

Последние записи
- Найти среднее значение по данным в ячейке
- Число различных чисел (Microsoft Office Excel)
- Убить процесс
- Конвертер heic в jpg
- Проверка на шестнадцатеричный формат записи
- Отдать пользователю файл с помощью file_get_contents()
- Написать собственую функцию operator[] для битов
- Проблема с движением 2D человека
- OpenGl.Создание винтовой лестницы
- Склеить несколько файлов в один

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
19th
Авг
 Введение в Scheme. Часть 2.
Введение в Scheme. Часть 2.
Здравствуйте, дорогие читатели. Как и обещал, сегодня мы продолжим рассмотрение наиболее распространенных команд языка Scheme и механизмов, облегчающих управление процессом выполнения, а также познакомимся ближе со средой разработки PLT Scheme.
Продолжение. Начало цикла смотрите в четвертом выпуске журнала…
Введение в Sсheme. Часть 2
Utkin www.programmersforum.ru
Нужно помнить, что данные предикаты нежелательно использовать на неточных числах – ошибки округления могут приводить к обратным результатам. Кстати, определить является ли число точным или не точным можно определить с помощью предикатов:
(exact? z) Тест на точность
(inexact? z) Тест на неточность
Для одного и того же числа один из этих предикатов всегда результат #t, тогда как второй #f. Для сравнения чисел можно использовать следующие предикаты, думаю назначение их понятно и так:
(= х1 х2 х3 …)
(< x1 x2 x3 …)
(> x1 x2 x3 …)
(<= x1 x2 x3 …)
(>= x1 x2 x3 …)
(= 1 1 1) #t
(= 1 2 1) #f
Аналогично, предикатам типов числа, не стоит применять сравнения на неточных числах, поскольку ошибки округления могут дать противоположный результат для почти равных чисел.
Еще предикаты для работы с числами:
(zero? z) Проверка на нуль
(positive? x) Проверка является ли число положительным
(negative? x) Проверка является ли число отрицательным
(odd? n) Проверка является ли число не четным
(even? n) Проверка является ли число четным
Поиск минимального и максимального чисел:
(max x1 x2 …)
(min x1 x2 …)
Примеры:
(max 3 4) Результат 4
(max 3.9 4 9 48 99 5) Результат 99.0 При этом число будет преобразовано в неточное.
(min 54 565 9L0) Результат 9.0
(min 4 4) Результат 4
Нужно соблюдать осторожность при сравнении почти равных неточных чисел, поскольку правильный результат работы данных предикатов не гарантирован. Теперь напомним стандартные арифметические операции:
(+ z1 …) Сложение
(* z1 …) Умножение
(- z1 z2) Вычитание
(- z) Унарный минус
(- z1 z2 …) Вычитание (с произвольным числом аргументов)
(/ z1 z2) Деление (деление на нуль не допускается)
(/ z) Деление 1 / z, при этом образуется дробь
(/ z1 z2 …) Деление z1 на произвольное число аргументов
Теперь примеры (поскольку некоторые результаты не очевидны):
(+ 3 4) Результат 7
(+ 3) Результат 3
(+) Результат 0
(* 4) Результат 4
(*) Результат 1
(- 3 4) Результат -1
(- 3 4 5) Результат -6
(- 3) Результат -3
(/ 3 4 5) Результат 3/20 (3 разделить на 4*5)
(/ 3) Результат 1/3
Кстати, дроби являются точными числами, поэтому их удобно использовать в предикатах для работы с числами (гарантируются однозначные результаты сравнений, отношений и т.д.). Дополнительные операции над числами:
(abs x) Абсолютное значение числа
Дополнительные операции деления:
(quotient n1 n2)
(remainder n1 n2)
(modulo n1 n2)
При этом n2 не должен быть равен нулю (независимо от точности числа). Если n1 / n2 есть целое:
(quotient n1 n2) Результат n1/n2
(remainder n1 n2) Результат 0
(modulo n1 n2) Результат 0
Если в результате n1 / n2 образуется не целое число:
(quotient n1 n2) Результат nq
(remainder n1 n2) Результат nr
(modulo n1 n2) Результат nm
где число nq – n1/n2, округленное к нулю, 0 <| nr | <| n2 |, 0 <| nm | <| n2 |, nr и nm отличаются от n1 множителем n2, nr получит знак n1, nm получит знак n2.
Особенностью этих функций (по сути, вариации на тему нахождение остатка от деления) является факт, того, что они возвращают точные числа, в случае если их входящие параметры также являются точными.
(modulo 13 4) Результат 1
(remainder 13 4) Результат 1
(modulo -13 4) Результат 3
(remainder -13 4) Результат -1
(modulo 13 -4) Результат -3
(remainder 13 -4) Результат 1
(modulo -13 -4) Результат -1
(remainder -13 -4) Результат -1
(remainder -13 -4.0) Результат -1.0 Обратите внимание, результат не точное число.
Следующие функции возвращают наибольший общий делитель или наименьший общий множитель их параметров. Результат является всегда неотрицательным.
(gcd 32 -36) Результат НОД (наибольший общий делитель) 4
(gcd) Результат 0
(lcm 32 -36) Результат НОМ (наименьший общий множитель) 288
(lcm 32.0 -36) Аналогично Результат 288.0, но теперь результат будет неточным.
(lcm) Результат 1
Следующие ниже функции возвращают числитель, и знаменатель дроби (знаменатель всегда положительное число):
(numerator q)
(denominator q)
Примеры:
(numerator (/ 6 4)) Результат 3
(denominator (/ 6 4)) Результат 2
(denominator
(exact->inexact (/ 6 4))) Результат 2.0, для получения неточного числа используется явное преобразование. Естественно удобно и для дробей:
(numerator 6/4) Результат 3 (рассматривается дробь 3/2, и только потом берется знаменатель)
Следующая группа функций:
(floor x)
(ceiling x)
(truncate x)
(round x)
всегда возвращает целые числа. Floor возвращает наибольшее целое число не большее чем х. Ceiling возвращает наименьшее целое число не меньше чем х. Truncate возвращает целое число, которое наиболее ближе к х, и абсолютная величина которого не больше абсолютной величины х. Round возвращает целое число путем округления х (половина икса округляется в большую сторону).
(floor -4.3) Результат -5.0 (числа целые, но не точные)
(ceiling -4.3) Результат -4.0
(truncate -4.3) Результат -4.0
(round -4.3) Результат -4.0
(floor 3.5) Результат 3.0
(ceiling 3.5) Результат 4.0
(truncate 3.5) Результат 3.0
(round 3.5) Результат 4.0 — не точное число
(round 7/2) Результат 4 — точное число
(round 7) Результат 7
(rationalize x y) – возвращает самое простое рациональное число, отличающееся от x не больше, чем y.
Рациональное число x более простое чем другое рациональное число y если x = p1/q1 и y = p2/q2 и и | p1 | < | p2 | и | q1 | <| q2 |. Таким образом, 3/5 более простое число чем 4/7. Хотя не все рациональные числа сопоставимы в этом упорядочении (например, 2/7 и 3/5), любой числовой интервал содержит рациональное число, которое более просто, чем любое рациональное число в том же интервале. Известно также, что 0 = 0/1 – самые простые рациональные числа из всех.
(rationalize
(inexact->exact .3) 1/10) Результат 1/3, точное число
(rationalize .3 1/10) Результат 0.3333333333333333
Трансцендентальные функции:
(exp z)
(log z)
(sin z)
(cos z)
(tan z)
(asin z)
(acos z)
(atan z)
(atan y x)
Здесь все просто, стоит отметить log – имеется ввиду натуральный (а не десятичный), atan с двумя параметрами использует знаки x, y для определения квадранта, к которому принадлежит результат.
(sqrt z) – вычисляет квадратный корень, включая мнимую часть числа:
(sqrt -1) Результат 0+1i (всегда мечтал в Паскале получить корень из -1)
(expt z1 z2) – возведение в степень, довольно-таки мощная функция, единственное ограничение – в степень запрещено возводить нуль.
(expt 2.1 3.3) Результат 11.569741950241465
(expt 2.1 -3.3) Результат 0.08643235124004903
Следующие функции предназначены для поддержки комплексных чисел:
(make-rectangular x1 x2)
(make-polar x3 x4)
(real-part z)
(imag-part z)
(magnitude z)
(angle z)
Здесь x1-x4 вещественные числа, z комплексное.
(make—rectangular x1 x2) Результат комплексное число
(make—polar x3 x4) Результат комплексное число
(real—part z) Результат реальную часть числа (x1)
(imag—part z) Результат мнимую часть числа (x2)
(magnitude z) Результат |x3|
(angle z) Результат xangle
Точные и неточные числа можно преобразовывать следующим образом:
(exact->inexact z)
(inexact->exact z)
Первая функция переводит точное число в неточное, вторая выполняет обратные действия. Естественно, такое преобразование возможно не всегда (такая ситуация считается ошибочной). Теперь рассмотрим ввод и вывод чисел. Числа можно получать из строки следующим образом:
(string->number string)
(string->number string radix)
Здесь radix есть основание системы счисления (точное целое число 2, 8, 10 или 16). Для первого варианта имеется ввиду основание системы счисления равным 10. Если число z является неточным и может быть выраженым с использованием точки в качестве разделителя целой и дробной частями, то число будет представлено с минимально возможным числом разрядов.
(string->number ”100″) Результат 100
(string->number ”100″ 16) Результат 256
(string->number ”1e2″) Результат 100.0
(string->number ”15##”) Результат 1500.0
В случае, если строку в число преобразовать не удастся, результат функции #f.
Пары и списки
Парой (иногда называется точечной парой) называется структура данных, представляющая собой запись, состоящую из двух полей, первое из которых называется car, а вторая cdr (названия сложились исторически). Пара создается функцией сons. Доступ к полям пары осуществляется одноименными функциями car и cdr. Присваивание значений полям пары осуществляется с помощью процедур set-car! и set-cdr!. Основное назначение пар это образование и представление списков. Список может быть определен рекурсивно, как пустой список (список, не содержащий элементов) или как пара поле cdr которого является списком. Если Х является списком, то:
. в Х содержится пустой список
. если список находится в X, то любая пара, поле cdr которой содержит список, находится также в X.
Объекты в полях car последовательных пар списка считаются элементами списка. Например, двухэлементный список это пара, car которой первый элемент списка и чей cdr пара, car которой второй элемент списка и чей cdr есть пустой список. Длина списка – это число элементов (которые можно выразить как число пар).
|
Список |
Список состоит из пар |
||||
|
Пара1 |
Car |
1-й элемент списка |
|||
|
Cdr |
Пара2 |
Car |
2-й элемент списка |
||
|
Cdr |
Пустой список |
||||
Список (a b c d e) можно выразить так (a . (b . (c . (d . (e . ()))))). То есть в списке пары расположены не последовательно друг за другом, а являются вложенными объектами. Пустой список – специальный объект своего собственного типа (это не пара); у него нет никаких элементов, и его длина равна нулю. При этом все списки имеют конечную длину (точное число) и заканчиваются пустым списком.
Для представления пар используется точечная нотация, поля разделяются точкой. Например, пара (4 . 5) имеет поле car 4 и поле cdr 5, при этом внутреннее представление пары будет иным. Списки выражаются проще (х1 х2 … хn), где х это элемент списка. Пустой список выражается, как (). Как уже было отмечено ранее, вся программа на языке Scheme является списком (как и любые ее логически законченные фрагменты), поэтому программы, и выражения можно обрабатывать также как и списки.
Существуют структуры, похожие на списки, которые не удовлетворяют данному выше определению, они называются неподходящие списки. Неподходящий список списком не является, вот его пример:
(a b c . d) что эквивалентно (a . (b . (c . d))), то есть неподходящие списки есть пары.
(define x (list ’a ’b ’c))
(define y x)
y Результат (a b c), list создает список
(list? y) Результат #t, предикат проверки списка
(set—cdr! x 4) Результат не определен (побочный эффект cdr х равен 4)
x Результат (a . 4)
(eqv? x y) Результат #t
y Результат (a . 4)
(list? y) Результат #f
(set—cdr! x x) Результат не определен
(list? x) Результат #f
Предикат (pair? obj) проверяет является ли объект парой.
(pair? ‘(a . b)) Результат #t
(pair? ‘(a b c)) Результат #t
(pair? ‘()) Результат #f
(pair? ’#(a b)) Результат #f
Следующая функция возвращает пару:
(cons obj1 obj2)
car пары будет представлять собой obj1, cdr соответственно obj2.
(cons ‘a ‘()) Результат (а)
(cons ‘(a) ‘(b c d)) Результат (c d)
(cons “a“ ‘(b c)) Результат (”a“ b c), обратите внимание на квотирование и кавычки
(cons ’a 3) Результат (a . 3)
(cons ’(a b) ’c) Результат ((a b) . c)
Квотирование в данном случае используется для того, чтобы поля пары не вычислялись в момент внесения в пару. Это позволяет вносить в пару как простые данные, вроде чисел, так и функции и выражения.
(car pair) – возвращает поле car пары (так и хочется сказать первое поле, но внутреннее представление пар может быть иным, поля пары могут находиться даже не в смежных областях памяти). Попытка получения car пустой пары вызовет ошибку.
(car ’(a b c)) Результат a
(car ’((a) b c d)) Результат (a)
(car ’(1 . 2)) Результат 1
(car ‘()) Результат ошибка вычислений
(cdr pair) – возвращает поле cdr пары. Получение cdr пустого списка вызовет ошибку.
(cdr ‘((a) b c d)) Результат (b c d)
(cdr ’(1 . 2)) Результат 2
(cdr ’()) Результат ошибка вычислений
(set—car! pair obj) и (set—cdr! pair obj) помещает соответственно в car и cdr пары pairs объект obj.
Результат их работы не определен, функции имеют побочные эффекты. Очень часто во время манипуляций со списками возникает много car и cdr. Такие выражения допускается сокращать:
(car (cdr (cdr x))) эквивалентно caddr, то есть справедливо следующее утверждение:
(define caddr (lambda (x) (car (cdr (cdr x)))))
Правило формирования функции следующее: все car представляются как а, а все cdr как d в наименовании функции, которая начинается с с и заканчивается r. При этом допускается формирование функций не более чем из четырех car и cdr.
(null? obj) – возвращает #t, если obj есть пустой список
(list? obj) – возвращает #t, если obj есть список.
(list? ‘(a b c)) Результат #t
(list? ’()) Результат #t
(list? ‘(a . b)) Результат #f
(let ((x (list ’a)))
(set-cdr! x x)
(list? x)) Результат #f
(list obj …) – создает список.
(list ’a (+ 3 4) ’c) Результат (a 7 c)
(list) Результат ()
(length list) – передает число элементов в списке
(length ’(a b c)) Результат 3
(length ’(a (b) (c d e))) Результат 3
(length ’()) Результат 0
(append list …) – объединение списков, при этом происходит перераспределение их внутренней структуры (таким образом, чтобы результат удовлетворял определению списка).
(append ‘(x) ‘(y)) Результат (x y)
(append ’(a) ’(b c d)) Результат (a b c d)
(append ’(a (b)) ’((c))) Результат (a (b) (c))
(append ’(a b) ’(c . d)) Результат (a b c . d)
(append ‘() ‘a) Результат a, список был изменен.
(reverse list) – возвращает список, перераспределенный в обратном порядке.
(reverse ’(a b c)) Результат (c b a)
(reverse ’(a (b c) d (e (f)))) Результат ((e (f)) d (b c) a)
(list-tail list k) – возвращает список на основе списка list, но без k первых элементов. Входящий список должен содержать не менее k элементов. Работу list-tail можно выразить функцией-эквивалентом:
(define list-tail
(lambda (x k)
(if (zero? k)
x
(list-tail (cdr x) (- k 1)))))
(list-ref list k) – возвращает k-й элемент списка. В списке должно быть не менее k элементов.
Нумерация элементов списка осуществляется от нуля. Плюсом пар и неподходящих списков является возможность создания древовидных структур данных с неограниченным числом узлов (пока хватит памяти компьютера).
Символы
Это специальные объекты, особенность которых заключается в том, что символы считаются эквивалентными (для предиката eqv?), если получены одинаковым путем. Символы в частности могут представлять идентификаторы программы, и их уникальность дает возможность использовать их во внутреннем представлении программы. Правила образования символов полностью соответствуют правилам образования идентификаторов. Не следует путать данные символы (Symbols) с символами строки (Characters). Это символы программы и не предназначены для представления строк (хотя и могут быть конвертированы в строки). В частности символы можно получить, квотировав идентификаторы.
Следующий предикат подтверждает, все то, что сказано выше:
(symbol? obj) – определяет является ли объект символом.
(symbol? ’foo) Результат #t
(symbol? (car ’(a b))) Результат #t
(symbol? “bar“) Результат #f, строки представляются строковыми символами!
(symbol? ‘nil) Результат #t
(symbol? ‘()) Результат #f
(symbol? #f) Результат #f
(symbol? 5) Результат #f
(symbol? ‘5) Результат #f, это не идентификатор и не выражение
Для преобразования символов в строки используется
(symbol->string symbol)
Примеры:
(symbol->string ’flying-fish) Результат “flying-fish”
(symbol->string ’Martin) Результат “martin”
(symbol->string
(string->symbol ”Malvina”)) Результат “Malvina”
Здесь (string->symbol “Malvina“) выполняет обратную функцию.
(string->symbol “Привет“)
Символы, в частности, предоставляют программисту возможность работать с объектами программы через операции над их идентификаторами.
Строковые символы
Строковой символ – минимальная единица представления текстовой информации. Строковые символы можно образовывать так #\<character> или #\<character name>. Вот примеры образования строковых символов:
#\a; буква в нижнем регистре
#\A; буква в верхнем регистре
#\(; открывающая скобка
#\ ; пробел
#\space; пробел (образование строкового символа по его имени)
#\newline; символ перехода на новую строку
Поскольку Scheme во многом система, не зависящая от конкретной платформы, то получать константы строковых символов по кодам в какой-либо кодировке не допускается. Поэтому нельзя получить строковой символ #\13, в тоже время PLT Scheme позволяет получать символы национальных алфавитов и задать строковый символ #\й вполне допустимо. Для определения факта того, что объект является строковым символом, используется следующая функция:
(char? obj) – возвращает #t, если объект является строковым символом.
(char? ‘try) Результат #f, поскольку язык проводит четкую границу между символами и строковыми символами.
Все строковые символы определяются на основе их порядка следования в алфавите. Поэтому между строковыми символами существуют отношения, связанными с их расположением относительно друг друга. Для оценки строковых символов используется ряд функций:
(char=? char1 char2)
(char<? char1 char2)
(char>? char1 char2)
(char<=? char1 char2)
(char>=? char1 char2)
Сначала следуют цифры, потом прописные буквы, потом строчные (национальные символы «больше» латиницы). Кстати, PLT Scheme версии 350 допускает более двух символов для сравнения (на манер числовых предикатов).
(char-ci=? char1 char2)
(char-ci<? char1 char2)
(char-ci>? char1 char2)
(char-ci<=? char1 char2)
(char-ci>=? char1 char2)
Тоже самое, но без учета регистра.
(char-ci=? #\A #\a)
Результат #t. Аналогично, функции с приставкой –ci в PLT Scheme могут содержать больше чем два аргумента.
(char-alphabetic? char) – возвращает #t, если строковой символ буква.
(char-numeric? char) – возвращает #t, если строковой символ цифра.
(char-whitespace? char) – возвращает #t, если строковой символ пробел.
(char-upper-case? letter) – возвращает #t, если строковой символ буква в верхнем регистре.
(char-lower-case? letter) – возвращает #t, если строковой символ буква в нижнем регистре.
Несмотря на то, что задавать константы строковых символов их кодами нельзя, получать коды из строковых символов разрешено: (char->integer char) – вернет точное целое число, которому сопоставлен данный строковой символ. Обратная ей функция (integer->char n). Изменить регистр символов можно с помощью функций:
(char—upcase char) – изменяет регистр строкового символа на верхний
(char—downcase char) – изменяет регистр строкового символа на нижний.
Строки
Строки это последовательности символов. В Scheme строки выделяются кавычками. В строки допускается включать Escape-последовательности через использование обратного слеша (\). Например, если известны коды символов, то строку можно задать следующим образом: “\u65\u65” (чего нельзя делать для строковых символов). Длина строки есть число содержащихся в ней символов (точное целое неотрицательное число). Индексация символов начинается от нуля. Аналогично операций с символами все функции имеющие приставку –ci есть операции со строками без учета регистра. Начнем с определения строки:
(string? obj) – возвращает #t, в случае, если объект является строкой.
Существует два способа напрямую создать строку с помощью функций:
(make-string k)
(make-string k char)
Здесь, k – есть длина создаваемой строки, char – символ, которым должна быть наполнена строка (в первой функции она будет наполнена символами вида ”\u0000\u0000\u0000”). Также строки можно создавать путем конкатенации (объединении) символов:
(string char …)
Длина строки:
(string-length string)
Можно также получить доступ к каждому элементу строки (строковому символу):
(string-ref string k)
(string-ref “Привет” 1) Результат #\р, так как нумерация в строке идет от нуля
Изменить конкретный символ в строке можно с помощью: (string—set! string k char). При этом следует помнить, что string—set! возвращает неопределенное значение. Строки можно сравнивать (на порядок расположения в них строковых символов):
(string=? string1 string2)
(string-ci=? string1 string2)
(string<? string1 string2)
(string>? string1 string2)
(string<=? string1 string2)
(string>=? string1 string2)
(string-ci<? string1 string2)
(string-ci>? string1 string2)
(string-ci<=? string1 string2)
(string-ci>=? string1 string2)
PLT Scheme разрешает использовать более двух аргументов при сравнении строк.
(string=? “12″ “15″ “gsjfds”) Результат #f
При этом более короткие строки считаются меньше длинных:
(string-ci<? “fff” “ffff”) Результат #t
Выделение подстроки:
(substring string start end)
При этом входящие параметры должны удовлетворять условию:
0 < start < end < (string-length string)
Объединение (конкатенация) строк:
(string—append string …)
(string—append “Привет ” “Мир!”) Результат “Привет Мир!”
Также важны функции преобразования строк:
(string->list string) – преобразование строки в список строковых символов
(list->string list) – преобразование списка в строку (список должен быть списком строковых символов)
(string->list string) и (list->string list) являются противоположными по отношению друг к другу.
(string-copy string) – возвращает копию строки
Векторы
Векторы в Scheme есть неоднородные структуры данных индексированные целыми числами. Одним из плюсов векторов является организация, построенная таким образом, что скорость доступа к ним выше, чем к спискам. Длина вектора есть число элементов, которые он содержит (целое точное неотрицательное число, также как и индекс любого из доступных элементов вектора). Индексация элементов вектора начинается от нуля. В общем, векторы сильно похожи на массивы императивных языков программирования, но имеют одну приятную особенность – вектор может содержать данные различных типов.
Для записи векторов используется следующая нотация: #(obj …).
#(0 (2 2 2 2) ”Anna”) Вектор, состоящий из трех элементов – числа нуль, списка (2 2 2 2) и строковой константы ”Anna”.
(vector? obj) – определяет, является ли объект вектором (#t если объект вектор).
(make—vector k) – создает вектор из k элементов, сами элементы не определены.
(make—vector k fill) – создает вектор из k элементов, элементы которого являются fill.
(vector obj …) – создает вектор из указанных объектов.
(vector ‘a ‘b ‘c) Результат #(a b c), сами элементы при этом не вычисляются (из-за одинарной кавычки).
(vector-length vector) – возвращает длину вектора (точное целое число).
(vector-ref vector k) – возвращает k-тый элемент вектора (k как и все индексы должен быть точным и целым).
(vector-ref ’#(1 1 2 3 5 8 13 21) 5) Результат 8 (нумерация от нуля).
(vector—set! vector k obj) – присваивает k-тому элементу вектора значение obj. Результат не определен, функция обладает побочными эффектами.
(vector->list vector) – создает список из вектора.
(list->vector list) – создает вектор из списка.
(vector->list ’#(dah dah didah)) Результат (dah dah didah)
(list->vector ’(dididit dah)) Результат #(dididit dah)
(vector-fill! vector fill) – заполняет указанный вектор объектами fill. Результат функции не определен, функция имеет побочные эффекты.
Особенности управления
Здесь мы опишем некоторые (не все, например, отложенные вычисления уже рассматривались) механизмы, облегчающие управление процессом выполнения.
(procedure? obj) – возвращает #t, в случае если перед нами процедура. Надо отметить, что в Scheme очень часто идет слияние понятий функция и процедура.
(procedure? car) Результат #t
(procedure? ’car) Результат #f
(procedure? (lambda (x) (* x x))) Результат #t
(procedure? ‘(lambda (x) (* x x))) Результат #f
(apply proc arg1 … args) – вызывает указанную функцию к аргументам заданным списком.
(apply + (list 3 4)) Результат 7, для функции + (плюс) задается параметр (только один), заданный в виде списка.
(map proc list1 list2 …) – применение функции proc к каждому из списков. Списки должны иметь одинаковый размер. Одна из мощнейших функций языка. Работает это следующим образом:
(map car ‘((a b) (d e) (g h))) Результат (a d g)
(map cdr ‘((a b) (d e) (g h))) Результат ((b) (e) (h))
(map cadr ‘((a b) (d e) (g h))) Результат (b e h)
Функция всегда работает со списками и списки же и возвращает. Эти примеры не полностью раскрывают работу функции, вот еще примеры:
(map + ’(1 2 3) ’(4 5 6)) Результат (5 7 9)
(map + ‘(1 2 3) ‘(4 5 6) ‘(7 8 9)) Результат (12 15 18)
(define my-list ‘(1 2 3 4 5))
(define (square val) (* val val))
(map square my-list) Результат (1 4 9 16 25)
(for—each proc list1 list2 …) —
аналогична map, но используется в основном для функций с побочными эффектами, результат которых не определен.
(let ((v (make-vector 5)))
(for-each (lambda (i)
(vector-set! v i (* i i)))
‘(0 1 2 3 4))
v)
Результат #(0 1 4 9 16). Создаем вектор v из пяти элементов. Затем применяем (lambda (i) к вектору v. Заносим данные из списка ‘(0 1 2 3 4) (который сразу не вычисляется из-за одинарной кавычки) следующим образом: в вектор v записывается элемент списка, умноженный сам на себя (запись осуществляется посредством vector—set!, при этом в качестве индексов для доступа к вектору используется все тот же список ‘(0 1 2 3 4)). После выхода из блока let вектор v будет разрушен, а его содержимое будет передан как результат работы блока let.
PLT Scheme
Теперь немного подробней о самой IDE. PLT Scheme состоит из нескольких компонентов:
. MrEd – расширение MzScheme для графического программирования
. DrScheme – среда проектирования
. Mzc – компилятор в байт-код, не зависимый от платформы (позволяет создавать переносимые приложения)
. MzScheme3m – экспериментальная версия MzScheme, особенность которой более точное управление распределением памятью (в сравнении MzScheme).
MzScheme, основной компилятор, интерпретатор, и система поддержки исполнения программ. Кроме того, PLT Scheme, содержит в себе не только описанный выше стандарт R5RS, но также дополнительные возможности, а именно:
. система поддержки пространства имен и управления трансляцией
. поддержка механизма исключений
. приоритетные потоки
. классы и система объектов
. регулярные выражения
. расширенная поддержка макросов
. поддержка хэшей (как встроенного типа данных)
. поддержка юникода.
И более того, PLT Scheme содержит также группу диалектов Scheme, каждый из которых имеет свои задачи (например, есть диалект специально адаптированный для изучения функционального программирования студентами высших учебных заведений). Так как система построена в минималистичном и строгом стиле рекомендуется начинать изучение с DrScheme (он не так суров, и не сильно отпугивает пользователей привыкших к обилию кнопок, картинок и иконостасу на Рабочем столе). Его-то мы и рассмотрим подробней.
Как уже упоминалось ранее, DrScheme имеет два окна, одно предназначено для ввода текста программы, второй есть командный интерпретатор (команды, введенные в него, исполняются немедленно, что удобно для изучения языка). В последнее же окно выводится и сообщения от drScheme, именуемое как главная текстовая область (см. рисунок 1):
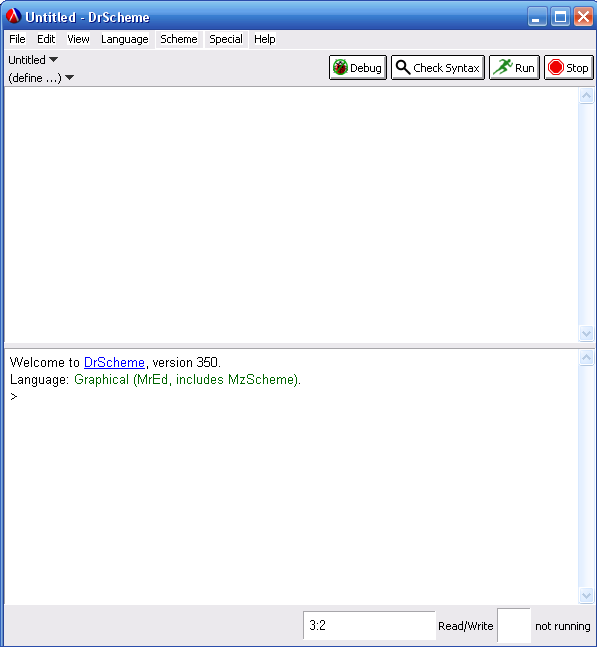
Рис. 1. Среда drSheme
Поскольку PLT Scheme поддерживает несколько языков программирования, то прежде чем приступить к работе, нужно выбрать* соответствующий язык программирования Language|Choose Language (см. рисунок 2):
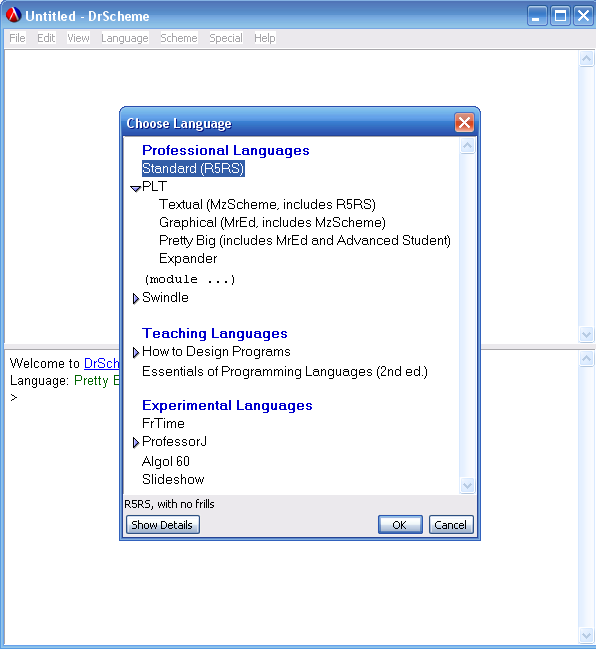
Рис. 2. Выбор языка
* Комментарий автора
наименование пунктов меню может немного отличаться в зависимости от версии среды разработки
Стандарт языка называется Standart (R5RS), для освоения материала статьи его вполне достаточно. Остальные диалекты отличаются различными свойствами, в том числе и поддержкой графического интерфейса пользователя. PLT Scheme запоминает последний выбранный диалект и при следующем запуске сразу же готов работать в выбранном контексте.
Изюминкой PLT Scheme является возможность компиляции текстов программ. Исторически и по ряду объективных причин большинство реализаций Scheme есть интерпретаторы. Однако готовые к употреблению программы без стороннего окружения также необходимы (что, кстати, требуют и решаемые задачи, круг которых гораздо шире в PLT Scheme, чем в голом стандарте R5RS). Чтобы получить из текста программы на языке Scheme вполне функциональный exe-файл требуется, чтобы программа была введена в окно ввода программы (обычно оно первое) (см. рисунок 3). А также чтобы она была уже сохранена во внешнем файле.
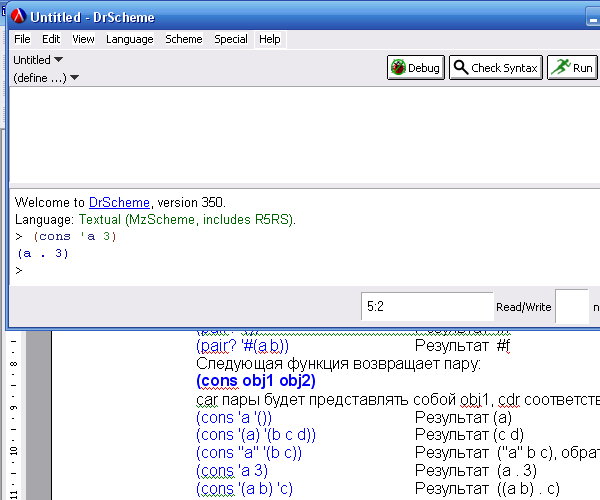
Рис. 3. Работа с примером
Затем выбираем пункт меню Scheme|Create Executable… Далее необходимо выбрать тип исполнения файла (см. рисунок 4):
. Launcher
. Stand-alone
. Distribution.
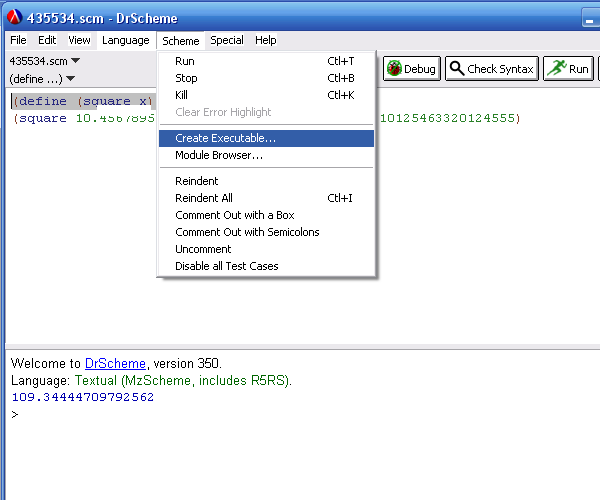
Рис. 4. Создание исполняемого файла
Для простых учебных примеров Stand—alone вполне достаточно (однако, если необходимо использовать программу на другом компьютере, то потребуется перетащить некоторые библиотеки).
Заключение
Введение дает только элементарные азы и рассчитано на плавный переход от императивного стиля к функциональному. Данное введение не дает представления о функциональном программировании – это просто справочник наиболее распространенных команд языка Scheme, также знакомство с конкретной средой разработки PLT Scheme. Более полное и подробное руководство по PLT Scheme можно найти на сайте проекта (на английском языке), статья предназначена быть отправной точкой для дальнейшего самостоятельного обучения. Дополнительно можно отметить возможность встраивания Scheme и в другие языки программирования (как встроить Scheme в Дельфи, можно узнать здесь: http://www.orlovsergei.com/Progs/Scheme/SchemeToDelphi.htm). Плюсы такого союза очевидны, например, это удобно для работы с длинной арифметикой.
Ресурсы
. Лисп как альтернатива Java http://alexey.tamb.ru/scheme/lisp-scheme-java.html
. Сайт «схемщиков» http://schemers.org
. PLT Scheme http://www.plt-scheme.org
. Дополнительные библиотеки для PLT Scheme http://planet.plt-scheme.org
. Неформальное введение в Scheme http://ru.wikibooks.org/wiki/Введение_в_язык_Scheme_для_школьников
19th
MP3 изну-три

В этой статье я расскажу, как устроен MP3 файл, и покажу, как можно работать с ним в ваших программах. Мы попробуем извлечь информацию о файле, такую как длину трека, его битрейт и частоту дискретизации. Воспроизведение звука мы рассматривать не будем, это отдельная, и я думаю намного более сложная тема…
Александр Терлецкий
by mutabor altair.79@mail.ru
Немного про формат
MP3 расшифровывается как MPEG 1 Layer 3, т.е. MPEG версии 1, третья редакция, или как-то в этом роде. Нам важно понять, что бывает еще MPEG 2, а Layer не обязательно может быть третьим. Что такое MPEG, почему Layer 3, чем отличается MPEG1 от MPEG2, и прочие подобные вопросы я рассматривать не буду, т.к. это само по себе тянет на отдельную статью. MP3 это сжатый формат, сжатие достигается за счет убирания из исходного звука частот заведомо не слышимых человеком, ну и еще за счет алгоритма сжатия какого-нибудь (это я тоже не буду здесь рассматривать). Именно поэтому сжимать архиваторами MP3 файлы не получается (вернее получается, но результат не впечатляет), они уже сжатые. Внутри файл состоит из фреймов. Заголовка у MP3 файла нет, зато у каждого фрейма есть свой заголовок, с ним то мы и будем в основном работать. Фрейм можно рассматривать, как некий дискретный кусок звукового потока.
Теги
Помимо фреймов, в файле могут быть один или несколько ID3 тегов. ID3 – это теги специально разработанные для формата MP3, т.к. он сам не содержит никакой описательной части. Теги бывают разных версий, чаще всего это или ID3v1.x или ID3v2.x. Теги первой версии находятся в последних 128 байтах файла, начинаются с символов TAG (такой тег может занимать и более чем 128 байт, но это редко, это усовершенствованная первая версия ID3). Теги второй версии могут находиться в любой части файла, но чаще они располагаются в начале файла, и начинаются с символов ID3. Теги второй версии намного более расширенные, чем теги первой версии, в них нет ограничений на длину полей с описанием трека, количество доступных полей намного больше, можно использовать Юникод, тег может содержать в себе изображение. Длина тега второй версии не фиксированная, и определяется по заголовку тега (в отличие от MP3 файла, у ID3v2 тега есть заголовок). Наличие тегов в файле не является обязательным, и их может не быть совсем, а могут быть оба, и тег первой версии в конце файла, и второй в начале, это делается в целях совместимости с большим количеством плееров. Часто возникает проблема с русскими символами в тегах в плеерах мобильных телефонах, я думаю это связано с Java машиной в телефоне, дело в том, что она поддерживает строки в формате UTF-8, а русские теги часто имеют кодировку Win-1251. Чтобы избежать «козябриков» на этих устройствах, нужно сохранять теги в Юникоде.
Теперь немного о том, как читать теги программно. Я не буду подробно освещать эту тему здесь, скажу лишь, что существуют библиотеки, компоненты для их чтения, также в сети доступна спецификация на эти теги, так что можно и самому написать их обработку, если есть желание. Звуковые движки, например тот же BASS, тоже умеют читать теги. Они кстати умеют и все остальное, о чем я буду писать ниже, и если ваша задача – получить информацию о файле, и вам не интересно как он устроен, можете в принципе дальше не читать, так как через интерфейс движка это сделать намного легче. Если вам звук нужно еще и воспроизводить, то этот способ даже лучше, зачем ковыряться в спецификациях, если есть удобный инструмент. Но бывают случаи, когда звук воспроизводить не надо, а нужна только информация о файле, и тогда лучше подключить легкий модуль, чем таскать движок за программой.
Битрейт
В этой статье я затрону только те характеристики, которые мы будем читать из файла, остальную общую информацию об MP3 можно без проблем найти в Интернете, ее достаточно, в отличие от более специализированной информации о формате.
Как вы все, наверное, знаете, MP3 файл может иметь различный битрейт, это кол-во бит выделенных на кодирование звука в единицу времени. Понятно, что чем он выше, тем качество звука лучше, и размер файла соответственно тоже больше. Значение битрейта в MP3 может находиться в пределах от 8 до 320 кбит/с. Полный список смотрите в Рис 2. Битрейт может быть постоянным (constant) и переменным (variable), это обозначается аббревиатурами CBR и VBR соответственно. Переменный битрейт позволяет снизить размер файла, не снижая качества. Это достигается за счет того, что на участках, где это не требуется, например тишина в начале трека, используется меньшее количество бит для кодирования. На уровне структуры файла это выражается в том, что один фрейм может иметь битрейт, например 128, а следующий может иметь уже 192, и т.д. В каждом отдельном фрейме битрейт имеет значение кратное степени двойки, соответствующее спецификации (см. рисунок 2). В целом по файлу, битрейт, в случае если он постоянный, не будет отличаться от значения битрейта первого фрейма, таким образом, нам достаточно взять информацию из первого фрейма, и мы имеем информацию о файле. В случае если битрейт переменный, то все усложняется, нам недостаточно одного фрейма, чтобы делать выводы об общем битрейте файла.
Частота дискретизации
Вторая характеристика, которую мы рассмотрим, это частота дискретизации или Sample Rate. Это частота, с которой при кодировании звука снимаются замеры с источника звука. Например, если частота у нас 44100 Гц, то это значит, что столько раз в секунду снимаются и сохраняются значения оригинального, аналогового звука. По сути, оцифровка. Можно конечно и уже оцифрованный звук перегнать с другим сэмпл-рейтом, но качество можно только понизить, повысить уже вряд ли удастся. Как и в случае с битрейтом, от частоты дискретизации напрямую зависит качество звука. Частота дискретизации в MP3 не может варьироваться, и всегда постоянна для всего файла.
Длина
У любой музыкальной композиции или любой другой звуковой записи есть такая характеристика, как длина. Упоминаю я ее отдельно для того, чтобы обрадовать вас, что так как у MP3 файла общего заголовка нет, то и готовые сведения о длине нам взять в принципе неоткуда (ID3 тег не в счет, в нем может быть длина трека, а может и не быть, а может и самого тега не быть). Поэтому длину нам придется высчитывать самостоятельно. На этом с характеристиками закончим и перейдем к разбору фреймов.
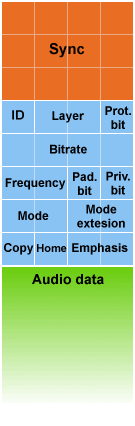
Рис. 1.
Фреймы
Один фрейм состоит из двух блоков (последовательностей бит) – заголовка и блока данных (см. рисунок 1). Заголовок представляет собой последовательность из 32 бит (4 байта), в которых описываются все необходимые параметры звука, а также параметры самого фрейма (например, его длина). В блоке данных находиться непосредственно звуковые данные. Рассмотрим заголовок подробнее (см. рисунок 2). Вначале идут 12 бит сигнатуры (Sync), по этим битам нужно искать фреймы, все они установлены в единицу. Затем идут еще три бита: версия, слой и защита от ошибок. Я сделал вывод, что если принять по умолчанию что мы работаем с MP3 файлом, а не с какой-нибудь другой версией MPEG, томожно брать первые два байта как сигнатуру, в этом случае они могут иметь всего две комбинации: FF FA или FF FB. Мне показалось так удобнее искать фреймы, и именно так я реализовал это в коде. Через третий байт мы пока перескочим, и я вкратце расскажу о четвертом. В нем есть такая интересная штука как режим стерео. Дело в том, что MP3 имеет еще оди н способ уменьшить вес файла, не ухудшив качество. Это режим Joint Stereo (объединенное стерео). Что же это такое? Пройдемся по порядку. Режим моно, это, как вы знаете, когда всего один звуковой канал. Стерео — это независимые левый и правый каналы. Для хранения стерео данных, необходимо ровно в два раза больше места, чем для моно. Joint Stereo же позволяет хранить два независимых канала, при этом, занимая меньше места, это достигается за счет «умной» паковки во время сжатия. Если выбран этот режим, и в данном сэмпле звука левый и правый каналы не отличаются, то кодер сохраняет только один из них, когда же каналы отличаются, то они сохраняются оба. Это в своем роде стерео по требованию, оно используется там, где это реально нужно, а где не нужно, место экономится. В четвертом байте хранится еще ряд параметров, не буду на них останавливаться, кому интересно, смотрите на рисунке, там все подписано, обычно они интереса не представляют.
Самый значимый для нас это 3-й байт заголовка. В нем содержится информация о битрейте, частоте дискретизации, установлен или нет Pad бит (определяет наличие добавочного байта в фрейме), все это вместе взятое позволяет нам высчитать размер этого фрейма. Размер фрейма высчитывается по формуле 1:
144 * BitRate / SampleRate + Pad; (1)

Рис. 2.
Если Pad бит равен единице то и в формулу подставляем единицу, если нулю – подставляем нуль. Битрейт и частоту подставляем в их полном виде, без округлений, битрейт в битах, а частоту в герцах. В файлах к этой статье вы найдете пример извлечения нужной информации из заголовка фрейма и реализацию этой формулы на языке Delphi. Чтобы что-то извлечь из заголовка, его нужно сначала найти, это тоже там есть. На самом деле достаточно найти первый фрейм, позицию каждого следующего мы уже будем знать, прибавляя к позиции текущего фрейма его длину.
Теперь поговорим о том, как найти переменный битрейт и длину трека. С постоянным битрейтом все ясно, он одинаковый для всего файла, и его можно взять из первого фрейма. С переменным не так. Во-первых, нигде не написано что он переменный, и чтобы это определить, нужно прочесть больше чем один фрейм. Я пошел самым простым путем, и читаю два первых фрейма. Если битрейт у них одинаковый я считаю что битрейт постоянный, если разный то переменный. Это скорее всего не точно, ведь переменным он может стать и после второго фрейма. Однозначных рекомендаций по этому вопросу я не встречал, возможно, есть соглашение, что если битрейт переменный, обязательно кодировать первые два фрейма с различным битрейтом, я бы так и сделал на месте разработчиков, но это только мои предположения. Если у вас есть более точная информация на этот счет, оставляйте комментарии к статье на сайте журнала, интересно будет почитать. Понятно, что в случае переменного битрейта необходимо как-то высчитать его среднее значение по всем фреймам. Оставлю это вам, у меня в коде в этом месте стоит заглушка, т.е. просто в случае переменного битрейта, в качестве его значения присваивается ноль.
Заключение
Теперь про длину трека. Ее можно высчитать, поделив размер файла (за вычетом тегов и прочего мусора, нужны только фреймы, не совсем ясно только, включать заголовки или нет) на битрейт, если он постоянный. Таким образом, мы получим длину трека в секундах. Если битрейт переменный, этот способ не подходит (хотя можно на усредненный битрейт поделить), тогда мы можем задействовать сэмпл-рейт, он у нас постоянный для всего файла, и представляет собой кол-во сэмплов в секунду. Если предположить что сэмпл и фрейм это одно и то же, то можно узнать количество секунд в треке, посчитав все фреймы. Я не пробовал ни тот, ни другой способ, не буду портить вам удовольствие и позволю самим попробовать высчитать длину трека. Если что интересное получится, пишите в комментариях. Опять же, можно переменный битрейт считать от обратного, найти по сэмпл- рейту длину, и потом уже одним действием найти средний битрейт.
Все исходные коды, упомянутые в статье, приложены непосредственно к журналу «ПРОграммист. Пятый выпуск».
На этом закончим, спасибо за внимание, читайте наш журнал.
Статья из пятого выпуска журнала «ПРОграммист».
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
17th
Авг
Microsoft предупреждает о случаях эксплуатации новой бреши в Windows XP/Vista/7
Microsoft предупреждает о случаях эксплуатации новой бреши в Windows XP/Vista/7 связанную с инфицированными USB-накопителями. В описании, размещенном на сайте Microsoft, говорится, что хакеры используют данную уязвимость уже около месяца. Уязвимость проявляется
в том, что ОС Windows обычно работает с файлами-ярлыками, которые традиционно размещаются на Рабочем столе или в меню Пуск системы и как правило эти ярлыки указывают на конкретные локальные файлы или программы.
Методика заражения
Вы должны принять во внимание, что этот вирус заражает систему необычным путем (без файла autorun..inf), через уязвимость в lnk-файлах. Так вы открываете зараженную флешку с помощью проводника или другого менеждера способного отображать иконки (например TotalCommander) и запускаете вирус, компьютер заражен. Ниже на скриншоте вы можете увидеть содержимое флешки FAR (он не заражает систему):

На скриншоте вы можете видеть что в корне USB-устройства располагаются два tmp файла (на самом деле они приложения) и 4 файла lnk. Следующий скриншот демонстрирует содержимое lnk файлов

Операционная система Windows 7 Enterprise Edition x86 со всеми последними обновлениями также уязвима, из чего следует вывод что уязвимость присутствует и в предыдущих версиях.
Процесс заражения и скрытия в системе
Процесс заражения развивается по следующему пути:
1. Два файла (mrxnet.sys и mrxcls.sys, один из них действует как драйвер-фильтр файловой системы, а второй включает в себя вредоносный код) располагаются в директории %SystemRoot%\System32\drivers. Ниже представлен скриншот программы GMER отображающей вирусные драйверы.
Данные драйверы подписаны (имеют цифровые подписи) Realtek Semiconductor Corp. Файлы mrxnet.sys и mrxcls.sys также добавлены в вирусные базы VirusBlokAda как Rootkit.TmpHider
(http://www.virustotal.com/ru/analisis/0d8c2bcb575378f6a88d17b5f6ce70e794a264cdc8556c8e812f0b5f9c709198-1278584497) и Scope.Rookit.TmpHider.2 (http://www.virustotal.com/ru/analisis/1635ec04f069ccc8331d01fdf31132a4bc8f6fd3830ac94739df95ee093c555c-1278661251) соотвественно.
2. Два файла (oem6c.pnf и oem7a.pnf, содержимое которых зашифровано) располагаются в папке %SystemRoot%\inf .
Вирус запускается сразу после заражения, так что перезагрузка не требуется.
Драйвер-фильтр скрывает файлы ~wtr4132.tmp и ~wtr4141.tmp и соответствующие lnk файлы. Поэтому пользователя не заметят новый файлах на USB-устройстве. . Vba32 AntiRootkit (http://anti-virus.by/en/beta.shtml) детектирует вирусные модули свежующим образом:
3. Также руткит добавляет потоки в системные процессы, и в тоже время прячет модули которые запускаются в потоках. Антируткит GMER фиксирует следующие аномалии:
4. Руткит устанавливает ловушки в системных процессах
Предпосылки эксплуатации уязвимости:
Успешность эксплуатации уязвимости и последствия зависят от конфигурации вашего компьютера:
• Атакующий, который успешно поэксплуатировал уязвимость получает права того локального пользователя под чьей учетной записью производилась эксплуатации. Пользователи сидящие под ограниченной четкой понесут меньший урон, чем те что имеют права администратора.
• Когда автозапуск выключен, пользователя самому придется открыть проводником или другой программой корень переносного устройства (флешки).
• Закрыв доступ к сетевым папкам с помощью фаервола вы предотвратите риск эксплуатации уязвимости через расшаренные ресурсы.
Защита
Данные советы не исправят уязвимость, но они помогут снизить риск успешность эксплуатации уязвимости до времени выхода заплатки. Майкрософт протестила данные советы и ответственно заявляет что они помогают.
• Отключение отображения иконок ярлыков
1. Пуск- Выполнить, в открывшемся окошке написать Regedit, нажать ОК.
2. Пройти в данную ветку реестра
HKEY_CLASSES_ROOT\lnkfile\shellex\IconHandler
3. Щелкните File (Файл) в меню и выберите Export (Экспорт)
4. В окне экспорта введите LNK_Icon_Backup.reg и нажмите Save (Сохранить)
Этими действиями вы создали резервную копию ключей реестра.
5. Выберите параметр Default в правой стороне окна Редактора реестра. Нажмите Enter чтобы отредактировать значение. Удалите значение, т.е. поле станет пустым, нажмите Enter.
6. Перезапустите процесс explorer.exe или перезагрузите компьютер.
Проверка результата. Отключение иконок на ярлыках защитит от эксплуатации уязвимости на уязвимой системе. Когда вы проделаете эти действия то иконки ярлыков и IE перестанут отображаться.
• Отключение службы WebClient.
Отключение службы WebClient поможет защитить уязвимую систему от атаки путем блокирования удаленной атаки через сервис Web Distributed Authoring and Versioning (WebDAV). После произведения данных действий, останется возможность для удаленной атаки и успешной эксплуатации уязвимости связанной с Microsoft Office Outlook и запуском программ на атакуемой машине пользователей сети (LAN), но при этом пользователь получит предупреждение о попытке запуска программ из интернет.
Для выключения службы WebClient воспользуйтесь следящими пунктами:
1. Пуск-Выполнить, впишите Services.msc и нажмите ОК.
2. Правой кнопкой щелкните по службе WebClient и выберите свойства.
3. Измените тип запуска на Отключено. Если эта служба запущена, то нажмите Стоп (остановить) .
4. Нажмите ОК и закройте приложение.
Проверка результата. Когда вы отключите службу WebClient, престанут посылаться запросы Web Distributed Authoring and Versioning (WebDAV), и любая служба зависящая от WebClient также не будет запускаться. Пока в корпорации не говорят, когда будет выпущено исправление. Пока же же пользователи могут защищаться путем отключения отображения ярлыков на съемных носителях или за счет отключения сервиса WebClient. Оба метода выполняются через реестр Windows.
Интересные факты с пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
17th
Каждому российскому участковому – личную страничку в Интернет
 Каждый российский участковый обзаведется личной интернет-страничкой, где будут размещены его персональные и контактные данные. За счет «интернетизации» участковых МВД хочет повысить качество обратной связи между населением и милицией. Однако за счет каких средств будут созданы более 54 тыс. сайтов, пока не понятно.
Каждый российский участковый обзаведется личной интернет-страничкой, где будут размещены его персональные и контактные данные. За счет «интернетизации» участковых МВД хочет повысить качество обратной связи между населением и милицией. Однако за счет каких средств будут созданы более 54 тыс. сайтов, пока не понятно.
В России под лозунгом «Безопасность начинается с доверия» стартовала акция, в рамках которой каждый участковый уполномоченный милиции обязан будет завести собственную интернет-страницу. На персональном сайте участкового будет размещена информация о нем самом: его фотография, биография, контактные данные. Кроме того, на сайте появятся данные о курируемых участковым районах, часах приема и контактах руководства и надзорных органов, фото людей, находящихся в розыске или пропавших без вести, и другого рода полезная информация.
Такие сайты будут содержать интерактивные разделы, где граждане смогут задать участковому вопрос. Появится и раздел «Добровольный помощник», где можно будет сообщить о правонарушении, в том числе и анонимно. По задумке МВД, создание персональных сайтов для участковых должно простимулировать социальную активность граждан.
Сегодня в России работают более 54 тыс. участковых. Согласно рекомендации МВД, в городах участковый инспектор должен обслуживать 4—5 тыс., в сельской местности — 3—4 тыс. человек. В настоящий момент средняя зарплата участкового составляет 12 тыс. руб. В ходе реформы МВД к 2012 году ее планируется увеличить втрое.
Средняя стоимость создания простенького сайта в Москве составляет около 10 тыс. руб. Таким образом, только на первоначальный этап «интернетизации» корпуса участковых понадобится более 540 млн руб. Плюс немалые средства потребуются для дальнейшей поддержки сайтов. Где министерство возьмет более чем полмиллиарда рублей, источник РБК daily в МВД ответить затруднился: «Возможно, это будет происходить постепенно, пока же таких средств нигде не заложено». Получить официальный комментарий в МВД не удалось.
«Идея очень здравая, ведь сегодня своего участкового знают в лицо только гиперактивные бабушки, — считает юрист Альберт Феоктистов. — Количество пользователей Интернета постоянно множится, особенно в больших городах, и многие уже привыкли за любой информацией обращаться в Сеть. Такие сайты позволят гораздо большему количеству граждан узнать своего участкового».
Интересные факты с пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
14th
Июл
Энкодер датчика PDF на ПЛИС. Часть 1
![]()
Данная статья рассчитана в помощь программистам и инженерам-разработчикам в области промышленной автоматизации и АСУТП. Поскольку материал объемный, то было решено разделить статью на части, в первой рассмотрим схемотехнику и конструктив модулей передачи и приема сигналов с датчиков приращений, алгоритм работы энкодера, а в остальных – его реализацию на ПЛИС, методику программирования и непосредственно практическое создание тестовой утилиты визуализации состояний датчика приращений…
Сергей Бадло
by raxp http://raxp.radioliga.com
Каждый компонент системы не должен быть наилучшим, а ровно таким, чтобы обеспечить требуемый уровень функционирования всей системы… / принцип системотехники
Для передачи импульсных сигналов с датчика приращений на относительно большие расстояния в условиях промышленных помех можно использовать как радиоканал, так и проводной вариант*, к примеру, дифференциальные интерфейсы на основе RS- 485 и LVDS. Реализация радиоканала и RS-485 видится избыточной, так как необходимо наличие «упаковщика» как минимум трех сигналов с шифратора приращений (A, B и строба), т.е. наличие контроллера. Как обойти эту проблему?
Список сокращений, использованных в статье:
PDF – датчик углового положения,
EEPROM – перепрограммируемая ПЗУ,
ПЛИС – перепрограммируемые логические матрицы с сохранением памяти CPLD и без сохранения FPGA (работа схемы ограничивается наличием питающего напряжения),
ТИ – тактовые импульсы,
LVDS (Low-Voltage Differential Signaling) – интерфейс передачи информации дифференциальными сигналами малых напряжений,
Шифратор приращений – преобразователь, на выходе которого в цифровой форме представляются воспринимаемые ими перемещения. Различают* поворотные и абсолютные шифраторы.
Краткий экскурс…
Вспомним про формат LVDS. LVDS используется в таких компьютерных шинах как FireWire, USB 3.0, PCI Express, DVI, Serial ATA. Но среди прочего, данный интерфейс получил распространение и для передачи сигналов на больших скоростях на расстояния до сотни метров. Да, именно так, уже существуют и такие LVDS драйверы. Кроме того, сигналы с шифратора приращений необходимо декодировать и привести в удобоваримый вид. А значит, возникает необходимость создания аппаратного энкодера для определения таких параметров как: положение ротора, направление вращения, обрыв в канале и т.п.

Рис. 1
Для реализации алгоритма энкодера видится два пути:
- Использование микроконтроллера
- Использование ПЛИС
Хороши оба варианта. Но для меня как разработчика более удобен вариант представления в виде схемы. Достоинства программируемых логических интегральных схем (ПЛИС) хорошо известны, это и наличие множества готовых библиотек от простейших логических элементов до микропроцессоров и возможность многократного перепрограммирования для изменения схемы, без внесения изменений в печать, и наличие си- подобного языка VHDL и возможность просто нарисовать поведение схемы. Хотя последние вряд-ли можно назвать преимуществами, так эти свойства присущи и микроконтроллерам…
Таким образом, задачу разработки энкодера для шифраторов приращений можно разбить на следующие этапы:
- Разработка модуля связи (передачи и приема) для передачи импульсных сигналов на большие расстояния в условиях промышленных помех
- Аппаратная реализация алгоритма энкодера на существующих ПЛИС
- Создание тестовой программы визуализации состояния датчиков приращений
Практика. Реализация модуля передачи и приема сигналов с шифратора приращений
Дифференциальный метод передачи используется в LVDS, поскольку обладает меньшей чувствительностью к общим помехам, чем простая однопроводная схема. Применение источников сигнала с дифференциальным токовым выходом и приемников с низкоомным дифференциальным входом (см. рисунок 2) обеспечивает минимальные индуктивные наводки, поскольку информация передается в форме тока, а емкостная наводка мала, так как при хорошей симметрии линии передачи она является синфазной и подавляется входным дифференциальным приемником. Дополнительной защитой линии является ее экранирование.
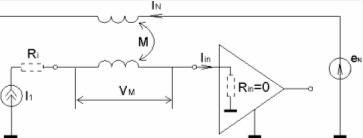
Рис. 2. Канал передачи сигнала с помощью тока нечувствителен к индуктивным наводкам
Поскольку дифференциальные технологии, в том числе и LVDS, менее чувствительны к шумам, то в них возможно использование меньших перепадов напряжения, до 350 мВ. что позволяет по сравнению с другими способами передачи сигналов значительно снизить потребляемую мощность. Например, статическая мощность, рассеиваемая на нагрузочном резисторе LVDS, составляет всего 1.2 мВт, по сравнению с 90 мВт, рассеиваемыми на нагрузочном резисторе интерфейса RS-422. На рисунке 3 представлена схема организации канала связи между шифратором приращений и контроллером энкодера с использованием дифференциальных линий передачи:
* Комментарий автора.
Поворотные шифраторы – генерируют выходные импульсы, которые подсчитываются реверсивным счетчиком, поэтому их показания соответствуют тому, как далеко диск продвинулся с начала отсчета. Здесь в основном применяются два чувствительных элемента, расположенных в преобразователях таким образом, что их выходы сдвинуты относительно друг друга на 90° по фазе.
Абсолютные шифраторы – реализуют кодированный выход, который индицирует абсолютное положение контролируемого объекта, причем кодирование производится в двоичном коде, а его длина соответствует длине кода измерительной системы. Как правило, снабжены интерфейсами: SSI (Synchronous Serial Interface), СAN, PROFIBUS, RS-485.
** Комментарий редакции.
Следует упомянуть про параллельно-последовательные преобразователи со встроенным антидребезгом и нормализацией сигналов цифровых входов и преобразования их в единый поток данных, передаваемый по SPI интерфейсу. К примеру, ИМС SN65HVS88x от Texas Instruments. Однако это потребует минимум еще трех корпусов со стороны передатчика и приемника, что приведет к удорожанию модуля связи. Да и сам интерфейс SPI не предназначен для таких расстояний. Кроме того, существуют кодеры на основе сдвигающих регистров (НТ12Е/НТ12D или MC145026/28). Но их применение оправдано в случае использования радиоканала.

Рис. 3. Схема организации канала передачи сигналов энкодера
Заданным условиям удовлетворяют нижеприведенные схемы (см. рисунок 4 и 5) на основе дифференциальных приемо-передатчиков сигнала LVDS формата SN65LVDS31 и SN65LVDS32 фирмы Texas Instruments [1].
Модуль связи энкодера конструктивно состоит из двух модулей: передачи и приема, разнесенных в пространстве. Модуль передачи размещается рядом с энкодером, а модуль приема непосредственно около контроллера энкодера.
Плата модуля передачи имеет в своем составе:
- узлы согласования входного уровня для типов датчиков приращений с открытым коллектором или потенциальным выходом
- узел формирования питающего напряжения 3.3В для ИМС дифференциального передатчика – U1
- дифференциальный передатчик с согласующими сопротивлениями – U2
- клеммник для подключения входных сигналов с датчика приращений – X1
- клеммник выходных сигналов – X2
Плата модуля приема включает:
- дифференциальный приемник с согласующими сопротивлениями – U1
- узел формирования питающего напряжения 3.3В для ИМС дифференциального приемника с гальванической развязкой – U2
- узлы согласования выходного уровня по типу СК или открытый коллектор
- клеммник для подключения входных сигналов с линии связи – X1
- клеммник выходных сигналов для энкодера – X2
Конструктив модуля связи
Платы модулей [3], габаритами 100х85 мм, выполнены из стеклотекстолита и разведены в пакете OrCad (см. рисунки 6 и 7). На плате передатчика перемычки X1…X4 (PLS-2) предназначены для конфигурации платы под датчики с открытым коллектором и потенциальным выходом. Суппрессоры D7…D10 служат для ограничения входных уровней и дополнительной защиты входных цепей микросхемы дифференциального передатчика U9. R21…R24 обеспечивают согласование длинной линии на основе витых пар***.
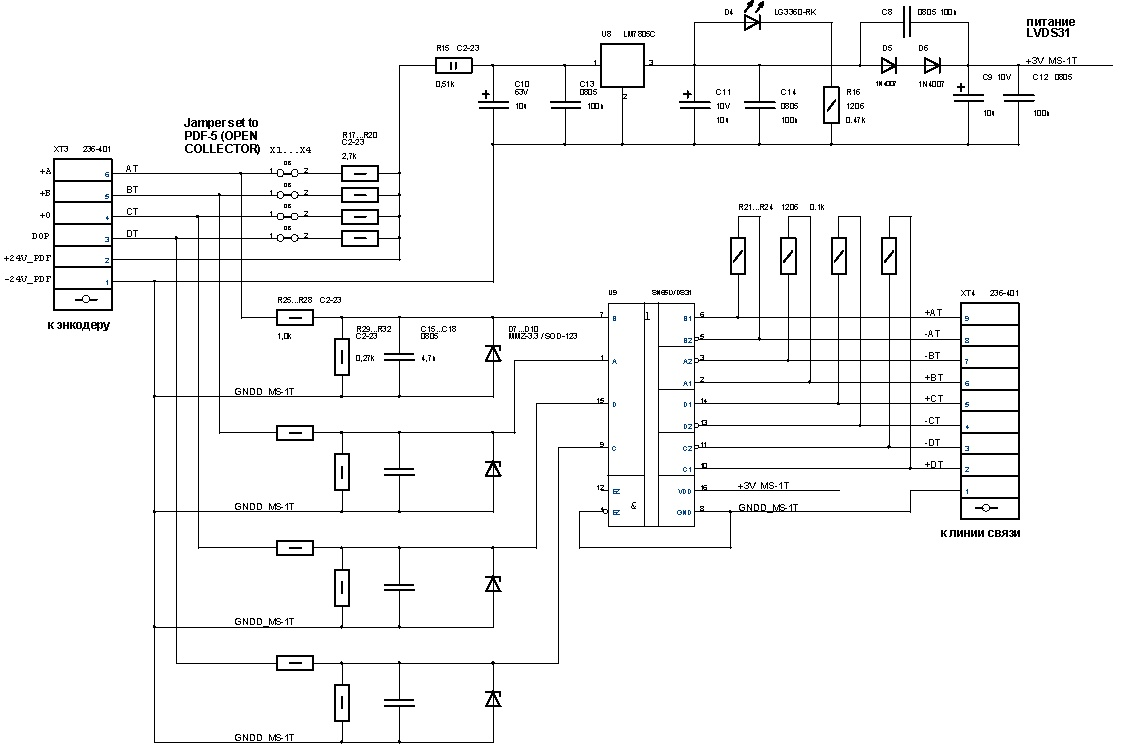
Рис. 4. Схема электрическая принципиальная модуля передачи сигналов датчика приращений
На плате приемника предусмотрен вариант, как потенциальных выходов, так и с открытым коллектором. Для питания цепей приемника использован DC-DC преобразователь PUS-0505 (U5). Допустимо использование любого 5-вольтового в корпусе SIP мощностью не менее полуватта. Гальваническую развязку сигналов обеспечивают оптроны TLP621 (U2, U3, U4, U6). Предусмотрено питание схемы как от 5В, так и 24В источника. Элементы R1…R4 обеспечивают согласование длинной линии на основе витых пар. При необходимости инверсии выходных сигналов предусмотрена схема НЕ на ИМС SN74F04 (U10).
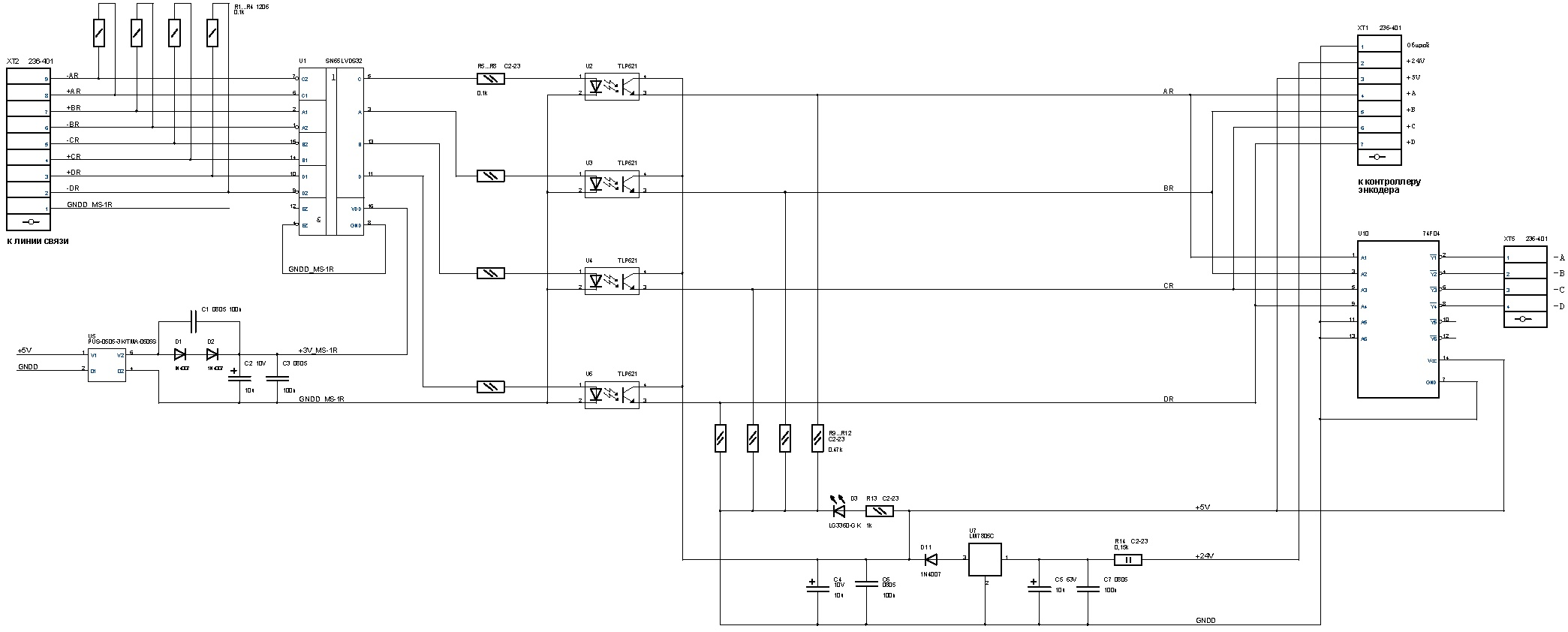
Рис. 5. Схема электрическая принципиальная модуля приема сигналов датчика приращений
* Комментарий автора.
В качестве кабеля связи рекомендуется использовать следующие марки кабеля:
— FTP 4x2xAWG 24/1,
— S- FTP 4x2xAWG 24/1,
— S- STP 4x2xAWG 24/1.
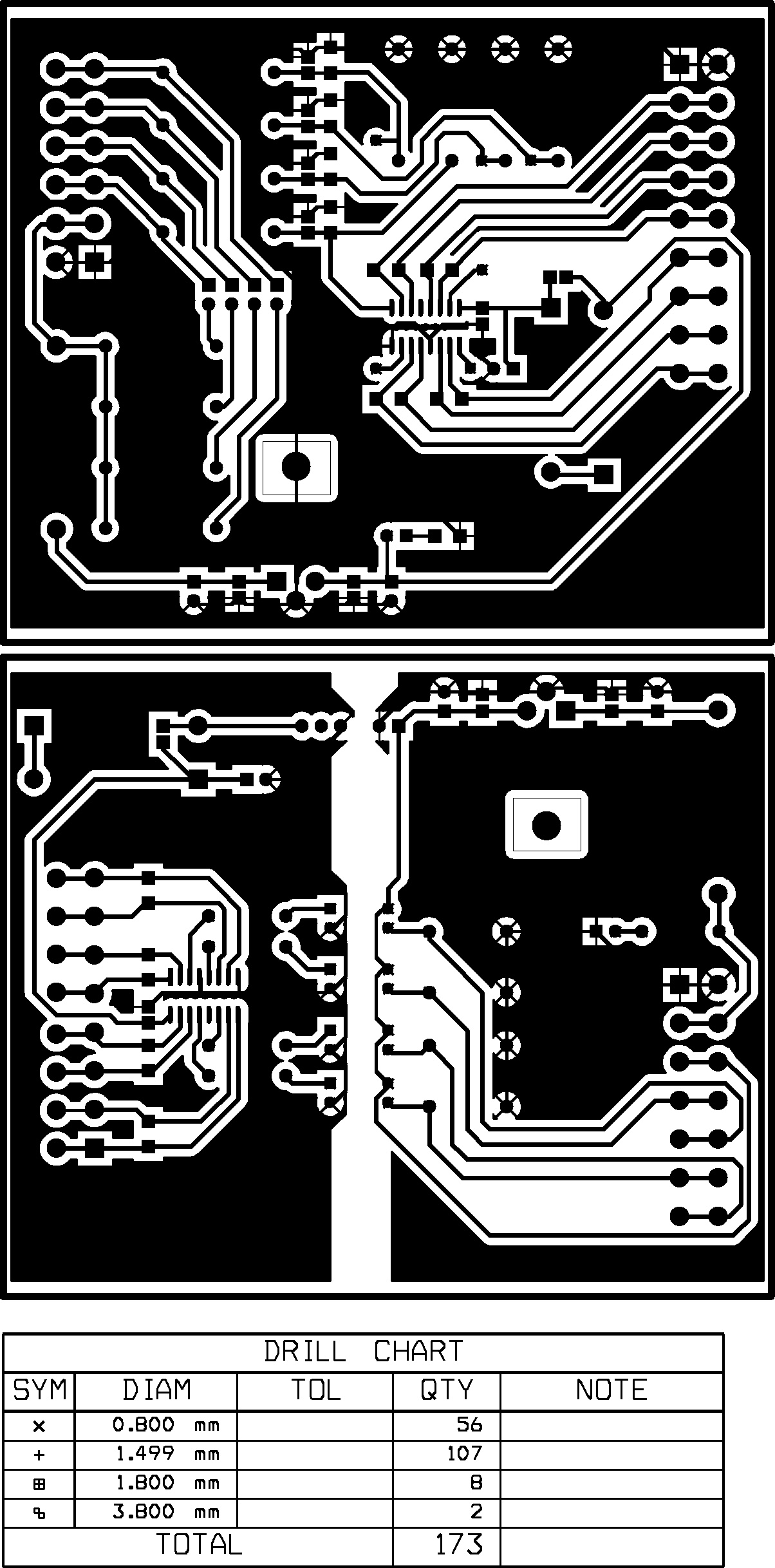
Рис. 6. Печатная плата “вид снизу” модуля передачи и приема (сверху-вниз)
Все резисторы, для упрощения разводки платы, корпусные. Конденсаторы типоразмера 0805. Используемые входные и выходные клеммники – WAGO 236-401 c защелками под отвертку. Платы установлены в корпуса из поликарбоната PHOENIX CONTACT с креплением на DIN рейку. Непосредственно габариты и вся конструкция в сборе представлена на рисунке 8.
Аппаратная часть. Краткое описание контроллера энкодера
Аппаратной основой энкодера датчика приращений служит модуль DIC110 (UNIOxx-5) фирмы Fastwell [2, 3], выполненный в формате MicroPC и установленный в 8-ми слотовое промышленное шасси на базе 486 процессора под управлением DOS. Шасси позволяет установку как ISA, так и PCI плат периферийного ввода-вывода.
Модули UNIOxx-5 имеют 5 разделяемых линий прерываний, канал прямого доступа к памяти (DMA) и светодиод обращения к плате. Внутренняя структура представлена на рисунке 9. Платы UNIO, в зависимости от загруженной прошивки, могут выполнять цифровой/частотный ввод-вывод, аналоговый ввод-вывод (через модули Grayhill), измерение частоты и многие другое. Прошивка изменяется программно, благодаря чему разработчики получают уникальную возможность решать с помощью одной платы множество задач. Если взглянуть на структуру, то сразу видно, что подобные возможности реализуются в основном благодаря наличию ПЛИС. Каждая матрица обслуживает 24 канала ввода-вывода. Загрузка схем матриц производится при включении питания или аппаратном сбросе (RESET) из электрически перепрограммируемого постоянного запоминающего устройства (EEPROM). Изменение варианта загружаемой схемы и, следовательно, способа обработки сигналов осуществляется перепрограммирова- нием EEPROM непосредственно в системе.
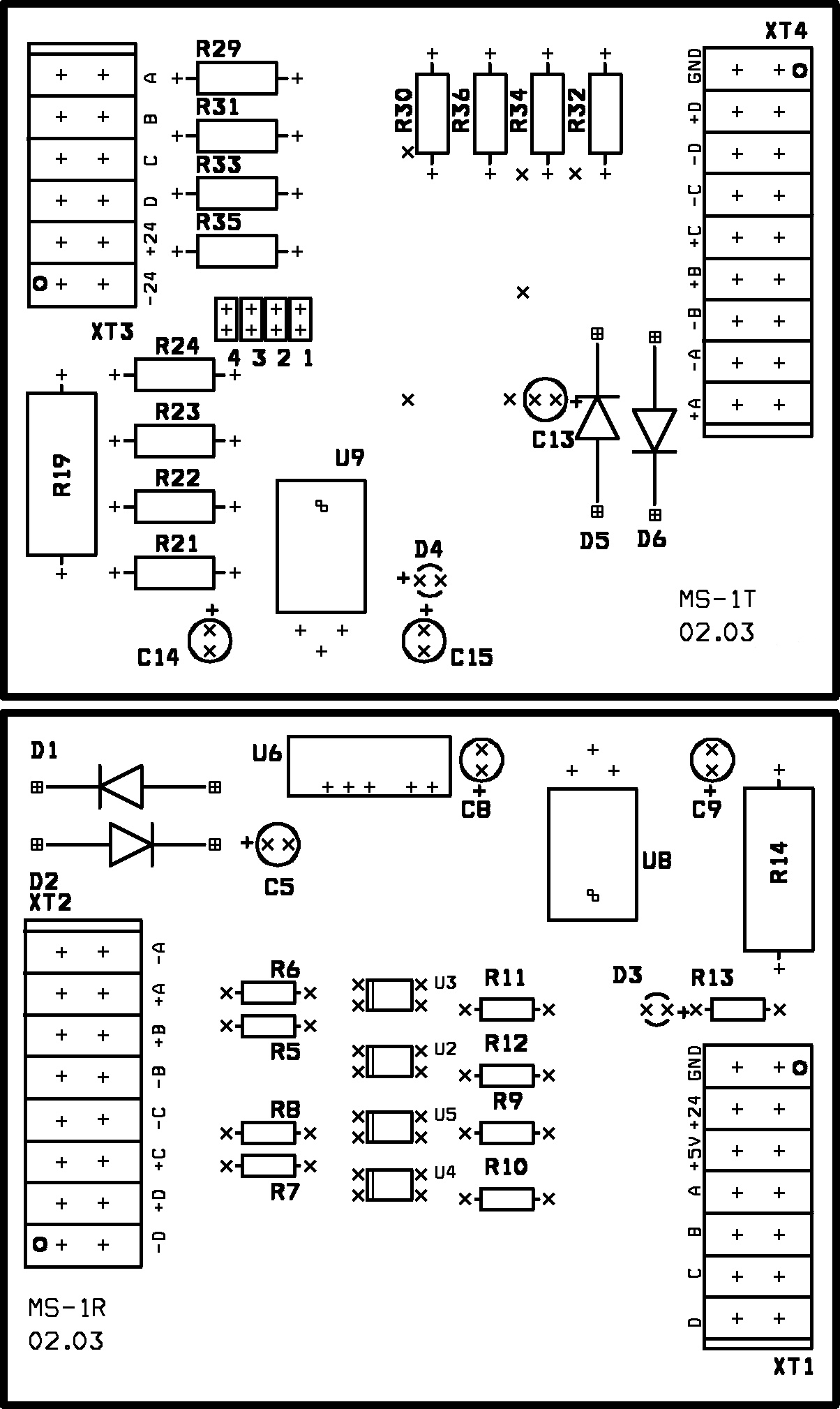
Рис. 7. Расположение элементов “вид сверху и снизу” модуля передачи и приема (сверху-вниз)

Рис. 8. Конструктив модуля передачи и приема импульсных сигналов
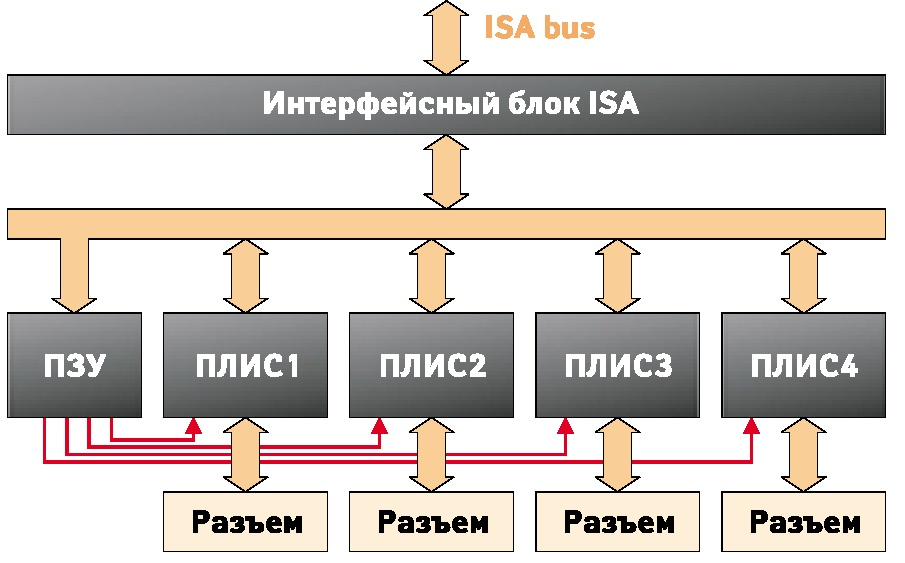
Рис. 9. Структура модуля UNIOxx
Разработка ПО. Алгоритм энкодера
Итак, приступим к основной задаче. Для работы нам понадобится следующее:
- Turbo C++ IDE ver.3.0 от Borland
- IDE среда Xilinx Foundation Series 3.1i / 6.2i для ПЛИС [4]
- Модуль передачи-приема импульсных сигналов датчика приращений
- Промышленная плата UNIOxx-5 от Fastwell
- JTAG.XILINX программатор из материала [5] или утилита внутреннего загрузчика ISP от FastWell [6]
Энкодер предназначен для декодирования сигналов угловых датчиков положения и передачи информации об угловом положении, скорости, направления вращения, количества оборо- тов, а также допол- ните- льных сигна- лов (в виде приз- наков отказа кана- лов, на- личия строба) в виде 8-ми разрядной цифровой последовательности для дальнейшей расшифровки программным путем.
Входные сигналы контроллера
Сигналы с каждого датчика шифратора приращений представляют последовательности импульсов, смещенных на 90 градусов по периоду следования. Частота следования импульсов определяет скорость вращения. Максимальная частота – 200 кГц. Максимальное количество импульсов за 1- оборот – 6000. Каждый оборот идентифицируется стробирующим импульсом. На рисунке 10 представлена последовательность импульсов от датчика, поступающих на вход контроллера:
A – прямой и инверсный канал A,
B – прямой и инверсный канал B,
O – прямой и инверсный строб O (длительность равна четверти периодаимпульса по каналу А или В ±10%)
Рис. 10. Входные сигналы энкодера
Управляющие сигналы:
- сигнал чтения READ по шине ISA платы UNIOxx-5
- адресация (А0…А2) для организации чтения
- (коммутации) 6-ти внутренних регистров тактовые импульсы (меандр) частотой 50 МГц от внешнего генератора платы UNIOxx-5
Выходные сигналы контроллера
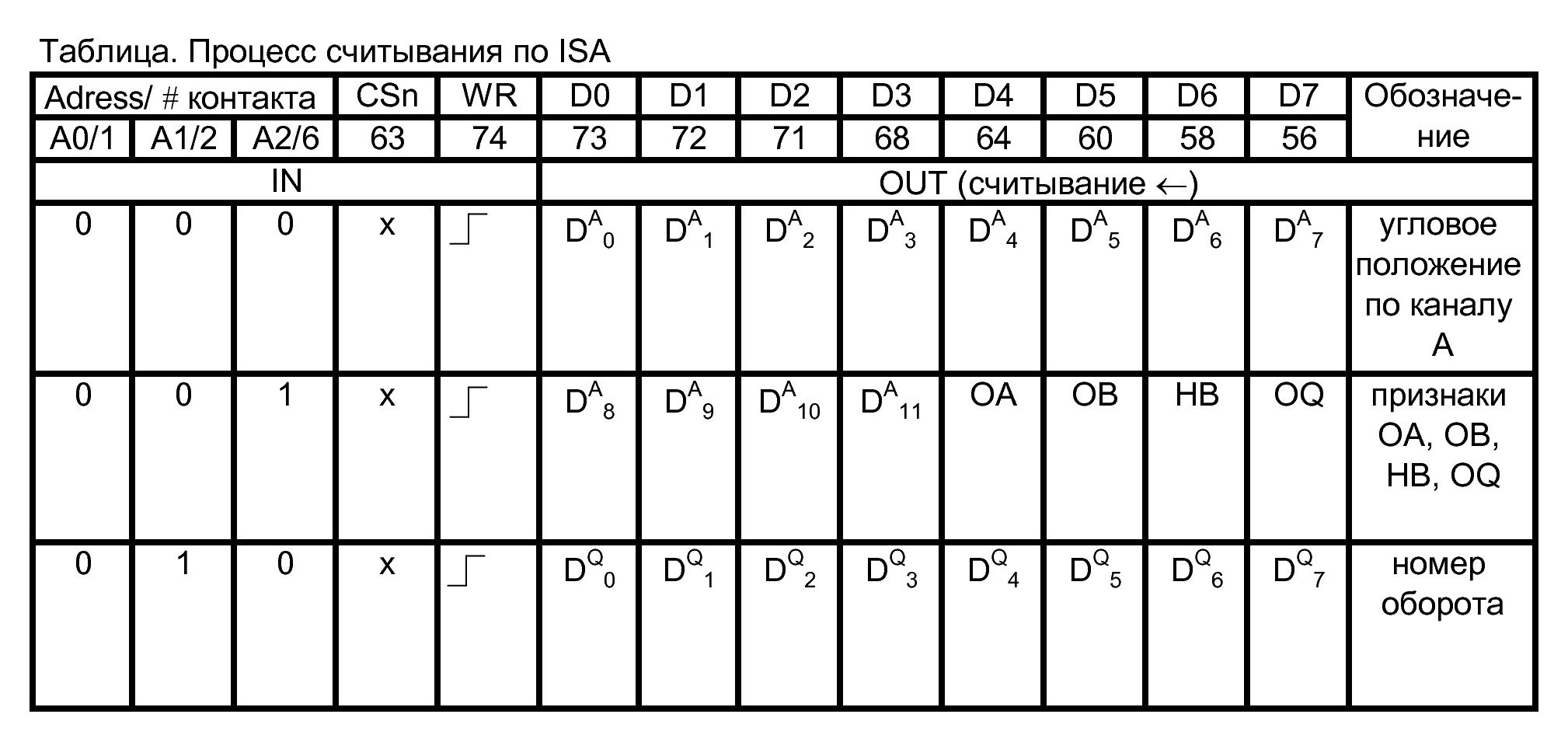
Выходные сигналы для каждой микросхемы FPGA передаются по шине ISA в последовательности, описанной в таблице. Дальнейшая работа с шиной ISA определяется принципиальной схемой и протоколом обмена с микросхемами FPGA. Cформируем основные требования к энкодеру:
- работоспособность при входных частотах канальных импульсов от 0.0 до 200 кГц
- выставление бита направления вращения
- запись данных в буферные регистры по поступлению: сигнала READ и опросе нулевого адреса из шины ISA, и хранение данных до поступления следующего сигнала READ
- измерение количества импульсов, соответствующих угловому положению датчика и реверсом счетчика количества импульсов по направлению вращения
- антидребезговый прием дискретных сигналов каналов (прямого и инверсного А, прямого и инверсного В)
- динамическое изменение ширины защитного интервала для каждого из каналов в пределах длительности канального импульса;
- хранение результата по предыдущему сигналу READ и выдачу текущего значения относительного углового положения, признаков канальных отказов, наличия строба, количества оборотов, относительной скорости
- выдача должна осуществляться путем последовательного выбора (адресации по шине адреса А0…А3) внутренних регистров
- хранения и записи в виде битовой последовательности DO0…DO7 по портам платы модуля UNIOxx-5
Теперь перейдем к программной части…
Скажем пару слов о среде САПР Xilinx****. Программные средства Xilinx Foundation представляют собой систему сквозного проектирования, которая реализует полный цикл разработки цифровых устройств на базе ПЛИС, включая программирование кристалла. Оболочка Project Navigator предоставляет пользователю интерфейс для работы с проектом и управления всеми процессами проектирования и программирования ПЛИС. Исходные описания проектируемых устройств могут быть представлены в текстовой форме с использованием языков HDL (Hardware Description Language), в виде диаграмм состояний или принципиальных схем. В состав пакета включен схемотехнический редактор и комплект библиотек.
Согласно спецификации на модуль UNIOxx-5 [2, 3], используются ПЛИС FPGA – XC5204. Теперь, запустив IDE Xilinx, создадим новый проект и выберем соответствующую матрицу (см. рисунок 11):
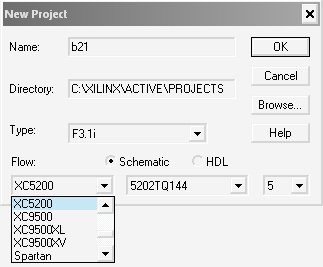
Рис. 11. Создание проекта и выбор параметров в среде Xilinx
Заключение
Следует обратить ваше внимание, что при необходимости передачи импульсных сигналов с датчика приращений на расстояния более чем несколько сот метров (но менее километра), нужно использовать дифференциальные приемо- передатчики с драйверами предкоррекции сигналов и компенсацией потерь. В качестве таких приемо-передатчиков можно рекомендовать микросхемы LVDS CLC001 и CLC012 фирмы National Semiconductor [8, 9].
* Комментарий автора.
Если вы впервые столкнулись с данной средой, то сперва рекомендуется ознакомиться с кратким руководством [7] по работе с пакетом.
Ресурсы
- Спецификация на ИМС SN65LVDS31 (SO-16) http://www.alldatasheet.com/datasheet-pdf/pdf/28186/TI/SN65LVDS31D.html и спецификация на ИМС SN65LVDS32 http://www.alldatasheet.com/datasheet-pdf/pdf/28217/TI/SN65LVDS32A.html
- Fastwel Micro PC compatible UNIOxx-5. Программируемые модули ввода-вывода. Руководство пользователя. – Doc. UNIOxx-5 ver.02.02
- Спецификация на модуль ввода-вывода UNIOXX-5 http://www.fastwel.ru/content/ecmsfiles/239170.pdf
- Сайт производителя Xilinx http://www.xilinx.com
- С. Бадло. JTAG.XILINX программатор. – Радиолюбитель, Минск, 2008, №7, с.38 http://raxp.radioliga.com/cnt/s.php?p=jtag.pdf
- Печатные платы модуля связи GERBER RS-274X http://programmersclub.ru/pro/pro4.zip
- Руководство по работе с Xilinx Foundation Series 3.1 http://raxp.radioliga.com/cnt/s.php?p=x3.zip
- Спецификация на драйвер CLC001 http://national.com/pf/CL/CLC001.html
- Спецификация на драйвер CLC012 http://national.com/pf/CL/CLC012.html
10th
Июл
Как работать с графикой на канве в среде Дельфи. Урок 7-8
Вот мы и подошли к заключительной серии наших уроков по графике в среде DELPHI. Сегодня рассмотрим практическое применение модуля <LoadObjectToBufferMod>, из нашего прошлого материала, на примере работы с движущимися графическими объектами…
Продолжение. Начало цикла смотрите в первом выпуске журнала…
Как работать с графикой на канве в среде Дельфи. Урок 7—8
Владимир Дегтярь
DeKot degvv@mail.ru
Проект с использованием дополнительного универсального модуля. Урок 7
Создайте и сохраните аналогично предыдущим урокам новый проект <Lesson 4>. В разделе uses введем модуль и в разделе var переменные для фона и звездолета ‘ship1 . Сам модуль должен находится в папке проекта (см. листинг 1):
Interface ЛИСТИНГ-1
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs,LoadObjectToBufferMod, ExtCtrls;
var
Form1: TForm1;
xf,yf: integer; // координаты вывода общего буфера на форму
dyf: integer; // приращение изменения координаты yf по вертикали
xS1,yS1: integer; // координаты звездолета 'ship1'
dxS1,dyS1: integer; // приращение координат 'ship1' по гориз. и вертик.
xR,yR: integer; // координаты звездолетов 'ship4' ...'ship7'
dyR: integer; // приращение координат 'ship2 - 5'
N_kadrS1: byte; // номер изображения спрайта 'ship1'
implementation
В процедуре OnCreate() формы проведем инициализацию буферов и введем начальные данные для переменных (см. листинг 2):
procedure TForm1.FormCreate(Sender: TObject); ЛИСТИНГ-2
begin
// инициализация и загрузка битовых образов буфера фона и общего буфера
InitFon(1,2,'data/star1.bmp');
LoadFon(0,0,'data/star1.bmp');
LoadFon(0,540,'data/star2.bmp');
InitBuff;
// начальные значения переменных
xS1:= 250; yS1:= 1006;
dxS1:= 5; dyS1:= 2;
xf:= 0; yf:= -540; dyf:= 2;
end;
Процедура InitFon() вызывается из модуля ‘1‘ – количество используемых файлов фона по ширине, ‘2‘ – по высоте, ‘data/star1.bmp’ – по этому файлу определяем размеры основного буфера фона BufFon. Далее в процедурах loadFon() загружаем все файлы фона в BufFon. InitBuff() – инициализация буфера Buffer и загрузка в него фона. Движение графических объектов организовано в обработчике таймера (см. листинг 3):
procedure TForm1.Timer1Timer(Sender: TObject); ЛИСТИНГ-3
begin
// вывод движения 'ship1'
N_kadrS1:= InitSprite('data/ship1.bmp',2,1,1,N_kadrS1);
LoadBuff(xS1-dxS1,yS1+dyS1,xS1,yS1,0);
Form1.Canvas.Draw(xf,yf,Buffer);
yf:=yf+dyf; // приращения координат для движ. фона
if yf >= 0 then // если половина фона "прошла" через окно формы
begin
yf:= -540; yS1:= 1006; // возврат к начальным координатам
FreeBuff; // "перезагрузка" фона
end;
yS1:= yS1 - dyS1; // приращение для 'ship1',обратное приращению фона
end;
Функция InitSprite() возвращает номер следующего кадра (следующий рисунок спрайта ‘ship1’), который при следующем такте таймера опять передается в эту же функцию. В процедуре LoadBuff() предыдущее изображение спрайта перекрывается областью TRect фона и затем выводится новое изображение спрайта.
Когда весь фон проходит через окно формы в процедуре FreeBuff() фон снова перерисовывается в Buffer и возвращаются начальные координаты вывода Buffer на форму. Движение звездолета по горизонтали организовано в обработчике нажатия клавиш (см. листинг 4):
procedure TForm1.FormKeyDown(Sender: TObject; var Key: Word; ЛИСТИНГ-4
Shift: TShiftState);
begin
case Key of
VK_Left: begin // клавиша "стрелка" - влево
if xS1 <= 0 then EXIT; { если звездолет у левого края формы
xS1 не изменяется}
dxS1:= -5; // движение звездолета влево
xS1:= xS1 + dxS1;
end;
VK_Right: begin // клавиша "стрелка" - вправо
if xS1 >= 630 then EXIT; { если звездолет у правого края формы
xS1 не изменяется}
dxS1:= 5; // движение звездолета вправо
xS1:= xS1 + dxS1;
end;
end;
end;
Запустите данный проект. Получим приложение аналогичное проекту <Lesson 3>. Сравнив коды этих проектов, заметно преимущество применения модуля. Сам проект приведен в папке <Lesson 4_1> (см. ресурсы к статье). Мы же продолжим создание проекта <Lesson 4> далее, введя еще один движущийся
графический объект (звездолет из файлов ‘ship4’ … ‘ship7’). Эти файлы имеют разный размер и разное количество рисунков).
В разделе var введем переменные для нового графического объекта:
var
N_kadrR: byte; // номер изображения спрайта 'ship4' ... 'ship7'
ns: byte = 5; // номер файла спрайтов
Nspr: byte = 2; // кол-во изображений в строке файла спрайтов
Добавим начальные значения новых этих переменных:
xs1 := 250; ys1 := 1006; // начальные значения переменных-
dxs1:= 4; dys1:= 2;
xf := 0; yf := -540; dyf:= 2;
xr := 50; yr:= 450;
dyr:= 3;
Randomize;
В обработчике таймера для нового объекта повторно вызовем методы вывода изображений спрайтов (см. листинг 6):
// вывод движения ‘ship4-ship7’ ЛИСТИНГ-6
N_kadrR:= InitSprite(‘data/ship’ + inttostr(ns) + ‘.bmp’, Nspr, 1, 1, N, N_kadR);
LoadBuf(xR, yR – dyR, xR, yR, 0);
Form1.canvas.draw(xf, yf, Buffer);
yR:= yR + dyR; // приращение для ‘ship4-ship7’
if yR >= yS1 + 100 then // проход ‘ship4-ship7’ через окно формы
begin
xR:= random(600);
yR:= yS1 – 600;
ns:= random(4) + 4;
if ns = 7 then Nspr:= 4
else Nspr:= 2
end
end
Здесь, в функции InitSprite() переменная Nspr означает количество изображений в файле спрайтов и определяется по значению ns – номера файла нового объекта, который в свою очередь определяется функцией random() после каждого прохождения новым графическим объектом окна формы. Причем, движение ‘ship1’ аналогично предыдущим примерам в процедуре FormKeyDown(). Полностью проект приведен в папке <Lesson 4> (см. ресурсы к статье).
Развитие проекта Lesson 4. Урок 8
Продолжим наш проект <Lesson 4>, превратив его в небольшой «шутер» или попросту в «стрелялку». Добавим также возможность стрельбы ракетами для ‘ship1’ по встречным звездолетам и эффект взрыва при попадании. Соответствующие графические файлы ракеты (bullet) и взрыва (explo) находятся в папке <data>. Сделаем это новым проектом с использованием проекта <Lesson 4>.
Итак, приступим… Создайте новую папку и присвойте ей имя <Lesson 5>. Скопируйте в нее все файлы
проекта <Lesson 4> и затем откройте проект в Delphi. Переименуем проект – File => Save Project as … и в диалоговом окне “Введите имя файла” – введите Lesson5 и сохраните проект под новым именем. Теперь снова откройте проект <Lesson 5> и добавьте переменные для новых объектов:
xb, yb: integer; // координаты ракеты
dyb: integer; // приращение координат ракеты
n_kadrb: byte; // номер изображения ракеты
n_kadre: byte; // номер изображения взрыва
vistrel,flag_s: boolean;
Флаги vistrel и flag_S типа Boolean необходимы для управления выводом изображения при выстреле ракетой. Случайный выбор звездолетов ‘ship4’ … ‘ship7’ выделим в отдельную процедуру, так как выбор в программе осуществляется несколько раз после прохождения звездолетом нижней границы окна формы, после попадания ракеты, а значит и уничтожения звездолета (см. листинг 7):
procedure randomship; ЛИСТИНГ-7
begin
xr:= random(600);
yr:= ys1 – 600;
ns:= random(4) + 4;
if ns = 7 then nspr:= 4
else nspr:= 2
end;
В процедуре FormKeyDown() добавим обработку клавиши ”пробел” – пуск ракеты (см. листинг 8):
vk_space: // пробел – выстрел ЛИСТИНГ-8
if not vistrel then begin
xb:= xs1 + 22;
yb:= ys1 – 30;
dyb:= 20;
vistrel:= true
end;
В обработчике таймера выводим движение ракеты при произведенном пуске – флаг (см. листинг 9):
if yr >= ys1 + 100 then ЛИСТИНГ-9
randomShip; // проход ship4-7 через окно формы
if (vistrel) and (not flag_s) then begin // если произведен выстрел, то
// вывод изображения ракеты
n_kadrb:= initSprite(‘data/bullet.bmp’, 1, 1, 1, n_kadrb);
loadBuff(xb, yb + dyb, yb, 0);
yb:= yb – dyb;
if yb <= ys1 – 510 then begin // ракета вышла за пределы окна формы
vistrel:= false;
freeBuff // ПЕРЕЗАГРУЗКА фона
end
end;
и также вводим “эффект взрыва” при попадании ракеты в цель (см. листинг 10):
if (yb <= yr) and ЛИСТИНГ-10
(xb >= xr) and
(xb <= xr+100) and
(vistrel) then begin
flag_s:= true;
dyb:= 0;
n_kadre:= initSprite(‘data/explo.bmp’, 8, 1, 1, n_kadre);
loadBuff(xb-54, yb + 2, xb-54, 0);
form1.canvas.draw(0, yf, buffer);
if n_kadre = 0 then begin // конец эффекта взрыва
vistrel:= false;
flag_s:= false;
freeBuff;
randomShip
end
end;
И собственно то, чего добивались. Скомпилируем и запустим наш проект (см. рисунок):
Рис. Окно проекта игры
Заключение
На этом мы закончим рассмотрение простейших приемов работы с движущимися графическими объектами. Предложу еще самостоятельно разобрать метод вывода на канву текстовой графики. Добавьте в код последнего приложения счетчики количества пусков ракет и попаданий в цель (например: count1, count2) и используя свойства Font(Size,Style,Color) и метод TextOut(X,Y, IntToStr(count..) введите статистику в приложении. Будем считать это домашним заданием…
Рассматриваемые в данной статье проекты полностью приведены в ресурсах к статье на http://www.programmersforum.ru в разделе «Журнал клуба программистов. Четвертый выпуск» (папка Lesson5*).
* Комментарий автора
Перед запуском в среде Дельфи скопируйте в папку с проектом папку data с графическими файлами.
Статья из четвертого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Как работать с графикой на канве в среде Дельфи. Урок 7-8
2nd
Июл
Игра Fortress 2. Создание лучшего бота – призовой фонд 5000 рублей!
Здравствуйте читатели нашего журнала. Сегодня мы хотим напомнить вам, что продолжается прием заявок на участие в конкурсе по созданию лучшего бота для игры в Fortress2 с денежным призом. Организатор конкурса – Форум программистов www.programmersforum.ru.
Игра Fortress 2. Создание лучшего бота – призовой фонд 5000 рублей!
Аблязов Руслан
by rpy3uH http://www.programmersforum.ru/member.php?u=11
* Комментарий автора
Для тех, кто не в курсе: бот представляет собой DLL с тремя экспортируемыми функциями. Документация по созданию бота находится в файле Fortress 2 Bot Specification
Скачать Fortress 2 build 2025 beta + Документация + исходник SimpleBot v1.0 http://programmersforum.ru/attachment.php?attachmentid=23688&d=1270876754
Скачать исходники SimpleBot v1.0 на С++ (CodeBlocks+MinGW) http://programmersforum.ru/attachment.php?attachmentid=23689&d=1270876964
Скачать документацию по созданию ботов http://pkonkurs.ru/wp-content/uploads/2010/06/Fortress-2-Bot-Specification.zip
Скачать исходник бота на С++ (CodeBlocks+MinGW) http://pkonkurs.ru/wp-content/uploads/2010/06/SimpleBotCpp.zip
Исходник бота на Delphi поставляется в комплекте с игрой.
Почему надо участвовать в этом конкурсе?
Во-первых, это интересно, вы можете поучаствовать в конкурсе, где не нужно загружать данные из текстового файла и сохранять их туда! Во-вторых, можно получить денежный приз, толстовку или футболку от клуба. В-третьих, вы получите опыт в создании ИИ для игры, и сможете сказать «Я разрабатывал бота для игры!»
Призы как денежные – 3000 рублей, так и сувениры от клуба на 2000 рублей. Конкурс расчитан на 2-4 месяца. Первая битва ботов состоится 15 июля 2010 года.
Ключевые понятия игры
Итак, вы хотите написать бота для этой игры, но не знаете как. Что пригодится для написания бота для игры:
1. Компилятор, который позволяет компилировать DLL файлы и разумеется знание языка этого компилятора
2. Знание правил игры
3. Знание, какие функции должны присутствовать в DLL, для того чтобы бот смог работать
С компилятором я думаю, проблем не будет он может быть любой, главное условие, чтобы он смог компилировать функции по соглашению stdcall. Сначала поясню как вообще происходит игра. играют двое, у каждого игрока есть база, есть три типа ресурсов, есть щит, есть проекты. Проекты бывают разные: атака вражеской базы, развитие своей базы, ремонт базы, шпионаж. Всего проектов 50. В начале игры игрок выбирает 15 проектов, которыми он будет играть. Потом игроки по очереди выбирают проекты, игрок может выбрать только тот проект, на который хватает ресурсов. Проигрывает то
т игрок, броня базы которого станет равной нулю.
Какова ее физика с точки зрения ботописателя? Читаем внимательно!
Мы выбираем двух ботов и нажимаем начать игру, ядро игры вызывает функции StartGame ботов участвующих в игре. Задача функции StartGame это выбор набора проектов, которыми будет играть бот, набор проектов надо сохранить в массиве, указатель на который будет передан функции StartGame. Проекты задаются числами (полный набор проектов указан в документации). После выбора проектов начинается игра. В ходе игры по очереди вызываются функции GetTurn каждого бота. В случае, если боту недоступен ни один проект, то функция GetTurn вызывается с нулевым указателем на массив доступных пр
оектов. В конце игры еще раз вызывается функция StartGame с нулевым указателем на массив проектов. Нулевой указатель на массив свидетельствует о том, что происходит уведомление бота о конце игры.
Количество ресурсов (энергия, металл, электроэлементы) зависит от количества объектов их добывающих (батареи, рудники, лаборатории). Количество батарей и рудников у врага можно уменьшить используя специальные шпионские-проекты. Внимание, нововведение в Fortress 2 : введено ограничение на количество лабораторий. По-умолчанию оно равно 5. Как только броня базы становится больше 50, к лимиту прибавляется одна лаборатория за каждые 5 единиц брони свыше 50. Например:
Base = 30, LabLimit = 5;
Base = 54, LabLimit = 5;
Base = 56, LabLimit = 6;
Base = 63, LabLimit = 7;
Base = 75, LabLimit = 8;
Base = 81, LabLimit = 9;
И т.д.
В случае использования проектов, которые увеличивают количество лабораторий и при этом уже достигнут лимит количества лабораторий, проект считается использованным (ресурсы расходуются), а количество лабораторий не изменяется.
Отличия от первой версии игры
1. Добавлены уведомления о пропуске хода и о конце игры и ее результатах
2. Бот может узнать имя противника (см. структуру TAdditionalGameInfo)
Возможности улучшения бота
Покажем, как можно изменить игру бота SimpleBot v1.1 в лучшую сторону, всего лишь добавив несколько строчек кода. Итак, приступим. Для разнообразия будем писать на C++. Что мы сделаем в первую очередь? Изменим набор проектов. Смотрим строку в коде, которая содержит список проектов [1, 2]:
const int Projects[MaxProjectsToPlayer] = {5, 6, 11, 13, 16, 18, 20, 28, 33, 34, 35, 44, 45, 46, 50};
Что тут можно изменить? В принципе можно тут изменить все, но заморачиваться мы не будем, просто удалим проект номер 50 и вставим (29) СуперАтака 2. En 16, Me 14, El 6 : Base-20, Shield-15. В итоге получаем такой список проектов:
const int Projects[MaxProjectsToPlayer] = {5, 6, 11, 13, 16, 18, 20, 28, 29, 33, 34, 35, 44, 45, 46};
Теперь смотрим функцию хода бота:
if (!aAvailProjects) return 0;
int OPP = GetOtherPlayer(aPlayerNumber);
if ((IsProjectAvail(20,aAvailProjects)) and
(aGame[aPlayerNumber].Base<25))
return 20;
if ((IsProjectAvail(18,aAvailProjects)) and
(aGame[aPlayerNumber].Base<20))
return 18;
if ((IsProjectAvail(16,aAvailProjects)) and
(aGame[aPlayerNumber].Shield<5))
return 16;
Первые две строки это проверка на уведомление о пропуске хода и получение индекса противника. Потом идет проверка доступности проектов 20, 18, 16:
(16) Ремонт 2. En 9, El 2 : SS+10
(18) Ремонт 4. Me 7, El 2 : SB+9
(20) Ремонт 6. Me 8, El 5 : SB+12
т.е. у бота приоритет : сначала проверить состояние базы, если состояние плохое выбираем ремонтный проект. изменять здесь ничего не будем. Смотрим далее. Далее идут при проверки и использование проектов увеличения количества батарей, рудников и лабораторий:
if (IsProjectAvail(34,aAvailProjects) and
(aGame[aPlayerNumber].Mines<3) and
(aGame[aPlayerNumber].Base>35) and
(aGame[aPlayerNumber].Shield>2))
return 34;
if (IsProjectAvail(33,aAvailProjects) and
(aGame[aPlayerNumber].Battery<4) and
(aGame[aPlayerNumber].Base>35) and
(aGame[aPlayerNumber].Shield>2))
return 33;
if (IsProjectAvail(35,aAvailProjects) and
(aGame[aPlayerNumber].Labs<3) and
(aGame[aPlayerNumber].Base>35) and
(aGame[aPlayerNumber].Shield>2))
return 35;
т.е. если состояние базы нормальное то можно увеличить количество батарей, рудников и лабораторий. Но как видно что количество батарей, рудников и лабораторий будет не больше 4,3,3 соответственно. Эти строчки мы менять не будем, добавим дополнительные строчки отвечающие за усиленное развитие базы
if (IsProjectAvail(34,aAvailProjects) and
(aGame[aPlayerNumber].Mines<6) and
(aGame[aPlayerNumber].Base>45) and
(aGame[aPlayerNumber].Shield>10))
return 34;
if (IsProjectAvail(33,aAvailProjects) and
(aGame[aPlayerNumber].Battery<7) and
(aGame[aPlayerNumber].Base>45) and
(aGame[aPlayerNumber].Shield>10))
return 33;
if (IsProjectAvail(35,aAvailProjects) and
(aGame[aPlayerNumber].Labs<5) and
(aGame[aPlayerNumber].Base>45) and
(aGame[aPlayerNumber].Shield>5))
return 35;
Теперь количество батарей, рудников и лабораторий будет увеличиваться до 7,6,5 соответственно. Развитие базы будет осуществляться только в том случае если состояние базы очень хорошее.
В набор проектов мы добавили проект номер 29, вопрос куда вставить его обработку чтобы не ухудшить игру бота. После проверок на развитие базы есть такие строки
if (IsProjectAvail(46,aAvailProjects)) return 46;
if (IsProjectAvail(28,aAvailProjects)) return 28;
в первую очередь обрабатывается наличие проекта номер 46 а потом 28. Вставим проверку проекта номер 29 между ними.
if (IsProjectAvail(46,aAvailProjects)) return 46;
if (IsProjectAvail(29,aAvailProjects)) return 29;
if (IsProjectAvail(28,aAvailProjects)) return 28;
Компилируем бота, запускаем игру, ставим 500 игр и смотрим результат (см. рисунок 1):
Рис. 1. Результаты игры SimpleBot v1.1
Результат очевиден, выигрыш в 84% игр. Но нет предела совершенству. Рассмотрим поведение бота… В начале, бот проверяет состояние базы и если оно плохое, то выбирает проект ремонта базы. Далее он проверяет условия начального развития базы (когда батарей, рудников и лабораторий совсем мало). Потом проверяет условия усиленного развития базы, и только потом атакующие проекты, и в самом конце если ни одно условие не выполнилось, то случайно выбирает проект.
Что можно изменить в первую очередь? Условия начального развития базы слишком жесткие: база должна быть не менее 35 единиц и щит должен быть не нулевой. Также слишком жесткие условия усиленного развития базы. Вот их нам и надо изменить. Вот что у меня получилось (в терминах Delphi):
if IsProjectAvail(BuildMineProject,aAvailProjects) and
(aGame[aPlayerNumber].Mines<3) and
(aGame[aPlayerNumber].Base>25) then
begin
Result:=BuildMineProject;
exit;
end;
if IsProjectAvail(BuildBatteryProject,aAvailProjects) and
(aGame[aPlayerNumber].Battery<4) and
(aGame[aPlayerNumber].Base>25) then
begin
Result:=BuildBatteryProject;
exit;
end;
if IsProjectAvail(BuildLabProject,aAvailProjects) and
(aGame[aPlayerNumber].Labs<3) and
(aGame[aPlayerNumber].Base>25) then
begin
Result:=BuildLabProject;
exit;
end;
if IsProjectAvail(BuildBatteryProject,aAvailProjects) and
(aGame[aPlayerNumber].Battery<7) and
(aGame[aPlayerNumber].Base>40) and
(aGame[aPlayerNumber].Shield>10) then
begin
Result:=BuildBatteryProject;
exit;
end;
if IsProjectAvail(BuildMineProject,aAvailProjects) and
(aGame[aPlayerNumber].Mines<6) and
(aGame[aPlayerNumber].Base>40) and
(aGame[aPlayerNumber].Shield>10) then
begin
Result:=BuildMineProject;
exit;
end;
if IsProjectAvail(BuildLabProject,aAvailProjects) and
(aGame[aPlayerNumber].Labs<5) and
(aGame[aPlayerNumber].Base>40) then
begin
Result:=BuildLabProject;
exit;
end;
Немного хотелось бы сказать про количество лабораторий. Их количество увеличивается только до 5, так как строительство больше пяти лабораторий требует дополнительного строительства базы. Вообще проекты спроектированы так, что на шпионские проекты надо много электроэллементов и если у вас мало электроэлементов вы не сможете использовать сильные шпионские проекты. Правильное развитие на лаборатории и использование шпионских проектов может стать решающим фактором в победе вашего бота.
Теперь посмотрим список проектов выбираемых ботом. Удалим 28 проект и добавим (31) СуперАтака 4. En 26, Me 16, El 10 : ->49 в итоге получаем такой список проектов:
const
STRATEGY:array[0..MaxProjectsToPLayer-1] of integer =
(
5, 6, 11, 13, 16, 18, 20, 28, 31, 33, 34, 35, 44, 45, 46
);
И вставим проверку использования 31 проекта перед всеми атакующими проектами, т.е. его наличие будет обрабатываться в первую очередь:
if IsProjectAvail(31,aAvailProjects) then
begin
Result:=31;
exit;
end;
if IsProjectAvail(46,aAvailProjects) then
begin
Result:=46;
exit;
end;
if IsProjectAvail(29,aAvailProjects) then
begin
Result:=29;
exit;
end;
Проверку наличия проектов 45 и 44 оставим без изменения, а вот в конце при случайном выборе проекта изменим число 15 на 8, таким образом, случайно будут выбираться только первые 8 проектов из списка доступных проектов, а именно проекты мелких атак и ремонта базы:
repeat
Result:=aAvailProjects^[random(8)];
until Result<>0;
Компилируем и смотрим результаты (см. рисунок 2):
Рис. 2. Результаты игры SimpleBot v1.2
Результат – выигрыш более 60% игр.
Ресурсы
. Скачать исходники SimpleBot v1.1. (C++) http://pkonkurs.ru/wp-content/uploads/2010/06/SimpleBotCpp_v11.zip
. Скачать Fortress 2 build 2026 + FortUI build 1004 http://pkonkurs.ru/wp-content/uploads/2010/06/Fortress-2-2026-+-FortUI-1004.zip
. Скачать Fortress 2 build 2026 beta + SimpleBot v1.2 http://pkonkurs.ru/wp-content/uploads/2010/06/Fortress-2-2026-+-FortUI-1004-+-SimpleBot-v1.2.zip
Статья из четвертого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Под редакцией Сергея Бадло…
Обсудить на форуме — Игра Fortress 2. Создание лучшего бота – призовой фонд 5000 рублей!
2nd
Защита от спама в форумах phpBB2. САРТСНА
Все, так или иначе, сталкивались с капчей. САРТСНА (Completely Automated Public Turing test to tell Computers and Humans Apart) – полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей). Представляет собой компьютерный тест, используемый для того, чтобы определить, кем является пользователь системы: человеком или компьютером. В этой статье я хочу рассказать о двух методах защиты форума на базе движка phpBB2 от спамеров и их ботов…
Защита от спама в форумах phpBB2. САРТСНА
by Arigaro http://www.programmersforum.ru/member.php?u=19542
Технология САРТСНА была создана в 2000 году учеными из университета Карнеги-Меллона, и сегодня используется в Интернете практически повсеместно. Основная идея теста САРТСНА: предложить пользователю такую задачу, которую легко решает человек, но которую крайне трудно решить компьютеру. Как правило, это задачи на распознавание зрительных образов. Наиболее часто эта технология используется в различных Интернет-сервисах, в частности – хранилищах файловых архивов и форумах.
Уязвимости защиты САРТСНА
При недостаточной степени защиты скриптов спамбот может пройти тест САРТСНА и без распознавания картинок. В этом случае он либо подменяет идентификатор сессии, либо парсит информацию, содержащуюся на WEB странице и определяет то, что изображено на картинке. Если количество вариантов ответов невелико, спамбот может «угадать» ответ. Как правило, используется несколько параллельных потоков, благодаря чему скорость перебора зависит от полосы доступного канала. Кроме того, возможно и накопление базы вопросов и ответов, и рано или поздно вся она будет у него.
Существуют программы, распознающие конкретные реализации САРТСНА, к примеру PWNtcha. Да и никто не мешает спамеру подключать модули программ распознавания текста, тот же FineReader. Различают «сильную» (сильно размытая и не контрастная картинка) и «слабую» САРТСНА. Что же делать и как защититься от спамботов?
Методы защиты
Первое, что нужно сделать, чтобы прекратить автоматическую регистрацию ботов и массовый спам в темах – это закрыть возможность писать сообщение гостям, поставить картинку (капчу) на форму регистрации и установить активацию учетной записи по E-Mail. Рассмотрим подробнее…
1. Изменение картинки при регистрации на форумах phpBB2
В ходе эксплуатации форума быстро выясняется, что штатных методов для защиты не достаточно. Боты умеют регистрироваться, читать почту и, более того, спокойно распознают картинку, предоставляемую движком форума phpBB2. Если же изменить картинку на более сложную, то можно остановить подавляющее большинство автоматически регистрируемых ботов.
Для этого нужно проделать следующее. В папке <includes> форума изменить файл usercp_confirm.php:
. Удалить всю часть файла после строчки:
// output six seperate original pngs … first way is preferable!
или же строчки (в разных версия форума могут встречаться несколько отличные друг от друга комментарии)
// Thanks to DavidMJ for emulating zlib within the code ![]()
. и до конца файла. Вместо удаленной части вставить следующее:
// Изменение картинки в форме регистрации
// Автор мода: Arigato, 2006
list($usec, $sec) = explode(’ ‘, microtime());
mt_srand($sec * $usec);
$font = getcwd() . “/includes/font.ttf”;
$img = ImageCreate (320, 50);
$color = array();
$color[] = ImageColorAllocate ($img, 0, 0, 0);
$color[] = ImageColorAllocate ($img, 255, 0, 0);
$color[] = ImageColorAllocate ($img, 0, 255, 0);
$color[] = ImageColorAllocate ($img, 255, 255, 0);
$color[] = ImageColorAllocate ($img, 255, 0, 255);
$color[] = ImageColorAllocate ($img, 0, 255, 255);
$color[] = ImageColorAllocate ($img, 255, 255, 255);
$sx = ImageSX ($img) – 1;
$sy = ImageSY ($img) – 1;
$sc = count ($color) – 1;
// Фоновый шум:
for ($i = 0; $i < 1024; $i++)
{
$x = mt_rand (0, $sx);
$y = mt_rand (0, $sy);
$c = $color[mt_rand(1,$sc)];
ImageSetPixel ($img, $x, $y, $c);
}
// Вывод кода:
$xpos = mt_rand (8, 32);
$height = $sy – mt_rand (0, $sy / 4);
for ($i = 0; $i < strlen($code); $i++)
{
$angle = mt_rand (0, 30) – 15;
$size = mt_rand (0, ![]() + 32;
+ 32;
$ypos = $sy – mt_rand (8, $sy – $height – 8);
$c = $color[mt_rand(1,$sc)];
$rect = ImageTTFtext ($img, $size, $angle, $xpos, $ypos, $c, $font, $code[$i]);
$width = $rect[2] – $rect[0];
$height = $rect[1] – $rect[7];
$xpos += $width + mt_rand (4, 48);
}
// Передний шум:
for ($i = 0; $i < 256; $i++)
{
$x = mt_rand (0, $sx);
$y = mt_rand (0, $sy);
$c = $color[mt_rand(0,$sc)];
ImageSetPixel ($img, $x, $y, $c);
}
for ($i = 0; $i < mt_rand (2, 8); $i++)
{
$x1 = mt_rand (0, $sx);
$y1 = mt_rand (0, $sy);
$x2 = mt_rand (0, $sx);
$y2 = mt_rand (0, $sy);
$c = $color[mt_rand(0,$sc)];
ImageLine ($img, $x1, $y1, $x2, $y2, $c);
}
header (”Content-type: image/png”);
header (”Cache-control: no-cache, no-store”);
ImagePng ($img);
ImageDestroy ($img);
?>
Кроме этого нужно поместить в папку includes файл со шрифтом font.ttf, архив с которым можно скачать ниже. При желании можно использовать любой другой TrueType шрифт [1], содержащий латинские буквы и цифры. Как показал опыт применения данного метода на многих форумах, автоматическая регистрация ботов после такой модификации прекращается полностью (см. рисунок):
![]()
![]()
2. Разрешить отправлять личные сообщения только пользователям с 20 и более сообщениями
на форуме phpBB2 (защита от спама в личку). Да, сегодня уже и такой вид спама имеет место. Хотя он еще не получил большого распространения, о защите уже пора задуматься. Итак, что нужно делать…
Открыть файл privmsg.php и найти строчку:
if ( $mode == ‘newpm’ )
Добавить выше следующий код:
// НАЧАЛО: отправка личных сообщений только для пользователей с 20 сообщениями на форуме
// Автор мода: Arigato, 2007
if ( $mode == ‘post’ || $mode == ‘reply’ || $mode == ‘quote’ )
{
$mod_mes_count = 20;
if ( $userdata[‘user_posts’] < $mod_mes_count )
{
message_die(GENERAL_MESSAGE, “<b>$userdata[username]</b>, у Вас на форуме <b>$userdata[user_posts]</b> сообщений<br />
Отправлять личные сообщения Вы сможете, когда наберете <b>$mod_mes_count</b> или более сообщений на форуме”);
}
}
// КОНЕЦ: отправка личных сообщений только для пользователей с 20 сообщениями на форуме
Переменная $mod_mes_count определяет количество сообщений на форуме, после которого пользователю разрешается отправлять ЛС. Читать ЛС может любой пользователь. Предупреждение о запрете отправки ЛС выводится по-русски, многоязычность не поддерживается.
Заключение
Мы уже выяснили, как убрать основную уязвимость – фиксированный шрифт и фиксированное положение символов. Но, как всегда добавим «ложку дегтя». Дело в том, что сегодня получили распространение сервисы по типу CaptchaExchange Server. Эти сервисы направлены на «обход» картинок САРТСНА, путем ручного «человеческого» распознавания символов. Принцип работы основан на системе баллов, которые пользователь может заработать, распознавая в свободное время картинки для других пользователей. Набранные баллы пользователь может потратить позже, в любое удобное время, запустив программу автоматического скачивания файлов с файлообменного сервера или для регистраций. К сожалению и второй, рассмотренный нами, метод не дает 100% гарантию, но основная цель будет достигнута – это снижение нагрузки на сервис и относительное спокойствие пользователей.
Ресурсы
. Вариант шрифта для замены на форуме
http://www.programmersforum.ru/attachment.php?attachmentid=5029&d=1217234938
или http://programmersclub.ru/pro/pro4.zip
Статья из четвертого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Защита от спама в форумах phpBB2. САРТСНА
2nd
Анимация в WEB на JavaScript
Здравствуйте! В этой статье я хотел бы рассказать о создании анимации на веб-страницах с использованием скриптового языка программирования JavaScript, далее JS. Статья ориентирована на новичков.
Анимация на WEB страницах
Алексей Шульга
by Levsha100 http://www.programmersforum.ru/member.php?u=19268
По правде говоря я не являюсь поклоником JS да и вэб-программирования тоже, но родина сказала «Надо!» ![]() Я немного отошел от темы нашего сайта, ибо работы над ним еще ведутся и это, видимо, будет еще долго. Поэтому было решено написать цикл статей по JS и различным интересным трюкам.
Я немного отошел от темы нашего сайта, ибо работы над ним еще ведутся и это, видимо, будет еще долго. Поэтому было решено написать цикл статей по JS и различным интересным трюкам.
Шаблон
Для начала нам необходимо создать заготовку- то место, куда мы будем внедрять скрипты, Вот она:
<html>
<head>
<title>Тестовая страничка</title>
</head>
<body>
</body>
</html>
Это обыкновенная HTML-страничка, я сохранил ее под именем Test.html .
Встраивание JS-скрипта
Итак, шаблон у нас есть, и теперь мы можем смело пробовать оживлять страничку с помощью скриптов, добавить JS-скрипт можно двумя основными способами- добавлением его непосредственно в веб-страницу, либо вынести его в отдельный файл, для наглядности я выбрал первый способ. Добавим скрипт в секцию body, после чего она примет вид:
<body>
<script>
//Тут находится JS-код
</script>
</body>
Для проверки можно заменить за комментированную строку такой строкой:
alert(”Hello, world” );
Этот код выведет [модальное] окно с текстом “Hello, world”.
Добавление объектов
Прежде чем мы займемся анимацией нужно что бы было то, что будет анимироваться, поэтому займемся созданием анимируемых объектов- для примера возьмем квадратные DIV-вы со стороной 10 пикселей. Прежде чем создавать собственно объекты для них необходимо задать стиль, это делается с помощью CSS. Пример:
<head>
<title>Тестовая страничка</title>
<style type=”text/css”>
.obj1style{position:absolute; width:10; height:10; background-color: #00FF00}
</style>
</head>
Наиболее важным свойством является свойство position и именно его значение absolute -оно позволяет размещать объект, к которому применен данный стиль, в любой точке веб-страницы. Свойства width и height, как нетрудно догадаться, отвечают за высоты и ширину объекта соответственно. Цвет фона объекта- зеленый.
Теперь займемся собственно добавлением объектов, для этого необходимо заменить строку:
//Тут находится JS-код
на строки:
var obj_count=10; //Сколько у нас будет объектов
for (i=1;i<=obj_count;i++){ //Цикл от 1 до количества создаваемых объектов
document.write(’<div style=”left:’);
document.write(i*20+50);
document.write(’;top:50;”MsoBodyTextIndent” style=”margin-right: -2.75pt; text-indent: 0cm;”>
document.write(i);
document.write(’”>’+'</div>’);
//вот то самое место, именно тут мы вписываем в страницу 10 DIV-ов с классом obj1style идентификаторами с именами от obj1-1 до obj1-10. Все элементы располагаются на одной высоте, отступ от левой стороны страницы высчитывается по формуле i * 20 +50, где i-это номер элемента[1..10].
}
Вместо данного кода мы могли бы написать что-то вроде:
<div style=”left:70; top:50;” id=”obj1-1″></div>
…
<div style=”left:250; top:50;” id=”obj1-10″></div>
Но это неэффективно и некрасиво да и лень мне писать так много.
I like to move it или анимируем!
Самое интересное. Итак, для начала зададимся целью, что необходимо сделать. Я решил начать с простого – объекты будут летать в неком сосуде и при ударении об стенку они будут отскакивать
* Комментарий автора
кстати данную модель можно было бы назвать “Модель идеального газа”, ибо данная анимация действительно в некой степени моделирует поведение частиц идеального газа.
Для начала после строки:
var obj_count=10;
добавим следующий код:
var VX= new Array(obj_count);
var VY= new Array(obj_count);
document.write(’<div style=”position:absolute; left:45; top:40; width:300; height:300; background:#bbbbbb;” id=”Area”></div>’);
Первые две строки создают два массива длиной 10 элементов, которые хранят значение скорости для каждого объекта. Третья же строка размещает на страничке “сосуд”, в котором будут летать наши “молекулы”, тут, в принципе, я думаю все знакомо и просто. Далее после строк начальной инициализации:
document.write(’;top:50;” id=”obj1-’);
document.write(i);
document.write(’”>’+'</div>’);
добавляем код, который будет задавать случайную скорость для каждого объекта
VX=Math.round(Math.random()*6)-3; if(VX==0){VX=1;}
VY=Math.round(Math.random()*6)-3; if(VY==0){VY=1;}
Условия “if” нужны для того что бы не было нулевых скоростей, то есть что бы небыло неподвижных объектов. Теперь перейдем к самому сердцу нашего аниматора- функции Timer она периодически ( с интервалом 50мс вызывает функцию Animate, но о ней позже.
Функция выглядит так:
function Timer()
{
setTimeout( function(){Animate();setTimeout(arguments.callee, 50);}, 0);
}
Эта функция должна вызываться(стартовать) при загрузке страницы для того что бы обеспечить такую возможность мы подправим тег body, итоговый вид после изменений показан ниже:
<body onload=”Timer()”>
Вроде разобрались, пора браться за последнюю в данном уроке и самую массивную функцию – функцию Animate, вот полный ее текст:
function Animate()
{
for(i=1;i<=obj_count;i++){
document.getElementById(”obj1-”+i).style.left=parseInt(document.getElementById(”obj1-”+i).style.left)+VX;
document.getElementById(”obj1-”+i).style.top=parseInt(document.getElementById(”obj1-”+i).style.top)+VY;
if( parseInt(document.getElementById(”obj1-”+i).style.left) <= parseInt(document.getElementById(”Area”).style.left) ){
document.getElementById(”obj1-”+i).style.left=document.getElementById(”Area”).style.left;
VX*=-1;
}
if( parseInt(document.getElementById(”obj1-”+i).style.left)+10 >= parseInt(document.getElementById(”Area”).style.left)+parseInt(document.getElementById(”Area”).style.width) ){
document.getElementById(”obj1-”+i).style.left=parseInt(document.getElementById(”Area”).style.left)+parseInt(document.getElementById(”Area”).style.width)-10;
VX*=-1;
}
if( parseInt(document.getElementById(”obj1-”+i).style.top) <= parseInt(document.getElementById(”Area”).style.top) ){
document.getElementById(”obj1-”+i).style.top=document.getElementById(”Area”).style.top;
VY*=-1;
}
if( parseInt(document.getElementById(”obj1-”+i).style.top)+10 >= parseInt(document.getElementById(”Area”).style.top)+parseInt(document.getElementById(”Area”).style.height) ){
document.getElementById(”obj1-”+i).style.top=parseInt(document.getElementById(”Area”).style.top)+parseInt(document.getElementById(”Area”).style.height)-10;
VY*=-1;
}
}
}
Как она работает? Очень просто! В цикле мы пробегаем по всем элементам, при этом выполняем следующие действия:
1. Прибавляем к X координате объекта его горизонтальную скорость, которую берем из массива VX.
2. Прибавляем к Y координате объекта его вертикальную скорость, которую берем из массива VY.
3. Проверяем, не вышел ли левый край объекта за левый край сосуда, если вышел, то ставим объект на границу и инвертируем скорость. Т.е. если летел, к примеру, шарик и он вылетел за левую границу, то мы возвращаем шар на край сосуда и пинаем его в обратную сторону, так, что модуль его горизонтальной скорости не меняться- меняется только знак
4. Аналогично, только мы проверяем вылет за правую границу.
5. В принципе тоже самое, только здесь все происходить в вертикальной плоскости- мы определяем вылет за верхнюю границу и если таковой факт был инвертируем вертикальную составляющую скорости.
6. Аналогично действию №5, за исключением того, что проверка происходит на вылет за нижнюю грань.
Смело копируем функцию перед функцией Timer() и пробуем запустить нашу маленькую демонстрацию (см. рисунок).

Рис. Тестовая анимация.
Заключение
В этой статье я попытался объяснить базовые принципы анимации с помощью JavaScript. Если Вам что-то непонятно, то не расстраивайтесь в следующих уроках курса я на более интересных и практичных примерах покажу как делать практичные вещи, которые будет не стыдно поставить на свой сайт а пока экспериментируйте! Также хотелось бы написать статью о оптимизации кода, ибо наш вариант далеко не идеален, поэтому ждите.
Если возникнут какие-либо вопросы то обращайтесь на форум www.programmersforum.ru, либо пишите на почтовый ящик редакции. Я или кто-либо другой попытаемся Вам помочь.
Статья из четвертого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
1st
Июл
Введение в Sсheme. Часть 1
Краткое описание функционального языка программирования Sсheme. Рассчитано на программистов, имеющих навыки программирования в императивном стиле.
by Utkin
В 1970 году Гай Стил (Guy L. Steele) и Джеральд Сассман (Gerald Jay Sussman) из Массачусетского технологического института начали работу на новым языком программирования. Тогда Джеральд Сассман уже имел ученую степень, а его помощник Гай Стил являлся студентом данного института. В 1975 году работы были закончены и получили свое дальнейшее воплощение в принципах работы СБИС (в 1978 году) и CAD-системах. Идеи, положенные в эти работы, позже использовались для конструирования элементов космических аппаратов и проведения экспериментов в космосе (с использованием элементов искусственного интеллекта). В 1984 году большое количество версий в разных институтах заставило разработчиков выработать единый стандарт (при участии Массачусетского технологического института и университета Индианы). Такие серьезные сферы дали хороший старт языку, однако его распространение сдерживалось низкой скоростью интерпретации. В 90-х годах прошлого века были разработаны новые технологии компиляции, что позволило повысить эффективность Scheme путем компиляции в байт-код и машинные коды (хотя экспериментальные компиляторы со Scheme существовали и ранее). На данный момент производительность Scheme в целом выше, чем у Java (учитывая, что языки разных стилей, то такое сравнение условно).
Scheme («скиим»)
это функциональный язык программирования, диалект Лиспа. Особенности: разумный минимализм, интерактивность, однородность синтаксиса (лисповые списки), высокий уровень абстрагирования, возможность писать программы оторванные от конкретной платформы, «строгий» язык (требует придерживаться определенного стиля), позволяет использовать разные парадигмы программирования и много чего еще особенного.
В дальнейшем будем рассматривать язык на примере PLT Scheme. Данная среда выбрана не случайно (имеются десятки других). Она бесплатна, имеет широкое распространение, большой набор библиотек и позволяет компилировать программы в exe-файлы. Взять можно отсюда: http://www.plt-scheme.org/ IDE в PLT Scheme называется DrScheme, имеет минималистический вид, однако содержит практически все, что необходимо для работы программиста. Редактор имеет два окна – первое для записи программы, второе информационное и окно интерактивного режима – команды языка, введенные в него, исполняются немедленно.
Также в комплекте имеется MrEd – система для создания переносимого графического интерфейса пользователя. Далее будет следовать краткое описание языка, настолько, насколько это возможно в рамках статьи. Все примеры, приведенные ниже можно сразу опробовать в окне интерактивного режима.
Синтаксические элементы и что еще обязательно нужно знать
Прежде чем, начать описание синтаксических элементов следует обратить внимание на некоторые вещи. Все вычисления, в процедурах, аргументах всегда осуществляются слева направо. Язык имеет поддержку типов, однако, типизация скрытая (динамический контроль типов). Объекты (включая процедуры – сама программа также может являться объектом данных) имеют неразрушаемую природу, однако переполнение памяти не возникает за счет того, что объекты могут быть перезаписаны, в случае, если больше не будут участвовать в вычислительном процессе. На данный момент все реализации Scheme используют хвостовую рекурсию, это позволяет выделять на выполнение рекурсионных вызовов ограниченный размер памяти. Такие вызовы позволяют не использовать специализированные операции цикла (могут быть получены за счет автоматического преобразования хвостовой рекурсии в итерации). Все функции являются самостоятельными объектами (могут создаваться динамически, сохранены в структурах данных, возвращены как результаты функций и т.д.). Примером таких языков являются Common Lisp и ML. Параметры процедур всегда передаются по значению (в противовес Haskell, который позволяет откладывать вычисление параметра, до тех пор, пока он не потребуется явно).
Модель арифметических вычислений создана таким образом, чтобы максимально не зависеть от конкретных аппаратных платформ. В Scheme каждое целое число является рациональным, каждое рациональное число является реальным, а каждое реальное к тому же является еще и комплексным. Поэтому разница между различными типами чисел, возведенная в ранг абсолютизма в императивных языках, здесь не проявляется.
Программа является списком, элементы списка отделяются друг от друга пробелом, сам список заключен в скобки. Операции представляется списком, в котором символ операции (который, в сущности, является именем функции) всегда занимает первое место в списке (префиксная форма или польская нотация):
Пример.
(+ 2 2) Результатом будет 4.
(+ 2 (* 2 2)) Результатом будет 6.
Особенностью такой записи является тот факт, что операция может быть применена к неограниченному количеству входящих параметров, можно написать и (+ 2 2 2 2 2 2 2 2 2 2 2) (сравните 2 + 2). Это приводит к тому, что программы, написанные на Scheme, могут являться данными для других программ написанных на Scheme. Для функциональных языков программирования является традицией писать интерпретаторы/компиляторы с них на этих же языках программирования.
PLT Scheme не делает разницы между идентификаторами, набранными в разных регистрах. В тоже время правила образования идентификаторов может различаться для разных версий и реализаций языка, однако есть общее требование – идентификатор не должен начинаться с цифры. Примеры идентификаторов:
lambda
q
list->vector
soup
+
V17a
<=?
a34kTMNs
the-word-recursion-has-many-meaningsДля идентификаторов разрешено использовать символы. Можно использовать, например, такой идентификатор ——>, однако по соглашению фрагмент -> делит идентификатор на две части и говорит о преобразовании типа, например list->vector для функции может трактоваться как преобразование списка в вектор (элементы которого являются элементами списка). Помимо пробелов и переходов на новую строку допускается также использовать символы табуляции, все эти элементы обычно используются для улучшения восприятия текста программы и в качестве разделителей лексем языка.
Одним из важных понятий языка является понятие представления объектов. Если в программе, это всего лишь поток символов, то внутренне объект может представляться совершенно иным способом. Далее, представление объектов не обязательно уникально, так число 28 может быть представлено как #e28.000 или #x1c. Список (1 2) можно представить как (01 02) или (1. (2. ())) Здесь () является пустым списком. Однако, список (+ 1 2) не является эквивалентом числа 3, это список, состоящий из трех элементов (результат вычисления которого является числом 3). С одной стороны, это может путать на начальном этапе знакомства с языком, но с другой это источник его мощи, данные могут являться программой, программа может являться данными.
Переменные перед использованием должны быть объявлены: (define x 28) В данном случае мы определяем переменную х со значением 28. В Дальнейшем допускается неоднократное переопределение (например, (define x 38)).
Точка с запятой (;) служит для обозначения комментария, который продолжается до конца строки и является неисполняемым оператором языка. Поэтому комментарии посреди лексемы языка не допускаются.
Небольшой пример:
;;; процедура FACT вычисляет факториал
;;; из неотрицательного целого числа.
(define fact
(lambda (n)
(if (= n 0)
1 ;Base case: return 1
(* n (fact (- n 1))))))Вызов факториала (fact 100) даст результат:
933262154439441526816992388562667004907159682643816214685929638952175999932299156089414639761565182862536979208272
23758251185210916864000000000000000000000000
Это говорит о том, что строгий диапазон для чисел не установлен и ограничен только объемом памяти и Вашим временем (кстати, считает за вполне приемлемое время), на операции над ними (справедливо для целых чисел).
Существует соглашение, по которому предикаты (элементы, возвращающие значения Истина/Ложь) должны именоваться с вопросительным знаком на конце.
Ну и еще что нужно знать об основных синтаксических элементах: *. + — могут использоваться в идентификаторах (например, предыдущем примере мы могли бы обозначить идентификатор функции как fact+ или fact+1).
Одинарная кавычка (‘) используется для абсолютного значения, которое вычислять не требуется (допускается второе обозначение данной функции — quote). Например, имеется элемент списка (х) и имеется функция с аналогичным именем, чтобы в списке х не вычислялся, используется данная функция.
Чтобы было понятней, объявим такую функцию:
(define (prostoX x) ( quote x))Вызовем ее
(prostoX 100) Результат будет х, а не 100
(quote a) Результат a
(quote #(a b c)) Результат #(a b c)
(quote (+ 1 2)) Результат (+ 1 2), а не 3
'(quote a) Результат (quote a)Можно заставить Scheme вычислять частично, для этого используется запятая:
`(list ,(+ 1 2) 4) Результат (list 3 4), то есть выражение перед запятой (+1 2) было вычислено.
Более сложный пример
(let ((name 'a)) `(list ,name ',name)) Результат (list a (quote a))Числовые, символьные, строковые и булевые константы «квотировать» не допускается.
Символ двойной кавычки (”) используется для ограничения строковых констант.
Символ обратного слеша (\) используется в строковых константах.
[ ] { } | Левые и правые квадратные скобки, изогнутые скобки и вертикальный штрих зарезервированы для возможных будущих расширений языка.
Символ шарп (#) используется для множества целей в зависимости от символа, который немедленно следует за этим:
- #t #f — обозначение булевых констант;
- # \ — вводит символьную константу;
- #( — вводит векторную константу;
- #e #i #b #o #d #x — используются для обозначения чисел.
Объявление процедур:
(lambda <formals> <body>)
<Formals> — список формальных параметров
<Body> — последовательность из одного или более выражений.
Лямбда-выражение считается процедурой, не имеющей имени. Результат(ы) последнего выражения в теле будет возвращен как результат(ы) вызова процедуры.
(lambda (x) (+ x x)) Есть описание процедуры без имени, имеющий один входящий параметр и возвращающий удвоенное значение переменной х.
((lambda (x) (+ x x)) 4) Результат 8 (последнее выражение, передано в процедуру)
Определим такую функцию
(define reverse-subtract
(lambda (x y) (- y x)))Ее вызов с параметрами (reverse-subtract 7 10) Результат результат 3 (для последнего выражения происходит обмен параметров в списке). Таким образом, сначала определяется безымянная процедура с двумя входящими параметрами х и y. Ее задача вычитать из y x. Далее, ей просто присваивается имя reverse-subtract, которую мы и вызвали с параметрами 7 и 10. х получает значение 7, у соответственно 10, затем мы вычитаем из y x тело (- у х), то есть (- 10 7). Результатом будет 3.
Определим следующую функцию:
(define add4
(let ((x 4))
(lambda (y) (+ x y))))Ее вызов с параметрами (add4 6) Результат 10. Обратите внимание – внутри функции определяется локальная переменная х, имеющая значение 4. Данная переменная существует только в рамках add4.
Lambda удобно использовать для образования хвостовой рекурсии – один из важнейших элементов функционального программирования. Для императивного программирования хвостовую рекурсию можно выразить через цикл. Также lambda в связке с define можно рассматривать как аналог механизма интерфейсов ООП.
Допускается и короткая форма функций, без использования процедур lambda: (define (имя параметры) (тело_функции)). Определим функцию возведения в квадрат: (define (square x) (* x x)). Вызовем ее (square 10), в результате получим 100. Вызовем ее еще раз (Square 10.5), в результате получим 110.25. Код может следовать сразу друг за другом без всяких приведений типов и никаких фокусов с параметризацией здесь не требуется совершенно. Хотелось бы на этом заострить внимание: то, что в последнее время привносится как новая веха ООП – параметризация, существует в функциональном программировании чуть ли не с момента его возникновения. Однако в функциональном программировании оно представлено на совершенно ином уровне.
Еще один момент, касающийся идентификаторов – в PLT Scheme все идентификаторы могут содержать дополнительные символы. Это значит, что вместо square можно смело определить функцию КВАДРАТ, и вообще можно переписать практически все ключевые элементы языка, используя национальный алфавит.
Условные выражения представляются в следующих формах:
(if <тест> <следствие> <альтернативный_вариант>)
Здесь все просто и аналогично другим языкам программирования:
(if (> 3 2) 'да 'нет) Результат да (обратите внимание на одинарные кавычки)
(if (> 2 3) 'да 'нет) Результат нет
(if (> 3 2)
(-3 2)
(+ 3 2)) Результат 1 (3 больше 2? Если да, то выполним (- 3 2), то есть получим в итоге 1).Можно использовать также cond:
(cond ((> 3 2) 'больше)
((<3 2) 'меньше)) Результат больше
(cond ((> 3 3) 'больше)
((<3 3) 'меньше)
(else 'равно)) Результат равноОбщая форма: (cond выражение1 выражение2 … выражениеN), где выражение состоит из ((условие) (действие)). Ветвь else будет выполнена в случае, если ни одно из предыдущих условий не было выполнено. Cond аналогична множественному использованию if (изначально конструкции if не было, и все условия обсчитывали через cond). В качестве задания: попробуйте выразить if через использование cond.
Давайте рассмотрим такой фрагмент программы:
(define (PAIR (a b)
(lambda (msg)
(case msg ; конструкция case для каждого значения msg
; выполняет соответствующее действие
((first) a) ; если сообщение – символ first, возвратить a
((second) b))))В зависимости от msg будет возвращено соответствующее значение, то есть фактически полностью соответствует case из императивных языков (таких как С++ или Дельфи). Case аналогично cond поддерживает else – ветвь которая будет обязательно выполнена в случае, если ни одна из предыдущих выполнена не была.
Можно составлять сложные условия за счет грамотного использования and и or:
(and (= 2 2) (> 2 1)) Результат #t (истина). 2=2 и 2>1? Истина
(and (= 2 2) (< 2 1)) Результат #f (ложь). 2=2 и 2<1? Ложь
(and 1 2 'c '(f g)) Результат (f g) (список не вычисляется из-за одинарных кавычек)
(and) Результат #t
(and (< 2 2) (= 2 2)) Результат #fВыражения оцениваются слева направо до первого ложного утверждения. Если все утверждения верны, то возвращается последний входящий параметр функции (у нас это пример со списком (f g)). Если and не имеет входящих утверждений, будет возращено #t (истина).
(or (= 2 2) (> 2 1)) Результат #t
(or (= 2 2) (< 2 1)) Результат #t
(or #f #f #f) Результат #fВыражения оцениваются слева направо до первого истинного утверждения (оставшиеся не рассматриваются). Если все выражения ложны, будет возвращено последнее из них. Теперь немного о присваивании переменных. Вообще-то, в чистом функциональном программировании переменных вообще существовать не должно, но подавляющее большинство функциональных языков программирования признают пользу существования переменных и вводят различные механизмы для их использования. Присваивание в PLT Scheme осуществляется таким образом:
(define x 2)
(set! x 4)
(+ x 1)Результат 5. Ничто нам не мешает переопределить переменную x через define, но все же необходимо помнить, что define не эквивалентно set! (хотя в нашем случае и приводит к одному результату). Разница заключается в том, что define связывает идентификатор переменной с ее новым значением (предыдущее значение переменной будет уничтожено в результате сборки мусора), а set! присваивает значение уже существующей. Вообще, следует учитывать, что имя переменной и ее значения связаны не напрямую между собой. В частности, это проявляется в том, что переменная может существовать по имени, без значения (проявляется, например, при операции quote). При этом нет точных рамок между именем переменной и именем функции. И через define имя переменной можно переопределить как имя функции.
Теперь рассмотрим более подробно конструкцию let. Собственно у нее ее два родственника let* и letrec с тем же синтаксисом (let ((определение_переменной1) (определение_переменнойN)) (тело)). Разница в них только в уровнях видимости связанных ими переменных. Это позволяет строить блочные структуры на манер принятый в структурном программировании. Короткая форма такова: (let (определение переменной) выражение), где определение переменной выглядит все в том же списочном стиле (переменная значение).
(lambda <formals> <body>)
<Formals> — список формальных параметров
<Body> — последовательность из одного или более выражений.
Лямбда-выражение считается процедурой, не имеющей имени. Результат(ы) последнего выражения в теле будет возвращен как результат(ы) вызова процедуры.
(lambda (x) (+ x x)) Есть описание процедуры без имени, имеющий один входящий параметр и возвращающий удвоенное значение переменной х.
((lambda (x) (+ x x)) 4) Результат 8 (последнее выражение, передано в процедуру)
Определим такую функцию
(define reverse-subtract
(lambda (x y) (- y x)))Ее вызов с параметрами (reverse-subtract 7 10) Результат результат 3 (для последнего выражения происходит обмен параметров в списке). Таким образом, сначала определяется безымянная процедура с двумя входящими параметрами х и y. Ее задача вычитать из y x. Далее, ей просто присваивается имя reverse-subtract, которую мы и вызвали с параметрами 7 и 10. х получает значение 7, у соответственно 10, затем мы вычитаем из y x тело (- у х), то есть (- 10 7). Результатом будет 3.
Определим следующую функцию:
(define add4
(let ((x 4))
(lambda (y) (+ x y))))Ее вызов с параметрами (add4 6) Результат 10. Обратите внимание – внутри функции определяется локальная переменная х, имеющая значение 4. Данная переменная существует только в рамках add4.
Lambda удобно использовать для образования хвостовой рекурсии – один из важнейших элементов функционального программирования. Для императивного программирования хвостовую рекурсию можно выразить через цикл. Также lambda в связке с define можно рассматривать как аналог механизма интерфейсов ООП.
Допускается и короткая форма функций, без использования процедур lambda: (define (имя параметры) (тело_функции)). Определим функцию возведения в квадрат: (define (square x) (* x x)). Вызовем ее (square 10), в результате получим 100. Вызовем ее еще раз (Square 10.5), в результате получим 110.25. Код может следовать сразу друг за другом без всяких приведений типов и никаких фокусов с параметризацией здесь не требуется совершенно. Хотелось бы на этом заострить внимание: то, что в последнее время привносится как новая веха ООП – параметризация, существует в функциональном программировании чуть ли не с момента его возникновения. Однако в функциональном программировании оно представлено на совершенно ином уровне.
Еще один момент, касающийся идентификаторов – в PLT Scheme все идентификаторы могут содержать дополнительные символы. Это значит, что вместо square можно смело определить функцию КВАДРАТ, и вообще можно переписать практически все ключевые элементы языка, используя национальный алфавит.
Условные выражения представляются в следующих формах:
(if <тест> <следствие> <альтернативный_вариант>)
Здесь все просто и аналогично другим языкам программирования:
(if (> 3 2) 'да 'нет) Результат да (обратите внимание на одинарные кавычки)
(if (> 2 3) 'да 'нет) Результат нет
(if (> 3 2)
(-3 2)
(+ 3 2)) Результат 1 (3 больше 2? Если да, то выполним (- 3 2), то есть получим в итоге 1).Можно использовать также cond:
(cond ((> 3 2) 'больше)
((<3 2) 'меньше)) Результат больше
(cond ((> 3 3) 'больше)
((<3 3) 'меньше)
(else 'равно)) Результат равноОбщая форма: (cond выражение1 выражение2 … выражениеN), где выражение состоит из ((условие) (действие)). Ветвь else будет выполнена в случае, если ни одно из предыдущих условий не было выполнено. Cond аналогична множественному использованию if (изначально конструкции if не было, и все условия обсчитывали через cond). В качестве задания: попробуйте выразить if через использование cond.
Давайте рассмотрим такой фрагмент программы:
(define (PAIR (a b)
(lambda (msg)
(case msg ; конструкция case для каждого значения msg
; выполняет соответствующее действие
((first) a) ; если сообщение – символ first, возвратить a
((second) b))))В зависимости от msg будет возвращено соответствующее значение, то есть фактически полностью соответствует case из императивных языков (таких как С++ или Дельфи). Case аналогично cond поддерживает else – ветвь которая будет обязательно выполнена в случае, если ни одна из предыдущих выполнена не была.
Можно составлять сложные условия за счет грамотного использования and и or:
(and (= 2 2) (> 2 1)) Результат #t (истина). 2=2 и 2>1? Истина
(and (= 2 2) (< 2 1)) Результат #f (ложь). 2=2 и 2<1? Ложь
(and 1 2 'c '(f g)) Результат (f g) (список не вычисляется из-за одинарных кавычек)
(and) Результат #t
(and (< 2 2) (= 2 2)) Результат #fВыражения оцениваются слева направо до первого ложного утверждения. Если все утверждения верны, то возвращается последний входящий параметр функции (у нас это пример со списком (f g)). Если and не имеет входящих утверждений, будет возращено #t (истина).
(or (= 2 2) (> 2 1)) Результат #t
(or (= 2 2) (< 2 1)) Результат #t
(or #f #f #f) Результат #fВыражения оцениваются слева направо до первого истинного утверждения (оставшиеся не рассматриваются). Если все выражения ложны, будет возвращено последнее из них. Теперь немного о присваивании переменных. Вообще-то, в чистом функциональном программировании переменных вообще существовать не должно, но подавляющее большинство функциональных языков программирования признают пользу существования переменных и вводят различные механизмы для их использования. Присваивание в PLT Scheme осуществляется таким образом:
(define x 2)
(set! x 4)
(+ x 1)[/c
(let ((x 2)) (* x 2)) Результат 4. Создаем переменную х=2, умножаем на 2 и передаем значение. Сам х при выходе из данного выражения будет разрушен. Let позволяет создавать сколько угодно переменных, действие которых будет распространяться исключительно на тело определения (при этом в рамках одного определения не допускается использовать несколько переменных с одинаковыми идентификаторами).(let ((x 2) (y 3))
(* x y)) Результат 6
(let ((x 2) (y 3))
(let ((x 7)
(z (+ x y)))
(* z x)))
Результат 35. В первом блоке определим х=2, у=3, переходим к исполнению тела let. Создадим второй х со значением 7, затем определяем еще одну переменную второго блока z, которая будет равна x+y (число 5) первого блока (поскольку х второго блока имеет силу только в теле второго блока, но не на этапе определения переменных этого же блока). Приступаем к исполнению тела второго блока – умножаем 5 (в данном случае, переменная z) на 7 (переменная х второго блока). Результат 35.
Как видно из примера, допускается неограниченная глубина вложенности let, внутри каждого определения допускается свободное повторение идентификаторов по отношению к другим let. В Scheme let часто используется как аналог программных скобок ({-}, begin-end) императивных языков программирования. Как правило, let используется чаще родственных ей let* и letrec.
Рассмотрим пример с let*
(let ((x 2) (y 3))
(let* ((x 7)
(z (+ x y)))
(* z x)))Результат 70. В первом блоке определим х=2 и у=3. Далее конструкция let* определяет переменную х=7, действие которой распространяется на все определения переменных справа и на тело let*, таким образом, z=7 (новый х)+3 (у из первого блока)=10. Приступаем к выполнению тела let* - z (число 10) умножаем на х блока let* (число 7). Результат 70.
Что касается letrec, ее особенность в том, что переменная получает свое значение не мгновенно, а в момент, когда она будет необходима (соответственно в теле переменная может получать разные значения в зависимости от того выражения, каким она должна инициализироваться). Это удобно в случае многочисленных рекурсионных вызовов.
(letrec ((even?
(lambda (n)
(if (zero? n)
#t
(odd? (- n 1)))))
(odd?
(lambda (n)
(if (zero? n)
#f
(even? (- n 1))))))
(even? 88))Данный пример определяет четность числа (#t, если четное). Как видно из примера, even? может вычисляться в зависимости от входящего числа через рекурсию. Еще один момент – если Вы заметили, то even? это должна быть переменная или функция, имеющая булевый тип, а 88 есть число (в рамках Scheme – не важно какое, считайте, что все числа есть комплексные величины). Здесь видна работа letrec, для тела вычисляется even? определенная не как переменная, а как функция (через lambda). Letrec часто используют для получения значения переменной через рекурсионные вызовы. Эта конструкция имеет один подводный камень – поскольку все параметры передаются по значению, должны существовать однозначные условия для получения результата. Никаких двусмысленностей в letrec быть не должно (могут возникнуть, в частности, при комбинациях родственников letrec, let и let*).
Одной из важных особенностью функциональных языков программирования является концепция функций – иными словами процедуры в обычном понимании в функциональном программировании быть не должно. Выражения и функции получают параметры и передают результат. Однако на практике часто возникают ситуации, когда результат либо не требуется, либо не определен, либо просто не имеет смысла. Самым простым примером является вывод информации на экран. Какой результат может в данном случае получить функция вывода сообщения на экран? В тоже время отсутствие результата (либо возникновение ситуации, когда результат работы функции определить невозможно) может привести программу к краху – следующая функция не сможет получить входящий параметр (либо не сможет определить что это за параметр). Явление, при котором функция проявляет себя каким-либо образом помимо передачи результата, называется побочными эффектами (явлениями). В чистом функциональном программировании побочных явлений быть не должно в принципе (например, побочным эффектом является присваивание переменной какого-либо значения, создание объектов без их непосредственной передачи (так себя ведет define), ввод и вывод данных и т.д.). Специально для решения подобных проблем существует конструкция (begin (выражение1) … (выражениеN)), все вычисления в которой осуществляются последовательно и строго слева направо. Особенностью данной конструкции является результат – он всегда будет возвращен для последнего выражения.
Пример:
(define x 0)
(begin (set! x 5)
(+ x 1)) Результат 6 (5+1)(begin (display "4 plus 1 equals ")
(display (+ 4 1))) Результат 5 (4+1), проигнорировав результаты вывода на экран посредством display (при этом сама строка будет напечатана). Begin также удобно использовать при создании законченных блоков, содержащих несколько выражений (например в If или cond) как замена let, с той лишь разницей, что для данного блока новых переменных не создается (соответственно и не разрушаются).
Рассмотрим итерации. Хотя хвостовая рекурсия может быть преобразована в цикл (при правильном ее составлении), циклы в Scheme существуют также и в общей форме. Один из них:
(do ((<переменная1> <инициализатор_переменной1> <шаг_приращения1>)
...)
(<тест> <выражение> ...)
<операторы_языка> ...)Сразу стоит обратить внимание, на то, что приращивать можно не одну переменную и условие для выхода из цикла тоже может быть не одно.
(do ((vec (make-vector 5))
(i 0 (+ i 1)))
((= i 5) vec)
(vector-set! vec i i)) Результат вектор #(0 1 2 3 4), здесь создается вектор и переменная i
(let ((x '(1 3 5 7 9)))
(do ((x x (cdr x))
(sum 0 (+ sum (car x))))
((null? x) sum)))
Результат 25, проводиться подсчет списка. Здесь создается две переменные х (обратите внимание, переменная цикла инициализируется переменной, объявленной через let) и sum.
Также если рассмотреть конструкцию let более внимательно, то можно обнаружить, что с помощью нее также можно формировать итеративные процессы. Для этого определяемую переменную можно представить как функцию (через ее инициализатор) и вызывать ее для каждого упоминания в теле let (через условные операторы cond или if).
Несмотря на то, что все параметры в функции передаются по значению, есть возможность отложить вычисление параметров до момента их действительного использования. Плюсов от этого как минимум два: первое – это увеличение скорости вычислений (при грамотном использовании) и второе – решение задач, которые нельзя вычислить обычным способом. Увеличение скорости возможно, в случае, если в функцию передается несколько параметров и часть из них напрямую влияет на логику работы функции. Допустим, первый параметр функции однозначно говорит о том, что результат ее работы известен (например, частный случай), и в дальнейшем ничего вычислять в рамках данной функции не требуется. Если передавать все параметры по значению, то в момент входа в функцию, должны быть известны все параметры, значит, все выражения должны быть вычислены. Даже если как в нашем абстрактном примере эти параметры для получения результата не понадобятся. Можно конечно и посчитать, но не следует забывать, что в функциональном программировании рекурсия обычное дело, а это либо чистая рекурсия, либо итеративный процесс, и то и другое медленно. Поэтому прирост скорости может достигать больших величин (а до недавнего времени в функциональном программировании это был очень актуальный вопрос). Что касается дополнительных возможностей, продолжим рассмотрение все того же примера. Что если выполнение одного или нескольких параметров невозможно в конкретный момент вычислительного процесса? Допустим, в выражении происходит деление на нуль. Решить такую задачу обычным способом невозможно. Однако, есть математические выкладки, говорящие о том, что функция имеет решение (потому что ее результат в данном случае зависит от другого параметра, например общий коэффициент, который в данный момент равен нулю, тогда результат функции также будет равен нулю независимо от остальных параметров). Если отложить на некоторое время вычисление остальных параметров и работать с тем, что влияет на логику вычислений, то функция способна вернуть корректный результат, даже если вычисление остальных параметров может привести к фатальной ошибке.
В Scheme отложить вычисление можно через (delay (выражение)). Выражение вычислено не будет до конструкции force (синтаксис аналогичен). Force требует немедленного вычисления выражения (обычно используется в связке с delay).
Как видите, между delay и force может находиться произвольное число выражений, лишь бы p по-прежнему оставалось актуальным (то есть в нашем случае force должно наступить в рамках let, иначе после p перестанет существовать). На самом деле пользоваться delay и force легко, главное чтобы каждое обращение к не вычисленному параметру сопровождалось force.
Подобно многим языкам программирования Scheme поддерживает макроопределения (макросы), позволяющие образовывать новые типы выражений. Можно переопределить большинство стандартных конструкций, с помощью уже известной нам (define новое_имя наименование_конструкции). При этом конструкция под старым именем тоже сохраняется. Возьмем наш факториал:
Теперь fact можно вызывать как под старым именем, так и под именем mmm. Scheme обладает мощными средствами для образования новых возможностей языка на основе макроопределения ключевых слов (не просто синтаксическая замена), но в связи со сложностью и большим объемом материала мы далее макросы рассматривать не будем. Если есть желание, то описание работы с макросами можно найти в большой и подробной справке по PLT Scheme (справочная система называется Help Desk).
И традиционная строчка кода:
Список сокращенных обозначений и терминов, использованных в статье
СБИС – сверхбольшие интегральные схемы.
CAD - Computer Aided Design - компьютерная поддержка конструирования, предполагает объемное и плоское геометрическое моделирование, инженерный анализ на расчётных моделях высокого уровня, оценку проектных решений, получение чертежей.
Java – язык программирования.
Цикл – разновидность управляющей конструкции в высокоуровневых языках программирования, предназначенная для организации многократного исполнения набора инструкций. Также циклом может называться любая многократно исполняемая последовательность инструкций, организованная любым способом (например, с помощью условного перехода).
Продолжение следует ...
Обсудить на форуме – Введение в Sсheme. Часть 1
Статья из четвёртого выпуска журнала "ПРОграммист".
Облако меток
реестр ассемблер timer TBitMap SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid поиск canvas файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
