

Последние записи
- Windows 10 сменить администратора
- Рандомное слайдшоу
- Событие для произвольной области внутри TImage
- Удаление папки с файлами
- Распечатка файла
- Преобразовать массив байт в вещественное число (single)
- TChromium (CEF3), сохранение изображений
- Как в Delphi XE обнулить таймер?
- Изменить цвет шрифта TextBox на форме
- Ресайз PNG без потери прозрачности

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
25th
Авг
 История появления и развития интернета
История появления и развития интернета
Закройте дверь
перед всеми ошибками,
и истина не сможет войти.
Рабиндранат Тагор
Своим зарождением Интернет обязан Министерству обороны США и его секретному исследованию, проводимому в 1969 году с целью тестирования методов, позволяющих компьютерным сетям выжить во время военных действий с помощью динамической перемаршрутизации сообщений. Первой такой сетью была ARPAnet, объединившая три сети в Калифорнии с сетью в штате Юта по набору правил, названных Интернет-протоколом (Internet Protocol или, сокращенно, IP).
В 1972 был открыт доступ для университетов и исследовательских организаций, в результате чего сеть стала объединять 50 университетов и исследовательских организаций, имевших контракты с Министерством обороны США.
В 1973 сеть выросла до международных масштабов, объединив сети, находящиеся в Англии и Норвегии. Десятилетие спустя IP был расширен за счет набора коммуникационных протоколов, поддерживающих как локальные, так и глобальные сети. Так появился TCP/IP. Вскоре после этого, National Science Foundation (NSF) открыла NSFnet с целью связать 5 суперкомпьютерных центров. Одновременно с внедрением протокола TCP/IP новая сеть вскоре заменила ARPAnet в качестве «хребта» (backbone) Интернета.
Ну а как же Интернет стал столь популярен и развит, а толчок к этому, а также к превращению его в среду для ведения бизнеса дало появление World Wide Web (Всемирная Паутина, WWW, 3W, вэ-вэ-вэ, три даблъю) — системы гипертекста (hypertext), которая сделала путешествие по сети Интернет быстрым и интуитивно понятным.
А вот идея связывания документов через гипертекст впервые была предложена и продвигалась Тедом Нельсоном (Ted Nelson) в 1960-е годы, однако уровень существующих в то время компьютерных технологий не позволял воплотить ее в жизнь, хотя кто знает, чем бы всё закончилось, если бы эта идея нашла применение?!
Основы того, что мы сегодня понимаем под WWW, заложил в 1980-е годы Тим Бернерс-Ли (Tim Berners-Lee) в процессе работ по созданию системы гипертекста в Европейской лаборатории физики элементарных частиц (European Laboratary for Particle Physics, Европейский центр ядерных исследований).
В результате этих работ в 1990 научному сообществу был представлен первый текстовый браузер (browser), позволяющий просматривать связанные гиперссылками (hyperlinks) текстовые файлы on-line. Доступ к этому браузеру широкой публике был предоставлен в 1991, однако распространение его вне научных кругов шло медленно.
Новым историческим этапом в развитии Интернет обязан выходу первой Unix-версии графического браузера Mosaic в 1993 году, разработанного в 1992 Марком Андресеном (Marc Andreessen), студентом, стажировавшимся в Национальном центре суперкомпьютерных приложений (National Center for Supercomputing Applications, NCSA), США.
С 1994, после выхода версий браузера Mosaic для операционных систем Windows и Macintosh, а вскоре вслед за этим — браузеров Netscape Navigator и Microsoft Internet Explorer, берет начало взрывообразное распространение популярности WWW, и как следствие Интернета, среди широкой публики сначала в США, а затем и по всему миру.
В 1995 NSF передала ответственность за Интернет в частный сектор, и с этого времени Интернет существует в том виде, каким мы знаем его сегодня.
Автор статьи ZEVS
Обсудить статью на форуме
Programming articles
Создание сайтов на шаблонах
Множество вариантов работы с графикой на канве
Шифруем файл с помощью другого файла
Перехват API функций — Основы
Как сделать действительно хороший сайт
Создание почтового клиента в Delphi 7
Применение паскаля для
решения геометрических задач
Управление windows с помощью Delphi
Создание wap сайта
Операционная система unix, термины и понятия
SQL враг или друг
Возникновение и первая редакция ОС UNIX
Оптимизация проекта в Delphi
Ресурсы, зачем нужны ресурсы
Термины программистов 20 века
Советы по созданию собственного сайта с нуля
Шифруем файл с помощью пароля
Фракталы — геометрия природы
Crypt — Delphi программа для шифрования
Рассылка, зачем она нужна и как ее организовать?
Учебник по C++ для начинающих программистов
Уроки для изучения ассемблера
Загадочный тип PCHAR
Средства по созданию сайтов
Операторы преобразования
классов is и as
Borland Developer studio 2006. Всё в одном
Создание базы данных в Delphi, без сторонних БД
Software engineering articles
25th
Делаем динамические тени на OPENGL. Часть 1
![]()
Здравствуйте. В этой статье я хочу рассмотреть создание движка динамического освещения с помощью графической библиотеки OpenGL. Писаться движок будет на Delphi, но это не мешает переписать его на любой другой язык, так как главное, рассматриваемое в статье, это алгоритмы…
Вадим Буренков
vadim_burenkov@mail.ru
Чтобы не тратить время на инициализацию OpenGL и избежать других проблем (например, с настройкой таймеров и рендера в текстуру) я буду использовать движок ZenGL [1]. Впрочем, от него нам многого не понадобится. Итак, приступим…
Инициализация OpenGL в ZenGL
Первым делом качаем ZenGL и создаем в нем простейшее приложение (вы можете найти его в папке LightEngine ресурсов статьи, там же вы найдете ZenGL):
код:
program LightEngine;
uses
zgl_main,
zgl_screen,
zgl_window,
zgl_timers,
zgl_textures,
zgl_textures_jpg,
zgl_sprite_2d,
zgl_mouse,
zgl_keyboard,
zgl_utils;
var
BackTex:zglPTexture; // текстура фона
bTiles:zglTTiles2D; // параметры тайлинга
uses
zgl_main,
zgl_screen,
zgl_window,
zgl_timers,
zgl_textures,
zgl_textures_jpg,
zgl_sprite_2d,
zgl_mouse,
zgl_keyboard,
zgl_utils;
var
BackTex:zglPTexture; // текстура фона
bTiles:zglTTiles2D; // параметры тайлинга
procedure Init;
var n,j:integer;
begin
// отключаем очищение буфера
zgl_disable(COLOR_BUFFER_CLEAR );
// Тут можно выполнять загрузку основных ресурсов
// загрузка текстуры и настройка тайлинга
BackTex:=tex_LoadFromFile( ‘Back.jpg’,0,TEX_DEFAULT_2D);
// параметры тайлов фона
bTiles.Count.X:=7;
bTiles.Count.Y:=5;
bTiles.Size.W:=128;
bTiles.Size.H:=128;
SetLength(bTiles.Tiles,7,5);
&nfor fto=0 to 4 do
&nbsforbsp;&ntob>for j:=0 to 6 do bTiles.Tiles[j,n]:=1;
end;
procedure Draw;
begin
// Тут «рисуем» что угодно 🙂
tiles2d_Draw(BackTex,0,0,BTiles); // отрисовка фона
end;
procedure Update;
begin
// Тут выполняется обработка данных
if key_Press( K_ESCAPE ) then zgl_Exit;
// обновление клавиш
key_ClearState;
Mouse_ClearState;
end;
procedure Timer;
begin
// Будем в заголовке показывать количество кадров в секунду
wnd_SetCaption( ‘LightEngine [ FPS: ‘ + u_IntToStr( zgl_Get(
SYS_FPS ) ) + ‘ ]’ );
end;
procedure Quit;
begin
// Тут выполняется очищение данных
end;
Begin
// Создаем таймер с интервалом 1000мс.
timer_Add( @Timer, 1000 );
// Создаем таймер с интервалом 10мс.
timer_Add( @Update, 10 );
// Регистрируем процедуру, что выполнится сразу после
// инициализации ZenGL
zgl_Reg( SYS_LOAD, @Init );
// Регистрируем процедуру, где будет происходить рендер
zgl_Reg( SYS_DRAW, @Draw );
// Регистрируем процедуру, которая выполнится после завершения
// работы ZenGL
zgl_Reg( SYS_EXIT, @Quit );
// Устанавливаем заголовок окна
// Разрешаем курсор мыши
wnd_ShowCursor( TRUE );
// Указываем первоначальные настройки
scr_SetOptions( 800, 600, REFRESH_MAXIMUM, FALSE, FALSE );
// Инициализируем ZenGL
zgl_Init;
End.
При инициализации мы указываем процедуры в которых будут производится различные действия (инициализация/обработка/очищение) а также параметры окна.
В инициализации загружается текстура и настраивается тайлинг (количество и размер настроен так, чтобы текстура закрывала весь экран). В обработке обновляются состояния мыши и клавиатуры, а также стоит проверка на нажатие ESC. Процедура очищения пока пуста, так как ресурсы движка очищаются самостоятельно.
Другие непонятные процедуры можно посмотреть в справке, которая находится в папке doc движка. Чтобы при компиляции не возникло проблем необходимо указать расположение модулей движка в Project->Options- >Directories/Conditionals->SearchPath, а именно папки zengl/src и zengl/src/PasZLib (см. рис.1). Можно скомпилировать проект, увидеть вы должны следующее (см. рис.2).
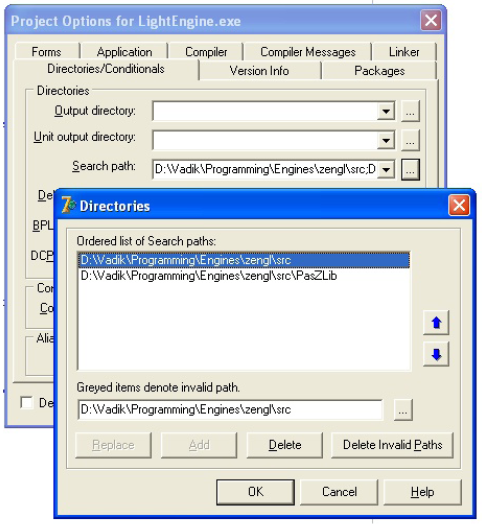
Рис. 1. Пути
Рис. 2. Тайлинг
Немного теории
Теперь перейдем к теории вопроса. В движке мы должны реализовать два типа – источники света и объекты, которые отбрасывают тени (см. рис.3):

Рис. 3. Тень от объекта
Источник света обладает параметрами:
- положение
- радиус
- цвет
- интенсивность
Все объекты являются невыпуклыми многоугольниками. Они имеют:
- локальные координаты вершин
- мировые координаты вершин
- количество вершин
- положение
- угол поворота
Локальные координаты нужны, так как через положение и угол поворота объекта его можно разворачивать.
Для хранения данных об освещенности нам понадобятся два буфера размером в экран. Первый – альфа буфер. В него выводится круглый источник света (см. рис.4):

Рис. 4. Источник света
После этого альфа буфер рисуется во второй буфер – буфер аккумуляции. При этом используется аддитивный режим блендинга, то есть цвета смешиваются. В буфере мы получаем такую картинку (см. рис.5):

Рис. 5. Смешивание источников света
В нем светлые участки – там где свет, а темные – там где тьма. А теперь мы выводим буфер аккамуляции на экран с блендингом MULT. Получается так, что чем светлее цвет, тем он прозрачнее (см. рис.6):

Рис. 6. Рисование с блендингом MULT
Как же делаются тени от объектов? При выводе источника света в альфа буфер на него рисуется форма тени черным цветом. Получается что от круга света «отрезают» кусок (см. рис.7):

Рис. 7. Форма тени на свете
С помощью такого алгоритма получаются тени любой сложности, причем их количество, как и источников света с объектами неограниченно (см.рис.8).
Да будет свет!
Под следующий код сделаем модуль, который и будет отвечать за тени. Назовем его ZGLShadows.

Рис. 8. Сцена с большим количеством теней
Напишем тип света:
код:
type
PLightSource=^TLightSource;
TLightSource=record
position:leVect; // положение
radius:single; // радиус
color:TColorRGB; // цвет
intensivity:single; // интенсивность cвета
prev,next:PLightSource;
end;
PLightSource=^TLightSource;
TLightSource=record
position:leVect; // положение
radius:single; // радиус
color:TColorRGB; // цвет
intensivity:single; // интенсивность cвета
prev,next:PLightSource;
end;
Все данные будут храниться в “prev-next” (двухсвязных) списках (см. рис.9):
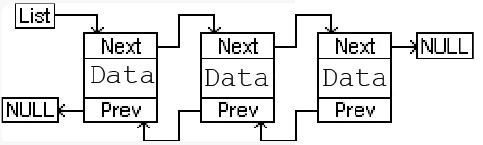
Рис. 9. Списки
Каждый элемент является звеном цепи и имеет указатели на предыдущее и следующее звено. Нам же нужно иметь первый элемент и длину цепи для управления списком:
код:
Var
// Источники света
le_Lights:PLightSource; // список
le_NumLights:integer; // количество
// Источники света
le_Lights:PLightSource; // список
le_NumLights:integer; // количество
Более подробно о такой системе хранения данных можно почитать в Интернете. Как мы видим, у нас появились новые типы данных:
код:
type
TColorRGB=record
r,g,b:single;
end;
TColorRGB=record
r,g,b:single;
end;
Данный тип нужен для хранения цвета в формате rgb, так как его использует OpenGL. ZenGL использует integer для хранения цветов (например $FFFFFF соответствует 1,1,1 в RGB), поэтому нам может понадобится процедура для перевода цвета в RGB:
код:
function IntToRGB(Color:Integer): TColorRGB;
begin
Result.r := ((Color and $FF0000) shr 16) / 255;
Result.g := ((Color and $FF00) shr 8) / 255;
Result.b := (Color and $FF) / 255;
end;
begin
Result.r := ((Color and $FF0000) shr 16) / 255;
Result.g := ((Color and $FF00) shr 8) / 255;
Result.b := (Color and $FF) / 255;
end;
Все координаты будут храниться в типе:
код:
type
leVect=record
x,y:single;
end;
leVect=record
x,y:single;
end;
Подробнее о нем будет написано позже, пока нам понадобится только формирование вектора по x и y:
код:
function le_v(x,y:single):leVect;
begin
result.x:=x;
result.y:=y;
end;
begin
result.x:=x;
result.y:=y;
end;
Перейдем к процедурам управления источниками света:
код:
Function le_CreateLightSource(p:leVect; radius,intensivity:single;
color:TColorRGB):PLightSource;
var t: PLightSource;
begin
new(t);
t.Next:= nil;
t.Prev:= nil;
t.position:=p;
t.radius:=radius;
t.intensivity:=intensivity;
t.color:=color;
t.Next:= le_Lights;
if le_Lights <> nil then le_Lights.Prev:= t;
le_Lights:= t;
Result:= le_Lights;
inc(le_NumLights);
end;
color:TColorRGB):PLightSource;
var t: PLightSource;
begin
new(t);
t.Next:= nil;
t.Prev:= nil;
t.position:=p;
t.radius:=radius;
t.intensivity:=intensivity;
t.color:=color;
t.Next:= le_Lights;
if le_Lights <> nil then le_Lights.Prev:= t;
le_Lights:= t;
Result:= le_Lights;
inc(le_NumLights);
end;
Функция создает источник света в памяти и возвращает указатель на него. Большую часть кода занимает работа со списками.
В следующей процедуре происходит рисование круга света как на рисунке 4. Он рисуется через GL_TRIANGLE_FAN. Первая точка в центре имеет цвет и интенсивность света, далее идут точки по радиусу окружности с нулевым цветом, благодаря чему мы имеем плавный переход цвета:
код:
procedure le_DrawLightSource(t:PLightSource);
var angle:single;
begin
angle:=0;
glBegin(GL_TRIANGLE_FAN);
glColor4f(t.color.r, t.color.g, t.color.b, t.intensivity);
glVertex2f(t.position.x,t.position.y);
glColor4f(0, 0, 0, 0 );
while angle<=Pi*2 do begin
glVertex2f( t.radius*cos(angle) + t.position.x,
t.radius*sin(angle) + t.position.y);
angle:=angle+((PI*2)/le_numSubdivisions);
end;
glVertex2f(t.position.x+t.radius, t.position.y);
glEnd();
end;
var angle:single;
begin
angle:=0;
glBegin(GL_TRIANGLE_FAN);
glColor4f(t.color.r, t.color.g, t.color.b, t.intensivity);
glVertex2f(t.position.x,t.position.y);
glColor4f(0, 0, 0, 0 );
while angle<=Pi*2 do begin
glVertex2f( t.radius*cos(angle) + t.position.x,
t.radius*sin(angle) + t.position.y);
angle:=angle+((PI*2)/le_numSubdivisions);
end;
glVertex2f(t.position.x+t.radius, t.position.y);
glEnd();
end;
Количество треугольников, из которого рисуется круг, задается константой:
код:
const
le_numSubdivisions = 32;
le_numSubdivisions = 32;
Следующая процедура рассчитывает и рисует тень для объектов, но о ней я напишу позже:
код:
procedure le_RenderShadowGeometry(t:PLightSource);
Далее напишем процедуру, которая освобождает память, занятую источником света:
код:
procedure le_FreeLightSource(t:PLightSource);
var DelT: PLightSource;
begin
DelT:= t;
if t.Prev <> nil then t.Prev.Next := t.Next
else le_Lights:= t.Next;
if t.Next <> nil then t.Next.Prev := t.Prev;
Dispose(DelT);
dec(le_NumLights);
t:=nil
end;
var DelT: PLightSource;
begin
DelT:= t;
if t.Prev <> nil then t.Prev.Next := t.Next
else le_Lights:= t.Next;
if t.Next <> nil then t.Next.Prev := t.Prev;
Dispose(DelT);
dec(le_NumLights);
t:=nil
end;
Следующая процедура вспомогательная, она обрабатывает каждый источник света передаваемой в нее процедурой:
код:
procedure le_EachLightSource(p:le_proc);
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do
begin
tNext:= t.Next;
p(t);
t:= tNext;
end;
end;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do
begin
tNext:= t.Next;
p(t);
t:= tNext;
end;
end;
le_proc – тип процедуры:
код:
type
le_proc=procedure(d:Pointer);
le_proc=procedure(d:Pointer);
Например, данная строчка нарисует все источники света:
код:
le_EachLightSource(@le_DrawLightSource);
Хочу заметить, что при попытке передать в le_EachLightSource процедуру очищения возникнет ошибка, связанная с памятью, поэтому для очищения всех источников света напишем отдельную процедуру:
код:
procedure le_FreeAllLightSources;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do begin
tNext:= t.Next;
le_FreeLightSource(t);
t:= tNext;
end;
end;
var t, tNext: PLightSource;
begin
t:= le_Lights;
while t <> nil do begin
tNext:= t.Next;
le_FreeLightSource(t);
t:= tNext;
end;
end;
Заставим это работать
С типом света мы управились, теперь надо заставить его работать. Объявим следующие переменные:
код:
var // Движок
le_AlphaBuffer: zglPRenderTarget; // буфер для света
le_AccBuffer: zglPRenderTarget; // буфер для сложения
// изображений света
le_DarkColor: integer; // цвет тени
le_AlphaBuffer: zglPRenderTarget; // буфер для света
le_AccBuffer: zglPRenderTarget; // буфер для сложения
// изображений света
le_DarkColor: integer; // цвет тени
В этой процедуре инициализируются буферы для рендеринга. К проекту нужно также подключить модули:
- zgl_textures – создание текстуры-буфера
- zgl_render_target – управление рендерингом
- zgl_primitives_2d – очищение рендер target. Хотя можно было бы просто рисовать QUAD на OpenGL.
- zgl_fx – процедуры управления блендингом
- zgl_sprite_2d – рисование текстур
Напишем процедуру инициализации буферов:
код:
procedure le_InitLightEngine(DarkColor:Integer);
begin
le_DarkColor:=DarkColor;
// инициализация буферов
le_AlphaBuffer:=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
le_AccBuffer :=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
end;
begin
le_DarkColor:=DarkColor;
// инициализация буферов
le_AlphaBuffer:=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
le_AccBuffer :=rtarget_Add( RT_TYPE_FBO, tex_CreateZero(
800,600, 0, TEX_DEFAULT_2D ) , RT_FULL_SCREEN );
end;
le_DarkColor – переменная, которая отвечает за освещенность. К ее смыслу и принципу работы я еще вернусь. Обобщающая процедура полной обработки света:
код:
procedure le_RenderLight(t:PLightSource);
begin
rtarget_Set( le_AlphaBuffer ); // начинаем рендер в буфер
pr2d_Rect(0,0,800,600, 0,255,PR2D_FILL); // очищаем черным
// цветом
le_DrawLightSource(t); // отрисовка источника света
rtarget_Set( nil );
rtarget_Set( le_AccBuffer ); // отрисовка полученного
// изобр-я в буфер аккамуляции
fx_SetBlendMode(FX_BLEND_ADD); // при отрисовке используем
// блендинг для сложения
// интенсивностей источ-в света
ssprite2d_Draw( le_AlphaBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
rtarget_Set( nil );
end;
begin
rtarget_Set( le_AlphaBuffer ); // начинаем рендер в буфер
pr2d_Rect(0,0,800,600, 0,255,PR2D_FILL); // очищаем черным
// цветом
le_DrawLightSource(t); // отрисовка источника света
rtarget_Set( nil );
rtarget_Set( le_AccBuffer ); // отрисовка полученного
// изобр-я в буфер аккамуляции
fx_SetBlendMode(FX_BLEND_ADD); // при отрисовке используем
// блендинг для сложения
// интенсивностей источ-в света
ssprite2d_Draw( le_AlphaBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
rtarget_Set( nil );
end;
И завершающая процедура – вывод буфера с использованием MULT блендинга:
код:
procedure le_FinishRender;
begin
// выводим полученные тени и свет на экран с использованием
// блендинга mult (чем светлее изображение тем прозрачней)
fx_SetBlendMode(FX_BLEND_MULT);
ssprite2d_Draw( le_AccBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
// очищаем буфер для следующего кадра (цветом le_DarkColor!)
rtarget_Set( le_AccBuffer );
pr2d_Rect(0,0,800,600, le_DarkColor,255,PR2D_FILL);
rtarget_Set( nil );
end;
begin
// выводим полученные тени и свет на экран с использованием
// блендинга mult (чем светлее изображение тем прозрачней)
fx_SetBlendMode(FX_BLEND_MULT);
ssprite2d_Draw( le_AccBuffer.Surface, 0,0,800,600,0);
fx_SetBlendMode(FX_BLEND_NORMAL);
// очищаем буфер для следующего кадра (цветом le_DarkColor!)
rtarget_Set( le_AccBuffer );
pr2d_Rect(0,0,800,600, le_DarkColor,255,PR2D_FILL);
rtarget_Set( nil );
end;
Хочу заметить, что очищение le_AccBuffer проводится цветом le_DarkColor. Следовательно, чем светлее этот цвет тем прозрачнее тени (см. рис.10). На изображении видно, что справа фон просвечивается даже там, где света нет, так как le_DarkColor не черный, а серый ($1f1f1f).

Рис. 10. Различный DarkColor
Все, система света написана. Правда, пока без теней от объектов. Теперь проверим ее в действии.
Добавим переменную под управляемый свет:
код:
var
UserLight:PLightSource; // указатель на управляемый свет
UserLight:PLightSource; // указатель на управляемый свет
Создадим его, и еще 4 света в Init:
код:
le_InitLightEngine(0); // инициализируем световой движок
// загружаем источники света
le_CreateLightSource
(le_v(520,550),400,0.3,IntToRGB($FF00FF));
le_CreateLightSource
(le_v(470,50),250,0.5,IntToRGB($FF0000));
le_CreateLightSource
(le_v(200,300),270,1,IntToRGB($00FF00));
le_CreateLightSource
(le_v(640,270),300,0.8,IntToRGB($FFFFFF));
UserLight:=le_CreateLightSource(le_v(0 ,
0),100,0.8,IntToRGB($FFFFFF));
// загружаем источники света
le_CreateLightSource
(le_v(520,550),400,0.3,IntToRGB($FF00FF));
le_CreateLightSource
(le_v(470,50),250,0.5,IntToRGB($FF0000));
le_CreateLightSource
(le_v(200,300),270,1,IntToRGB($00FF00));
le_CreateLightSource
(le_v(640,270),300,0.8,IntToRGB($FFFFFF));
UserLight:=le_CreateLightSource(le_v(0 ,
0),100,0.8,IntToRGB($FFFFFF));
Теперь в Draw напишем рисование теней:
код:
// обработка всех источников света
le_EachLightSource(@le_RenderLight);
// отрисовка теней
le_FinishRender;
le_EachLightSource(@le_RenderLight);
// отрисовка теней
le_FinishRender;
В Update привяжем UserLight к мышке, сделаем изменение размера при нажатии на кнопки мыши и цвета при нажатии на колесико:
код:
if mouse_Down( M_BLEFT ) then
UserLight.radius:=UserLight.radius+3;
if mouse_Down( M_BRIGHT ) then
if UserLight.radius>0 then
UserLight.radius:=UserLight.radius-3;
if mouse_Click( M_BMIDLE ) then begin
UserLight.color.r:=random(100)/100;
UserLight.color.g:=random(100)/100;
UserLight.color.b:=random(100)/100;
end;
UserLight.radius:=UserLight.radius+3;
if mouse_Down( M_BRIGHT ) then
if UserLight.radius>0 then
UserLight.radius:=UserLight.radius-3;
if mouse_Click( M_BMIDLE ) then begin
UserLight.color.r:=random(100)/100;
UserLight.color.g:=random(100)/100;
UserLight.color.b:=random(100)/100;
end;
И наконец, в Quit очищаем источники света:
код:
le_EachLightSource(@le_FreeLightSource);
Запускаем, любуемся результатом (см. рис.11).

Рис. 11. Результат
Заключение
В следующей части статьи я рассмотрю создание теней от объектов, а также оптимизирую код, чтобы добиться большей производительности. Весь исходный код проекта приложен к журналу «ПРОграммист. Пятый выпуск».
Продолжение следует…
Ресурсы
- Страница разработчика ZenGL http://andrukun.inf.ua/zengl.html
- Михалкович С.С. Основы программирования.
Второй семестр 08-09, 2 часть
Обсудить на форуме – Делаем динамические тени на OPENGL. Часть 1
22nd
Авг
Беспроводная сеть масштаба микрорайона. Часть 1

Общаясь с друзьями и знакомыми, работающими в области ИТ, не раз приходилось слышать заявление, что Wi-Fi подходит только для сетей масштаба квартиры или небольшого офиса. В качестве аргументов приводились малая дальность, зависимость от погодных условий, ненадежность оборудования. Примерно такое же мнение бытует о том, что для провайдерских сетей не подходит платформа Windows. Аргументы: высокая ресурсоемкость, ненадежность и вообще неспособность работать в качестве системы биллинга.
Александр
by WildHunter http://airnet.sytes.net

А так ли это? Этот вопрос нас всерьез заинтересовал и подтолкнул к попытке создания беспроводной сети как раз на базе Wi-Fi и Windows. Оговорюсь, что некоторый опыт создания беспроводных сетей у нас уже был, правда, немного другого назначения – корпоративных.
Начали мы естественно с постановки самим себе техзадания:
- Сетевая технология WiFi IEEE 802.11b/g, возможно в будущем 802.11a и 802.11n википедия
- Серверы на базе Windows Server. В качестве основной ОС был выбран Windows Server 2003, как достаточно надежная и неприхотливая система, при этом обеспечивающая нужный функционал википедия
- Максимальная простота развертывания, эксплуатации и администрирования сети.
- Минимальные затраты, поскольку проект некоммерческий и финансирования со стороны не будет, придется обходиться собственными силами и средствами.
- Надежность, производительность и пропускная способность, достаточные для обслуживания городского микрорайона.
Выбор оборудования
Основательно изучив рынок предложений недорогого Wi-Fi оборудования, мы остановили свой выбор на нескольких моделях точек доступа (ТД) от D-Link: DWL-2100AP, DAP-1150 и DAP-1160 http://www.d-link.ru. Основными причинами выбора именно этих точек стали их приемлемая цена, накопленный в России и на Украине большой опыт их эксплуатации, а также наличие большого количества альтернативных прошивок, как от различных производителей оборудования, так и open-source.
Для тестирования было закуплено несколько экземпляров указанных выше точек доступа, а также различных антенн к ним. Началось тестирование в различных режимах, на разных расстояниях, с различными антеннами и прошивками. От «родных» прошивок мы отказались практически сразу, поскольку они рассчитаны как раз на применение в домашних или условиях небольшого офиса, не позволяют менять многие важные параметры (ACK timeout, мощность передатчика, чувствительность приемника и т.д.), а также практически не обеспечивают возможности мониторинга беспроводных соединений.
Точки DWL-2100AP оказались хороши для построения мостов на большие расстояния (до 50 км), но капризными в эксплуатации и несовместимыми со многими другими моделями Wi-Fi устройств. Также у них обнаружилась неприятная проблема: довольно часто при большой нагрузке «слетали» прошивки, а их восстановление оказалось довольно непростой процедурой. В итоге DWL-2100AP была признана нами годной к применению только для организации мостов. Хотя вполне возможно, что нам просто достались неудачные экземпляры.
DAP-1150 – очень простое и надежное устройство, тем не менее отвечающее всем основным критериям хотспота. А с немного доработанной прошивкой от Conceptronic http://www.conceptronic.net эта точка стала практически полностью соответствовать нашим требованиям.

Рис. 1. Точка доступа DAP-1150
Основные характеристики DAP-1150 с прошивкой Conceptronic:
- Стандарты: 802.11b/g, 802.3/802.3u 10Base- T/100Base-TX Ethernet, ANSI/IEEE 802.3 NWay auto-negotiation.
- Интерфейсы: 802.11b/g беспроводная LAN, 1 порт 10/100Base-TX Ethernet LAN
- Диапазон частот: 2.4 – 2.4835 ГГц
- Количество каналов: 13 (ETSI)
- Схемы модуляции:
802.11b: DQPSK, DBPSK, DSSS, CCK
802.11g: BPSK, QPSK, 16QAM, 64QAM, OFDM - Режимы работы: Station – Ad Hoc, Station – Infrastructure, AP, AP Bridge – Point to Point, AP Bridge – Point to MultiPoint, AP Bridge – WDS, Universal Repeater.
- Скорость передачи данных:
802.11g: 6, 9, 12, 18, 24, 36, 48, 54 Мбит/с
802.11b: 1, 2, 5.5, 11 Мбит/с - Чувствительность приемника: до -100dBm
- Выходная мощность передатчика: 20dBm
- Безопасность: WEP, WPA/WPA2, фильтрация МАС-адресов, SSID broadcast disable.
- Дополнительные возможности: IAPP, встроенный Radius-сервер.
DAP-1160 с прошивкой AProuter http://aprouter.com.br превратилась в довольно серьезное устройство с широким функционалом, включающим в себя массу полезных возможностей, от контроля качества WDS- соединений википедия до многофункционального шейпера википедия.

Рис. 2. Точка доступа DAP-1160
Основные характеристики DAP-1160 с прошивкой AProuter:
- Стандарты: 802.11b/g, 802.3/802.3u 10Base- T/100Base-TX Ethernet, ANSI/IEEE 802.3 NWay auto-negotiation.
- Интерфейсы: 802.11b/g беспроводная LAN, 2 порта 10/100Base-TX Ethernet LAN
- Диапазон частот: 2.4 – 2.4835 ГГц
- Количество каналов: 13 (ETSI)
- Схемы модуляции:
802.11b: DQPSK, DBPSK, DSSS, CCK
802.11g: BPSK, QPSK, 16QAM, 64QAM, OFDM - Режимы работы роутера: WISP Client, Bridge, Gateway, Router (WAN Ethernet), Router (WAN Wireless).
- Режимы работы Wireless: Wireless Client, AP, WDS+AP, WDS-Bridge.
- Скорость передачи данных:
802.11g: 6, 9, 12, 18, 24, 36, 48, 54 Мбит/с
802.11b: 1, 2, 5.5, 11 Мбит/с - Чувствительность приемника: до -100dBm
- Выходная мощность передатчика: 20dBm
- Безопасность: WEP, WPA/WPA2, фильтрация МАС-адресов, SSID broadcast disable.
- Дополнительные возможности: IP Aliases, IAPP, Block Relay, Firewall, Traffic Control (шейпер), DDNS, Watchdog.
Антенны ANT24-0700C производства D-Link были выбраны по наилучшему показателю цена/качество в своем классе и из-за небольших размеров:

Рис. 3. Антенна ANT24-0700C
Основные характеристики ANT24-0700C:
- Диапазон частот: 2,4-2,5ГГц
- Сопротивление: 50 Ом
- VSWR: 1.92 (макс.)
- Максимальное усиление: 7dBi
- Допустимая мощность: 1 Вт
- Диаграмма направленности в вертикальной плоскости (Вектор Е): 24 градуса.
- Диаграмма направленности в горизонтальной плоскости (Вектор Н): 360 градусов.
- Разъем: Reverse SMA «мама» (встроенный в антенну), переходник с RP-SMA на RP-TNC (внешний).
- Материал корпуса: ABS, ABS+PC
- Рабочая температура: От -20 до 65 градусов.
Построение сети
После завершения тестирования мы приступили к созданию собственно сети. В качестве базовой была выбрана классическая топология «звезда», центральной точкой которой стала DAP-1160 в режиме Bridge WDS, а «лучами» DAP-1150 в режиме WDS + AP. Использование технологии WDS позволяет получить на каждой точке доступа скорость передачи данных на уровне 1.2-1.4 Мбайт/с, максимальная скорость у клиентов составляет порядка 550-600 кБайт/с. Реальная скорость передачи данных зависит от типа клиентского оборудования и качества беспроводного соединения клиент-ТД, а также от количества клиентов и общей загрузки сети.

Рис. 4. Общая схема сегмента сети
Покрытие каждой ТД составляет (в радиусе, значения указаны при наличии прямой видимости или незначительных препятствий, например деревьев):
- Мобильные устройства (смартфоны, КПК, PSP и т.п.) – до 200м
- Ноутбуки, нетбуки, USB-устройства со встроенными антеннами – до 300м
- Ноутбуки, USB-устройства с внешними (или внутренними дипольными) антеннами – до 1500м
- ТД в режиме клиента с направленными антеннами – до 10км
Установка точек доступа
Естественно, что мы старались устанавливать ТД как можно выше, но не всегда это удается. Кроме того, при установке ТД на самую высокую мачту в округе, есть риск получить прямое попадание в нее молнии, от которого не спасет никакая грозозащита. Поэтому второй фактор, который мы старались учитывать – наличие поблизости громоотводов или более высоких мачт.
Все наши хотспоты стоят на мачтах высотой 4-6 метров, которые расположены на крышах зданий высотой в 5-6 этажей. Рядом есть небольшой массив из 9-этажных зданий, но нам не удалось договориться с местным ОСМД*.
Питание на точки подается по витой паре, обычно из квартир наших клиентов (чтобы избежать бюрократии с ЖЕКами и ОСМД), по этому же кабелю клиенты входят в сеть. Взаимовыгодное сотрудничество: мы получаем место для установки и запитки точки, а клиенты получают VIP-доступ к сети ![]()
* Комментарий автора. Объединение совладельцев многоквартирного дома (ОСМД). Юридическое лицо, созданное владельцами для содействия использованию их собственного имущества и управления, содержания и использования неделимого и общего имущества.
Качество
На следующем скриншоте показаны характеристики соединения с ТД на расстоянии ~1000 метров при прямой видимости (см. рисунок 5):
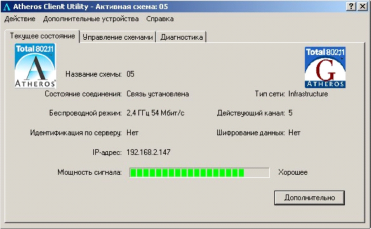
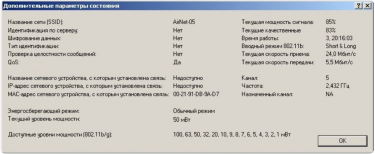
Рис. 5. Качественные характеристики соединения в Atheros Client Utility
ТД: DAP-1150, мощность 20dBm, антенна штыревая 7dBi. Клиент: ноутбук Asus X51RL, WiFi-плата Atheros AR2425, антенна встроенная дипольная 4dBi.
Линк стабильный, текущая скорость линка «гуляет» в пределах 18-36 Мбит/с, это нормально. Скорость загрузки файла с сервера сети держится в пределах 400-500 Кбайт/с. Может показаться, что при средней скорости линка в 24 мегабита это немного, но нужно учитывать особенности технологии Wi-Fi, в которой мегабиты совсем другие, чем в кабельных сетях. Кроме того, режим WDS также вносит свои коррективы, и не в большую сторону. Если вы ожидаете от Wi-Fi волоконно-оптических скоростей, то вам действительно лучше посмотреть в сторону оптики. А Wi-Fi это простая, недорогая, удобная и достаточно качественная связь для всех.
Как это ни странно, но на качество связи почти не влияют погодные условия. Если линк стабилен в хорошую погоду, то он таким и останется в дождь, снег или туман. Возможно, немного снизится скорость, но связь будет. Наш опыт практической эксплуатации показывает следующие результаты: в дождь (даже сильный) или снег уровень сигнала между ТД снижается в среднем всего на 1-4 dBm, туман никакого заметного влияния вообще не оказывает. Замечу, что все точки стоят на примерно одинаковом расстоянии от центральной, которое составляет 800-1200 метров. Для Wi-Fi при прямой видимости это расстояние несерьезное. Так что мнение о влиянии погоды на Wi-Fi сильно преувеличено. Влияние погодных условий становится заметным только на больших расстояниях, от 5 км и более. А вот что действительно отрицательно влияет**: преграды, помехи в эфире, избыточная мощность радиоустройств. Данные факторы обсуждались и не раз, например на http://www.lan23.ru, поэтому подробно мы их здесь рассматривать не будем.
** Комментарий автора. В последнее время технология Wi-Fi в наших краях сделала явный рывок, но непонятно, вперед, назад или «налево». В эфире полный бардак, огромное количество различных устройств, большинство из которых настроены как попало или вообще не настроены. Все это снижает качество связи, а если так и будет продолжаться дальше – связь вообще станет невозможной… Вот какая картина открывается с некоторых наших хотспотов:
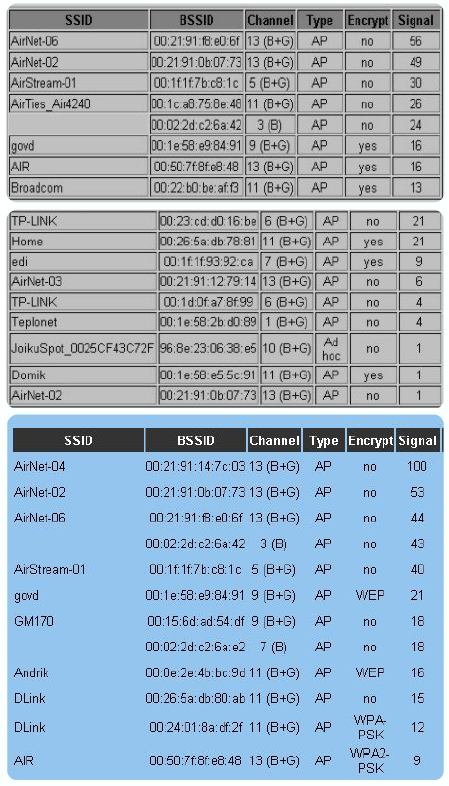
Каждая ТД нормально выдерживает до 20 одновременно работающих клиентов, если нет «тяжелого» трафика, в первую очередь P2P. Если есть, то даже один клиент в состоянии через минуту сделать для всех остальных вход в сеть недоступным, а минуты через 3-5 отправить точку на перезагрузку. ТД почти не критичны к скорости или общему объему трафика, но очень критичны к количеству подключений. Это не значит, что использовать «тяжелый» трафик невозможно. Вполне возможно, если предпринять определенные меры для защиты сети от перегрузок. К таким методам защиты, например, относятся ограничение количества подключений на хост, работа по VPN, а также использование адаптивных шейперов и QoS. Но об этом поговорим в другой раз, так как это более относится к серверным технологиям, а не к Wi- Fi.
Несколько слов о клиентских устройствах
Сейчас на рынке представлена масса самых разнообразных устройств 802.11b/g/n. Из них довольно трудно, но возможно выбрать оптимальный*** вариант. Некоторые устройства, например USB-брелки со встроенной антенной, рассчитаны на работу только внутри помещения и обладают очень ограниченным радиусом действия. Даже одна стена или дерево под окном, для них уже неодолимая преграда.
Другой класс – это устройства с внешними антеннами. Даже со штатными антеннами они показывают неплохую дальность при прямой видимости, а при установке хорошей антенны вполне могут работать на расстояниях, измеряемых километрами. Поэтому при выборе Wi-Fi устройства стоит обратить внимание не только на дизайн, размеры и цену, но в первую очередь – на технические характеристики.
При покупке ноутбука, КПК или любого другого устройства, оснащенного встроенным Wi-Fi, также обязательно интересуйтесь характеристиками Wi- Fi платы, типом и характеристиками встроенной антенны. Зачастую, встроенные платы подходят только для связи внутри комнаты или на расстояниях до 100 метров на открытой местности. Хотя есть и большое количество устройств, оснащенных качественным Wi-Fi и вполне способных поддерживать связь на приличных расстояниях.
Основные характеристики Wi-Fi устройств
- Стандарты, поддерживаемые устройством. От этого зависит универсальность и максимальная скорость передачи данных. В настоящее время в Европе поддерживаются следующие стандарты:
- 802.11b (максимальная скорость 11 Мбит/с)
- 802.11g (максимальная скорость 54 Мбит/с)
- 802.11n (максимальная скорость 150/300 Мбит/с)
- Мощность передатчика и чувствительность приемника. Не стоит чрезмерно увлекаться мощностью, слишком мощный сигнал в городских условиях скорее вреден, так как вызывает многократные отражения и наложения, а также создает массу помех. Да и для здоровья он не очень полезен. На наш взгляд оптимальные значения составляют до 100 мВт (20 dBm) мощности и -95 dBm чувствительности.
- Возможность подключения внешней антенны и характеристики штатной. «Главная часть любого радиоустройства – антенна», это вам скажет любой специалист по любому виду радиосвязи. К Wi-Fi это тоже относится в полной мере. Для нормальной работы (приличной дальности и скорости) любого Wi-Fi-устройства необходима антенна с коэффициентом усиления не менее 4dBi.
- Функционал устройства. К этому относится все, что устройство умеет делать и насколько удобно его использовать. По этому критерию выбор огромный, от самых простых до сложнейших устройств, которые «умнее» вашего компьютера. Главное – достаточно четко представлять, чего вы хотите и сколько вы согласны за это заплатить.
*** Комментарий редакции. Многие задаются вопросом: «Как увеличить дальность связи?». Перво-наперво, при выборе WLAN-аппарата, обратите внимание на то, чтобы выходная мощность была как можно ближе к разрешенной 20 dB. Следующим решающим фактором является чувствительность. У лучших современых аппаратов она находится на уровне -97 dB. Чем выше чувствительность к слабым сигналам, тем выше дальность. Но это палка о двух концах, так как мы не учитываем при этом помеховую обстановку вокруг.
Как влияют эти величины на дальность связи? К примеру, аппарат с мощностью в 20 dB сможет обеспечить в два раза большую дальность приема по сравнению с 14 dB, т.е. разница в 6 dB дает двойной выигрыш. Если к этому прибавить, что аппарат с чувствительностью -97 dB, позволяет получить выигрыш в 4 раза по сравнению с аппаратом, у которого чувствительность равна -76 dB, то общий выигрыш будет 8-ми кратным.
Заключение
Это основные характеристики, но существует еще масса различных тонкостей, специфических моментов и технических особенностей. Рассказать здесь обо всех нереально, поэтому выбор оборудования – совсем непростое дело, в котором не помешает консультация специалиста. Если вы, конечно, сами не являетесь таковым ![]()
Продолжение следует…
Ресурсы
- Сетевая аутентификация на практике http://www.citforum.ru/nets/articles/authentication
- Крупнейший и самый активный сайт рунета по Wi-Fi http://www.lan23.ru/index.html
- Антенны, много антен… хороших и разных http://radiowolna.narod.ru
Статья из пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Беспроводная сеть масштаба микрорайона. Часть 1
20th
Авг
Основы неврологии
В последнее время появилось много публикаций на тему нейронных сетей, однако большинство из них научного характера, предназначенные, как правило, для специалистов, пресыщены формулами и абстракциями, не дают четкого представления о предмете. В этой статье мы попытаемся понять основные принципы работы и устройство нейронной сети. Статья, дающая вводные представления о нейронных сетях.
ОСНОВЫ НЕВРОЛОГИИ
by Utkin www.programmersforum.ru
«Настоящий программист должен:
Пройти все уровни Тетриса, пользоваться только своим бубном и написать нейронную сеть»
/ Махабхарата, эпос народов Индии
Нейронные сети – это математические модели биологических нейронных сетей, выраженные как программным, так и аппаратным способами. Поэтому, сначала рассмотрим единицы, из которых состоит биологическая нейронная сеть – нейроны. Нейроны – это специальные биологические клетки, объединенные в нервную систему организма. Это нужно для осуществления нервной деятельности, а именно принятие информации об окружающем мире (и внутреннем состоянии организма), выработка решений и управление исполнительными органами. Нейроны бывают нескольких видов, но мы рассмотрим только один, который для простоты восприятия классифицируем как классический вид нейронов, т.е. тех, что в основном используются в компьютерных моделях. Итак, нейрон представляет собой клетку, имеющую несколько отростков, один из которых является выводом нейрона, а остальные являются его входами. Вывод нейрона называется аксоном, входы – дендритами, а точка соединения аксонов и дендритов называется синапс. Нейроны по своей сути схожи с микропроцессорами (или ядрами процессора) и фактически занимаются обработкой информации, поступающей на их дендриты и выдающие результат на аксон. Практически нейроны работают с электрическими импульсами (только на основе ионов – прямая передача электронов в жидких системах не очень удачная вещь, приводящая обычно к разрушению жидкости либо емкости, в которой данная жидкость находится). Ничего не напоминает? Иными словами, нервная система подавляющего большинства организмов – есть огромная электрическая схема. Один нейрон может соединяться с несколькими тысячами других, что дает высокий параллелизм (именно параллелизм, а не модную многопоточность). Некоторые принципы работы нейронов не установлены (потому что нейроны-то у всех есть, а вот электронный микроскоп не у каждого), однако известно, что существует класс нейронов, использующий две группы входов – возбуждающие и тормозящий. Сигналы на возбуждающих входах заставляют нейрон генерировать сигнал на аксоне, тормозящие соответственно подавляют выходной сигнал. Дендриты имеют порог срабатывания, то есть требуют, чтобы на их вход поступал сигнал определенного уровня, иначе он будет не засчитан, И который может изменяться под воздействием ряда факторов – например попадания определенных веществ, таких как гормоны. Время срабатывания нейронов относительно небольшое: 2-5 мс, Однако более 6 миллиардов нейронных сетей доказали, что с их помощью можно решать довольно-таки сложные задачи, такие как: разум, научно-технический прогресс и создание цивилизаций (наравне с такими задачами как разрушение природы и конкурентных видов, а также активная и очень эффективная внутривидовая борьба). Более того, миллионы лет эволюции убедительно доказывают, что такого быстродействия вполне достаточно для решения задач реального времени. Компьютерные же модели пока, что ушли не так далеко и используются в научных целях (в основном для того, чтобы понять каким же образом 6-ти миллиардам нейронных сетей вообще удалось выработать такую концепцию как нейронные сети).
Анамнез
Несмотря на громкие заявления, реальное использование нейронных сетей на практике ничтожно в сравнении с традиционными алгоритмами. Основная причина – неточное формулирование задач, результаты которых также не очевидны – такие как прогнозирование погоды, биржевые сводки, в общем, все, что сводится к гаданию на кофейной гуще и где нельзя однозначно поймать за руку. Наиболее серьезным является применение нейронных сетей для распознавания образов на базе персептронов (сети, где нейроны сгруппированы в слои), что не удивительно, теоретические предпосылки данных концепций (и персептронов и распознавания образов и распознавания образов на персептронах) были разработаны 60-70-х годах прошлого столетия, примерно в тоже время, когда был создан автомат для автоматического распознавания индексов на почтовых конвертах. В последнее время мощностей обычных компьютеров вполне достаточно для создания полноценных нейронных сетей (чем мы собственно и будем заниматься), что позволяет все чаще применять их на практике (например, интересной темой является использование нейронных сетей для сжатия информации). Следует сразу же предупредить: использование нейронных сетей в задачах, алгоритмы которых легко перенести на языки программирования, в подавляющем большинстве случаев не эффективно (обычно по быстродействию).
Настольная инструкция по приготовлению нейронных сетей
Прежде чем писать программу, имитирующую биологические нейроны, нужно выработать модель. Я предлагаю следующую модель нейрона…
Каждый нейрон имеет 32 входа, из них 16 положительных (считаю, использование термина возбуждающие выходы, здесь использовать не стоит) и 16 отрицательных. Выход соответственно один. Сразу договоримся о терминах – входы будем называть дендритами. Хотя в некоторых литературных источниках используется обозначение синапса, это на самом деле не совсем верно (почему написано выше). Выход также будем называть аксоном. Входы получают сигналы по принципу: есть сигнал / нет сигнала (0/1 или ложь/истина). Сам нейрон будет работать по принципу сумматора – он складывает все сигналы на каждой из групп входов. Соответственно, если число сигналов на положительных входах больше, чем на отрицательных, то нейрон устанавливает сигнал на выходе (аксоне). В обратном случае сигнал с выхода снимается (даже если сумма сигналов на положительных входах равна сумме сигналов на отрицательных).
Для данных нейронов порог срабатывания дендритов будет всегда и для всех одинаковым и равным уровню выходного сигнала. То есть наш нейрон будет работать с логическими величинами, и фактически будет являться предикатом (функцией возвращающей результат логического типа). Здесь по законам жанра научно-популярных статей следует погрузиться в обилие формул и не только математических. Но, как правило, для большинства читателей таких статей они абсолютно бесполезны, поэтому мы приводить их здесь не будем (кому интересно, найдет в прилагаемых источниках).
Почему 32 входа? Это компромисс между производительностью сети и быстродействием компьютера. Зависимость здесь следующая – чем больше выходов имеет нейроны, тем больше вычислительная мощность сети и тем больше вычислительных ресурсов требуется на реализацию.
Сам по себе нейрон устройство узкоспециализированное и его использование не в сети (даже если она и состоит из одного нейрона) является весьма проблематичным занятием, и поэтому далее мы рассмотрим модель нейронной сети.
Итак, помимо самих нейронов, сеть может содержать таблицу входных данных и таблицу выходных данных. Таблица входных данных характеризует информацию, поступающую в нейронную сеть – в биологии ее прототипом являются рецепторы. То есть датчики, с которых берется информация о задаче. Нейроны подключаются входами к таблице входных данных (заодно и к выходам нейронов) и формируют результаты, часть из которых помещаются в таблицу выходных данных. Данные, помещенные в таблицу выходных данных, символизируют решение поставленной задачи. Существует множество вариантов нейронной сети, но наиболее распространены персептроны – нейронные сети, где нейроны объединены в группы (слои). Обычно нейроны одного слоя могут соединяться с выходами нейронов другого, конкретного слоя, но бывают и исключения. В нашем варианте мы будем использовать хаотичное соединение нейронов (здесь имеется ввиду, что если порядок соединения нейронов и существует, то на данный момент он неизвестен), каждый нейрон имеет право быть соединенным с любым объектом нейронной сети, включая и таблицу входных данных, и таблицу выходных данных. Потому что это ближе к реальной биологической модели и строгих доказательств того, что нейроны объединены в группы или слои не обнаружено. Зато обнаружены нейроны – цель которых только передача импульса от входа к выходу, то есть это удлинители, которые соединяют между собой нейроны (те, что не могут быть соединены между собой напрямую ввиду их расположения).
Серьезным недостатком решения задач на нейронных сетях является отсутствие четких условий решения при постановке задачи перед нейронной сетью. Иными словами нельзя точно сказать, сколько нейронов требуется для решения данной задачи или достаточно ли данного числа нейронов для получения положительных результатов. Возможно, при определении конфигурации нейронной сети будет выбрано недостаточной число нейронов и решение задачи никогда не наступит. Существует ряд работ направленных на решение этой проблемы [1-5], однако до успешных результатов пока далеко (опять-таки, несмотря на заверения академиков и обилие формул). Сейчас выбор параметров в основном определяется на основании предыдущих опытов, либо экспериментальным путем. Я же выбрал хаотичную модель по двум причинам. Во-первых, персептроны не способны решать некоторые задачи независимо от числа нейронов в них (это было известно еще в Советском Союзе), а во-вторых, персептроны есть ограниченное подмножество моделей с хаотичным образованием нейронов и при изменении связей можно добиться получения персептрона практически любого типа. А возможность замыкания отдельных входов нейрона на его же выход или на константные сигналы позволяет имитировать дискретные уровни порога срабатывания.
Важной способностью нейронной сети – является возможность ее обучения за счет изменения порогов срабатывания и/или переключения связей между нейронами. Поскольку в нашем случае нейроны имеют одинаковые пороги срабатывания на всех входах и выходах, то обучение нашей модели будет происходить через изменение связей между нейронами. Кстати, на изменениях порога срабатывания есть алгоритмы автоматического обучения нейронных сетей, но опять же все это дело весьма и весьма условно. Потому что обучение возможно также только для некоторых видов задач и потому что такое обучение вырождается в генетический алгоритм, а это уже другая история, хоть и смежная (естественно исследователи не ищут легких путей). Обучение нейронных сетей такого типа производится случайным изменением связей между нейронами (как правило). Происходит это следующим образом. Пусть имеется некоторая задача, заключающаяся в решении некоторой функции f(x). То есть на каждое состояние таблицы входных данных должно быть только одно состояние таблицы выходных данных. Возьмем избитый пример – распознавание образов. Здесь на каждую картинку имеется соответствующая цепочка сигналов. Имеющейся сети дается тестовое задание – серия образов, затем сеть прореживается и получившаяся серия результатов сравнивается с эталонными данными. Если сеть отвечает требованиям задачи, то ее уже можно использовать (чего с первого раза на практике не бывает). Если же нет, то текущая конфигурация запоминается и на ее основе формируется новая сеть путем случайного изменения связи случайного дендрита случайного нейрона. Процесс распознавания повторяется. Теперь уже сравниваются оба результата тестирования: первоначальный и новый, полученный в результате мутации (здесь много биологических терминов). Например, сравнивать можно по проценту правильных результатов в серии распознавания образов. Теперь за основу берется та сеть, в которой процент совпадений больше и процесс повторяется до тех пор, пока результат тестирования не даст полного совпадения с эталоном. Или заранее определенное количество раз, иначе есть вероятность бесконечного процесса обучения. Здесь же нужно сразу определиться какой вариант сети лучше, в случае если оба варианта дают одинаковый процент узнаваний (новый вариант сети предпочтительней).
Подводные камни и течения
А что вообще может решать нейронная сеть? Теоретически даже может решить теорему Ферма. Для этого требуется не так уж много – нейронная сеть с числом нейронов примерно 1012 – 1015 степени, нейроны должны иметь возможность соединяться с несколькими тысячами других (порядка 20000). Если еще не понятно, то это мозг человека – лучшая иллюстрация работы нейронных сетей. На самом деле нейронов требуется еще меньше, потому что значительная их часть требуется на обслуживание и управление полуавтоматическими системами, таких как легкие, мышцы, желудок, саморегуляция и т.д. А также на передачу данных для других групп нейронов в те же самые органы. Плюс обработка огромного количества датчиков. Такую нейронную систему можно считать эталонной, но не идеальной. На ее обучение требуются годы.
На самом деле нейрон очень мощная логическая единица. С помощью нее можно эмулировать, например такие элементы как логическое «И», логическое «ИЛИ» и логическое «НЕ», то есть практически все современные логические операции легко могут быть выражены через нейронные сети. Одной из причин сложности конструирования эффективных сетей является тот факт, что логика на нейронах на порядок мощней обычной логики и всех ее смежных дисциплин, потому-то и выразить ее в рамках стандартной довольно-таки проблемно без привлечения интегралов и прочих трехэтажных формул (включая и логических). Далее с помощью нейронов можно эмулировать и работу сразу сложных блоков, таких как триггеры, счетчики, шифраторы, дешифраторы и т.д. И, наконец, нейронная сеть позволяет эмулировать аналоговые элементы (при наличии творческой жилки у программиста) и сложные схемы (на манер программ Qucs, Electronics Workbench, Microcap и т.д.).
Далее, нейронные сети способные решать задачи даже, если никогда до этого не сталкивались с такими условиями ранее, хаотичные соединения позволяют формировать различные как положительные, так и отрицательные обратные связи, что может порождать решения на грани интуиции. Однако в таких условиях возникает новая проблема – подобно человеку, нейросети способны ошибаться.
Еще одна частая ошибка (наблюдается даже в серьезных трудах) – это временные интервалы функционирования нейрона относительно других в нейронной сети. Представим работу какого-либо нейрона. Итак, он прочитал данные и сформировал новое состояние аксона. В результате какой-либо другой нейрон будет читать уже новое состояние аксона, и работа всей системы в целом будет нарушена (потому как нейрон может обратиться к любому другому нейрону и не факт, что тот уже поменял свое состояние на новое). Проблема усугубляется тем, что новое значение на первом нейроне не всегда влияет на состояние последующих, а только для некоторых дендритов или некоторых состояний системы. Далее существует вероятность, что данный нейрон также изменит свое состояние и т.д. Таким образом, результаты работы могут быть полностью искажены. Отчасти благодаря такой проблеме персептроны и получили такое распространение. В них слои, нейроны и их взаимосвязи организованы в иерархии таким образом, что все нейроны всегда получают новые сигналы, то есть сначала первый слой берет данные из рецепторов, второй слой берет данные из первого слоя и т.д. Но нас это ни как не останавливает, решение этой проблемы снижает быстродействие, но зато позволяет имитировать нейронные сети любой конфигурации. Смысл заключается в кэширование результатов работы нейрона. Иными словами нейрон изменяет (или не изменяет) состояние аксона не сразу, а только после того, как абсолютно все нейроны в сети выполнят свою работу. Только после этого происходит изменение состояния всех нейронов. Это гарантирует, что все нейроны получат достоверные сигналы, и, следовательно, выработают достоверные результаты.
Далее следует правильно трактовать результаты работы. Для простых задач, решение которых однозначно описывается f(x), то есть один параметр и только одно результирующее значение для каждого значения входящего параметра, это самое результирующее значение перестает играть особую роль. Всегда можно написать транслятор результатов, с использованием стандартных средств программирования, в случае если их число не велико. Объясню на примере все того же распознавания образов. Допустим, перед сетью стоит задача распознавания образов букв A, B и С. Результатом должно быть 2 бита (см. таблицу 1 и 2):
Таблица 1. Вариации распознавания
|
Входной образ |
Результат |
|
|
Буква А |
0 |
1 |
|
Буква В |
1 |
0 |
|
Буква С |
1 |
1 |
|
Любое другое изображение |
0 |
0 |
На самом деле это все равно что, вот такая таблица (см. таблицу 2):
Таблица 2. Вариации распознавания
|
Входной образ |
Результат |
|
|
Буква А |
0 |
1 |
|
Буква В |
1 |
1 |
|
Буква С |
1 |
0 |
|
Любое другое изображение |
0 |
0 |
И нет особого смысла мучить сеть мутациями (особенно если она состоит из тысяч нейронов), гораздо быстрей и проще написать транслятор, который брал бы данные из таблицы выходных значений и выдавал требуемый результат (см. рисунок):
|
Таблица входных данных (рецепторы)
|
|
|
|
|
|
Нейроны
|
|
|
|
|
|
Таблица выходных данных
|
|
|
|
|
|
Транслятор результатов
|
|
Рис.1. Алгоритм продвижения данных
Как уже было отмечено ранее, не стоит ожидать сразу ошеломляющей эффективности при использовании нейронных сетей, по разным причинам. Одна из них (необъективная) связана с восприятием самого человека. Как известно, приборы неизбежно вносят свои погрешности в результаты измерений, аналогично и человек при оценке работы нейросети, в большинстве случаев вносит в результаты свои погрешности.
Продолжим с тем-же распознаванием образов. Требуя от сетей четкого и однозначного определения результатов, очень часто человек сам не в состоянии адекватно оценить предлагаемое изображение по ряду причин (это связано не только со зрением). В тоже время человек способен распознать образ даже очень плохого качества, основываясь:
а) на предыдущем опыте – что, как правило, недоступно для нейронных сетей. Иными словами, человек не только обучен узнавать образ, но он может и просто помнить его, что значительно упрощает идентификацию объекта. Нейросетям для запоминания же требуется несколько большее количество нейронов, чем у них есть.
б) на информации, которая недоступна нейронным сетям по условиям задачи. Самый простой пример – это разбор рукописного текста. Чтобы понять все слова совершенно необязательно понимать все буквы – этот эффект давно известен и в частности им пользуются американцы в повседневной речи. Они проглатывают окончания (иногда середину) слов, просто не договаривая их. Также и человек, распознав большинство членов предложения, в состоянии восстановить слово исходя из контекста, а не за счет определения символов слова.
Теперь представим, что у нас уже имеется нейронная сеть (в смысле компьютерная модель). Она способна решать задачи и вроде все отлично, но настоящего исследователя такая позиция нисколько не устраивает – как это работает? Может для решения задачи требуется меньше нейронов? Что будет если отключить вон тот нейрончик? Ведь чем меньше в сети нейронов, тем меньше ресурсов требуется для ее выполнения, а скорость выполнения – один из серьезных недостатков, сдерживающий развитие науки о нейронных сетях.
Заблокировать нейрон можно, если его заставить читать информацию из самого себя (и только из самого себя). Тогда на его аксоне будет пожизненный нуль (напомню, что в хаотичной модели нейронной сети любой нейрон имеет право адресоваться к любому источнику сигнала, включая и самого себя).
Далее анализ, проведенный на базе имитации основных логических элементов, показывает, что нейронные сети более предрасположены к обучению, если помимо изменяемых данных они содержат в себе некоторые константные сигналы (в большинстве случаев достаточно постоянного 1 и постоянного 0). Получить их можно искусственно, например, жестко задать неизменяемое значение в таблице входных сигналов. Ну и нуль всегда можно получить, заблокировав нейрон.
Как это ни странно, но к нейронным сетям можно применять и некоторые стандартные средства отладки. Один из них – контрольные точки. Можно получать данные с одного нейрона и писать их в массив для дальнейшего анализа. Какого? Самый примитивный пример – если нейрон не меняет своего значения на протяжении всей работы нейросети, независимо от входящих параметров, то следует задуматься над этим фактом. Может проще все дендриты, которые подключены к нему, переключить на константные значения в таблице входных значений? Фактически такой нейрон выполняет транспортную функцию – он передает константу (или формирует ее) для тех нейронов, которые подключены к нему. Это актуально для биологических нейронов (не может нейрон из мозга напрямую подключиться к нейрону из копчика), но бессмысленно для нашей сети – каждый нейрон имеет возможность напрямую подключаться к источникам сигнала. Более сложный анализ предусматривает сбор информации и ее сравнение с группой нейронов. Цель – поиск дубликатов, то есть устранение все тех же нейронов, выполняющих транспортную функцию.
Можно также поискать нейроны, выполняющие бесполезную работу. Это нейроны, к которым никто не обращается, то есть ни другие нейроны, ни таблица выходных данных. Соответственно и результаты их работы не нужны. Аналогично можно поступить и со значениями из таблицы входных значений: если к данному элементу никто не обращается, то возможно данный элемент просто не нужен, либо сеть работает неправильно и требуется расширенное тестирование. Задача всех оптимизаций такова, чтобы получить нейронную сеть без элементов, работа которых не влияет на результат работы нейронной сети: кто не работает, тот не должен есть ресурсы компьютера.
Препараты
Здесь мы рассмотрим структуры данных, с помощью которых можно создать нейросеть. Запись будет производиться на языке Дельфи. Однако я постараюсь дать развернутое обоснование выбранных полей, так чтобы нейронную сеть легко можно было организовать и с помощью других языков программирования.
Прежде всего, нам нужна модель нейрона, который будет являться центральным элементом нейронной сети. Итак, предлагаю следующую модель:
type
TNeron = class (TObject)
protected
Akson: Boolean; // Выход нейрона
Akson2: Boolean; // Кэш нейрона
Dendrits: Array [0..31] of Integer; // Входы нейрона (как адрес другого нейрона)
private
public
// Подготовка к работе нейрона
constructor Create;
destructor Destroy; override;
procedure Init(); // Инициализация нейрона
// Организация доступа
procedure SetDendrit(Num, Value: Integer); // Установка связи дендрита
procedure Update(); // Запись данных из кэша
procedure SetAkson2(Value: Boolean); // Запись значения в кэш
function GetAkson(): Boolean; // Чтение аксона
function GetDendrit(Num: Integer): Integer; // Чтение значения дендрита (связи)
end;
Akson – значение логического типа, это выход, откуда будут читаться результаты работы нейрона.
Akson2 – это кэш аксона, предназначен для синхронизации работы нейронной сети.
Dendrites – это массив ссылок на аксоны и другие элементы нейронной сети. Всего их 32 и на данном этапе нет различий между положительными и отрицательными входами (это делается программно). Ссылка представляет собой идентификатор объекта, в качестве которого может выступать:
а) нейрон;
б) элемент таблицы входных данных;
в) элемент таблицы выходных данных.
* Комментарий автора
Обратите внимание, идентификатор является общим для всех элементов (в том смысле, что, используя данный идентификатор, дендрит, может обратиться к любому объекту, включая и свой собственный аксон).
Вообще-то, в нейронной сети каждый тип элементов организован в свои собственные динамические массивы и имеет свой собственный индекс для доступа. Общий же (или абсолютный) идентификатор вычисляется для удобства использования и адресации в тех методах нейронной сети, где это непосредственно требуется. Собственно ничего сложного нет – нейрон, по сути, хранилище данных, не реализована даже функция работы нейрона. Просто потому, что его работа без нейронной сети невозможна. Все методы направлены в основном на чтение/запись полей класса. Вообще реализацию можно было сделать и без класса (даже проще), но потом это отразиться на удобстве дальнейшей модификации нейронной сети. Теперь рассмотрим модель нейронной сети:
type
TNNet=class
protected
// Поля
Data: Array of TNeron; // Нейроны
Count: Integer; // Количество нейронов
TableIn: Array of Boolean; // Рецепторы
CountIn: Integer; // Количество рецпеторов
TableOut: Array of Boolean; // Таблица результатов
TableOut2: Array of Integer; // Ссылки на существующие нейроны, откуда читать сигналы
CountOut: Integer; // Число сигналов в таблице результатов
private
function RunNeron(Neron: Integer): Boolean; // Выполнение указанного нейрона
procedure Updating(); // Перенос сигналов из кэша нейронов на их выходы
Procedure OutPuting(); // Берем все значения для таблицы выходных данных
public
procedure InitNerons(); // Инициализация набора нейрона
procedure InitTablein(); // Инициализация рецепторов
procedure InitTableOut(); // Инициализация таблицы выходных сигналов
constructor Create; overload; // Конструктор нейросети
constructor Create(InTable, Nerons, OutTable: Integer); overload; // Конструктор нейросети
destructor Destroy; override; // Деструктор нейросети
// Работа с рецепторами
procedure SetCountIn(Value: Integer); // Устанавливаем число рецепторов
procedure ClearTableIn(); // Устанавливает все рецепторы в False (гасит сигналы)
function GetCountIn(): Integer; // Возвращает число рецепторов
procedure SetElemIn(Num: Integer; Value: Boolean); // Устанавливает сигнал для указанного рецептора
procedure SetTableIn(Value: Array of Boolean); // Запись сигналов сразу для всех рецепторов
// Работа с таблицей выходных данных
Procedure SetCountOut(Value: Integer); // Устанавливает число элементов таблицы выходных данных
Function GetCountOut(): Integer; // Возвращает число элементов таблицы выходных данных (сигналов)
Function GetValueOut(Num: Integer): Boolean; // Чтение выходного сигнала
Function GetLinkOut(Num: Integer): Integer; // Читаем линк для данной ячейки таблицы выходного сигнала
Procedure SetLinkOut(Num, Value: Integer); // Установка линка на нейрон
Procedure ClearOut(); // Очистка таблицы выходных сигналов (установка в False)
// Работа с нейронами
Procedure SetDendrit(Neron, Num, Value: Integer); // Установка линка
Procedure SetDendrit2(Neron, Num, Value: Integer); // Установка линка (абсолютная адресация в рамках нейросети)
function GetDendrit(Neron, Num: Integer): Integer; // Чтение линка
Procedure Run(); // Выполнение одного шага нейросети
Procedure Run2(Tik: Integer); // Выполним указанное число циклов нейросети
Procedure Run3(); // Минимальный запуск
Procedure SetNeronCount(Value: Integer); // Задаем количсетво нейронов
Procedure Mutation(); // Мутация нейросети (произвольного входа произвольного нейрона)
Procedure Generator(InTable, Nerons, OutTable: Integer); // Формирование сети с заданным количеством нейронов и данных в таблице
end;
Как уже было отмечено ранее, все типы элементов нейросети сгруппированы в рамках своего типа в динамические массивы. Здесь только следует обратить внимание на TableOut2 – эта структура относится к таблице выходных данных и представляет собой ссылки на нейроны, откуда следует читать информацию в элементы таблицы. Все Count’ы в данном случае являются счетчиками числа элементов в массиве. В принципе, число элементов динамического массива можно узнать и в Дельфи, не пользуясь дополнительной переменной. Но наш пример учебный и предназначен для понимания принципов работы нейронной сети. Оптимизацию можно проводить уже после ознакомления с данным примером.
Итак, из полей класса нейронной сети видно, что он также не представляет собой ничего сложного. Теперь немного уделим внимание методам, это поможет понять логику их работы. Сначала рассмотрим методы в секции Private. Это методы для внутреннего пользования, то есть, они поддерживают работу класса, и не должны вызываться извне – это может нарушить нормальную работу нейронной сети.
Сразу возникает вопрос – почему RunNeron есть функция? Она возвращает True (истина), если нейрон может выполнить свою работу (и тогда он ее выполнит). Сделано так специально с расчетом на будущую модификацию сети. Например, в данном классе не реализовано сохранение и чтение нейронной сети во внешний файл. Представьте себе ситуацию, что Вы загрузили поврежденный файл или же во время работы изменили нейронную сеть. Тогда возможно нарушение ее внутренней структуре, что может привести к тому, что дендрит будет ссылаться на нейрон (или на элемент одной из таблицы), которого не существует в данной нейронной сети.
Updating должен выполняться (и выполняется) сразу после выполнения всех нейронов в сети – это процесс обновления сигналов на выходах нейронов. Она переносит значение из Akson2 в Akson в каждом нейроне нейронной сети. Функция RunNeron помещает результат работы нейрона именно в Akson2, что дает возможность другим нейронам получать старые данные и сохраняет целостность и корректность модели.
OutPuting – отвечает за сбор информации в таблицу выходных значений. После обработки всех нейронов осуществляется обновление их выходов (посредством Updating). Затем OutPuting читает информацию из объекта нейронной сети, руководствуясь информацией из TableOut2, и переносит результат в соответствующий элемент таблицы выходных данных.
Большинство остальных методов класса ориентированы на получение данных об объектах нейронной сети, а также на внесение в нее изменений, в том числе и внесение информации о задаче (информация в таблице входных данных). Пожалуй, интерес представляет только Run – выполнение нейронной сети. На самом деле это группа операций. А именно – выполнение всех нейронов, обновление состояний выходов нейронов и получение результатов в таблицу выходных данных.
** Комментарий автора.
Напоследок – не совсем удачное название класса выбрано специально, чтобы избежать возможного конфликта имен. Дело в том, что существует ряд классов и компонентов, имеющих в названии Net. Да и самописные инструменты, связанные с работой через сеть (не нейронную) обычно называются аналогично, а длинное имя элементарно лень писать. Все остальные вопросы можно уточнить в проекте, в котором реализована данная модель нейронной сети.
Заключение
В данной статье описана простая модель нейронной сети, при доработке которой можно добиться весьма неплохих результатов. Здесь-бы хотелось отразить те моменты, с помощью которых данный пример можно развить до вполне конкурентоспособного и, возможно, даже коммерческого варианта:
1. Сохранение и чтение нейронной сети в файл. В случае если Вы только отрабатываете свои навыки, то это может быть простенький текстовый формат по типу CSV (где все поля в строке разделяются символами табуляции). Простота устройства сети позволяет легко реализовать процедуру сохранения информации с использованием буфера, например, через список строк (такой как TStringList). Процесс чтения, как правило, немного сложнее из-за необходимости контроля целостности внутренней структуры сети.
2. Введение отладочных механизмов. Несмотря на то, что речь о них в статье шла, в примере они не реализованы. Здесь необходимо уделить внимание оптимизации алгоритма по скорости. Сложности возникать не должно, что и зачем в статье описано. Главное помнить, что работа сети есть большое количество итеративных (циклических) процессов, а на это требуется время, что может потребовать принудительного выделения ресурсов, например, с помощью Application.ProccessMessagess, либо аналогичных средств.
3. Введение дополнительных удобств использования. В примере данные возвращаются побитно, но можно группировать информацию и возвращать массивы, либо упаковывать в байты и анализировать их далее.
4. Оформление проекта в качестве динамической библиотеки, что позволит подключать ее и для других языков программирования, и вообще будет способствовать распространению.
5. Написание дополнительных инструментов. В частности, можно написать генератор нейронных сетей, позволяющий создавать нейронные сети с некоторыми заданными характеристиками. Тогда проект может уже подгружать и работать с готовыми нейронными сетями.
6. Написать распределенную версию нейронной сети. Это позволит запускать ее на нескольких компьютерах и производить внутренний обмен посредством локальной и глобальной сети. Что в свою очередь дает решать более глобальные и ресурсоемкие задачи.
7. Оформление подробной документации. Один из важнейших вопросов, к которому большинство программистов, обычно относятся халатно.
Источники. Что почитать
. Раздел википедии http://ru.wikipedia.org/wiki/Нейросети
. Введение в искусственные нейронные сети http://www.osp.ru/os/1997/04/179189/
. Нейронные сети http://www.statsoft.ru/home/textbook/modules/stneunet.html
. Введение в теорию нейронных сетей http://www.orc.ru/~stasson/neurox.html
. Материал по нейронным сетям http://www.artkis.ru/neural_network.php
. Нейронные сети – математический аппарат http://www.basegroup.ru/library/analysis/neural/math/
. Лекции по теории и приложениям искусственных нейронных сетей
http://alife.narod.ru/lectures/neural/Neu_ch12.htm
. Основные понятия Нейронных Сетей http://oasis.peterlink.ru/~dap/nneng/nnlinks/
. Нейронные сети: прогнозирование как задача распознавания образов
http://www.masters.donntu.edu.ua/2003/fvti/paukov/library/neurow.h
Статья из пятого выпуска журнала ПРОграммист.
Скачать этот номер можно по ссылке.
20th
Маленькие помощники программиста
 Ежедневно мы сталкиваемся с рутинной работой, которая отнимает львиную долю нашего времени. В этой статье я попробую «приучить» читателя к созданию маленьких помощников, оптимизирующих работу или сокращающих время рутинных операций…
Ежедневно мы сталкиваемся с рутинной работой, которая отнимает львиную долю нашего времени. В этой статье я попробую «приучить» читателя к созданию маленьких помощников, оптимизирующих работу или сокращающих время рутинных операций…
Маленькие помощники программиста
Алексей Шишкин
by Alex Cones www.programmersforum.ru
http://www.programmersforum.ru/member.php?u=40711
В фантастических фильмах мы часто видим, что человека окружают маленькие роботы, которые помогают ему, выполняют его рутинную работу. Рыботы пылесосы убирают пыль и мусор, маленькие роботы кофеварки подадут Вам свежий кофе, а маленький робосекретарь напомнит Вам о важной встрече. В жизни все не так просто.
Но, не смотря на такую жестокую реальность, программисты главным образом живут в мире виртуальном. Поэтому ничто не мешает им улучшать свою жизнь, создавая «роботов»-помощников. «Но какие-же помощники могут быть у программиста?» – скажете Вы. Я постараюсь ответить на Ваш вопрос, опираясь на собственный опыт.
История появления…
Итак, первая вещь, которая была создана мной для облегчения собственной жизни – это «Заполнялкин» (см. рисунок 1):
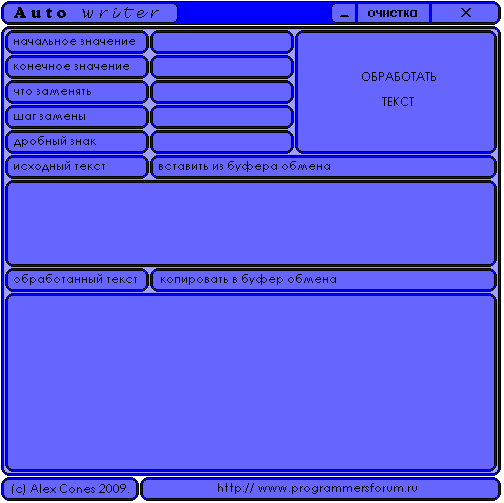
Рис. 1. Утилита «Заполнялкин»
Эта программа предназначалась для того, чтобы оптимизировать написание больших блоков кода, отличающихся только ссылками. Так, например, введя шаблон:
Label@@.Caption := IntToStr(@@);
Можно было получить практически неограниченное количество следующих строк:
Label1 := IntToStr(1);
Label2 := IntToStr(2);
Label3 := IntToStr(3);
Label4 := IntToStr(4);
Label5 := IntToStr(5);
Кстати говоря, данные строки были получены с помощью вышеописанной программы. Итак, вопрос создания многократной записи большого количества похожего кода уже не стоял, и я занялся другими проблемами.
Второй программой стал Resource Builder (см. рисунок 2):
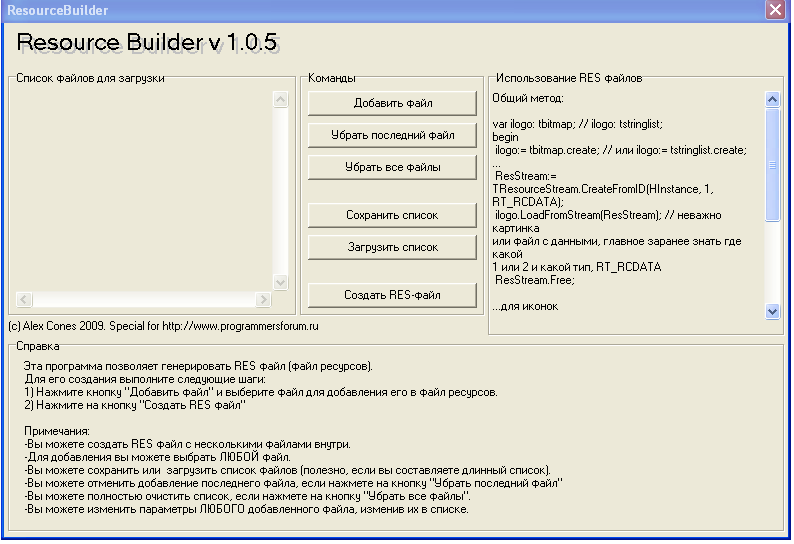
Рис. 2. Утилита Resource Builder
Да, возможно некоторые станут упрекать меня за то, что такое название уже существует, но я ведь не собираюсь продавать это творение, поэтому не обеспокоен нарушением авторских прав на название программы. Моя версия создателя ресурсов к программам отличалась тем, что в ней можно было добавить любой файл в ресурсы к программе.
Итак, вопрос удобства создания программ уже не стоял, я приступил к улучшению окружающей меня обстановки: я создал G.A.P. Создать эту программу меня вдохновили действия Educated Fool – он создал excel-ский макрос, который упаковывал проект в архив, создавал к нему превью и отправлял на FTP сервер. По аналогии моя программа делает снимок экрана (или части его ? по выбору пользователя), дает возможность создать превью к снимку, отметить на нем что-то и отправить на сервис хранения картинок, оставив ссылку на картинку в буфере обмена (см. рисунок 3):

Рис. 3. Утилита G.A.P
* Комментарий автора
На этом месте я хочу предупредить читателя о том, что данная статья задумывалась вовсе не как реклама этих программ, а как пособие начинающему «импруверу» (от англ. improve – улучшать). Не бойтесь экспериментировать, и запомните одну вещь – ЛЮБАЯ работа может быть оптимизирована. Даже если кажется, что это не так.
Однажды мне потребовалось залить на файлообменный сервис достаточно большой файл. С моей полу-диалапной скоростью эта задача имеет решение только посредством FTP доступа. К счастью сервис предоставляет такую услугу. Радости моей не было предела и на первую же ночь я поставил на загрузку злополучный файл. Проснувшись утром и просмотев логии, я ужаснулся – сервер отключает меня каждые 15 минут бездействия. Даже если в этот момент загружается файл. Выход был лишь один – отправлять команду просмотра каталогов каждые 10 минут (благо для этого была выделена отдельная кнопка). Но не кликать-же по ней каждые десять минут, пока файл не загрузится? Хотя-я… Собственно, почему нет? За 15 минут был создан Click Shot (программа, которая будет кликать за меня в нужную точку экрана через заданный промежуток времени)
Рис. 4. Утилита Click Shot
Думаю, лишним будет говорить то, что файл был успешно загружен.
Вчера один из моих товарищей вставил в мой ноутбук свою флешку. Несмотря на то, что на ней были только документы, Windows спросила разрешения запускать с неё программы. Снизойдя до отказа, я включил отображения скрытых и системных файлов и обнаружил autorun и exe-шник. Открыв авторан, я понял, почему антивирус продолжал молчать
[AutoRun
;lsbvrkskjvbliurbsv
;srvlbsrvksrjksr
open = klbhk.exe
;kjbsjvbkvksjvn
Одна закрывающаяся скобка… И план вторжения армий провалился… Но что-то я отвлекся. Удаление файлов прокатывать не захотело по причине аттрибута «системный» у обоих файлов. Форматировать флешку мне не позволили, и я накатал программу, изменяющую аттрибуты каталогов и файлов по выбору пользователя. Так появился на свет A.ch (см. рисунок 5):

Рис. 5. Утилита A.ch
Заключение
В завершение статьи хочу отметить, что каждая решенная проблема приносит удовольствие, но лично для меня большее удовольствие приносит решение проблемы. Дерзайте, и да прибудут с вами маленнькие помощники программиста!
Ссылки
. Заполнялкин. Версия 1.0 http://www.programmersforum.ru/showpost.php?p=367784&postcount=26
. Resource Builder http://www.programmersforum.ru/showthread.php?t=69505
. GAP http://www.programmersforum.ru/showthread.php?t=69505
. Click Shot http://www.programmersforum.ru/showthread.php?t=92768
. A.ch – Attribute Changer http://www.programmersforum.ru/showthread.php?t=104574
Статья из пятого выпуска журнала ПРОграммист.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
19th
Авг
Разработчики – интерфейс – пользователи
В статье написано то, что автор смог прочесть, понять и пересказать своими словами и немного того, до чего додумался сам; все то, что касается процесса взаимодействия двух человек – разработчика и пользователя. Кратко это выражается одним словом – интерфейс…
«Встречают по одежке, а провожают по уму»
Демьяненко Александр by Grenles http://www.programmersforum.ru/member.php?u=17572
Часть первая. Философия
Надо же! Почти вступление! Не скажу, что я большой профессионал, особенно по теме данной статьи, но и не скажу, что я совсем уж любитель. Я учусь писать, читать, видеть, думать, и снова начинаю этот процесс сначала*.
* Комментарий автора.
Кто-то сказал: «хочешь что-то понять, – объясни это что-то другому, – он может и не понять
сказанного тобою, но уж ты сам точно это поймешь».
Очень сложно учить чему-то профессионалов, особенно в той области, которую они знают лучше тебя, гораздо проще – стать их учеником. Однако, как ни странно, порой именно любители пишут книги для профессионалов и учат их ремеслу и только лишь потому, что не всегда профессионалы умеют выразить доходчиво свои знаний для других. Поэтому не все так плохо, но и не так просто, как кажется на первый взгляд. В мире всегда полно тех, кто задает вопрос: «А с чего мне лучше начать?». Мало того, есть еще такие профессионалы, которые проснувшись утром, понимают, что они ничего не знают из того, что должны знать. Именно поэтому каждый день они начинают с поиска и изучения новых горизонтов знания. Каждый раз, узнав больше, они понимают, что все равно ничего не знают и снова начинают бесконечный процесс приобретения знаний. Вот для этих людей и не только для них я и начал разговор на заданную тему.
Тема, которую хочу затронуть, выражается одним словом – интерфейс. Тема с одной стороны кажется простой и легкой, а с другой – это весьма сложная и обширная область знаний, которую трудно уместить в рамки одной статьи. Анализируя современный рынок программного обеспечения, множество интернет сайтов, различных печатно-книжных изделий я пришел к выводу, что знания о правилах создания интерфейса должны быть у всех, так или иначе связанных с созданием продуктов, предназначенных для пользователей, потребителей. На сегодняшний день эта область знания вполне достойна того, чтобы идти отдельным курсом в высших учебных заведениях.
От того, насколько удачно продуман и реализован интерфейс продукта, зависит 75% успеха разработчика и 100% эффективности использования потребителем конечного продукта. Случается, что и начинающие разработчики, и гранды компьютерной индустрии, как студенты на экзаменах, «засыпаются» на плохо сделанном интерфейсе для своих великих проектов. К сожалению, не всегда с первого раза удается найти удобный способ взаимодействия пользователя и продукта. То, что ясно разработчику, не всегда очевидно пользователю и наоборот. Почти как мужчина и женщина всегда говорят на разных языках, так разработчик и пользователь живут и мыслят на основе разных категорий.
Садясь за статью и желая раскрыть тему полнее и правильнее, я решил обратиться в Интернет, чтобы узнать: «А как на мой вопрос отвечали другие?». Не скажу, что эта фраза мне попалась первой, но зацепился я за нее сразу: «Для ReGet дизайн придумывала студия Артемия Лебедева. В результате пользоваться ReGet, в отличие от FlashGet очень удобно. Можете в этом сами убедиться» [1]. При этом, я не думаю, что функционально обе программы сильно разнятся, выполняемые ими задачи практически одни и те же, но разница в том, что одну программу мы используем, а другую просто имеем ввиду, зная что она есть.
Самый веский аргумент, окончательно подтолкнувший меня на создании серии статей по заданной теме, я нашел в источнике [1]: «в России слишком много программистов-самоучек, которые все этапы создания программы от идеи программы до ее реализации выполняют сами». К сожалению, не у всех есть возможность нанять профессиональных дизайнеров или найти специалиста в этой области, поэтому приходится «изобретать велосипед» самому.
Начнем. С чего? Элементарно! What song? Книги!
Я нашел очень много информации по теме и около нее: статьи, примеры, книги, журналы. Среди множества источников выделил три книги. Не буду утверждать, что они являют собой ту самую истину, которая незыблема и нет других источников информации, но прочесть бы их я посоветовал:
1. Стив Круг. Веб-дизайн или не заставляйте меня думать

ее стоит прочесть хотя бы для того, чтобы понять основные принципы «юзабилити» и того, как не стоит делать интерфейс. Кто-то скажет, – но она же только для тех, кто создает веб-сайты, Отвечу, – а кто сказал, что создание интерфейса программы сильно отличается от создания интерфейса веб-сайтов? Я бы сказал иначе, создание веб-сайтов выросло из принципов создания программ, именно поэтому внешний вид может быть разным, но подходы, принципы, правила одни и те же. Но, как ни странно, думать надо в любом случае и при создании сайта, и при создании программы. Хорошо думать, когда есть знания. Замечательно думать, когда знания перешли в умения. Надеюсь, уважаемый читатель, ты меня понял.
2. Джеф Раскин. Интерфейс: новые направления в проектировании компьютерных систем

считаю весьма полезными для разработчиков, желающих стать профессионалами. Я бы не сказал, что по году создания и издания книга нова. В найденной мною версии она датируется 1996 годом, но только что это меняет? В книге весьма интересно разложены по полочкам элементы интерфейса их плюсы и минусы, и порой высказывается совершенно иной взгляд на привычные, казалось бы, вещи: отказ от GUI, отказ от использования мыши, отказ от разбиения задач по приложениям. В определенном смысле программы интернет-браузеры реализуют эту идею, когда в одном окне выполняется все – звук, графика, редактирование, просмотр видео и прочие действия.
3. Иоханнес Иттен. Искусство цвета

книга тоже не новая, но привожу я ее из тех соображений, что дизайнеру, просто глупо ничего не знать о свете и цвете и не уметь применять эти знания на практике. Да и просто это повод открыть интернет и поискать любую литературу на тему рисования, цвета, способов изображать предметы. Скажу вам – очень интересная тема. Исследуйте на досуге, а я как-нибудь позднее чего-нибудь вам об этом расскажу. Искусство художника оказывается полезным для дизайнера – это основа его творчества.
4. В.В. Головач. Дизайн пользовательского интерфейса

Скажу сразу, она попалась мне на глаза гораздо позже других книг и понравилась намного больше тем, что в ней нет строгой теории, а сразу идет разбор конкретных ситуаций – ошибок и решений. Как ни странно, на фоне прочтения первых трех книг, эта – четвертая книга как будто подвела итоги решений, описанных теоретически в «умных» книгах.
Мало того, изложение материала таково, что я бросил чтение других книг и продолжил чтение только этой книги. При этом, на основании изложенных примеров, я реализовал несколько удобных «фишек» для своих программ на будущее, и они мне понравились. Советую прочесть эту книгу, просто потому, что это полезно и интересно.
Есть более новая версия этой книги – «Дизайн пользовательского интерфейса 2. Искусство мыть слона».
Начав читать, и, почти дочитав эти книги, я понял, что дизайн это бесконечный процесс слияния знаний, фантазии и ресурсов, которыми обладает дизайнер, в котором многое зависит от личности и ее таланта. Задумавшись, решил, что точнее назвать этого человека дизайнера – создатель: во-первых – это по-русски, а во-вторых – более отражает процесс дизайна (создавать нечто удобное, новое и оригинальное).
Что наша жизнь? И…
Классический ответ на заданный вопрос – «игра». В каком-то смысле, если задуматься, так и есть – вся наша жизнь есть одна сплошная игра. И в любой игре есть маски, костюмы, актеры, зрители. Я нашел этой игре новое обличие:
. зрители – это пользователи, потребители созданного вами продукта – программы, фильма, музыки, книги и тому подобного
. маски и костюмы – это тот самый интерфейс, в который мы облекаем наш продукт и то, что видит в первую очередь зритель. Это только потом он начинает разбираться в сюжете (логике), в таланте актера (профессионализме разработчика), имя которого завтра будет трудно вспомнить, если он оказался плох и т.д.
. актеры – это разработчики, по сути – мы с вами, те, кто хоть однажды пытался что-то проектировать, создавать, строить и прочее. От того, насколько мы талантливые актеры будет зависеть успех всего спектакля, аншлаг, признание публики, слава, деньги и прочее.
Разрабатывая программу, мы играем роль самого Создателя. Может быть, именно поэтому большинству так нравится играть, многим – нравится программировать, а некоторым из числа избранных – создавать и творить. Все это теоретически хорошо, но возникает вопрос, а какой ты создатель? И для кого ты создаешь? Мучаешься, не спишь ночами, читаешь гору разной литературы, бьешься над парой строк кода и все ради чего? Чтобы однажды узнать – твой труд никому не нужен, потому что ты не смог найти удачный способ взаимодействия пользователя с твоим творением. Не смог донести до него свою мысль и идею – ответ на главный вопрос: «…зачем ему нужно то, что ты создал?». Тебе-бы встретиться с ним, поговорить по душам за рюмкой чаю, но уже поздно – время упущено и пользователь ушел к другому, так и не поняв, что же ты хотел для него сделать. К сожалению, в жизни часто так бывает, что разработчик и пользователь встречаются друг с другом тет-а-тет весьма и весьма не часто. Особенно последняя фраза касается начинающих разработчиков – опытные-то знают, что пользователя надо завлечь пряничком, блестящей оберткой, усадить на мягкий стульчик, подать вкусный чай… Часто начинающие разработчики не то чтобы забывают о пользователе, они порой плохо представляют, а кто это вообще такой.
Пройдемся по науке
Собственно, что я хотел сказать? Для начала надо немного определиться и ответить на вопрос главный вопрос статьи: «Что такое интерфейс***?»
** Интерфейс (от англ. interface — поверхность раздела, перегородка) — совокупность средств
и методов взаимодействия между элементами системы [4].
Ответ обобщенный, подходит для разных сторон и сфер человеческой деятельности, но в своей сути он отражает смысл этого явления. Далее, подумав немного, решил, что мир придуман не вчера и все процессы должны быть так или иначе давно регламентированы и описаны. Я начал искать стандарты, правила, ГОСТ-ы. Приводить здесь подробное описание этих документов абсолютно бессмысленно. Каждый сам может найти их в сети Интернет. Будет гораздо лучше, если выскажу свои соображения, которые сделал, переработав найденную информацию…
Большинство ГОСТ-ов, найденных мною, направлены на разработку технической документации, связанной с процессом разработки программного обеспечения. Создается впечатление, что изначально в 70-х начале 80-х годов прошлого столетия упор делался на техническую сторону этого вопроса – разработку и детализацию алгоритмов, средств сопряжения, подбор технической базы, создание различных инструкций по эксплуатации и прочее. Старый ГОСТ именно это и регламентировал. Впрочем, если подумать, так оно и должно было быть, так как программирование по сути родилось из математики и на первом месте было решение задач, а не внешнее оформление. Лишь в ГОСТ, относящимся к недавним советским временам, а именно, ГОСТ 19.201-78 и ГОСТ 24.207-80 можно неявно увидеть фразы, частично указывающие на средства взаимодействия с пользователем: «требования к программе или программному изделию», «требования к маркировке и упаковке». Правда, прочтя эти фразы, явно и не скажешь, что тут имеется ввиду «интерфейс». Тем не менее, в источнике [2] нашел следующее: «Техническое задание, как правило, разрабатывается на основе ГОСТа 19.201-78 «ЕСПД.
Техническое задание. Требования к содержанию и оформлению». Таким образом, получается, что разработчик должен сам знать и подразумевать, что в задание должны закладываться вопросы, связанные с интерфейсом. Явно это в ГОСТ не звучит. Но это было «тогда». По ГОСТ советских времен подразумевалось, что интерфейс у нас возникает сам собой, – это следует из текстов документов. Получалось, как в известной фразе: «В СССР секса нет, а дети есть». Всем известна фраза о том, что в мире все подвержено изменениям. Тоже самое можно утверждать и про ГОСТ-ы. Не прошло и 20-ти лет, изменились требования времени, реалии, изменилось само время. Согласно документам, датируемым 2000-м годом и выше, разработчики ГОСТ уже узнали про интерфейс и даже явно написали об этом в «Пример шаблона технического задания (ТЗ) на сайт» [3], где есть два раздела: «Требования к графическому дизайну сайта», и «Требования к дизайну сайта». Это уже радует. Конечно же, кажется совершенно очевидным, что сайт без дизайна не сайт. Однако, судя по всему, на осознание этого факта разработчикам ГОСТ потребовалось время. Думаю, что оно им еще будет нужно, чтобы создать отдельный ГОСТ, касающийся только дизайна, как такового.
В итоге, проглядев различные ГОСТ, документы, шаблоны и примеры, сделал основной вывод. Сейчас, как и раньше, основной упор идет на правильное, точное, детальное оформление документации по всем этапам разработки продукта – замысел, поиск информации для начала разработки, процесс разработки, тестирование, внедрение, эксплуатация. С одной стороны – это правильно, сложные продукты делает много людей и для удобства их работы и взаимодействия нужны документы, описывающие детально и правильно различные этапы процесса создания конечного продукта. А с другой стороны – это жуткая бюрократическая формальность, требующая от каждого участника процесса описывать каждое свое действие и решение. Именно поэтому создание документации так не любят разработчики. Порой время, требуемое на ее создание соизмеримо со временем создания самого программного продукта. Но, опять же, мы вернулись к тому, от чего пришли – в настоящее время по ГОСТ дизайн и интерфейс упирается в «бумагу».
Если внимательно подумать, то это правильно, заказчику «нечто» не покажешь, а нарисованное и написанное на бумаге вполне возможно. Поэтому, насколько мне представляется, знание ГОСТ и этапов от создания технического задания до сопровождения готового продукта необходимо не только крупным фирмам, но и одиночным разработчикам, так как это позволяет делать все правильно и приучает к определенному порядку. Конечно же, для написания программы, из разряда «калькулятор» вряд-ли нужно техническое задание, но знание этого необходимо. Прошлись по науке? Хотя ГОСТ и прочие нормативные документы необходимо знать, но, по сути, это скучно, сухо и сложно. Пожалуй, хватит – идем дальше.
Что вы делаете после того, как решили написать собственную программу?
Предполагаю, что 95% респондентов ответят – обдумываю идею программы, способы реализации, типы данных, выбор среды программирования и прочие детали и … будут почти правы. А почему – почти? А потому «почти», что мало-кто сразу из большинства разработчиков начинает думать над тем: а как будет выглядеть ваше будущее творение перед лицом пользователя. Удобно—ли пользователю будет работать с программой***. Согласен, что на первом этапе весьма сложно представить цельный интерфейс программы, так как и программы, собственно говоря, еще и нет, но задуматься над этим стоит уже с самого начала.
*** Комментарий автора.
Скажу, что два года назад, когда я стал активно заниматься программированием, а не просто сопровождением программ и написанием мелких макросов, я больше корпел над алгоритмами и достижением результата, – программа должна делать то, что хочет от нее пользователь. Интерфейс возникал или по ходу написания, или так, как было удобно мне, а не пользователю. После запуска продукта в эксплуатацию как минимум неделя была посвящена только тому, что я отвечал на вопросы что, где, почему и зачем. Теперь же я стараюсь думать не только над «внутренностями», но и над «внешним видом».
А как вы пишете программу?
Думаю, что большинство ответят примерно так: «Сажусь за компьютер, открываю среду программирования и начинаю писать код». Если это визуальная среда программирования, то обычно 100% действий начинается с того, что на пустую форму перетаскивается мышкой какой-либо элемент из палитры компонентов и… вот тут начинается самое интересное, вы ступаете на дорогу «войны». Я не ошибся, именно дорогу войны, даже точнее будет сказать – тропу. Почему? Все очень просто – весь процесс разработки есть борьба с самим собой, с кодом, ошибками и прочими неприятностями. В любой программе во время ее написания никогда с первого раза не бывает правильно размещенного элемента в нужном месте формы, соседние элементы иногда начинают мешать друг другу или просто не помещаются на форме так, как этого хочется. В итоге вы все время воюете – с алгоритмом, со средой разработки с внешним видом. Причем чаще всего страдает от всей этой «битвы» интерфейс. Да и кто серьезно задумывается**** над тем, насколько удобно пользователю будет работать с программой, когда на первое место выходят задачи логики функционирования программного продукта?
**** Комментарий автора.
Пример из моей практики. В связи с производственной необходимостью потребовалось решить проблему автоматизации учета. Проблема была в том, что «низы» уже не могли вести расчеты «вручную» в связи с их сложностью, объемом и цикличностью, а «верхи» не знали быстрого решения проблемы, то есть подходящего программного решения по цене и решаемым задачам не было. В итоге, по стечению различных обстоятельств, наш системный администратор взялся за разработку программы «с нуля». То, что для него это было тяжело, это мягко сказано, это было очень тяжело. Ему приходилось решать проблемы абсолютно разного рода – выполнять свою непосредственную работу, параллельно изучать новые методы и технологии программирования, изучать предметную область задачи, решать дела домашние, между этим делать еще что-то. Мало того, периодически он «воевал» с непосредственным начальством по поводу совмещения прямых рабочих обязанностей и работы по написанию программы (программу он писал добровольно и, в том числе, на своем рабочем месте, а какому начальству понравится такое?). Смысл всей этой предыстории таков, что ему было не до интерфейса и дизайна программы. Для него было важным решить технические проблемы стоявшей перед ним задачи. В итоге задачу он решил для своего уровня и того времени достойно. Однако, в процессе эксплуатации выяснилось, что где-то он не додумал логику, где-то проиграл в удобстве интерфейса. При этом каждый день он решал какие-либо проблемы, связанные с внедренной программой – дописывал, исправлял, модернизировал, консультировал пользователей, писал документацию. Добавление новых решений и отчетов в программу, привело к тому, что с каждым днем она становилась все функциональнее и сложнее. В итоге, несмотря на то, что он видел и знал огрехи интерфейса, переделать или исправить что-то было уже практически невозможно, так как это означало переписывание программного кода практически сначала.
Вывод, напрашивающийся из всей этой ситуации таков – в условиях нехватки времени (а в обычных «рабочих» условиях так и есть) одному человеку практически невозможно создать удобную во всех отношениях программу. Все усилия в этом случае направлены на то, чтобы найти и реализовать логическое решение, внедрить и запустить в работу программу. Понимание того, как все должно быть, как удобнее работать, приходит уже после того, когда программа запущена в работу и эксплуатируется. И, часто получается так, что реализация «удобства интерфейса» уходит на второй план, так как возникают более важные задачи, – исправление допущенных ошибок в логике, модернизация и прочее. Именно поэтому большинство серьезных фирм очень много времени тратят на подготовку процесса, создание «стартовой базы», и лишь потом начинают программировать. В экстремальных условиях интерфейс страдает всегда.
Когда вы задумываетесь о том, кто и как будет работать с вашей программой и какие ситуации могут при этом возникнуть?
А вот на эти вопросы я не могу дать однозначного для всех ответа. У каждого найдется свой ответ, но, в конечном итоге, правильный ответ на эти вопросы всегда звучат из уст пользователя. Почему из уст пользователя? Отвечу цитатой рецензента этой статьи, литературного редактора этого журнала, Utkin: «…даже в идеальной программе пользователи найдут что покритиковать. Просто потому что пользователи всегда придирчивы. Одним подавай одно, другим требуется прямо противоположное». Поспорить с этим сложно. Еще классик И.А. Крылов написал басню про Слона, который рисовал картину в угоду всем и в итоге никому его шедевр не понравился. В данном случае – тот же самый процесс.
Мало того, этот самый «пользователь» всегда найдет ту самую ошибку, которую никто из разработчиков даже в страшном сне не мог увидеть. При этом, сложно сказать, какая ошибка хуже – алгоритмическая или визуальная, обе одинаково неприятны. Разница лишь в том, что логическую ошибку среднестатистический пользователь не всегда можно найти, особенно, если плохо знает логику функционирования программы, – такую ошибку не всегда видно. С точки зрения пользователя, логические ошибки могут быть вообще никогда не обнаружены. По известной статистике большинство пользователей используют лишь 5-10% возможностей программы, про остальные 90-95% возможностей, где и может оказаться логическая ошибка, они могут не знать. Визуальная ошибка всегда хуже – она просто заметнее. Классический пример из недавнего прошлого – это ошибка вывода изображения видеокартой. Чаще всего такие ошибки выявлялись в играх, как более требовательным к ресурсам компьютера, а не «офисных» приложениях, которым хватало «гарантированного минимума». Они проявлялись в том, что могли «ломаться» контуры изображаемых предметов, возникали непредвиденные визуальные эффекты, искажения картинки в целом, в худшем варианте или просто ничего не было видно, или компьютер шел на перезагрузку. При этом, источник ошибки мог быть с любом месте – как в сбое видеокарты, так в используемом программном обеспечении (драйверах видеокарты, драйверах DirectX или OpenGL, несовместимости с операционной системой и прочее).
Для крупных корпораций уровня Microsoft или Adobe, когда есть рынок, бренд, сформированный круг пользователей, которые все равно не уйдут, такие ошибки менее ощутимы. Да, они неприятны, никто не говорит, что ошибки – это хорошо, но все-таки, менее ощутимы. Для таких корпораций они всего-лишь повод создания обновлений и выпуска новых версий программ. При этом, вовсе на факт, что старые версии работали хуже или не удовлетворяли потребностям пользователя. На мой взгляд, рассматривая, как пример, программу Adobe Photoshop, для большинства пользователей (не дизайнеров) вообще достаточно ее варианта в версии 9.0. Новые возможности программы, выпуск линейки продуктов от Adobe в виде нескольких DVD дисков, еще раз повторю, обычным пользователям, вообще не понятны и не нужны, – они просто не пользуются ими в полной мере. Хотя, как бренд и признак «статуса», большинство просто устанавливают эти продукты на свой компьютер, не зная и 5% всех возможностей. Грубо говоря, они микроскопом забивают гвозди, изменяя размеры фотографий или сохраняя их в другой формат.
Возвращаясь к теме разговора, еще раз скажу, что ошибки для крупных корпораций менее болезненны, чем для разработчиков-одиночек. И вот почему. Образно говоря, обслуживание ошибок у них поставлено на конвейер – службы поддержки, бесплатная горячая телефонная линия, консультации он-лайн и через различные сервисы в сети. В данном случае под «ошибками» я подразумеваю не только непосредственно ошибки в программе, найденные пользователями, но и «ошибки в мозгах пользователей», связанные с обычной человеческой ленью и нежеланием разобраться и думать. С одной стороны – такая ситуация везде и всюду и считается обычной, а с другой – это повод, способ, средство знать еще сильнее «привязывать» пользователей к себе. Если бы большинство из нас внимательно читали бы документацию и перед тем, как задать вопрос, подумали над его решением, то половина вопросов исчезла, а службам поддержки нечего было бы делать.
Если вы «один из подающих надежды», тот самый герой, призванный удивить мир, то у вас просто нет права на ошибку. Вы должны выстелить точно в цель, чтобы громко и красиво заявить о себе. В противном случае велика вероятность того, что пользователи вас не поймут и забудут навсегда ваш адрес и ваш продукт и, развернувшись, уйдут к другим. Исключение в этой ситуации, составляет всеми горячо любимый Билл Гейтс, который, несмотря на то, что первые версии его операционный системы Windows содержали много ошибок и пользователями по всему миру изначально вообще не воспринимались, смог продать свою систему этому миру. Возможно, одна из причин его успеха в том, что первыми пользователями его системы были студенты, ставившие над ней эксперименты. А так как чаще всего то, что изучается в университете, дальше используется в повседневной работе, то Windows и получила такое распространение. Впрочем, умалять заслуг Билл Гейтса, как удачного менеджера и торговца не стоит. Думаю что, еще одна хитрость, принесшая успех Windows состоит в том, что долгое время вообще никто даже и не знал, что надо покупать лицензии на эту систему. Она эксплуатировалась везде и всюду просто так, благодаря умным ребятам, называющих себя хакерами. В свое время ходила шутка о том, что самая лицензионная часть операционной системы – драйвер от мыши.
Другая исключительная ситуация, может быть только одна – ваша программа настолько уникальна и нужна пользователю, что он вынужден терпеть и ждать, и прощать вам ваши ошибки. Правда, такие исключения бывают редко и чаще всего встречаются в сфере специфических видов деятельности человека. Например, программа расчета поведения группы микроорганизмов под влиянием факторов внешней среды, или программа учета параметров работы газотурбинного двигателя. Рядовому пользователю такие программы просто не нужны, подозреваю, что он даже не догадывается о существовании таких программ.
Если кратко подводить итог***** всему сказанному в этих абзацах, что я бы сказал так. Если вы, как разработчик задумались над удобством использования вашего продукта не на стадии разработки, а гораздо позднее, то можно с уверенностью утверждать, что чем дальше вы от точки старта, тем больше затрат и усилий придется приложить, чтобы внести одно «элементарное» исправление. Это касается как общей логики функционирования, так и интерфейса в целом. Копеечная ошибка на старте всегда выливается миллионные затраты на ее исправление на финише.
***** Комментарий автора.
Часто в процессе создания возникает иллюзия «понятности», – это состояние, в котором разработчик настолько проникается идеей продукта и его тонкостями, что ему начинает казаться, что и другим также все очевидно и понятно в функционале создаваемого продукта, как и ему самому. На деле же все выходит наоборот, – даже знающего и опытного пользователя всегда требуется обучать и отвечать на такие вопросы, которые с точки зрения разработчика находятся в ряду «элементарных».
Необходимо как можно раньше начинать глядеть на ваше творение со стороны пользователя и делать это чаще и не просто глядеть (любоваться), а пытаться использовать все то, что вы создали, именно как пользователь. Забыть все, что известно о «внутреннем содержимом» продукта и стать неопытным пользователем, задающим извечные детские вопросы: «Как?» и «Почему?». Поверьте мне, это правило очень и очень часто помогает увидеть такие интересные вещи.
Элементы и проблемы… все мы родом из детства
Насколько я помню, начиная со школьных уроков информатики и продолжая на специализированных курсах университета, везде учат практически одинаково. Ученику рассказывают про алгоритмы, основы написания программ, грамматике языков программирования. Задавая типовые задачи, пытаются выработать логическое мышление, умение применять операторы и структуры изученного языка. Это все полезно и нужно, так как на самом деле заставляет думать и приводит к приобретению навыков логического мышления.
Я могу ошибаться, утверждая следующее, но на мой взгляд, практически нигде нет ни слова о том, как сделать так, чтобы с программой, в общем смысле – продуктом, было удобно работать. Учат только языку, логике и умению применить знания на практике. А о том, чтобы умения, воплощенные в продукте, было еще и удобно использовать на практике, если и говорится, то уж очень мало, настолько мало, что об этом не остается даже воспоминания.
Говорить, что нас ничему не учили, тоже нельзя. Если чуть-чуть подумать, то можно немного провести аналогии, хотя это будет слишком размыто и не очень конкретно. Уроки рисования в школе, когда каждый как умел, так и рисовал, теоретически можно взять в качестве элементарной базы графического дизайна. Тоже можно сказать о черчении и геометрии, из них можно почерпнуть понятия о проекциях, симметрии, способах изображения объектов, пропорциях. Можно еще упомянуть историю, касаемо истории искусств, обычаев, культуры – оттуда можно взять некоторые элементы для декора, дизайна, оформления. Но, мне кажется, это все-таки сложно и «притянуто за уши». Мало того, требует определенных усилий и особого мышления, чтобы все это собрать воедино. Пожалуй, из школьной программы – это и все, что можно взять в багаж, если не учитывать книги и специальные курсы, где непосредственно учат дизайну и оформительскому искусству, я их не рассматриваю, так как они идут факультативно и не входят в основную программу обучения, то есть массово не изучаются.
Если идти обучаться далее в университет (не могу со стопроцентной вероятностью утверждать, что в настоящее время ситуация не изменилась), то до недавнего времени в большинстве высших технических учебных заведений не было специально выделенной дисциплины, так или иначе связанной с интерфейсом. Студентам преподавались эргономика, трехмерная графика, черчение, инженерное моделирование, но увязать их с интерфейсом, опять же, можно лишь косвенно. Выделенной специализированной дисциплины, технических ВУЗах до недавнего времени не было. Я не беру во внимание обучение специальности дизайнер, так как считаю, что её изучает отдельно взятая группа людей и, распространяемые знания, не идут в широкие массы в отличие, например, от математики, физики, химии, изучаемых всеми в обязательном порядке на первых курсах университета.
Таким образом, молодой инженер, выпускник высшего учебного заведения с техническим уклоном, может оказаться хорошим специалистом, весьма подкованным логически и технически, но имеющим слабые знания в части дизайна, интерфейса и способов взаимодействия с пользователями. В результате, придя на рабочее место, молодому специалисту приходится восполнять этот пробел в знаниях самому и, порой, «изобретать велосипед» там, где он давно уже придуман. Иначе говоря, технические ВУЗы выпускают хороших специалистов, обладающих знаниями по своей специальности, но в разной степени хорошо умеющих эти знания красиво и удобно представить в конечном продукте. Именно по этой причине, как одной из основных, имеют такую популярность различные дизайнерские фирмы. Конечно же тому есть и другие причины – не все умеют созидающе мыслить, красиво рисовать, придумывать, но научить делать это можно всех. С одной стороны удобно поручить создание интерфейса и дизайна знающим людям, а с другой стороны подобное происходит потому, что большинство просто не знает и не умеет это делать правильно. Итак, завершаю философствовать и перехожу к описанию отдельных элементов касающихся интерфейса и не только его.
Продолжение следует…
Ресурсы
. Размышления об интерфейсе http://tclstudy.narod.ru/articles/mytk.html
. Культура разработки программного обеспечения http://www.orientir-yug.ru/kult_po.htm
. Техническое задание на разработку интернет-сайта http://www.rugost.com/index.php?option=com_content&task=view&id=182&Itemid=85
. Википедия. Интерфейс http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81
. Джеф Раскин. Интерфейс: новые направления в проектировании компьютерных систем
http://www.kodges.ru/9701-interfejjs-novye-napravlenija-v-proektirovanii.html
. С.Круг. Не заставляйте меня думать http://www.bookshunt.ru/b10909_veb_dizajn_kniga_stiva_kruga_ili_quotne_zastavlyajte_menya_dumatquot/download
. Об оформлении программной документации http://www.raai.org/about/persons/karpov/pages/ofdoc/ofdoc.html
. ГОСТ 19.102-77.Стадии разработки http://www.nist.ru/hr/doc/gost/19102-77.htm
. Студия Артемия Лебедева. Создание интерфейса навигатора «Штурман» http://www.artlebedev.ru/everything/shturmann/process
. Этот мерзкий, неудобный, противоестественный оконный интерфейс
http://epikoiros.narod.ru/public/antiwind.htm
. Обзор эргономических проблем и недостатков пользовательского интерфейса ПО бухгалтерского учёта на примере 1С:Предприятие 7.5 http://www.usability.ru/Articles/1.htm
. Ссылка на отдельное сообщение форума http://forums.drom.ru/1067823597-post12.html
Статья из пятого выпуска журнала ПРОграммист.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Обсудить на форуме — Разработчики – интерфейс – пользователи
19th
Введение в Scheme. Часть 2.
Здравствуйте, дорогие читатели. Как и обещал, сегодня мы продолжим рассмотрение наиболее распространенных команд языка Scheme и механизмов, облегчающих управление процессом выполнения, а также познакомимся ближе со средой разработки PLT Scheme.
Продолжение. Начало цикла смотрите в четвертом выпуске журнала…
Введение в Sсheme. Часть 2
Utkin www.programmersforum.ru
Нужно помнить, что данные предикаты нежелательно использовать на неточных числах – ошибки округления могут приводить к обратным результатам. Кстати, определить является ли число точным или не точным можно определить с помощью предикатов:
(exact? z) Тест на точность
(inexact? z) Тест на неточность
Для одного и того же числа один из этих предикатов всегда результат #t, тогда как второй #f. Для сравнения чисел можно использовать следующие предикаты, думаю назначение их понятно и так:
(= х1 х2 х3 …)
(< x1 x2 x3 …)
(> x1 x2 x3 …)
(<= x1 x2 x3 …)
(>= x1 x2 x3 …)
(= 1 1 1) #t
(= 1 2 1) #f
Аналогично, предикатам типов числа, не стоит применять сравнения на неточных числах, поскольку ошибки округления могут дать противоположный результат для почти равных чисел.
Еще предикаты для работы с числами:
(zero? z) Проверка на нуль
(positive? x) Проверка является ли число положительным
(negative? x) Проверка является ли число отрицательным
(odd? n) Проверка является ли число не четным
(even? n) Проверка является ли число четным
Поиск минимального и максимального чисел:
(max x1 x2 …)
(min x1 x2 …)
Примеры:
(max 3 4) Результат 4
(max 3.9 4 9 48 99 5) Результат 99.0 При этом число будет преобразовано в неточное.
(min 54 565 9L0) Результат 9.0
(min 4 4) Результат 4
Нужно соблюдать осторожность при сравнении почти равных неточных чисел, поскольку правильный результат работы данных предикатов не гарантирован. Теперь напомним стандартные арифметические операции:
(+ z1 …) Сложение
(* z1 …) Умножение
(- z1 z2) Вычитание
(- z) Унарный минус
(- z1 z2 …) Вычитание (с произвольным числом аргументов)
(/ z1 z2) Деление (деление на нуль не допускается)
(/ z) Деление 1 / z, при этом образуется дробь
(/ z1 z2 …) Деление z1 на произвольное число аргументов
Теперь примеры (поскольку некоторые результаты не очевидны):
(+ 3 4) Результат 7
(+ 3) Результат 3
(+) Результат 0
(* 4) Результат 4
(*) Результат 1
(- 3 4) Результат -1
(- 3 4 5) Результат -6
(- 3) Результат -3
(/ 3 4 5) Результат 3/20 (3 разделить на 4*5)
(/ 3) Результат 1/3
Кстати, дроби являются точными числами, поэтому их удобно использовать в предикатах для работы с числами (гарантируются однозначные результаты сравнений, отношений и т.д.). Дополнительные операции над числами:
(abs x) Абсолютное значение числа
Дополнительные операции деления:
(quotient n1 n2)
(remainder n1 n2)
(modulo n1 n2)
При этом n2 не должен быть равен нулю (независимо от точности числа). Если n1 / n2 есть целое:
(quotient n1 n2) Результат n1/n2
(remainder n1 n2) Результат 0
(modulo n1 n2) Результат 0
Если в результате n1 / n2 образуется не целое число:
(quotient n1 n2) Результат nq
(remainder n1 n2) Результат nr
(modulo n1 n2) Результат nm
где число nq – n1/n2, округленное к нулю, 0 <| nr | <| n2 |, 0 <| nm | <| n2 |, nr и nm отличаются от n1 множителем n2, nr получит знак n1, nm получит знак n2.
Особенностью этих функций (по сути, вариации на тему нахождение остатка от деления) является факт, того, что они возвращают точные числа, в случае если их входящие параметры также являются точными.
(modulo 13 4) Результат 1
(remainder 13 4) Результат 1
(modulo -13 4) Результат 3
(remainder -13 4) Результат -1
(modulo 13 -4) Результат -3
(remainder 13 -4) Результат 1
(modulo -13 -4) Результат -1
(remainder -13 -4) Результат -1
(remainder -13 -4.0) Результат -1.0 Обратите внимание, результат не точное число.
Следующие функции возвращают наибольший общий делитель или наименьший общий множитель их параметров. Результат является всегда неотрицательным.
(gcd 32 -36) Результат НОД (наибольший общий делитель) 4
(gcd) Результат 0
(lcm 32 -36) Результат НОМ (наименьший общий множитель) 288
(lcm 32.0 -36) Аналогично Результат 288.0, но теперь результат будет неточным.
(lcm) Результат 1
Следующие ниже функции возвращают числитель, и знаменатель дроби (знаменатель всегда положительное число):
(numerator q)
(denominator q)
Примеры:
(numerator (/ 6 4)) Результат 3
(denominator (/ 6 4)) Результат 2
(denominator
(exact->inexact (/ 6 4))) Результат 2.0, для получения неточного числа используется явное преобразование. Естественно удобно и для дробей:
(numerator 6/4) Результат 3 (рассматривается дробь 3/2, и только потом берется знаменатель)
Следующая группа функций:
(floor x)
(ceiling x)
(truncate x)
(round x)
всегда возвращает целые числа. Floor возвращает наибольшее целое число не большее чем х. Ceiling возвращает наименьшее целое число не меньше чем х. Truncate возвращает целое число, которое наиболее ближе к х, и абсолютная величина которого не больше абсолютной величины х. Round возвращает целое число путем округления х (половина икса округляется в большую сторону).
(floor -4.3) Результат -5.0 (числа целые, но не точные)
(ceiling -4.3) Результат -4.0
(truncate -4.3) Результат -4.0
(round -4.3) Результат -4.0
(floor 3.5) Результат 3.0
(ceiling 3.5) Результат 4.0
(truncate 3.5) Результат 3.0
(round 3.5) Результат 4.0 — не точное число
(round 7/2) Результат 4 — точное число
(round 7) Результат 7
(rationalize x y) – возвращает самое простое рациональное число, отличающееся от x не больше, чем y.
Рациональное число x более простое чем другое рациональное число y если x = p1/q1 и y = p2/q2 и и | p1 | < | p2 | и | q1 | <| q2 |. Таким образом, 3/5 более простое число чем 4/7. Хотя не все рациональные числа сопоставимы в этом упорядочении (например, 2/7 и 3/5), любой числовой интервал содержит рациональное число, которое более просто, чем любое рациональное число в том же интервале. Известно также, что 0 = 0/1 – самые простые рациональные числа из всех.
(rationalize
(inexact->exact .3) 1/10) Результат 1/3, точное число
(rationalize .3 1/10) Результат 0.3333333333333333
Трансцендентальные функции:
(exp z)
(log z)
(sin z)
(cos z)
(tan z)
(asin z)
(acos z)
(atan z)
(atan y x)
Здесь все просто, стоит отметить log – имеется ввиду натуральный (а не десятичный), atan с двумя параметрами использует знаки x, y для определения квадранта, к которому принадлежит результат.
(sqrt z) – вычисляет квадратный корень, включая мнимую часть числа:
(sqrt -1) Результат 0+1i (всегда мечтал в Паскале получить корень из -1)
(expt z1 z2) – возведение в степень, довольно-таки мощная функция, единственное ограничение – в степень запрещено возводить нуль.
(expt 2.1 3.3) Результат 11.569741950241465
(expt 2.1 -3.3) Результат 0.08643235124004903
Следующие функции предназначены для поддержки комплексных чисел:
(make-rectangular x1 x2)
(make-polar x3 x4)
(real-part z)
(imag-part z)
(magnitude z)
(angle z)
Здесь x1-x4 вещественные числа, z комплексное.
(make—rectangular x1 x2) Результат комплексное число
(make—polar x3 x4) Результат комплексное число
(real—part z) Результат реальную часть числа (x1)
(imag—part z) Результат мнимую часть числа (x2)
(magnitude z) Результат |x3|
(angle z) Результат xangle
Точные и неточные числа можно преобразовывать следующим образом:
(exact->inexact z)
(inexact->exact z)
Первая функция переводит точное число в неточное, вторая выполняет обратные действия. Естественно, такое преобразование возможно не всегда (такая ситуация считается ошибочной). Теперь рассмотрим ввод и вывод чисел. Числа можно получать из строки следующим образом:
(string->number string)
(string->number string radix)
Здесь radix есть основание системы счисления (точное целое число 2, 8, 10 или 16). Для первого варианта имеется ввиду основание системы счисления равным 10. Если число z является неточным и может быть выраженым с использованием точки в качестве разделителя целой и дробной частями, то число будет представлено с минимально возможным числом разрядов.
(string->number ”100″) Результат 100
(string->number ”100″ 16) Результат 256
(string->number ”1e2″) Результат 100.0
(string->number ”15##”) Результат 1500.0
В случае, если строку в число преобразовать не удастся, результат функции #f.
Пары и списки
Парой (иногда называется точечной парой) называется структура данных, представляющая собой запись, состоящую из двух полей, первое из которых называется car, а вторая cdr (названия сложились исторически). Пара создается функцией сons. Доступ к полям пары осуществляется одноименными функциями car и cdr. Присваивание значений полям пары осуществляется с помощью процедур set-car! и set-cdr!. Основное назначение пар это образование и представление списков. Список может быть определен рекурсивно, как пустой список (список, не содержащий элементов) или как пара поле cdr которого является списком. Если Х является списком, то:
. в Х содержится пустой список
. если список находится в X, то любая пара, поле cdr которой содержит список, находится также в X.
Объекты в полях car последовательных пар списка считаются элементами списка. Например, двухэлементный список это пара, car которой первый элемент списка и чей cdr пара, car которой второй элемент списка и чей cdr есть пустой список. Длина списка – это число элементов (которые можно выразить как число пар).
|
Список |
Список состоит из пар |
||||
|
Пара1 |
Car |
1-й элемент списка |
|||
|
Cdr |
Пара2 |
Car |
2-й элемент списка |
||
|
Cdr |
Пустой список |
||||
Список (a b c d e) можно выразить так (a . (b . (c . (d . (e . ()))))). То есть в списке пары расположены не последовательно друг за другом, а являются вложенными объектами. Пустой список – специальный объект своего собственного типа (это не пара); у него нет никаких элементов, и его длина равна нулю. При этом все списки имеют конечную длину (точное число) и заканчиваются пустым списком.
Для представления пар используется точечная нотация, поля разделяются точкой. Например, пара (4 . 5) имеет поле car 4 и поле cdr 5, при этом внутреннее представление пары будет иным. Списки выражаются проще (х1 х2 … хn), где х это элемент списка. Пустой список выражается, как (). Как уже было отмечено ранее, вся программа на языке Scheme является списком (как и любые ее логически законченные фрагменты), поэтому программы, и выражения можно обрабатывать также как и списки.
Существуют структуры, похожие на списки, которые не удовлетворяют данному выше определению, они называются неподходящие списки. Неподходящий список списком не является, вот его пример:
(a b c . d) что эквивалентно (a . (b . (c . d))), то есть неподходящие списки есть пары.
(define x (list ’a ’b ’c))
(define y x)
y Результат (a b c), list создает список
(list? y) Результат #t, предикат проверки списка
(set—cdr! x 4) Результат не определен (побочный эффект cdr х равен 4)
x Результат (a . 4)
(eqv? x y) Результат #t
y Результат (a . 4)
(list? y) Результат #f
(set—cdr! x x) Результат не определен
(list? x) Результат #f
Предикат (pair? obj) проверяет является ли объект парой.
(pair? ‘(a . b)) Результат #t
(pair? ‘(a b c)) Результат #t
(pair? ‘()) Результат #f
(pair? ’#(a b)) Результат #f
Следующая функция возвращает пару:
(cons obj1 obj2)
car пары будет представлять собой obj1, cdr соответственно obj2.
(cons ‘a ‘()) Результат (а)
(cons ‘(a) ‘(b c d)) Результат (c d)
(cons “a“ ‘(b c)) Результат (”a“ b c), обратите внимание на квотирование и кавычки
(cons ’a 3) Результат (a . 3)
(cons ’(a b) ’c) Результат ((a b) . c)
Квотирование в данном случае используется для того, чтобы поля пары не вычислялись в момент внесения в пару. Это позволяет вносить в пару как простые данные, вроде чисел, так и функции и выражения.
(car pair) – возвращает поле car пары (так и хочется сказать первое поле, но внутреннее представление пар может быть иным, поля пары могут находиться даже не в смежных областях памяти). Попытка получения car пустой пары вызовет ошибку.
(car ’(a b c)) Результат a
(car ’((a) b c d)) Результат (a)
(car ’(1 . 2)) Результат 1
(car ‘()) Результат ошибка вычислений
(cdr pair) – возвращает поле cdr пары. Получение cdr пустого списка вызовет ошибку.
(cdr ‘((a) b c d)) Результат (b c d)
(cdr ’(1 . 2)) Результат 2
(cdr ’()) Результат ошибка вычислений
(set—car! pair obj) и (set—cdr! pair obj) помещает соответственно в car и cdr пары pairs объект obj.
Результат их работы не определен, функции имеют побочные эффекты. Очень часто во время манипуляций со списками возникает много car и cdr. Такие выражения допускается сокращать:
(car (cdr (cdr x))) эквивалентно caddr, то есть справедливо следующее утверждение:
(define caddr (lambda (x) (car (cdr (cdr x)))))
Правило формирования функции следующее: все car представляются как а, а все cdr как d в наименовании функции, которая начинается с с и заканчивается r. При этом допускается формирование функций не более чем из четырех car и cdr.
(null? obj) – возвращает #t, если obj есть пустой список
(list? obj) – возвращает #t, если obj есть список.
(list? ‘(a b c)) Результат #t
(list? ’()) Результат #t
(list? ‘(a . b)) Результат #f
(let ((x (list ’a)))
(set-cdr! x x)
(list? x)) Результат #f
(list obj …) – создает список.
(list ’a (+ 3 4) ’c) Результат (a 7 c)
(list) Результат ()
(length list) – передает число элементов в списке
(length ’(a b c)) Результат 3
(length ’(a (b) (c d e))) Результат 3
(length ’()) Результат 0
(append list …) – объединение списков, при этом происходит перераспределение их внутренней структуры (таким образом, чтобы результат удовлетворял определению списка).
(append ‘(x) ‘(y)) Результат (x y)
(append ’(a) ’(b c d)) Результат (a b c d)
(append ’(a (b)) ’((c))) Результат (a (b) (c))
(append ’(a b) ’(c . d)) Результат (a b c . d)
(append ‘() ‘a) Результат a, список был изменен.
(reverse list) – возвращает список, перераспределенный в обратном порядке.
(reverse ’(a b c)) Результат (c b a)
(reverse ’(a (b c) d (e (f)))) Результат ((e (f)) d (b c) a)
(list-tail list k) – возвращает список на основе списка list, но без k первых элементов. Входящий список должен содержать не менее k элементов. Работу list-tail можно выразить функцией-эквивалентом:
(define list-tail
(lambda (x k)
(if (zero? k)
x
(list-tail (cdr x) (- k 1)))))
(list-ref list k) – возвращает k-й элемент списка. В списке должно быть не менее k элементов.
Нумерация элементов списка осуществляется от нуля. Плюсом пар и неподходящих списков является возможность создания древовидных структур данных с неограниченным числом узлов (пока хватит памяти компьютера).
Символы
Это специальные объекты, особенность которых заключается в том, что символы считаются эквивалентными (для предиката eqv?), если получены одинаковым путем. Символы в частности могут представлять идентификаторы программы, и их уникальность дает возможность использовать их во внутреннем представлении программы. Правила образования символов полностью соответствуют правилам образования идентификаторов. Не следует путать данные символы (Symbols) с символами строки (Characters). Это символы программы и не предназначены для представления строк (хотя и могут быть конвертированы в строки). В частности символы можно получить, квотировав идентификаторы.
Следующий предикат подтверждает, все то, что сказано выше:
(symbol? obj) – определяет является ли объект символом.
(symbol? ’foo) Результат #t
(symbol? (car ’(a b))) Результат #t
(symbol? “bar“) Результат #f, строки представляются строковыми символами!
(symbol? ‘nil) Результат #t
(symbol? ‘()) Результат #f
(symbol? #f) Результат #f
(symbol? 5) Результат #f
(symbol? ‘5) Результат #f, это не идентификатор и не выражение
Для преобразования символов в строки используется
(symbol->string symbol)
Примеры:
(symbol->string ’flying-fish) Результат “flying-fish”
(symbol->string ’Martin) Результат “martin”
(symbol->string
(string->symbol ”Malvina”)) Результат “Malvina”
Здесь (string->symbol “Malvina“) выполняет обратную функцию.
(string->symbol “Привет“)
Символы, в частности, предоставляют программисту возможность работать с объектами программы через операции над их идентификаторами.
Строковые символы
Строковой символ – минимальная единица представления текстовой информации. Строковые символы можно образовывать так #\<character> или #\<character name>. Вот примеры образования строковых символов:
#\a; буква в нижнем регистре
#\A; буква в верхнем регистре
#\(; открывающая скобка
#\ ; пробел
#\space; пробел (образование строкового символа по его имени)
#\newline; символ перехода на новую строку
Поскольку Scheme во многом система, не зависящая от конкретной платформы, то получать константы строковых символов по кодам в какой-либо кодировке не допускается. Поэтому нельзя получить строковой символ #\13, в тоже время PLT Scheme позволяет получать символы национальных алфавитов и задать строковый символ #\й вполне допустимо. Для определения факта того, что объект является строковым символом, используется следующая функция:
(char? obj) – возвращает #t, если объект является строковым символом.
(char? ‘try) Результат #f, поскольку язык проводит четкую границу между символами и строковыми символами.
Все строковые символы определяются на основе их порядка следования в алфавите. Поэтому между строковыми символами существуют отношения, связанными с их расположением относительно друг друга. Для оценки строковых символов используется ряд функций:
(char=? char1 char2)
(char<? char1 char2)
(char>? char1 char2)
(char<=? char1 char2)
(char>=? char1 char2)
Сначала следуют цифры, потом прописные буквы, потом строчные (национальные символы «больше» латиницы). Кстати, PLT Scheme версии 350 допускает более двух символов для сравнения (на манер числовых предикатов).
(char-ci=? char1 char2)
(char-ci<? char1 char2)
(char-ci>? char1 char2)
(char-ci<=? char1 char2)
(char-ci>=? char1 char2)
Тоже самое, но без учета регистра.
(char-ci=? #\A #\a)
Результат #t. Аналогично, функции с приставкой –ci в PLT Scheme могут содержать больше чем два аргумента.
(char-alphabetic? char) – возвращает #t, если строковой символ буква.
(char-numeric? char) – возвращает #t, если строковой символ цифра.
(char-whitespace? char) – возвращает #t, если строковой символ пробел.
(char-upper-case? letter) – возвращает #t, если строковой символ буква в верхнем регистре.
(char-lower-case? letter) – возвращает #t, если строковой символ буква в нижнем регистре.
Несмотря на то, что задавать константы строковых символов их кодами нельзя, получать коды из строковых символов разрешено: (char->integer char) – вернет точное целое число, которому сопоставлен данный строковой символ. Обратная ей функция (integer->char n). Изменить регистр символов можно с помощью функций:
(char—upcase char) – изменяет регистр строкового символа на верхний
(char—downcase char) – изменяет регистр строкового символа на нижний.
Строки
Строки это последовательности символов. В Scheme строки выделяются кавычками. В строки допускается включать Escape-последовательности через использование обратного слеша (\). Например, если известны коды символов, то строку можно задать следующим образом: “\u65\u65” (чего нельзя делать для строковых символов). Длина строки есть число содержащихся в ней символов (точное целое неотрицательное число). Индексация символов начинается от нуля. Аналогично операций с символами все функции имеющие приставку –ci есть операции со строками без учета регистра. Начнем с определения строки:
(string? obj) – возвращает #t, в случае, если объект является строкой.
Существует два способа напрямую создать строку с помощью функций:
(make-string k)
(make-string k char)
Здесь, k – есть длина создаваемой строки, char – символ, которым должна быть наполнена строка (в первой функции она будет наполнена символами вида ”\u0000\u0000\u0000”). Также строки можно создавать путем конкатенации (объединении) символов:
(string char …)
Длина строки:
(string-length string)
Можно также получить доступ к каждому элементу строки (строковому символу):
(string-ref string k)
(string-ref “Привет” 1) Результат #\р, так как нумерация в строке идет от нуля
Изменить конкретный символ в строке можно с помощью: (string—set! string k char). При этом следует помнить, что string—set! возвращает неопределенное значение. Строки можно сравнивать (на порядок расположения в них строковых символов):
(string=? string1 string2)
(string-ci=? string1 string2)
(string<? string1 string2)
(string>? string1 string2)
(string<=? string1 string2)
(string>=? string1 string2)
(string-ci<? string1 string2)
(string-ci>? string1 string2)
(string-ci<=? string1 string2)
(string-ci>=? string1 string2)
PLT Scheme разрешает использовать более двух аргументов при сравнении строк.
(string=? “12″ “15″ “gsjfds”) Результат #f
При этом более короткие строки считаются меньше длинных:
(string-ci<? “fff” “ffff”) Результат #t
Выделение подстроки:
(substring string start end)
При этом входящие параметры должны удовлетворять условию:
0 < start < end < (string-length string)
Объединение (конкатенация) строк:
(string—append string …)
(string—append “Привет ” “Мир!”) Результат “Привет Мир!”
Также важны функции преобразования строк:
(string->list string) – преобразование строки в список строковых символов
(list->string list) – преобразование списка в строку (список должен быть списком строковых символов)
(string->list string) и (list->string list) являются противоположными по отношению друг к другу.
(string-copy string) – возвращает копию строки
Векторы
Векторы в Scheme есть неоднородные структуры данных индексированные целыми числами. Одним из плюсов векторов является организация, построенная таким образом, что скорость доступа к ним выше, чем к спискам. Длина вектора есть число элементов, которые он содержит (целое точное неотрицательное число, также как и индекс любого из доступных элементов вектора). Индексация элементов вектора начинается от нуля. В общем, векторы сильно похожи на массивы императивных языков программирования, но имеют одну приятную особенность – вектор может содержать данные различных типов.
Для записи векторов используется следующая нотация: #(obj …).
#(0 (2 2 2 2) ”Anna”) Вектор, состоящий из трех элементов – числа нуль, списка (2 2 2 2) и строковой константы ”Anna”.
(vector? obj) – определяет, является ли объект вектором (#t если объект вектор).
(make—vector k) – создает вектор из k элементов, сами элементы не определены.
(make—vector k fill) – создает вектор из k элементов, элементы которого являются fill.
(vector obj …) – создает вектор из указанных объектов.
(vector ‘a ‘b ‘c) Результат #(a b c), сами элементы при этом не вычисляются (из-за одинарной кавычки).
(vector-length vector) – возвращает длину вектора (точное целое число).
(vector-ref vector k) – возвращает k-тый элемент вектора (k как и все индексы должен быть точным и целым).
(vector-ref ’#(1 1 2 3 5 8 13 21) 5) Результат 8 (нумерация от нуля).
(vector—set! vector k obj) – присваивает k-тому элементу вектора значение obj. Результат не определен, функция обладает побочными эффектами.
(vector->list vector) – создает список из вектора.
(list->vector list) – создает вектор из списка.
(vector->list ’#(dah dah didah)) Результат (dah dah didah)
(list->vector ’(dididit dah)) Результат #(dididit dah)
(vector-fill! vector fill) – заполняет указанный вектор объектами fill. Результат функции не определен, функция имеет побочные эффекты.
Особенности управления
Здесь мы опишем некоторые (не все, например, отложенные вычисления уже рассматривались) механизмы, облегчающие управление процессом выполнения.
(procedure? obj) – возвращает #t, в случае если перед нами процедура. Надо отметить, что в Scheme очень часто идет слияние понятий функция и процедура.
(procedure? car) Результат #t
(procedure? ’car) Результат #f
(procedure? (lambda (x) (* x x))) Результат #t
(procedure? ‘(lambda (x) (* x x))) Результат #f
(apply proc arg1 … args) – вызывает указанную функцию к аргументам заданным списком.
(apply + (list 3 4)) Результат 7, для функции + (плюс) задается параметр (только один), заданный в виде списка.
(map proc list1 list2 …) – применение функции proc к каждому из списков. Списки должны иметь одинаковый размер. Одна из мощнейших функций языка. Работает это следующим образом:
(map car ‘((a b) (d e) (g h))) Результат (a d g)
(map cdr ‘((a b) (d e) (g h))) Результат ((b) (e) (h))
(map cadr ‘((a b) (d e) (g h))) Результат (b e h)
Функция всегда работает со списками и списки же и возвращает. Эти примеры не полностью раскрывают работу функции, вот еще примеры:
(map + ’(1 2 3) ’(4 5 6)) Результат (5 7 9)
(map + ‘(1 2 3) ‘(4 5 6) ‘(7 8 9)) Результат (12 15 18)
(define my-list ‘(1 2 3 4 5))
(define (square val) (* val val))
(map square my-list) Результат (1 4 9 16 25)
(for—each proc list1 list2 …) —
аналогична map, но используется в основном для функций с побочными эффектами, результат которых не определен.
(let ((v (make-vector 5)))
(for-each (lambda (i)
(vector-set! v i (* i i)))
‘(0 1 2 3 4))
v)
Результат #(0 1 4 9 16). Создаем вектор v из пяти элементов. Затем применяем (lambda (i) к вектору v. Заносим данные из списка ‘(0 1 2 3 4) (который сразу не вычисляется из-за одинарной кавычки) следующим образом: в вектор v записывается элемент списка, умноженный сам на себя (запись осуществляется посредством vector—set!, при этом в качестве индексов для доступа к вектору используется все тот же список ‘(0 1 2 3 4)). После выхода из блока let вектор v будет разрушен, а его содержимое будет передан как результат работы блока let.
PLT Scheme
Теперь немного подробней о самой IDE. PLT Scheme состоит из нескольких компонентов:
. MrEd – расширение MzScheme для графического программирования
. DrScheme – среда проектирования
. Mzc – компилятор в байт-код, не зависимый от платформы (позволяет создавать переносимые приложения)
. MzScheme3m – экспериментальная версия MzScheme, особенность которой более точное управление распределением памятью (в сравнении MzScheme).
MzScheme, основной компилятор, интерпретатор, и система поддержки исполнения программ. Кроме того, PLT Scheme, содержит в себе не только описанный выше стандарт R5RS, но также дополнительные возможности, а именно:
. система поддержки пространства имен и управления трансляцией
. поддержка механизма исключений
. приоритетные потоки
. классы и система объектов
. регулярные выражения
. расширенная поддержка макросов
. поддержка хэшей (как встроенного типа данных)
. поддержка юникода.
И более того, PLT Scheme содержит также группу диалектов Scheme, каждый из которых имеет свои задачи (например, есть диалект специально адаптированный для изучения функционального программирования студентами высших учебных заведений). Так как система построена в минималистичном и строгом стиле рекомендуется начинать изучение с DrScheme (он не так суров, и не сильно отпугивает пользователей привыкших к обилию кнопок, картинок и иконостасу на Рабочем столе). Его-то мы и рассмотрим подробней.
Как уже упоминалось ранее, DrScheme имеет два окна, одно предназначено для ввода текста программы, второй есть командный интерпретатор (команды, введенные в него, исполняются немедленно, что удобно для изучения языка). В последнее же окно выводится и сообщения от drScheme, именуемое как главная текстовая область (см. рисунок 1):
Рис. 1. Среда drSheme
Поскольку PLT Scheme поддерживает несколько языков программирования, то прежде чем приступить к работе, нужно выбрать* соответствующий язык программирования Language|Choose Language (см. рисунок 2):
Рис. 2. Выбор языка
* Комментарий автора
наименование пунктов меню может немного отличаться в зависимости от версии среды разработки
Стандарт языка называется Standart (R5RS), для освоения материала статьи его вполне достаточно. Остальные диалекты отличаются различными свойствами, в том числе и поддержкой графического интерфейса пользователя. PLT Scheme запоминает последний выбранный диалект и при следующем запуске сразу же готов работать в выбранном контексте.
Изюминкой PLT Scheme является возможность компиляции текстов программ. Исторически и по ряду объективных причин большинство реализаций Scheme есть интерпретаторы. Однако готовые к употреблению программы без стороннего окружения также необходимы (что, кстати, требуют и решаемые задачи, круг которых гораздо шире в PLT Scheme, чем в голом стандарте R5RS). Чтобы получить из текста программы на языке Scheme вполне функциональный exe-файл требуется, чтобы программа была введена в окно ввода программы (обычно оно первое) (см. рисунок 3). А также чтобы она была уже сохранена во внешнем файле.
Рис. 3. Работа с примером
Затем выбираем пункт меню Scheme|Create Executable… Далее необходимо выбрать тип исполнения файла (см. рисунок 4):
. Launcher
. Stand-alone
. Distribution.
Рис. 4. Создание исполняемого файла
Для простых учебных примеров Stand—alone вполне достаточно (однако, если необходимо использовать программу на другом компьютере, то потребуется перетащить некоторые библиотеки).
Заключение
Введение дает только элементарные азы и рассчитано на плавный переход от императивного стиля к функциональному. Данное введение не дает представления о функциональном программировании – это просто справочник наиболее распространенных команд языка Scheme, также знакомство с конкретной средой разработки PLT Scheme. Более полное и подробное руководство по PLT Scheme можно найти на сайте проекта (на английском языке), статья предназначена быть отправной точкой для дальнейшего самостоятельного обучения. Дополнительно можно отметить возможность встраивания Scheme и в другие языки программирования (как встроить Scheme в Дельфи, можно узнать здесь: http://www.orlovsergei.com/Progs/Scheme/SchemeToDelphi.htm). Плюсы такого союза очевидны, например, это удобно для работы с длинной арифметикой.
Ресурсы
. Лисп как альтернатива Java http://alexey.tamb.ru/scheme/lisp-scheme-java.html
. Сайт «схемщиков» http://schemers.org
. PLT Scheme http://www.plt-scheme.org
. Дополнительные библиотеки для PLT Scheme http://planet.plt-scheme.org
. Неформальное введение в Scheme http://ru.wikibooks.org/wiki/Введение_в_язык_Scheme_для_школьников
19th
MP3 изну-три

В этой статье я расскажу, как устроен MP3 файл, и покажу, как можно работать с ним в ваших программах. Мы попробуем извлечь информацию о файле, такую как длину трека, его битрейт и частоту дискретизации. Воспроизведение звука мы рассматривать не будем, это отдельная, и я думаю намного более сложная тема…
Александр Терлецкий
by mutabor altair.79@mail.ru
Немного про формат
MP3 расшифровывается как MPEG 1 Layer 3, т.е. MPEG версии 1, третья редакция, или как-то в этом роде. Нам важно понять, что бывает еще MPEG 2, а Layer не обязательно может быть третьим. Что такое MPEG, почему Layer 3, чем отличается MPEG1 от MPEG2, и прочие подобные вопросы я рассматривать не буду, т.к. это само по себе тянет на отдельную статью. MP3 это сжатый формат, сжатие достигается за счет убирания из исходного звука частот заведомо не слышимых человеком, ну и еще за счет алгоритма сжатия какого-нибудь (это я тоже не буду здесь рассматривать). Именно поэтому сжимать архиваторами MP3 файлы не получается (вернее получается, но результат не впечатляет), они уже сжатые. Внутри файл состоит из фреймов. Заголовка у MP3 файла нет, зато у каждого фрейма есть свой заголовок, с ним то мы и будем в основном работать. Фрейм можно рассматривать, как некий дискретный кусок звукового потока.
Теги
Помимо фреймов, в файле могут быть один или несколько ID3 тегов. ID3 – это теги специально разработанные для формата MP3, т.к. он сам не содержит никакой описательной части. Теги бывают разных версий, чаще всего это или ID3v1.x или ID3v2.x. Теги первой версии находятся в последних 128 байтах файла, начинаются с символов TAG (такой тег может занимать и более чем 128 байт, но это редко, это усовершенствованная первая версия ID3). Теги второй версии могут находиться в любой части файла, но чаще они располагаются в начале файла, и начинаются с символов ID3. Теги второй версии намного более расширенные, чем теги первой версии, в них нет ограничений на длину полей с описанием трека, количество доступных полей намного больше, можно использовать Юникод, тег может содержать в себе изображение. Длина тега второй версии не фиксированная, и определяется по заголовку тега (в отличие от MP3 файла, у ID3v2 тега есть заголовок). Наличие тегов в файле не является обязательным, и их может не быть совсем, а могут быть оба, и тег первой версии в конце файла, и второй в начале, это делается в целях совместимости с большим количеством плееров. Часто возникает проблема с русскими символами в тегах в плеерах мобильных телефонах, я думаю это связано с Java машиной в телефоне, дело в том, что она поддерживает строки в формате UTF-8, а русские теги часто имеют кодировку Win-1251. Чтобы избежать «козябриков» на этих устройствах, нужно сохранять теги в Юникоде.
Теперь немного о том, как читать теги программно. Я не буду подробно освещать эту тему здесь, скажу лишь, что существуют библиотеки, компоненты для их чтения, также в сети доступна спецификация на эти теги, так что можно и самому написать их обработку, если есть желание. Звуковые движки, например тот же BASS, тоже умеют читать теги. Они кстати умеют и все остальное, о чем я буду писать ниже, и если ваша задача – получить информацию о файле, и вам не интересно как он устроен, можете в принципе дальше не читать, так как через интерфейс движка это сделать намного легче. Если вам звук нужно еще и воспроизводить, то этот способ даже лучше, зачем ковыряться в спецификациях, если есть удобный инструмент. Но бывают случаи, когда звук воспроизводить не надо, а нужна только информация о файле, и тогда лучше подключить легкий модуль, чем таскать движок за программой.
Битрейт
В этой статье я затрону только те характеристики, которые мы будем читать из файла, остальную общую информацию об MP3 можно без проблем найти в Интернете, ее достаточно, в отличие от более специализированной информации о формате.
Как вы все, наверное, знаете, MP3 файл может иметь различный битрейт, это кол-во бит выделенных на кодирование звука в единицу времени. Понятно, что чем он выше, тем качество звука лучше, и размер файла соответственно тоже больше. Значение битрейта в MP3 может находиться в пределах от 8 до 320 кбит/с. Полный список смотрите в Рис 2. Битрейт может быть постоянным (constant) и переменным (variable), это обозначается аббревиатурами CBR и VBR соответственно. Переменный битрейт позволяет снизить размер файла, не снижая качества. Это достигается за счет того, что на участках, где это не требуется, например тишина в начале трека, используется меньшее количество бит для кодирования. На уровне структуры файла это выражается в том, что один фрейм может иметь битрейт, например 128, а следующий может иметь уже 192, и т.д. В каждом отдельном фрейме битрейт имеет значение кратное степени двойки, соответствующее спецификации (см. рисунок 2). В целом по файлу, битрейт, в случае если он постоянный, не будет отличаться от значения битрейта первого фрейма, таким образом, нам достаточно взять информацию из первого фрейма, и мы имеем информацию о файле. В случае если битрейт переменный, то все усложняется, нам недостаточно одного фрейма, чтобы делать выводы об общем битрейте файла.
Частота дискретизации
Вторая характеристика, которую мы рассмотрим, это частота дискретизации или Sample Rate. Это частота, с которой при кодировании звука снимаются замеры с источника звука. Например, если частота у нас 44100 Гц, то это значит, что столько раз в секунду снимаются и сохраняются значения оригинального, аналогового звука. По сути, оцифровка. Можно конечно и уже оцифрованный звук перегнать с другим сэмпл-рейтом, но качество можно только понизить, повысить уже вряд ли удастся. Как и в случае с битрейтом, от частоты дискретизации напрямую зависит качество звука. Частота дискретизации в MP3 не может варьироваться, и всегда постоянна для всего файла.
Длина
У любой музыкальной композиции или любой другой звуковой записи есть такая характеристика, как длина. Упоминаю я ее отдельно для того, чтобы обрадовать вас, что так как у MP3 файла общего заголовка нет, то и готовые сведения о длине нам взять в принципе неоткуда (ID3 тег не в счет, в нем может быть длина трека, а может и не быть, а может и самого тега не быть). Поэтому длину нам придется высчитывать самостоятельно. На этом с характеристиками закончим и перейдем к разбору фреймов.
Рис. 1.
Фреймы
Один фрейм состоит из двух блоков (последовательностей бит) – заголовка и блока данных (см. рисунок 1). Заголовок представляет собой последовательность из 32 бит (4 байта), в которых описываются все необходимые параметры звука, а также параметры самого фрейма (например, его длина). В блоке данных находиться непосредственно звуковые данные. Рассмотрим заголовок подробнее (см. рисунок 2). Вначале идут 12 бит сигнатуры (Sync), по этим битам нужно искать фреймы, все они установлены в единицу. Затем идут еще три бита: версия, слой и защита от ошибок. Я сделал вывод, что если принять по умолчанию что мы работаем с MP3 файлом, а не с какой-нибудь другой версией MPEG, томожно брать первые два байта как сигнатуру, в этом случае они могут иметь всего две комбинации: FF FA или FF FB. Мне показалось так удобнее искать фреймы, и именно так я реализовал это в коде. Через третий байт мы пока перескочим, и я вкратце расскажу о четвертом. В нем есть такая интересная штука как режим стерео. Дело в том, что MP3 имеет еще оди н способ уменьшить вес файла, не ухудшив качество. Это режим Joint Stereo (объединенное стерео). Что же это такое? Пройдемся по порядку. Режим моно, это, как вы знаете, когда всего один звуковой канал. Стерео — это независимые левый и правый каналы. Для хранения стерео данных, необходимо ровно в два раза больше места, чем для моно. Joint Stereo же позволяет хранить два независимых канала, при этом, занимая меньше места, это достигается за счет «умной» паковки во время сжатия. Если выбран этот режим, и в данном сэмпле звука левый и правый каналы не отличаются, то кодер сохраняет только один из них, когда же каналы отличаются, то они сохраняются оба. Это в своем роде стерео по требованию, оно используется там, где это реально нужно, а где не нужно, место экономится. В четвертом байте хранится еще ряд параметров, не буду на них останавливаться, кому интересно, смотрите на рисунке, там все подписано, обычно они интереса не представляют.
Самый значимый для нас это 3-й байт заголовка. В нем содержится информация о битрейте, частоте дискретизации, установлен или нет Pad бит (определяет наличие добавочного байта в фрейме), все это вместе взятое позволяет нам высчитать размер этого фрейма. Размер фрейма высчитывается по формуле 1:
144 * BitRate / SampleRate + Pad; (1)

Рис. 2.
Если Pad бит равен единице то и в формулу подставляем единицу, если нулю – подставляем нуль. Битрейт и частоту подставляем в их полном виде, без округлений, битрейт в битах, а частоту в герцах. В файлах к этой статье вы найдете пример извлечения нужной информации из заголовка фрейма и реализацию этой формулы на языке Delphi. Чтобы что-то извлечь из заголовка, его нужно сначала найти, это тоже там есть. На самом деле достаточно найти первый фрейм, позицию каждого следующего мы уже будем знать, прибавляя к позиции текущего фрейма его длину.
Теперь поговорим о том, как найти переменный битрейт и длину трека. С постоянным битрейтом все ясно, он одинаковый для всего файла, и его можно взять из первого фрейма. С переменным не так. Во-первых, нигде не написано что он переменный, и чтобы это определить, нужно прочесть больше чем один фрейм. Я пошел самым простым путем, и читаю два первых фрейма. Если битрейт у них одинаковый я считаю что битрейт постоянный, если разный то переменный. Это скорее всего не точно, ведь переменным он может стать и после второго фрейма. Однозначных рекомендаций по этому вопросу я не встречал, возможно, есть соглашение, что если битрейт переменный, обязательно кодировать первые два фрейма с различным битрейтом, я бы так и сделал на месте разработчиков, но это только мои предположения. Если у вас есть более точная информация на этот счет, оставляйте комментарии к статье на сайте журнала, интересно будет почитать. Понятно, что в случае переменного битрейта необходимо как-то высчитать его среднее значение по всем фреймам. Оставлю это вам, у меня в коде в этом месте стоит заглушка, т.е. просто в случае переменного битрейта, в качестве его значения присваивается ноль.
Заключение
Теперь про длину трека. Ее можно высчитать, поделив размер файла (за вычетом тегов и прочего мусора, нужны только фреймы, не совсем ясно только, включать заголовки или нет) на битрейт, если он постоянный. Таким образом, мы получим длину трека в секундах. Если битрейт переменный, этот способ не подходит (хотя можно на усредненный битрейт поделить), тогда мы можем задействовать сэмпл-рейт, он у нас постоянный для всего файла, и представляет собой кол-во сэмплов в секунду. Если предположить что сэмпл и фрейм это одно и то же, то можно узнать количество секунд в треке, посчитав все фреймы. Я не пробовал ни тот, ни другой способ, не буду портить вам удовольствие и позволю самим попробовать высчитать длину трека. Если что интересное получится, пишите в комментариях. Опять же, можно переменный битрейт считать от обратного, найти по сэмпл- рейту длину, и потом уже одним действием найти средний битрейт.
Все исходные коды, упомянутые в статье, приложены непосредственно к журналу «ПРОграммист. Пятый выпуск».
На этом закончим, спасибо за внимание, читайте наш журнал.
Статья из пятого выпуска журнала «ПРОграммист».
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
17th
Авг
Microsoft предупреждает о случаях эксплуатации новой бреши в Windows XP/Vista/7
Microsoft предупреждает о случаях эксплуатации новой бреши в Windows XP/Vista/7 связанную с инфицированными USB-накопителями. В описании, размещенном на сайте Microsoft, говорится, что хакеры используют данную уязвимость уже около месяца. Уязвимость проявляется
в том, что ОС Windows обычно работает с файлами-ярлыками, которые традиционно размещаются на Рабочем столе или в меню Пуск системы и как правило эти ярлыки указывают на конкретные локальные файлы или программы.
Методика заражения
Вы должны принять во внимание, что этот вирус заражает систему необычным путем (без файла autorun..inf), через уязвимость в lnk-файлах. Так вы открываете зараженную флешку с помощью проводника или другого менеждера способного отображать иконки (например TotalCommander) и запускаете вирус, компьютер заражен. Ниже на скриншоте вы можете увидеть содержимое флешки FAR (он не заражает систему):

На скриншоте вы можете видеть что в корне USB-устройства располагаются два tmp файла (на самом деле они приложения) и 4 файла lnk. Следующий скриншот демонстрирует содержимое lnk файлов

Операционная система Windows 7 Enterprise Edition x86 со всеми последними обновлениями также уязвима, из чего следует вывод что уязвимость присутствует и в предыдущих версиях.
Процесс заражения и скрытия в системе
Процесс заражения развивается по следующему пути:
1. Два файла (mrxnet.sys и mrxcls.sys, один из них действует как драйвер-фильтр файловой системы, а второй включает в себя вредоносный код) располагаются в директории %SystemRoot%\System32\drivers. Ниже представлен скриншот программы GMER отображающей вирусные драйверы.
Данные драйверы подписаны (имеют цифровые подписи) Realtek Semiconductor Corp. Файлы mrxnet.sys и mrxcls.sys также добавлены в вирусные базы VirusBlokAda как Rootkit.TmpHider
(http://www.virustotal.com/ru/analisis/0d8c2bcb575378f6a88d17b5f6ce70e794a264cdc8556c8e812f0b5f9c709198-1278584497) и Scope.Rookit.TmpHider.2 (http://www.virustotal.com/ru/analisis/1635ec04f069ccc8331d01fdf31132a4bc8f6fd3830ac94739df95ee093c555c-1278661251) соотвественно.
2. Два файла (oem6c.pnf и oem7a.pnf, содержимое которых зашифровано) располагаются в папке %SystemRoot%\inf .
Вирус запускается сразу после заражения, так что перезагрузка не требуется.
Драйвер-фильтр скрывает файлы ~wtr4132.tmp и ~wtr4141.tmp и соответствующие lnk файлы. Поэтому пользователя не заметят новый файлах на USB-устройстве. . Vba32 AntiRootkit (http://anti-virus.by/en/beta.shtml) детектирует вирусные модули свежующим образом:
3. Также руткит добавляет потоки в системные процессы, и в тоже время прячет модули которые запускаются в потоках. Антируткит GMER фиксирует следующие аномалии:
4. Руткит устанавливает ловушки в системных процессах
Предпосылки эксплуатации уязвимости:
Успешность эксплуатации уязвимости и последствия зависят от конфигурации вашего компьютера:
• Атакующий, который успешно поэксплуатировал уязвимость получает права того локального пользователя под чьей учетной записью производилась эксплуатации. Пользователи сидящие под ограниченной четкой понесут меньший урон, чем те что имеют права администратора.
• Когда автозапуск выключен, пользователя самому придется открыть проводником или другой программой корень переносного устройства (флешки).
• Закрыв доступ к сетевым папкам с помощью фаервола вы предотвратите риск эксплуатации уязвимости через расшаренные ресурсы.
Защита
Данные советы не исправят уязвимость, но они помогут снизить риск успешность эксплуатации уязвимости до времени выхода заплатки. Майкрософт протестила данные советы и ответственно заявляет что они помогают.
• Отключение отображения иконок ярлыков
1. Пуск- Выполнить, в открывшемся окошке написать Regedit, нажать ОК.
2. Пройти в данную ветку реестра
HKEY_CLASSES_ROOT\lnkfile\shellex\IconHandler
3. Щелкните File (Файл) в меню и выберите Export (Экспорт)
4. В окне экспорта введите LNK_Icon_Backup.reg и нажмите Save (Сохранить)
Этими действиями вы создали резервную копию ключей реестра.
5. Выберите параметр Default в правой стороне окна Редактора реестра. Нажмите Enter чтобы отредактировать значение. Удалите значение, т.е. поле станет пустым, нажмите Enter.
6. Перезапустите процесс explorer.exe или перезагрузите компьютер.
Проверка результата. Отключение иконок на ярлыках защитит от эксплуатации уязвимости на уязвимой системе. Когда вы проделаете эти действия то иконки ярлыков и IE перестанут отображаться.
• Отключение службы WebClient.
Отключение службы WebClient поможет защитить уязвимую систему от атаки путем блокирования удаленной атаки через сервис Web Distributed Authoring and Versioning (WebDAV). После произведения данных действий, останется возможность для удаленной атаки и успешной эксплуатации уязвимости связанной с Microsoft Office Outlook и запуском программ на атакуемой машине пользователей сети (LAN), но при этом пользователь получит предупреждение о попытке запуска программ из интернет.
Для выключения службы WebClient воспользуйтесь следящими пунктами:
1. Пуск-Выполнить, впишите Services.msc и нажмите ОК.
2. Правой кнопкой щелкните по службе WebClient и выберите свойства.
3. Измените тип запуска на Отключено. Если эта служба запущена, то нажмите Стоп (остановить) .
4. Нажмите ОК и закройте приложение.
Проверка результата. Когда вы отключите службу WebClient, престанут посылаться запросы Web Distributed Authoring and Versioning (WebDAV), и любая служба зависящая от WebClient также не будет запускаться. Пока в корпорации не говорят, когда будет выпущено исправление. Пока же же пользователи могут защищаться путем отключения отображения ярлыков на съемных носителях или за счет отключения сервиса WebClient. Оба метода выполняются через реестр Windows.
Интересные факты с пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
17th
Каждому российскому участковому – личную страничку в Интернет
 Каждый российский участковый обзаведется личной интернет-страничкой, где будут размещены его персональные и контактные данные. За счет «интернетизации» участковых МВД хочет повысить качество обратной связи между населением и милицией. Однако за счет каких средств будут созданы более 54 тыс. сайтов, пока не понятно.
Каждый российский участковый обзаведется личной интернет-страничкой, где будут размещены его персональные и контактные данные. За счет «интернетизации» участковых МВД хочет повысить качество обратной связи между населением и милицией. Однако за счет каких средств будут созданы более 54 тыс. сайтов, пока не понятно.
В России под лозунгом «Безопасность начинается с доверия» стартовала акция, в рамках которой каждый участковый уполномоченный милиции обязан будет завести собственную интернет-страницу. На персональном сайте участкового будет размещена информация о нем самом: его фотография, биография, контактные данные. Кроме того, на сайте появятся данные о курируемых участковым районах, часах приема и контактах руководства и надзорных органов, фото людей, находящихся в розыске или пропавших без вести, и другого рода полезная информация.
Такие сайты будут содержать интерактивные разделы, где граждане смогут задать участковому вопрос. Появится и раздел «Добровольный помощник», где можно будет сообщить о правонарушении, в том числе и анонимно. По задумке МВД, создание персональных сайтов для участковых должно простимулировать социальную активность граждан.
Сегодня в России работают более 54 тыс. участковых. Согласно рекомендации МВД, в городах участковый инспектор должен обслуживать 4—5 тыс., в сельской местности — 3—4 тыс. человек. В настоящий момент средняя зарплата участкового составляет 12 тыс. руб. В ходе реформы МВД к 2012 году ее планируется увеличить втрое.
Средняя стоимость создания простенького сайта в Москве составляет около 10 тыс. руб. Таким образом, только на первоначальный этап «интернетизации» корпуса участковых понадобится более 540 млн руб. Плюс немалые средства потребуются для дальнейшей поддержки сайтов. Где министерство возьмет более чем полмиллиарда рублей, источник РБК daily в МВД ответить затруднился: «Возможно, это будет происходить постепенно, пока же таких средств нигде не заложено». Получить официальный комментарий в МВД не удалось.
«Идея очень здравая, ведь сегодня своего участкового знают в лицо только гиперактивные бабушки, — считает юрист Альберт Феоктистов. — Количество пользователей Интернета постоянно множится, особенно в больших городах, и многие уже привыкли за любой информацией обращаться в Сеть. Такие сайты позволят гораздо большему количеству граждан узнать своего участкового».
Интересные факты с пятого выпуска журнала “ПРОграммист”.
Скачать этот номер можно по ссылке.
Ознакомиться со всеми номерами журнала.
Облако меток
css реестр ассемблер timer SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid canvas поиск файл Pascal форма Файлы интернет Microsoft Office Excel excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
