение нейронной сети. На самом деле это группа операций. А именно – выполнение всех нейронов, обновление состояний выходов нейронов и получение результатов в таблицу выходных данных.
** Комментарий автора.
Напоследок – не совсем удачное название класса выбрано специально, чтобы избежать возможного конфликта имен. Дело в том, что существует ряд классов и компонентов, имеющих в названии Net. Да и самописные инструменты, связанные с работой через сеть (не нейронную) обычно называются аналогично, а длинное имя элементарно лень писать. Все остальные вопросы можно уточнить в проекте, в котором реализована данная модель нейронной сети.
Заключение
В данной статье описана простая модель нейронной сети, при доработке которой можно добиться весьма неплохих результатов. Здесь-бы хотелось отразить те моменты, с помощью которых данный пример можно развить до вполне конкурентоспособного и, возможно, даже коммерческого варианта:
1. Сохранение и чтение нейронной сети в файл. В случае если Вы только отрабатываете свои навыки, то это может быть простенький текстовый формат по типу CSV (где все поля в строке разделяются символами табуляции). Простота устройства сети позволяет легко реализовать процедуру сохранения информации с использованием буфера, например, через список строк (такой как TStringList). Процесс чтения, как правило, немного сложнее из-за необходимости контроля целостности внутренней структуры сети.
2. Введение отладочных механизмов. Несмотря на то, что речь о них в статье шла, в примере они не реализованы. Здесь необходимо уделить внимание оптимизации алгоритма по скорости. Сложности возникать не должно, что и зачем в статье описано. Главное помнить, что работа сети есть большое количество итеративных (циклических) процессов, а на это требуется время, что может потребовать принудительного выделения ресурсов, например, с помощью Application.ProccessMessagess, либо аналогичных средств.
3. Введение дополнительных удобств использования. В примере данные возвращаются побитно, но можно группировать информацию и возвращать массивы, либо упаковывать в байты и анализировать их далее.
4. Оформление проекта в качестве динамической библиотеки, что позволит подключать ее и для других языков программирования, и вообще будет способствовать распространению.
5. Написание дополнительных инструментов. В частности, можно написать генератор нейронных сетей, позволяющий создавать нейронные сети с некоторыми заданными характеристиками. Тогда проект может уже подгружать и работать с готовыми нейронными сетями.
6. Написать распределенную версию нейронной сети. Это позволит запускать ее на нескольких компьютерах и производить внутренний обмен посредством локальной и глобальной сети. Что в свою очередь дает решать более глобальные и ресурсоемкие задачи.
7. Оформление подробной документации. Один из важнейших вопросов, к которому большинство программистов, обычно относятся халатно.
Источники. Что почитать
. Раздел википедии http://ru.wikipedia.org/wiki/Нейросети
. Введение в искусственные нейронные сети http://www.osp.ru/os/1997/04/179189/
. Нейронные сети http://www.statsoft.ru/home/textbook/modules/stneunet.html
. Введение в теорию нейронных сетей http://www.orc.ru/~stasson/neurox.html
. Материал по нейронным сетям http://www.artkis.ru/neural_network.php
. Нейронные сети – математический аппарат http://www.basegroup.ru/library/analysis/neural/math/
. Лекции по теории и приложениям искусственных нейронных сетей
http://alife.narod.ru/lectures/neural/Neu_ch12.htm
. Основные понятия Нейронных Сетей http://oasis.peterlink.ru/~dap/nneng/nnlinks/
. Нейронные сети: прогнозирование как задача распознавания образов
http://www.masters.donntu.edu.ua/2003/fvti/paukov/library/neurow.h
Статья из пятого выпуска журнала ПРОграммист.
Скачать этот номер можно по ссылке.
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
